| 分类 | 内容 |
|---|---|
| 论文题目 | RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback |
| 作者 | 作者团队:由来自清华大学和新加坡国立大学的研究者组成,包括Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua。 |
| 发表年份 | CVPR 2024 |
| 摘要 | 文章针对多模态大型语言模型(MLLMs)在生成与图片不符的文本(即幻觉问题)提出了RLHF-V框架。通过从细粒度的人类反馈中学习,显著减少基础MLLM的幻觉率,提高了模型的可信度和实用性。 |
| 引言 | 强调了MLLMs在多模态理解、推理和交互方面的能力,同时指出其存在的幻觉问题,即生成与关联图片不符的文本,这一问题限制了MLLMs在实际应用中的可信度。 |
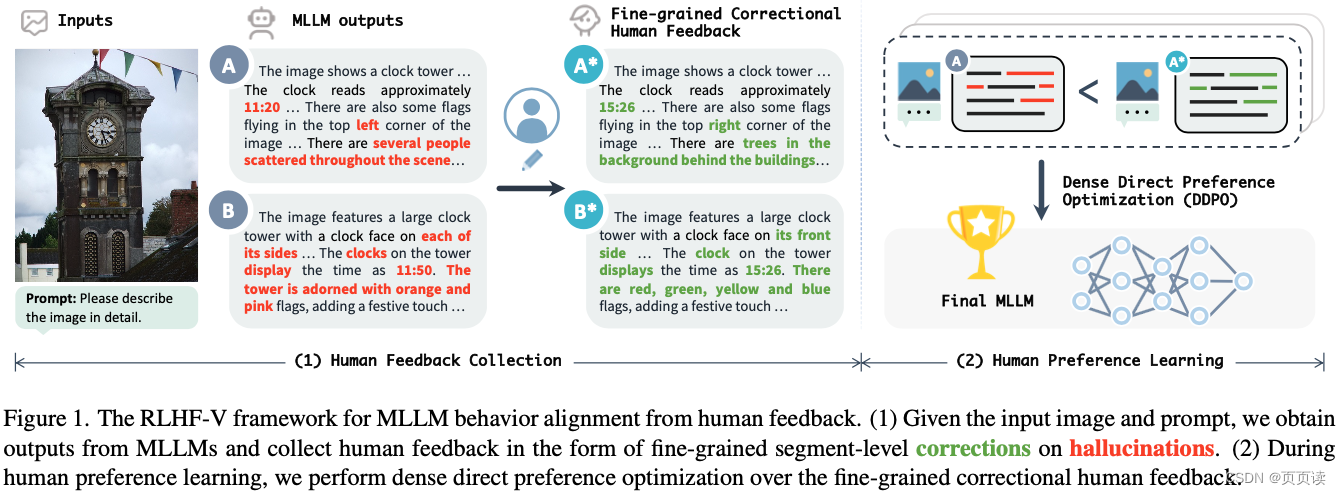
| 主要内容 | RLHF-V框架:论文提出了RLHF-V,一种旨在通过细粒度人类反馈对多模态大型语言模型(MLLMs)行为进行校准的框架,以解决模型产生的幻觉问题,即生成的文本与关联图片不符。这种框架的关键思想是通过人类偏好的形式收集细粒度的反馈,并利用这些反馈来优化模型,从而提高其在处理多模态输入时的可靠性和准确性。 细粒度的人类反馈收集:RLHF-V的一个创新之处在于其收集人类反馈的方式。不同于以往依赖粗粒度或整体排名的反馈,RLHF-V要求人类注释者对模型输出中的具体错误或幻觉部分进行细节级的校正。这种细粒度的反馈不仅提供了更明确的学习信号,而且还避免了因语言多样性或偏见而引起的误导。 密集直接偏好优化(DDPO):为了有效利用收集到的细粒度人类反馈,RLHF-V采用了一种名为密集直接偏好优化(DDPO)的技术。DDPO是一种新的优化策略,专门设计用来处理细粒度的反馈,并能够直接在偏好数据上进行模型训练。通过强化学习方法,DDPO能够精确地调整模型的行为,以减少幻觉产生,增强模型输出的事实依据。 |
| 实验 | 实验设计:为了验证RLHF-V的有效性,作者在五个基准数据集上进行了广泛的实验。这些实验旨在评估RLHF-V在减少幻觉、提高模型可靠性方面的性能。实验包括自动评估和人类评估两部分,分别从模型的准确性、可信度以及与人类偏好的一致性进行评价。 基准数据集:实验涉及的基准数据集包括图像描述、视觉问答和多模态对话等任务,旨在全面评估RLHF-V在多种多模态交互场景下的表现。通过与当前最先进的MLLMs(包括未使用RLHF-V优化的基线模型)进行对比,实验结果展示了RLHF-V在这些任务上的显著改进。 主要结果:实验结果表明,使用RLHF-V框架进行优化的MLLMs在减少幻觉、提高文本与图片一致性方面表现出色。具体而言,与基线模型相比,RLHF-V能够显著降低幻觉率,改善模型输出的可信度和准确性。在人类评估方面,RLHF-V优化后的模型产生的输出更加符合人类的偏好和期望,显示出对复杂多模态输入的更好理解。 效率与性能:除了提升模型性能,RLHF-V还显示出良好的数据和计算效率。即使在有限的标注数据下,RLHF-V也能通过其细粒度的反馈学习机制有效地改进模型行为,证明了其在实际应用中的可行性和效率。 |
| 结论 | RLHF-V通过细粒度的人类反馈校准MLLMs的行为,显著提高了模型的可信度,并在开源MLLMs中取得了最先进的性能。 |
| 阅读心得 | 亮点:
|
【Paper Reading】6.RLHF-V 提出用RLHF的1.4k的数据微调显著降低MLLM的虚幻问题
news2026/2/15 6:38:20
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1526580.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
![[SaaS] 淘宝设计AI](https://img-blog.csdnimg.cn/direct/24f621fe7d1f49a19b816768a2607991.png)
[SaaS] 淘宝设计AI
“淘宝设计AI” 让国际大牌造世界双11超级品牌 超级发布https://mp.weixin.qq.com/s/xFVDARQHxlweKAYG91DtYw下面是一个完整的品牌营销海报设计流程,AIGC起到了巨大作用,但是仍然很难去一步解决这个问题,还是逐步修改的一个过程。
Midjouner…
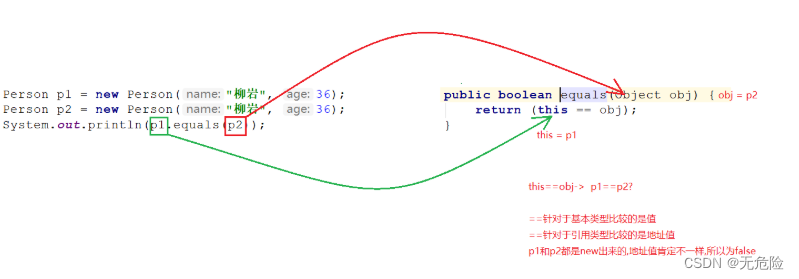
java 面向对象--equals方法
Object 类的使用
类 java.lang.Object是类层次结构的根类,即所有其它类的父类。每个类都使用 Object 作为超类。 Object类型的变量与除Object以外的任意引用数据类型的对象都存在多态引用 method(Object obj){…} //可以接收任何类作为其参数 Person o new Person…

【NTN 卫星通信】 TN和多NTN配合的应用场景
1 场景描述 此场景描述了农村环境,其中MNO (运营商TerrA)仅在城市附近提供本地地面覆盖,而MNO (SatA)提供广泛的NTN覆盖。SatA使用GSO轨道和NGSO轨道上的卫星。SatA与TerrA有漫游协议,允许: 所有TerrA用户的连接,当这些用户不…

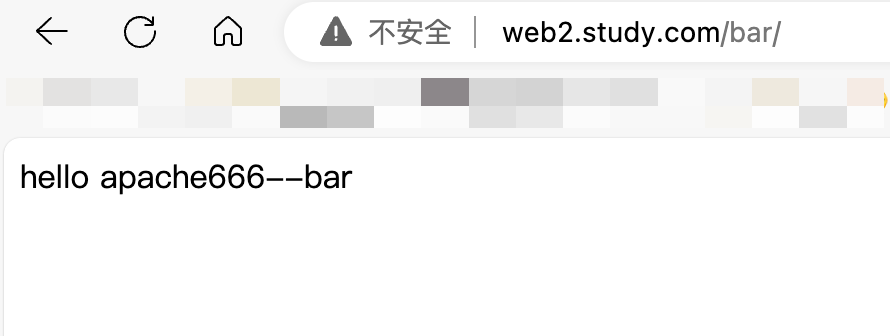
Ingress 基于URL路由多个服务
文章目录 前言一、基于请求地址转发不同应用的pod1.创建一个nginx的pod和一个apache的pod及其各自的service2.创建ingress实现一个地址两个path分别访问nginx和apache3.验证根据域名web2.study.com的两个路径/foo和/bar来访问到不同的pod4.分别在nginx和apache的pod里创建网站目…
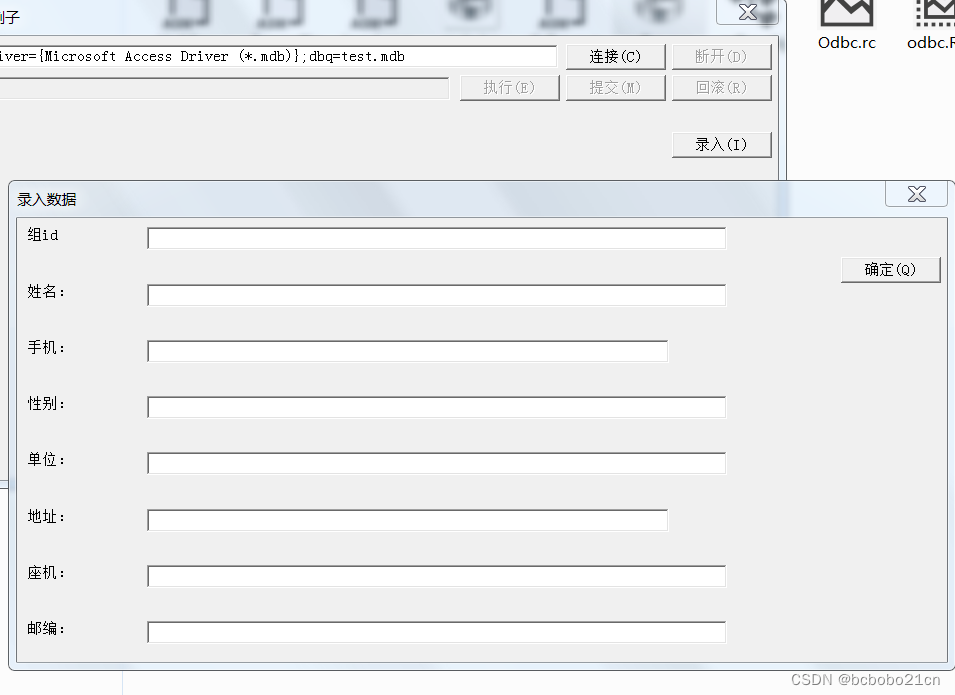
win32汇编弹出对话框
之前书上有一个win32 asm 的odbc例子,它有一个窗体,可以执行sql;下面看一下弹出一个录入数据的对话框;
之前它在.code段包含2个单独的asm文件,增加第三个,增加的这个里面是弹出对话框的窗口过程࿰…
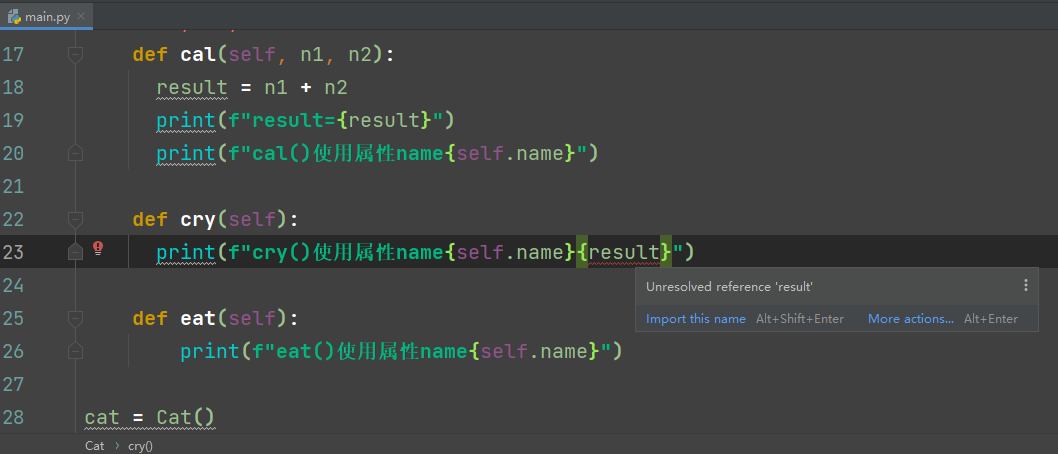
Python--类中作用域
1、在面向对象编程中,主要的变量就是成员变量(属性)和局部变量
class Cat:# 属性name Noneage None# n1, n2, result为局部变量def cal(self, n1, n2):result n1 n2print(f"result{result}")
2、作用域的分类:属性…
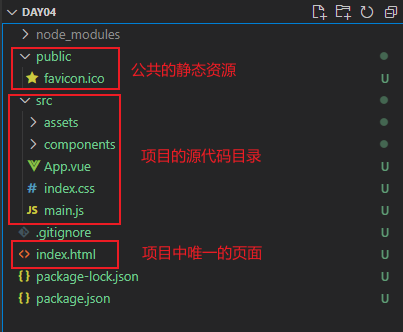
Vue3-03_组件基础_上
单页面应用程序
什么是单页面应用程序
单页面应用程序(英文名:Single Page Application)简称 SPA,顾 名思义,指的是一个 Web 网站中只有唯一的一个 HTML 页面,所有的 功能与交互都在这唯一的一个页面内完…

09|代理(上):ReAct框架,推理与行动的协同
应用思维链推理并不能解决大模型的固有问题:无法主动更新自己的知识,导致出现事实幻觉。也就是说,因为缺乏和外部世界的接触,大模型只拥有训练时见过的知识,以及提示信息中作为上下文提供的附加知识。如果你问的问题超…
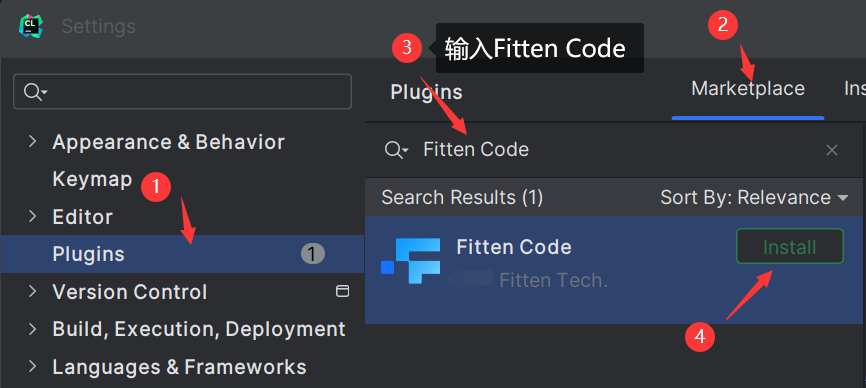
Fitten Code对JetBrains支持再升级,新增7大功能
十科技基于计图框架,推出基于代码大模型的 AI 代码助手 ——Fitten Code,今天,Fitten Code再升级,新增7大功能。特此转载。 「一键开启编程新时代,Fitten Code 对 JetBrains 支持再升级!」 Fitten Code代码…

新火种AI|英伟达GTC大会在即,它能否撑住场面,为AI缔造下一个高度?
作者:小岩
编辑:彩云
英伟达不完全属于AI行业,但神奇的是,整个AI领域都有着英伟达的传说。因为几乎所有的AI巨头都需要英伟达的芯片来提供算力支持。
也正因此,纵使AI赛道人来人往,此起彼伏,…

zabbix企业微信接入结合海螺问问编写的shell脚本
前言
博客懒得写详细了,视频剪的累死了,看视频就好了
白帽小丑的个人空间-白帽小丑个人主页-哔哩哔哩视频 shell脚本
#!/bin/bash
#set -x
CorpID"" #我的企业下面的CorpID
Secret"" #创建的应用那…

阿里云服务器计算型、通用型、内存型各实例计算、存储等性能介绍
在阿里云目前的活动中,属于计算型实例规格的云服务器有计算型c7、计算型c7a、计算型c8a、计算型c8y这几个实例规格,属于通用型实例规格的云服务器有通用型g7、通用型g7a、通用型g8a、通用型g8y,属于内存型实例规格的云服务器有内存型r7、内存…

Linux信号机制(二)
目录 一、信号的阻塞
二、信号集操作函数
三、sigprocmask函数
四、pause函数 五、sigsuspend函数 一、信号的阻塞 有时候不希望在接到信号时就立即停止当前执行,去处理信号,同时也不希望忽略该信号,而是延时一段时间去调用信号处理函数。…
【闲聊】-后端框架发展史
框架,是为了解决系统复杂性,提升开发效率而产生的工具,主要服务于研发人员。 当然,框架还有更深层的作用,框架的沉淀是一种高级的抽象,会将人类的业务逐步抽象为统一标准又灵活可变的结构,为各行…
Java-CAS 原理与 JUC 原子类
由于 JVM 的 synchronized 重量级锁涉及到操作系统(如 Linux) 内核态下的互斥锁(Mutex)的使用, 其线程阻塞和唤醒都涉及到进程在用户态和到内核态频繁切换, 导致重量级锁开销大、性能低。 而 JVM 的 synchr…

影响汇率的因素?fpmarkets澳福总结几个
汇率对于刚刚开始外汇交易的新手来说非常重要,这不是没有道理的,了解汇率如何变化以及怎么变化有助于在外汇交易中获得稳定的利润。那么影响汇率的因素有哪些?fpmarkets澳福总结几个。 任何国家货币的汇率都是由市场决定的。主要的市场因素是…
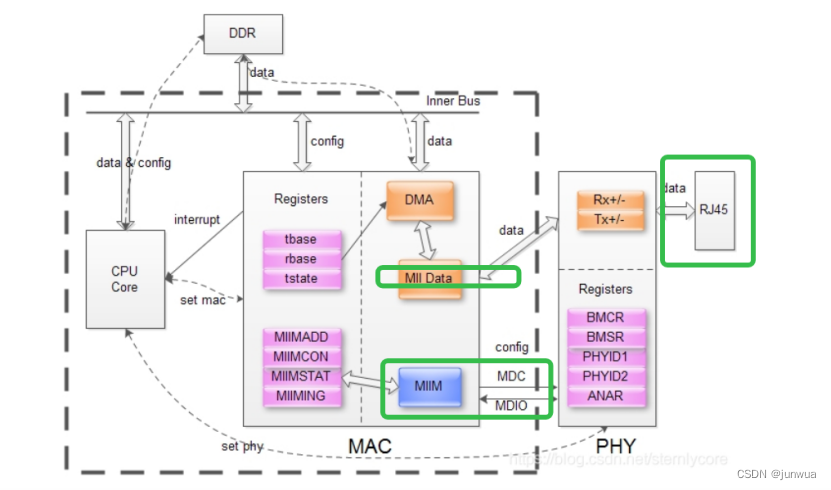
汽车网络基础知识 要点
在以太网开发中,常常会听到一些专业名词,例如PHY,MAC,MII,switch,下面是解释 PHY
PHY 是物理接口收发器,它实现物理层。包括 MII/GMII (介质独立接口) 子层、PCS (物理编码子层) 、PMA (物理介…

高颜值HMI触控界面一出,价值感飙升,瞬间感觉消费不起了。
千万不要觉得用户很理性,其实用户都是“好色之徒”,判断产品价值基本上靠眼睛,颜值高的价格高,质量高,反之质量低,价格低。如果通过精心的高颜值设计,能让你的产品价值感拉满,你不心…

html密码访问单页自定义跳转页面源码
内容目录 一、详细介绍二、效果展示1.部分代码2.效果图展示 三、学习资料下载 一、详细介绍
密码访问单页自定义跳转页面,修改了的密码访问单页,添加了js自定义密码跳转页面。需要正确输入密码才能跳转目标网址。
二、效果展示
1.部分代码
代码如下&…