LangChain + LLM 方案的局限性:LLM意图识别准确性较低,交互链路长导致时间开销大;Embedding 不适合多词条聚合匹配等。
背景
在探索如何利用大型语言模型(LLM)构建知识问答系统的过程中,我们确定了两个核心步骤:
- 将用户提出的问题和知识库中的信息转换成嵌入向量(Embeddings),然后利用向量相似度技术来检索最相关的知识条目。
- 利用LLM来识别用户问题的意图,并对检索到的原始答案进行加工和整合,以提供更加精准和有用的回答。
然而,这种方法在实际应用中遇到了一些挑战:
- 上层应用与模型基础的紧耦合导致灵活性受限。每当需要更换或升级语言模型时,上层的应用逻辑也必须进行大量的调整。在LLM技术迅速发展的今天,由于成本、许可、技术热点和性能等多方面的考量,模型的变更几乎是不可避免的。
- 处理环节的不完善和高开发成本也是一个问题。例如,嵌入向量的存储和搜索、LLM的提示词生成、以及数据链路的处理(包括导入、分片和加工)等,如果这些环节都需要从头开发,将耗费大量的时间和资源。
- 缺乏标准化工具和组件也是一大挑战。为了能够根据不同场景灵活地组装和调整系统,我们需要的是一个像“乐高”一样的标准化组件库。
局限性分析
问题简介
多知识点聚合处理场景下,Embedding-Search 召回精度较低的问题。典型应用范式是:
- 一个仓库有 N 条记录,每个记录有 M 个属性;
- 用户希望对 x 条记录的y 个属性进行查询、对比、统计等处理。
这种场景在游戏攻略问答中很常见,以体育游戏 NBA2K Online2 为例:
# 多知识点——简单查询
Q: 皮蓬、英格利什和布兰德的身高、体重各是多少?
# 多知识点——筛选过滤
Q: 皮蓬、英格利什和布兰德谁的第一位置是 PF?
# 多知识点——求最值
Q: 皮蓬、英格利什和布兰德谁的金徽章数最多?
Embedding 缺陷
原始的 Embedding Search在面对多知识点聚合处理时,存在几个问题:
- 本地知识建立索引时,通常对单个知识点进行 Embedding;通畅不会为不同知识点的排列组合分别制作索引,所有组合都建立索引的开销是巨大的。
- 原始问题直接 Embedding ,和单条知识点的向量相似度比较低。为了避免召回结果有遗漏,就需要降低相似度评分下限(vector similarity score threshold),同时提高召回结果数量上限(top k)。这会产生不好的副效应:
1. 召回结果,有效信息密度大幅降低;score threshold 过高或 top k 过低,会导致某些有效知识点无法命中;反之则很多无效知识点或噪声会被引入。且由于总 token 数量的限制,导致本地知识点被截断,遗漏相似度较低但有效的知识点。
2. 召回结果的膨胀,增加了和 LLM 交互的 token 开销和 LLM 处理的时间复杂度。
3. 给 LLM 的分析处理带来额外噪声,影响最终答案的正确性。
方案分析
想要更加精准的回答问题,需要从两个层面入手:
1. 问题理解—准确识别用户意图
为了准确理解用户的意图,问答系统需要能够:
- 解析用户问题:系统需要通过分析用户的提问来识别他们的意图。
- 制定计划:根据识别的意图,系统需要拆分问题为多个步骤,并为每个步骤选择合适的工具或方法。
- 多轮交互:使用Agents和Chains等工具,系统可以通过多轮对话来逐步明确用户的需求。
在LangChain框架中,Agents 可以帮助系统规划并执行这些步骤。例如,Plan-and-Execute Agents可以用来制定动作计划,而Action Agents则负责执行这些动作。
- HyDE。Precise Zero-Shot Dense Retrieval without Relevance Labels 一文面向 Zero-Shot场景下的稠密检索 ,使用基础模型在训练过程中已经掌握的相关语料,面向用户问题,生成虚构的文档。该文档的作用,不是输出最终结果,而是通过 LLM 对问题的理解能力,生成与之相关的内容。这相当于自动化生成相关性标签,避免外部输入。虚构文档生成后,再使用无监督检索器进行 Embedding;然后将生成的向量在本地知识库中进行相似性检索,寻找最终结果。
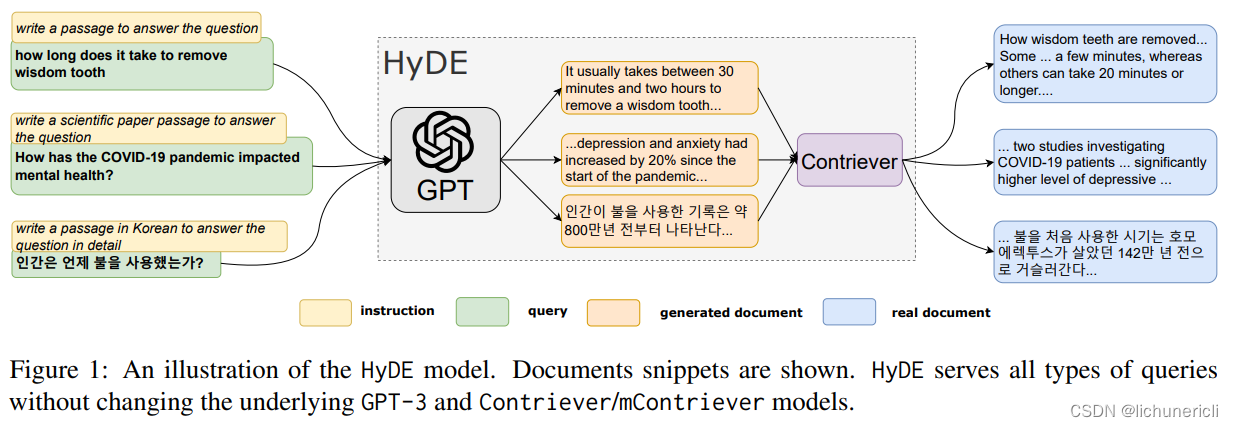
HyDE 要求与用户问题相关的知识,已经存在于 LLM 基础模型中。但专业领域知识,可能本来就是未联网、未公开的;LLM 生成的虚构文档,可能包含很多噪音,所以效果不一定很明显;另外生成文档的额外交互,进一步增加了时间开销。目前,LangChain 提供了 HyDE Chain,LlamaIndex 也提供了类似的能力;大家有兴趣可以尝试,面对中文可能需要自定义 Prompt Template。
- 意图识别。通过 命名实体识别 和 槽位填充 实现。概括就是:
- 在为用户提供服务的预设场景下,细分用户各种意图的类别,定制对应的语义槽,每个槽位可以视为在语义层面体现意图的基本单位。
- 通过深度学习、统计学习,甚至 LLM ,理解用户问题提取语义槽中需要的内容。在基于大语言模型构建知识问答系统一文中给过例子:通过 System Role 告知LLM 需要提取槽位信息,让 LLM通过多轮对话引导用户给出所有槽位信息。还是以游戏攻略为例,玩家咨询球员的打法,那么必须提供:球员姓名,年代(比如2020/2022 年),比赛模式。对应的语义槽可以定义为:
"球员打法" : {
"球员名称" : ____,
"年代" : ____,
"比赛模式": ____,
}在LangChain框架中,Agents的作用是帮助系统规划并执行各种步骤。例如,Plan-and-Execute Agents可以用来制定动作计划,而Action Agents则负责执行这些动作。
HyDE(Precise Zero-Shot Dense Retrieval without Relevance Labels)是一种面向Zero-Shot场景下的稠密检索方法。它使用基础模型在训练过程中已经掌握的相关语料,面向用户问题,生成虚构的文档。这些文档的作用,不是输出最终结果,而是通过LLM(大型语言模型)对问题的理解能力,生成与之相关的内容。这相当于自动化生成相关性标签,避免外部输入。生成虚构文档后,再使用无监督检索器进行Embedding;然后将生成的向量在本地知识库中进行相似性检索,寻找最终结果。
HyDE要求与用户问题相关的知识,已经存在于LLM基础模型中。但专业领域知识,可能本来就是未联网、未公开的;LLM生成的虚构文档,可能包含很多噪音,所以效果不一定很明显;另外生成文档的额外交互,进一步增加了时间开销。目前,LangChain提供了HyDE Chain,LlamaIndex也提供了类似的能力;大家有兴趣可以尝试,面对中文可能需要自定义Prompt Template。
意图识别是通过命名实体识别和槽位填充实现的。概括来说,就是在为用户提供服务的预设场景下,细分用户各种意图的类别,定制对应的语义槽,每个槽位可以视为在语义层面体现意图的基本单位。通过深度学习、统计学习,甚至LLM,理解用户问题提取语义槽中需要的内容。在基于大语言模型构建知识问答系统一文中给过例子:通过System Role告知LLM需要提取槽位信息,让LLM通过多轮对话引导用户给出所有槽位信息。以游戏攻略为例,玩家咨询球员的打法,那么必须提供:球员姓名,年代(比如2020/2022年),比赛模式。对应的语义槽可以定义为球员姓名、年代、比赛模式。
2. 搜索召回——提升精度
将用户的诉求转化为语义槽后,可以较为准确的体现问答意图,这有助于提升搜索命中精度。原始知识点在建立索引时,除了原始的 Embedding 方法,可以做更多优化:
- 增加 关键词、主题词检索。主题词由机构定义和发布的规范词,通常是专有名词或名词短语;主题词检索结果包括检索词的近义词、同义词以及同一概念词的不同书写形式等,通过主题词检索可以很大程度降低漏检和误检。关键词由作者自定义或自动分析提取,通常是可以高度概括该文章主题的,使用关键词搜索可搜出更加明确的主题方向的文章。
- 对相同知识点建立多级索引。同一知识点通常涉及多个维度,建立多级索引可以让其在多维度查询下发挥作用。比如,球员信息涉及:姓名、球队、年龄、进攻、防守、荣誉等多项属性。可以针对多属性分别建立索引,这样可以高效查询指定的属性数据,而不必每次将所有内容全部提取。
- 把原始知识库转化为知识图谱。知识图谱的三元组:实体、属性和关系。实体表示现实世界中的某个事物或对象,属性表示这个事物或对象的特征或属性,关系表示实体之间的关系。知识三元组可以帮助人们更好地理解和组织知识,并支持推理和问题解决。在问答系统中可以通过提示词引导 LLM 从用户的问题中提取知识三元组,然后在知识图数据库中进行查询。
在问答系统中,将用户的诉求转化为语义槽可以显著提升搜索的精度,因为这样可以更准确地捕捉用户的问答意图。在建立知识点的索引时,除了使用原始的Embedding方法,还可以采取以下优化措施:
1. **增加关键词和主题词检索**:
- **主题词**是由权威机构定义和发布的规范词汇,通常包括专有名词或名词短语。主题词检索能够返回包括检索词的近义词、同义词以及同一概念词的不同书写形式等结果,这样可以大大减少漏检和误检的情况。
- **关键词**可以是作者自定义的,也可以通过自动分析提取,它们通常能够高度概括文章的主题。使用关键词搜索可以找到与特定主题方向更为明确相关的文章。
2. **对相同知识点建立多级索引**:
- 同一知识点可能涉及多个维度,因此建立多级索引可以让其在不同维度的查询中都能发挥作用。例如,对于球员信息,可以建立包括姓名、球队、年龄、进攻、防守、荣誉等多项属性的索引。这样,在查询时可以高效地检索到指定的属性数据,而不必每次都提取所有内容。
3. **将原始知识库转化为知识图谱**:
- 知识图谱由实体、属性和关系组成的三元组构成。实体代表现实世界中的事物或对象,属性描述这些事物或对象的特征,关系则表示实体之间的相互联系。知识图谱可以帮助人们更好地理解和组织知识,并支持推理和问题解决。在问答系统中,可以通过提示词引导LLM从用户的问题中提取知识三元组,然后在知识图谱数据库中进行查询。
通过这些优化措施,可以使得问答系统更加高效和精确地响应用户的查询,提供更相关和有用的信息。
解决思路
意图识别和召回优化,属于一体两面,均有助于提升问答系统的精度。搜索层面知识图谱相对于 Embedding 方式,加工成本较高。在遵从奥卡姆剃刀的前提下,有没有什么高性价比的方式来解决这个问题?
笔者想到,意图识别和召回,其实有一个共同点:均可用 关键词/主题词 表示。那么问题可以转变为:
- 关键词/主题词提取:
- 面向知识点,提取的结果作为索引入口。
- 面向问题,提取的结果作为语义槽内容。
- 复用 Embedding 框架。从原始问题和知识点直接 Embedding 后的匹配,转化为对两者提取的关键词进行 Embedding 后再进行匹配。
基于关键词Embedding的入库和搜索的流程图如下所示:

这种方式怎么解决原始 Embedding 存在的几个局限呢?
- 多知识点聚合处理局限。在关键词提取过程中,可以将并列的关键词短语拆分,平铺后分别检索。这样就可以降低 Embedding 的噪音,提高命中精度。最后将生成不同关键词短语召回的结果组合即可。举个例子:
语句:姚明和奥尼尔的内线与三分能力。
关键词提取后,按照从属关系叉乘,得到的结果应该是:
- 姚明内线
- 姚明三分
- 奥尼尔内线
- 奥尼尔三分
- LLM 过度依赖导致的性能开销。首先通过关键词短语召回已经可以大大提升命中精度,所以 不必设置 较低的 score threshold 或者较大的 top k,这本来就过滤了很多无关词条。另外,关键词提取如果可以不依赖于 LLM,而是使用传统的 NLP 技术,那么可以避免和 LLM 的多轮交互,节省了响应时间。这样,对于大量的知识点文档,也可以做关键词提取。
带着这样的思路,下文主要描述关键词提取实现方法和效果。
意图识别和召回优化是提升问答系统精度的两个关键方面。知识图谱虽然相对于Embedding方式在搜索层面具有更高的加工成本,但在遵循奥卡姆剃刀原则(即“如无必要,勿增实体”)的前提下,我们可以探索一些性价比更高的解决方案。
关键词和主题词提取可以作为一种高性价比的解决方案,因为它们既可以作为知识点的索引入口,也可以作为问题的语义槽内容。通过复用Embedding框架,我们可以将原始问题和知识点直接Embedding后的匹配,转化为对两者提取的关键词进行Embedding后再进行匹配。这种方法的核心优势在于:
1. **解决多知识点聚合处理的局限**:
- 在关键词提取过程中,可以将并列的关键词短语拆分,平铺后分别检索。这样就可以降低Embedding的噪音,提高命中精度。最后将生成不同关键词短语召回的结果组合即可。例如,对于语句“姚明和奥尼尔的内线与三分能力”,提取的关键词可以按照从属关系叉乘,得到“姚明内线”、“姚明三分”、“奥尼尔内线”和“奥尼尔三分”。
2. **减少LLM过度依赖导致的性能开销**:
- 通过关键词短语召回已经可以大大提升命中精度,因此不必设置较低的score threshold或者较大的top k,这本身就过滤了很多无关词条。另外,如果关键词提取可以不依赖于LLM,而是使用传统的NLP技术,那么可以避免与LLM的多轮交互,从而节省响应时间。这对于大量的知识点文档来说尤为重要。
基于这样的思路,下文将主要描述关键词提取的实现方法和效果,以及如何通过这种方式提升问答系统的整体性能。
关键词提取
我们的目标是,从无标注文本(零样本)是实现信息抽取(Information Extraction,IE),因为很少涉及人为干预,该问题非常具有挑战性。IE 包含三类任务:
- 实体关系三元组抽取(RE, Relation Extraction )。三元组(triples)即 (主体, 关系, 客体) ,用英文表示为 (Subject, Relation, Object) 。关系抽取,即实体三元组抽取。涉及两件事:
- 识别文本中的主体、客体,即实体识别任务。
- 判断这两个实体属于哪种关系,即关系分类。
- 命名实体识别(NER, Name-Entity Recognition)。又称作专名识别、命名实体,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。指的是可以用专有名词(名称)标识的事物,一个命名实体一般代表唯一一个具体事物个体,包括人名、地名等。
- 事件抽取(EE, Event Extraction)。指的是若干与特定矛盾相关的事物,在某一时空内的运动,从自然语言角度通过“主谓宾”等语义单元体现。事件抽取就是从半结构化、非结构化数据中,识别一个与目标相关的事件的重要元素识别出来。
笔者针对知识问答这样的特定场景,将上述三类任务简化为两个过程:
1. 名词短语提取。即:主语、宾语。通常由名词,和名词的限定词或者修饰词组成。比如:
姚主席如何评价周琦的组织进攻能力?
主语:姚主席
宾语:能力。但真正具有实际意义的是能力的限定修饰词,即“周琦组织进攻能力”。
2. 谓语。体现名词短语之间的事件。比如:评价。在更多场景中是:比较、查询、过滤、统计等,存在动态计算、处理的需求。因此即使忽略谓语,仅通过名词短语的组合也可以获得完备的知识。谓语所代表的事件,可以交给 LLM 处理。
笔者在经过对多种业务场景的分析后,最终萌生出下面的 关键词提取方式:
- 关键词只考虑名词短语,将其作为知识点的索引用于召回。
- 事件体现的是不同知识点的关系。重点在于事件关联者,获取事件关联者对应的语料后,通过 LLM 理解事件进行处理:
- 知识点通常不是按照事件组织的,而是按实体。因此索引建立和关键词抽取,应该以名词短语为主要目标。
- 主语、宾语之间存在并列和限定关系。将限定关系按级联方式处理,同一名词短语内如果存在并列关系则与其他部分叉乘。
将该思路应用到上面的例子中:

如图所示,使用 NLU 的基本处理流程,分析原始问句:
1. 分词
2. 词性标注(Part-Of-Speech Tagging, Penn Chinese Treebank),用于识别名词短语。比如:NR 表示人名、机构、地名等专有名词;NT 表示时间名词,NOI表示汉字顺序颠倒产生的噪声,NN 表示其它类型名词。
3. NER 识别。比如姚,周琦等。
4. 然后还需要考虑语义间的依存关系,确定名词间的关系,比如:
- 并列
- 修饰。比如:“组织进攻能力”
- 从属、限定等等。比如:[周琦, 组织进攻能力]
这样不难得到应该搜索的关键词列表:[姚主席, 周琦, 组织进攻能力]。下面来看看这种思路究竟如何实现,还是分为两大类:LLM、传统 NLP。
基于 LLM 提取
LLM已经天然具备 NLU 和 NLG 的能力,所以做名词短语提取按道理应该手到擒来。业界已经有尝试,比如《Zero-Shot Information Extraction via Chatting with ChatGPT》一文,提出两阶段多轮问答信息提取方式:

在该思想的启发下,笔者使用 langchain 开发了信息提取 Chain,LLM 使用的是 ChatGLM-6B本地部署,提取部分测试片段如下所示:

发现问题了吗:明明是分析张三丰;结果李四和王五怎么冒出来了。要知道,Prompt 已经添加了“不要编造内容”的说明,但无济于事。总体而言,使用 LLM 提取信息效果如下:
- 可以支持部分程度的 NER;对非专业名词、或业务自定义术语识别不好,需要Fine-Tuning。
- 可以提取名词短语,但无法做精确的语义分析,大量测试案例下总是存在不少偏差。
- 即使明确了输出格式,但还是频繁出错。
- 耗时较长。提取 6 条测试案例耗时 12s。
简单而言:不是不能做,但对 LLM 的要求较高;结果不准确、开销也大。
传统 NLP 方法提取
在 LLM 做信息提取,效果不尽如人意的情况下,转而尝试传统 NLP 技术。前面提到的:分词、词性标注、NER 等,业界已经有不少传统 NLP 工具可以使用。
- spacy,测试结果较差,很多语句识别不出来,比如:
“请比较詹姆斯和麦迪的属性”
—— 无法识别任何人名
“詹姆斯、字母哥和杰林.布朗的金徽章有何差异?”
—— 只能识别出布朗,且将 "杰林" 抛弃
- CoreNLP 和 HanLP 均可正确识别。
经过测试后最终选择 HanLP作为基础工具,原因在于:
- 对中文支持好
- 依赖少,开箱即用
- 基础工具完备,接口整洁,便于二次开发
下面基于 HanLP,看看究竟如何解决前文提出的:多知识点聚合查询问题?其核心点在于三步:
- 词性标注
- 名词短语关系分析:修饰、限定、并列等
- 名词短语重新组织:修饰、限定关系级联;并列关系与其他部分叉乘。
关键词提取是信息抽取(IE)的一个重要组成部分,特别是在知识问答场景中。IE通常涉及实体关系三元组抽取(RE)、命名实体识别(NER)和事件抽取(EE)。为了简化这些任务,我们可以将它们归纳为两个主要过程:名词短语提取和谓语分析。
1. **名词短语提取**:这包括识别文本中的主语和宾语,通常由名词及其限定词或修饰词组成。例如,在问句“姚主席如何评价周琦的组织进攻能力?”中,“姚主席”是主语,“周琦的组织进攻能力”是宾语。
2. **谓语分析**:谓语体现了名词短语之间的事件或关系。在许多场景中,谓语可以是“比较”、“查询”、“过滤”、“统计”等,这些可能需要动态计算或处理。即使忽略谓语,仅通过名词短语的组合也可以获得完备的知识。谓语所代表的事件可以交给LLM处理。
在关键词提取方面,我们可以专注于名词短语,将它们作为知识点的索引用于召回。事件则体现了不同知识点的关系,重点在于事件关联者。获取事件关联者对应的语料后,可以通过LLM理解事件进行处理。知识点通常不是按照事件组织的,而是按实体组织的,因此索引建立和关键词抽取应该以名词短语为主要目标。
在处理主语和宾语之间的并列和限定关系时,我们可以将限定关系按级联方式处理,同一名词短语内如果存在并列关系则与其他部分叉乘。例如,在处理“姚主席如何评价周琦的组织进攻能力?”这个问题时,我们可以通过分词、词性标注、NER识别和名词间关系分析,得到应该搜索的关键词列表:[姚主席, 周琦, 组织进攻能力]。
在提取关键词方面,有两种主要方法:基于LLM的提取和传统NLP方法提取。
- **基于LLM的提取**:LLM天然具备NLU和NLG能力,但在实际应用中可能会遇到一些问题,如对非专业名词或业务自定义术语识别不准确,需要Fine-Tuning。此外,即使明确了输出格式,LLM在信息提取时仍可能频繁出错,且耗时较长。
- **传统NLP方法提取**:在LLM效果不佳时,可以转向使用传统NLP技术。例如,HanLP是一个对中文支持良好、依赖少、开箱即用且便于二次开发的基础工具。使用HanLP,可以通过词性标注、名词短语关系分析和名词短语重新组织来解决多知识点聚合查询问题。
通过这些方法,我们可以有效地从文本中提取关键词,从而提高知识问答系统的精度和效率。
名词短语提取与整合
举一个更加复杂的例子,在主语和宾语中添加:并列和修饰关系。首先分词,然后添加词性标注,结果如下:

依存分析
词性有了,下面需要进一步提取句子中单词与单词之间的语法关系,即 依存句法分析;笔者采取 Stanford Dependencies Chinese (SDC) 标准进行分析,并且为了清晰展示,将分析结果转化为 Pandas DataFrame 的形式,如下图所示:

- dep_tok_id,表示当前分词所依赖的中心词的id。比如:“指导” 的中心词 ID是 5。
- dep_rel,表示当前分词和中心词的关系。比如:“指导”和中心词“主席”的关系是 conj ,根据 SDC 标准其含义为“连接”,即指导和主席属于并列关系。类似的,“詹姆斯”、“约基奇”和“张伯伦”都属于并列关系;但是“张伯伦”的中心词是“能力”,关系为 assmod ,即关联关系(修饰限定)。
- sdp_tok_ids 和 sdp_rel。是在依存句法分析的基础上,进一步提供 语义依存分析,旨在分析一个句子中单词与单词之间的语义关系(sdp_rel),并将其表示为图结构的任务。不同于依存句法分析的地方是:图结构中每个节点可以有任意个目标节点。在本例当中,特别需要关注的是:Agt(施事者),Poss(领事者),eCoo(并列关系)等。
根据 DataFrame 中提供的依赖关系,可以直观地获取名词短语:
- 主体:并列关系 [张指导, 姚主席]
- 客体:[三分能力],三分和能力是修饰关系
- 客体还存在三个并列的领事关系(所属关系):[詹姆斯, 约基奇, 张伯伦]
所以实际的客体,应该将并列的领事关系和本体叉乘后平铺,结果就是:
[詹姆斯三分能力, 约基奇三分能力, 张伯伦三分能力]用这三个关键词,Embedding 后去本地知识库搜索就可大大提升命中精度。不过大家如果细心的话可以发现:语义依存分析的结果其实 不准确,比如:
- “指导”一词的 sdp_rel 为 root,即被识别为动词作为语义树的根部
- “和”与“主席”被识别为领事关系
这种语义偏差的原因在于:同一个分词的语义容易产生混淆。比如“指导”既可以作为名词,也可以作为动词。中文多义词和语境比较复杂,导致语义依存分析有不小的概率会出现误判。那么怎么解决这个问题呢?一定要使用有监督训练方式,对基础语义依存分析模型进行 Fine-Tuning吗?一旦涉及有监督,成本就不容小区了。不过幸好:词性标注和依存句法分析,相对语义依存分析,准确率是更高的,所以笔者想到另外一种方式:
基于正确的词性标注,构建出语法树,从 语法角度提取名词短语。
成分句法分析
分析一个句子在语法上的递归构成,在 NLU 领域是经典的 成分句法分析 问题。下面罗列 Chinese Treebank 标准片段,描述对分词单元类型的定义,请大家关注蓝色背景内容。

再次回顾我们要解决的多知识点聚合处理的目标:
- 名词短语(Noun Phrase)提取。即提取 NP;
- 处理好修饰名词短语间的修饰限定问题。比如:DNP 等
- 处理好并列、连接关系。比如:CC 等
- 将修饰关系的名词短语级联;将并列关系的NP和修饰关系的NP 叉乘。
基于该思路,上文提到实例,可以转化为下面的成分句法分析树:

这是典型的树结构:
- 顶层的 NP 有两个:分别是主体和客体。客体是 VP(动词短语),表示主体的施事对象,和施事行为。
- 每个 NP 是一颗子树。变种很多,但核心有三种形式:
- 并列。比如:[张指导, 姚主席]通过明确的连接词 "和" 建立关系;[詹姆斯, 约基奇, 张伯伦] 则通过非终结的标点服务建立关系。
- 堆叠。由修饰词和名词联合形成一个名词短语。
- 从属。通过"的"这样 DEG 词性的结构,明确表示前后两个短语间的从属关系。比如:"三分及抢断",隶属于"詹姆斯"。
这样来看,NP 的提取非常简单,通过递归方式对三种基础形式的树结构进行识别即可,提取时注意区分:
- 主体、客体。
- NP 子树中各个单元的组织关系。并列单元在和其它单元组合时,需要叉乘输出;其它邻接单元直接合并即可。
在上述算法下,样例中提取的名词短语列表最终如下所示:

- 第一个列表为主语列表
- 第二个列表为平铺后的宾语列表
- 在性能方面,单条语句处理方式是 5ms;之前基于 LLM 的方式处理 6 条语句,需要 12s;性能相差数百倍。
至此,已经介绍完笔者关于关键词提取的基本思路,完整的处理流程如下图所示:

名词短语提取与整合是信息抽取中的关键步骤,特别是在处理复杂句子时。以下是一个复杂例子的分析过程:
1. **分词与词性标注**:首先对句子进行分词,然后为每个分词添加词性标注。例如,在处理“张指导、姚主席如何评价詹姆斯、约基奇、张伯伦的三分及抢断能力?”这个问题时,我们首先进行分词和词性标注。
2. **依存分析**:接下来,进行依存句法分析,以提取句子中单词与单词之间的语法关系。例如,使用Stanford Dependencies Chinese (SDC) 标准进行分析,并将结果转化为Pandas DataFrame的形式,以便于查看和分析。
3. **成分句法分析**:为了解决语义依存分析中可能出现的误差,可以基于正确的词性标注构建语法树,从语法角度提取名词短语。成分句法分析可以帮助我们理解句子在语法上的递归构成。
4. **提取名词短语**:根据成分句法分析的结果,提取名词短语。例如,在上述例子中,我们可以提取出以下名词短语列表:
- 主语列表:[张指导, 姚主席]
- 宾语列表:[詹姆斯三分能力, 约基奇三分能力, 张伯伦三分能力]
5. **性能考量**:在性能方面,基于传统NLP方法的处理速度远快于基于LLM的方法。例如,单条语句的处理时间为5ms,而之前基于LLM的方法处理6条语句需要12s,性能相差数百倍。
通过以上步骤,我们可以有效地提取和整合名词短语,从而提高知识问答系统的精度和效率。完整的处理流程包括分词、词性标注、依存分析、成分句法分析和名词短语提取。
应用效果
关键词提取实现后,配合前文提到的召回方法,应用到文章开始的几个示例问题,结果如下所示:



最后汇总笔者提出的解决多知识点聚合处理问题的方案:
- 基于传统 NLP 的成分句法分析,提取名词短语;再通过短语间的依存关系,生成关键词列表
- 从完整语句的 Embedding,切换为关键词 Embedding:
- 知识库构建时。基于单知识点入库,入库时提取关键词列表进行 Embedding,用于检索。
- 查询时。对用户的问题提取关键词列表进行 Embedding 后,从本地知识库命中多条记录。
- 将单问句中的多知识点拆解后检索,将召回的多条记录交付给 LLM 整合。
该方法的优势在于:
- 相比传统 Embedding,大幅提升召回精准度。
- 支持单次交互,对多知识点进行聚合处理。而不必让用户,手动分别查询单个知识点,然后让 LLM 对会话历史中的单个知识点进行汇总。
- 使用传统 NLP 在专项问题处理上,相比 LLM 提供更好的精度和性能。
- 减少了对 LLM 的交互频次;提升了交付给 LLM 的有效信息密度;大大提升问答系统的交互速度。
笔者提出的解决多知识点聚合处理问题的方案可以概括为以下几个步骤:
1. **基于传统NLP的成分句法分析**:利用成分句法分析从用户问题中提取名词短语,然后通过分析短语间的依存关系,生成关键词列表。
2. **从完整语句的Embedding切换到关键词Embedding**:在知识库构建时,对单个知识点进行入库,同时提取关键词列表进行Embedding,以便于后续的检索。在查询时,对用户的问题进行关键词提取和Embedding,然后从本地知识库中检索出多条相关记录。
3. **多知识点拆解与检索**:将用户单次提问中的多个知识点拆解开来分别进行检索,然后将召回的多条记录交付给LLM进行整合和回答。
这种方法的优势主要体现在以下几个方面:
- **提升召回精准度**:与传统的方法相比,基于关键词Embedding的检索方式能够大幅提升召回的精准度。
- **支持多知识点聚合处理**:用户可以在单次交互中提出包含多个知识点的问题,而不需要分别查询单个知识点,然后由LLM对会话历史中的信息进行汇总。
- **专项问题处理精度和性能**:在处理特定问题时,传统NLP方法相比LLM提供了更好的精度和性能。
- **减少LLM交互频次**:通过减少与LLM的交互次数,提升了交付给LLM的有效信息密度,从而大大提升了问答系统的交互速度。
综上所述,笔者的方案通过结合传统NLP技术和关键词Embedding,有效地解决了多知识点聚合处理的问题,提高了系统的整体性能和用户体验。
总结
LLM 的出现,推动下游应用激烈变革,各种探索如火如荼地展开。但在热潮背后,我们还有一些细节问题需要仔细对待。LLM 的未来是伟大的,甚至可能是迈向 AGI 的重要里程碑;但现在并不能宣判传统 NLP 技术的死亡。
本文提供了传统 NLP 和 LLM 结合的一种可能,通过用户问题和本地知识库关键词提取,能较好的解决 Embedding 精度缺失,以及 HyDE、LLM NLU的精度和性能问题。实现单轮对话,对多知识点的聚合处理。后续将继续探索 LLM 和传统技术的角色分工,进一步提升综合收益。
大致方案罗列:
- 基于传统 NLP 的成分句法分析,提取名词短语;再通过短语间的依存关系,生成关键词列表
- 从完整语句的 Embedding,切换为关键词 Embedding:
- 知识库构建时。基于单知识点入库,入库时提取关键词列表进行 Embedding,用于检索。
- 查询时。对用户的问题提取关键词列表进行 Embedding 后,从本地知识库命中多条记录。
- 将单问句中的多知识点拆解后检索,将召回的多条记录交付给 LLM 整合。
该方法的优势在于:
- 相比传统 Embedding,大幅提升召回精准度。
- 支持单次交互,对多知识点进行聚合处理。而不必让用户,手动分别查询单个知识点,然后让 LLM 对会话历史中的单个知识点进行汇总。
- 使用传统 NLP 在专项问题处理上,相比 LLM 提供更好的精度和性能。
- 减少了对 LLM 的交互频次;提升了交付给 LLM 的有效信息密度;大大提升问答系统的交互速度。
1.3 意图补充、修复、改写
从【【text2sql】基于ChatGPT打造'中文自动转SQL'产品(第一部分)】贴一些,从聊天机器人侧,query还需要做的一些功能点:
- 引导能力,槽位补充能力
-
- 用户:我想查一下电量;Bot: 好的,请问您想查的时间范围、空间范围,和分项是?用户:查上个月的整个园区的吧;Bot:好的,那请问是要查照明、空调、动力的还是其他类型的耗电量?用户:就查询各个分项的,和总体的都查询。Bot:好的,那我复述一下,您希望查询,"照明、空调、动力的还是其他类型的耗电量,以及总体耗电量,时间范围是上个月,空间范围是整体园区",请问是吗?用户:是的/没问题/对。
- 引导用户表述完整,查询要素,指标、维度、范围
- 槽位修复能力
- 比如:“好的,查询目标设置为查询温度,请问查询哪个空间的温度?”
-
- 指代消除,解析能力
- 澄清,它、这等指代词的具体含义
- 改写
- 改写模块其实非常关键,数据库的存储有特定的形式,但是用户不会按照你的底层数据结构去写,例如,用户不见得会输入和平精英,而是吃鸡,数据库里可不见得会存吃鸡对吧
从【小虫飞飞:基于大语言模型构建知识问答系统】类似与将chatgpt变成一个NPC进行对话,用来回收+修复槽位
改写模块包括(来自【R&S[21] | 搜索中涉及的算法问题】):
- 同义词改写。上面的吃鸡就要改写为和平精英,这个需要通过同义词挖掘等方式去构造词典实现。
- 拼音改写。数据库是罗密欧与朱丽叶,但是用户输入的是罗密欧与朱莉业,拼音改写其实颇为常见,用户经常由于找不到需要的结果或者不知道应该需要哪个,于是直接输入后开始搜索。
- 前缀补全。非常常见,用户输入射雕,射雕英雄传就要出了,这个一般的方法也是构造词典,另外有一个很重要的需要了解的就是前缀树,这个能让你查询的时间非常低的水平(只和query长度本身有关)。
- 丢词和留词。结合上述关键词提取和命名实体识别完成,有些不必要的词汇需要被删除,例如“李小璐到底怎么了”,整个句子只有李小璐是关键词,其他词如果也通过and逻辑召回,就没有信息召回了,这时候其实可以直接删除或者将降级到or逻辑。留词和丢词相反,丢词如果是做减法,留词就是做加法。
- 近义词召回。这个召回不是从数据库中召回,而是召回近义词,具体的方法是通过embedding方法转化词汇,然后通过ball tree、simhash的方式召回与之意思相近的词汇,该模式虽然比较激进,但是能一定程度增加召回,有一定效果。
1.4 多轮对话意图继承能力
-
- 意图继承能力
- 多轮对话之间的意图继承
- 意图继承能力
而多轮的根本难题在于,如何把关键信息保留并在合适的时间取出并使用。目前的大家可能用的比较多的是直接拼接历史对话,这点并非不好,凭借大模型的能力确实能做到很高程度的多轮对话,但实际上,我们还是可以用很多思路(来自:提升大模型系统体验的一些思路):
- 简单的,可能并不需要考虑模型回复的内容,只需要拼接用户query。
- 单独构造DM模块,结合NER做槽位继承。
- 参考科研界的一些做法,做更加抽象的矩阵DM,然后配合大模型计算。
1.5 过长提问的总结
-
- 过长提问的总结
- 比较长的提问可以通过LLM进行归纳与总结
- 过长提问的总结
1.6 拒绝回复
来自【提升大模型系统体验的一些思路】
拒绝回复其实很多场景会应用到,例如在面对用户提问的内容并不是目前我们预期支持的领域(客服场景问天气),或者用户所问出现观点类(如何看待俄乌问题)、黄反类问题(这个就不用我举例了吧)、大模型安全(query中带有诱导性错误)时,再就是知识库为空的情况,我们就需要进行拒绝,并给用户一些回复,让用户不至于那么不舒服。常见的策略一般有这些:
- 一句写死的回复:“哎呀,这方面的问题我还不太懂,需要学习下”。
- 用大模型生成,例如借助prompt引导生成一些安抚性的回复,“对不起,你问的[]问题,我好像还不太懂。你可以试试问问别的”。
- 使用推荐问或者追问的策略。(你是否在找以下几个问题XX;你描述的我好像不太懂,能再补充补充吗)
其实也可以看到,也不见得非得用大模型,有时候写死或者做一些推荐问疑似问(前沿重器[12] | 美团搜索引导技术启示),好像也可以。