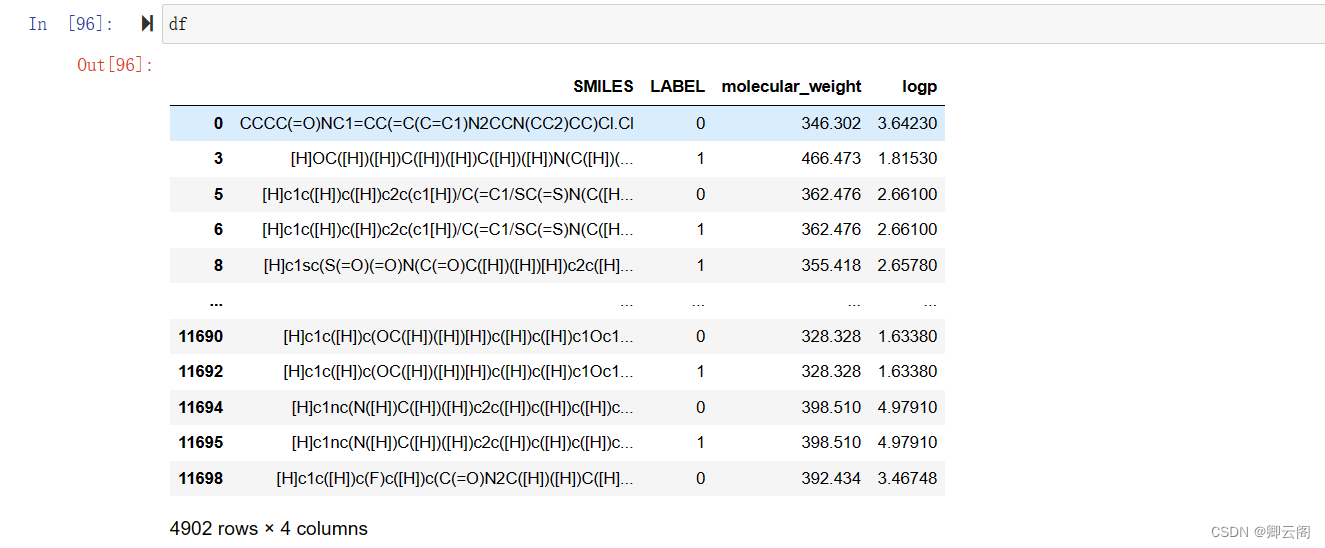
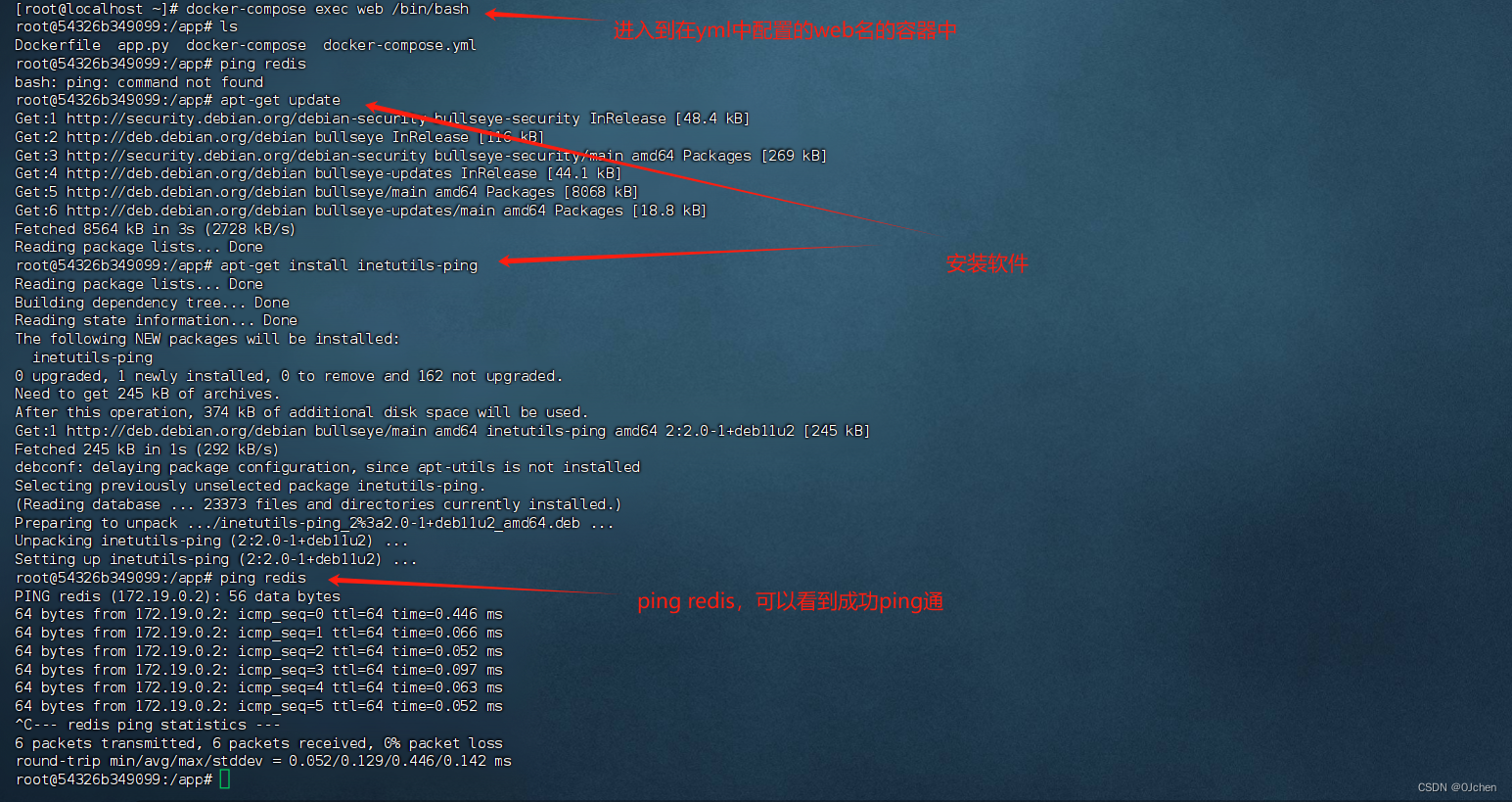
此为看完视频What is a Vector Database?后的笔记。
作者首先对数据库做了分类,其中RTweb表示real time web app。
然后对用例做了分类,最后一个就是适合于AI的近似搜索。
好处,包括灵活性,可扩展性和性价比。
本视频最重要的是讲向量数据库的特征,即vector和embedding。
这两个特征是配合工作的。
vector就是向量,就是数组,就是一组数,就是一组浮点数。可以看OpenAI的例子。
在OpenAI的文档中,embedding的定义为:
Get a vector representation of a given input that can be easily consumed by machine learning models and algorithms.
获取给定输入的向量表示,机器学习模型和算法可以轻松使用该表示。
vector和embedding经常互换使用,但既然这里分开了,也可以说下他们的细微区别。
vector是名词,是一组数;embedding是动词,是向量化的过程,或将数据表示为向量的技术,以捕获有意义的信息、语义关系或上下文特征,按照(What are vector embeddings?)的说法,虽然嵌入和向量可以在向量嵌入的上下文中互换使用,但“嵌入”强调以有意义和结构化的方式表示数据的概念,而“向量”指的是数字表示本身。
在OpenAI的例子中,输入一个对象(如文本),OpenAI返回向量,然后你可以存入向量数据库中,如Oracle 23c或SingleStore。
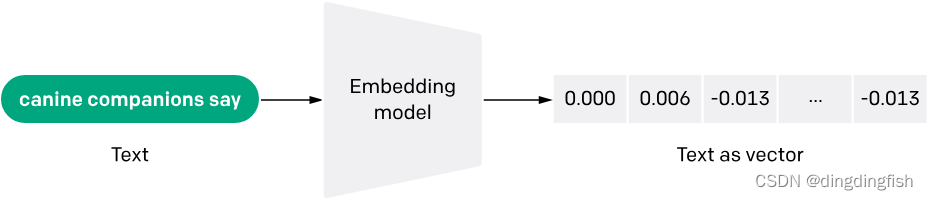
如果你订阅了OpenAI,可以试下这个通过API实现embedding的例子。
最后,说下好处。
- 灵活性:关系型,文档,Graph等,任何类型的数据都可以向量化
- 可扩展性:这里指的是数据的扩展/增长
- 性价比:指搜索性能很好