day9:
- 28. 实现 strStr()
- KMP的主要应用:
- 什么是前缀表:
- 前缀表是如何记录的:
- 如何计算前缀表:
- 构造next数组:
- 1、初始化
- 2、处理前后缀不相同的情况
- 3、处理前后缀相同的情况
- 代码:
- 459.重复的子字符串(先不做了,)
28. 实现 strStr()
题目链接
状态:KMP不太懂
文档:programmercarl.com
思路:
KMP的经典思想就是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
KMP的主要应用:
KMP主要应用在字符串匹配上。
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
什么是前缀表:
next数组就是一个前缀表(prefix table)
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
举个例子:(在文本串中查找是否存在模式串)
文本串:aa b aa baafa — 模式串:aa b aa f
可以看出,文本串中第六个字符b 和 模式串的第六个字符f,不匹配了。如果暴力匹配,发现不匹配,此时就要从头匹配了。
但如果使用前缀表,就不会从头匹配,而是从上次已经匹配的内容开始匹配。
文本串中的aabaa已经和模式串中的aabaa匹配好了,只有最后一个字符不匹配
那么就要从上次已经匹配好的内容开始匹配,上次和模式串中的 f 前的aa匹配好了的是文本串中的b,所以从模式串中第三个字符b继续开始匹配。
前缀表是如何记录的:
首先要知道前缀表的任务是当前位置匹配失败,找到之前已经匹配上的位置,再重新匹配,此也意味着在某个字符失配时,前缀表会告诉你下一步匹配中,模式串应该跳到哪个位置。
那么什么是前缀表:记录下标 i 之前(包括i)的字符串中,有多大长度的相同前缀后缀。
如何计算前缀表:
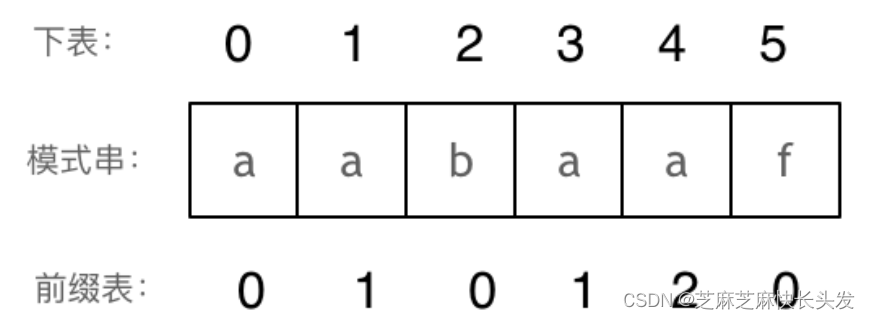
注意字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
可以看出模式串与前缀表对应位置的数字表示的就是:下标 i 之前(包括i)的字符串中,有多大长度的相同前缀后缀。
找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少。
为什么要前一个字符的前缀表的数值呢,因为要找前面字符串的最长相同的前缀和后缀。所以要看前一位的 前缀表的数值。
前一个字符的前缀表的数值是几, 所以把下标移动到下标为几的位置继续匹配。
next数组既可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。
构造next数组:
我们定义一个函数getNext来构建next数组,函数参数为指向next数组的指针,和一个字符串。 代码如下:
void getNext(int* next, const string& s)
构造next数组其实就是计算模式串s,前缀表的过程。 主要有如下三步:
- 初始化
- 处理前后缀不相同的情况
- 处理前后缀相同的情况
1、初始化
定义两个指针 i 和 j,j 指向前缀末尾位置,i 指向后缀末尾位置。
然后还要对next数组进行初始化赋值,如下:
int j = -1;
next[0] = j;
next[i] 表示 i(包括i)之前最长相等的前后缀长度(其实就是j)
2、处理前后缀不相同的情况
因为j初始化为-1,那么i就从1开始,进行s[i] 与 s[j+1]的比较。
为什么是 i 和 j+1 去比较呢?既然前缀表统一减一了,那么回退的时候也会多回退1,所以就要在 j 上下功夫了,让 j+1,每次比较的时候都比较 j 的后一位。
遍历模式串s的循环下标i 要从 1开始,代码如下:
for (int i = 1; i < s.size(); i++) {
如果 s[i] 与 s[j+1]不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回退。
怎么回退呢?
next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度。
那么 s[i] 与 s[j+1] 不相同,就要找 j+1前一个元素在next数组里的值(就是next[j])。
所以,处理前后缀不相同的情况代码如下:
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
3、处理前后缀相同的情况
如果 s[i] 与 s[j + 1] 相同,那么就同时向后移动i 和j,说明找到了相同的前后缀,
所有情况处理结束后,还要将j(前缀的长度)赋给next[i], 因为next[i]要记录相同前后缀的长度。
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j;
最后整体构建next数组的函数代码如下:
void getNext(int* next, const string& s){
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
代码:
class Solution {
public:
//创建next数组 整体-1
void getNext(int* next,string& s)
{
//初始化(后缀i,前缀j,next数组)
int j = -1;
next[0] = j;
//i不能=0,因为还要和j进行比较
for(int i=1;i<s.size();i++)
{
//前后缀不相等
while(j >= 0 && s[i] != s[j+1])
{
//j向前一个next的值进行回退
j = next[j];
}
//前后缀相等
if(s[i] == s[j+1])
{
j++; //j向前走一位,同时i也向前走一位
}
//更新next值
next[i] = j; //因为j已经++了,所以已经表示相对应的串的长度了
}
}
int strStr(string haystack, string needle) {
if(needle.size() ==0)
{
return 0;
}
int next[needle.size()];
getNext(next,needle); //获取needle的next数组
//在文本串s里 找是否出现过模式串t
int j = -1; //因为next数组里记录的起始位置为-1
//i是从0开始的,因为要从头比
for(int i = 0;i<haystack.size();i++)
{
//如果不匹配
while(j >= 0 && haystack[i] != needle[j+1])
{
//j>=0才行,不然next[j]就是无效数据了
j = next[j];
}
//匹配上了
if(haystack[i] == needle[j+1]) j++;
if(j == needle.size()-1) //比的是j+1 j++后就是j+1的位置
return (i-needle.size()+1);
}
return -1;
}
};