目录
摘要
Abstract
文献阅读:耦合时间和非时间序列模型模拟城市洪涝区洪水深度
现有问题
提出方法
创新点
XGBoost和LSTM耦合模型
XGBoost算法
编辑
LSTM(长短期记忆网络)
耦合模型
研究实验
数据集
评估指标
研究目的
洪水深度预测
实验结果
LSTM变体
Bidirectional LSTM(双向LSTM)
GRU(门循环控制单元)
Seq2seq模型
编码器-解码器(encoder-decoder)架构
Seq2seq训练
双向LSTM对乘客数量进行预测
摘要
本周阅读的文献,提出了一种基于XGBoost和LSTM算法的城市洪泛区洪水模拟耦合模型,该模型强调降雨和雨后洪水的全过程,利用降雨数据构,通过XGBoost算法构建非时间序列回归模型来模拟和预报洪水深度,降雨后,通过LSTM算法利用时间序列原理,在降雨后进行持续预测。有效的预测洪水深度,解决了雨后洪水深度预测问题。双向LSTM通过两层LSTM可以提供更丰富的上下文信息,将前向和后向的输出进行拼接得到最终结果,可以获得更全面的序列信息。GRU在LSTM的基础上简化门控即减少了参数,从而有效降低过拟合的风险,减小了时间、空间复杂度的负担。Seq2seq模型常用的就是LSTM或者GRU作为编码-解码结构,用于通过一个序列生成另一个序列,且两者之间不等长,常用于机器翻译等。
Abstract
The literature read this week proposes a coupled model for urban flood simulation based on XGBoost and LSTM algorithms. The model emphasizes the entire process of rainfall and post rainfall floods, and uses rainfall data to construct a non time series regression model using XGBoost algorithm to simulate and predict flood depth. After rainfall, the LSTM algorithm utilizes the principle of time series to make continuous predictions after rainfall. Effectively predicting flood depth solves the problem of predicting flood depth after rain. Bidirectional LSTM can provide richer contextual information through two layers of LSTM, concatenating forward and backward outputs to obtain the final result, which can obtain more comprehensive sequence information. On the basis of LSTM, GRU simplifies gating by reducing parameters, effectively reducing the risk of overfitting and reducing the burden of time and space complexity. The Seq2seq model commonly uses LSTM or GRU as the encoding decoding structure, which is used to generate another sequence from one sequence, and the two are not of equal length, commonly used in machine translation, etc.
文献阅读:耦合时间和非时间序列模型模拟城市洪涝区洪水深度
Coupling Time and Non-Time Series Models to Simulate the Flood Depth at Urban Flooded Area | Water Resources Management
2023 Water Resources Management
现有问题
造成城市洪水的主要原因是短时强降雨,因此,目前许多非时间序列研究都倾向于使用降雨数据作为驱动,然而这种方式面临着雨后洪水预报的实现和精度要求的问题。短时强降雨后仍存在的洪水潜在后果严重,并且雨后时期,城市洪水的关键因素降雨不再影响洪水的消退过程,意味着洪水从高位到干枯的过程是一个受淹没区地理结构影响的完整时间序列。
提出方法
提出XGBoost回归模型和LSTM回归模型相结合的方法对郑州市部分洪涝区进行洪水深度预测。其中极端梯度增强(XGBoost)算法在多维非时间数据处理和回归预测方面具有高精度和高效率的优点,LSTM算法在时间序列数据的分析和预测方面表现出很大的优势。
创新点
- 考虑雨后洪水的存在,将洪水过程分为降雨和雨后两个阶段。
- 通过XGBoost和LSTM模型,对洪水的整个过程进行了完整的分阶段预测。
- 利用了非时间序列和时间序列模型的优点,弥补了使用单一模型的缺点,提高了结果的准确性。
XGBoost和LSTM耦合模型
XGBoost算法
XGBoost(eXtreme Gradient Boosting)又叫极度梯度提升树,是一种用于大规模并行化的提升树集成算法,针对分类或回归问题,是目前最快、集成最好的决策树算法。在相同配置和场景仿真下,XGBoost算法在保证仿真结果准确性的同时,效率比同类算法快数倍。XGBoost算法由多个相关CART树共同决定,即下一决策树的输入样本将与前一决策树的训练和预测结果相关联。XGBoost模型的预测输出结果是多个基础模型结果的和
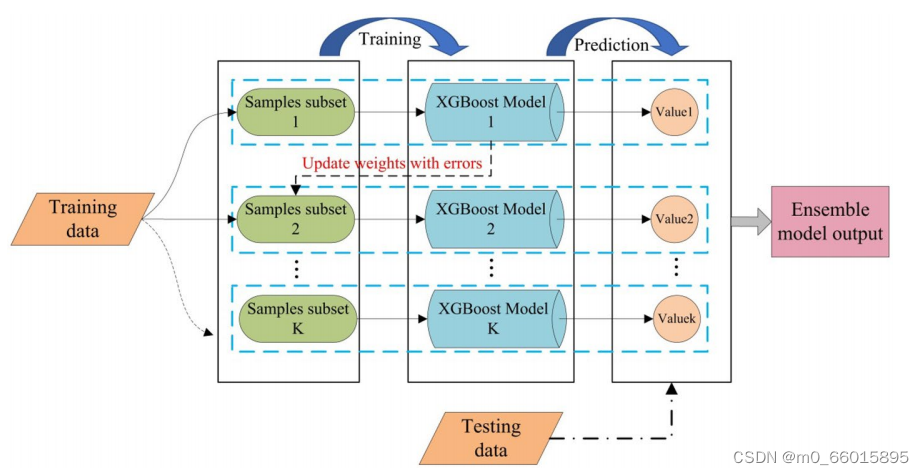
XGBoost算法的结构
它是采用多个基学习器,每个基学习器都比较简单。基本思路就是不断生成新的树,每棵树都是基于上一颗树和目标值的差值来进行学习,从而降低模型的偏差。最终模型结果的输出如下:,即所有树的结果累加起来才是模型对一个样本的预测值。那在每一步如何选择/生成一个较优的树,那就是由目标函数来决定。

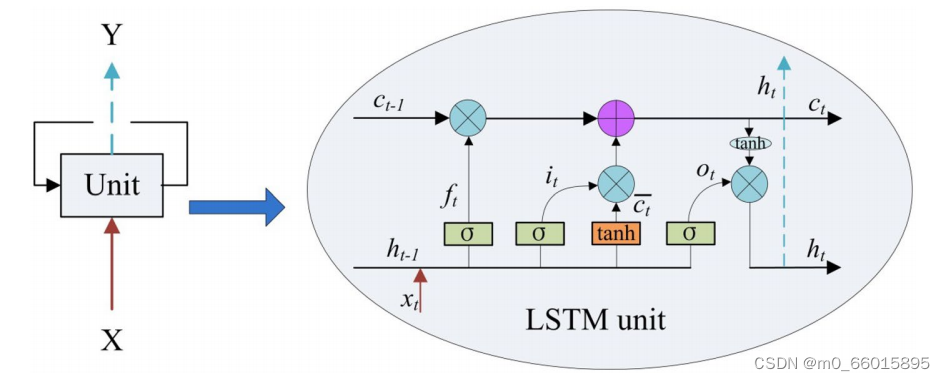
LSTM(长短期记忆网络)
LSTM网络依靠三个门(输入门、输出门
和遗忘门
)来控制信息流进出允许梯度流过长序列的记忆块,在LSTM中,第一阶段是遗忘门,遗忘层决定哪些信息需要从细胞状态中被遗忘,下一阶段是输入门,输入门确定哪些新信息能够被存放到细胞状态中,最后一个阶段是输出门,输出门确定输出什么值,具有很强的适应时间序列的长(静态)期和短(循环)期动态特性的能力

耦合模型
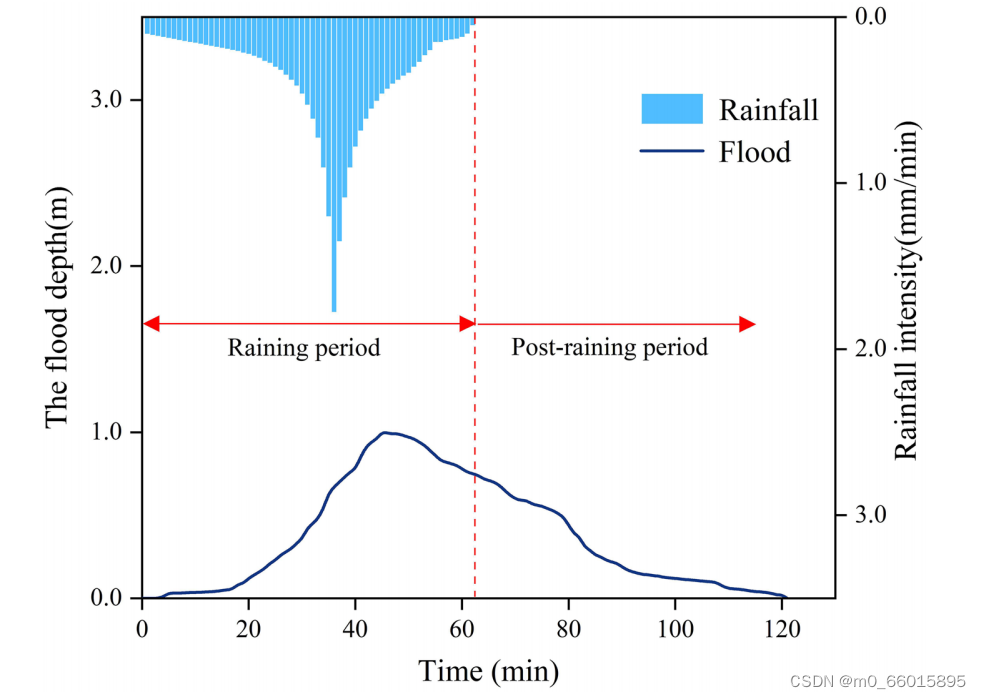
降雨是降雨期洪水的主导驱动因素,因此为了提高效率,可以利用降雨数据来模拟和预报洪水深度。相反,在降雨后没有更新数据的情况下,XGBoost模型的可操作性和可信度下降。因此采用LSTM算法,利用时间序列原理,在降雨后进行持续预测。以雨致洪水为例,将其分为降雨期和雨后两个不同时期,以降雨结束点作为洪水过程的分割点。
研究实验
数据集
13个降雨事件和洪水数据构成了本研究的原始数据库。降雨数据和洪水数据采集时间间隔不同,需要对数据进行处理以满足需求。基于降水观测站数据,采用空间插值的Kriging方法对降水过程进行线性插值。将线性插值方法应用于洪水数据处理,使采集的降雨和洪水数据的时间粒度统一到2分钟级别。
评估指标
选取平均相对误差(Mean Relative Error)、Nash-Sutcliffe效率系数(Nash-Sutcliffe Efficiency coefficient)和合格率(合格率MRE、NSE和QR)作为模型的定量评价指标。和
分别为预测值和实测值;
为测量值的平均值;c和n分别为合格样品数量和总样品数量。较低的MRE值和较高的NSE和QR值表明了该模式的性能优势。
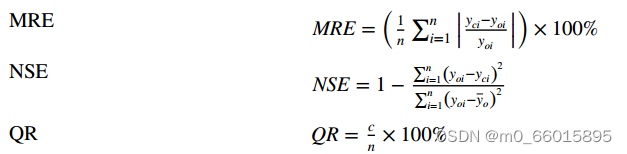
研究目的
- 将洪涝的过程分为降雨期和雨后期两个阶段;
- 利用降雨数据,利用XGBoost算法构建非时间序列回归模型预测降雨期洪水深度;
- 基于XGBoost回归模型预测的数据,采用LSTM算法建立时间序列模型,预测雨后汛期洪水深度;
- 利用XGBoost和LSTM算法的耦合模型预测不同回归期降雨淹没区的洪水深度。
洪水深度预测
1. 降雨期间的洪水深度预测
利用XGBoost算法建立非时间序列回归模型,预测洪水深度。该模型以降雨资料为预测因子,将降雨期的洪水过程划分为若干段。模型输入数据包括被淹地区、t时刻的降雨强度和累积平均降雨量,以及t+1时刻的洪水深度,数据被存储为一组数据向量,并加载到XGBoost回归模型中。选取前10个降雨洪水数据作为模型的训练数据,剩余数据用于检验模型的预测性能。采用基于控制变量法的连续优化方法确定XGBoost模型的主要参数迭代次数、学习率和最大深度,利用对各淹没点建立的训练好的XGBoost回归模型对降雨期洪水进行模拟。
2. 降雨后洪水深度预测
降雨数据不再适用于降雨后期的洪水预测,降雨后的洪水深度数据为不受外界影响的时间序列数据,因此,利用LSTM神经算法构建时间序列模型,对雨后地面洪水进行持续预测。输入窗口的大小和隐藏层的数量等参数需要人工确定,其余剩余参数通过内部函数优化选择。输入窗口的大小为a×b。由于只考虑一维的洪水深度数据,所以将b定义为常数1。为了达到最佳的预测效果,采用网格搜索方法对参数进行优化。同样,将前10次降雨事件下的洪水深度数据作为训练数据,将最后一次降雨事件下的洪水深度数据作为测试数据。
对比研究
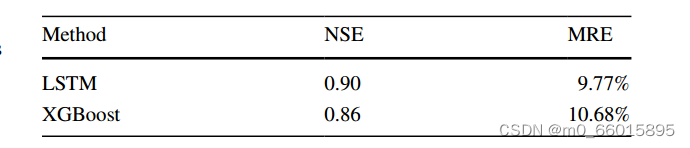
为了验证模型的有效性,将LSTM模型与XGBoost回归模型进行比较,将相同的数据应用于XGBoost模型和LSTM模型。如表所示,经验证的三个降雨事件的LSTM和XGBoost模型得到的平均NSE分别为0.90和0.86。LSTM模型的MRE值较低,表明LSTM模型对雨后期城市洪水深度的预测精度更高。
实验结果
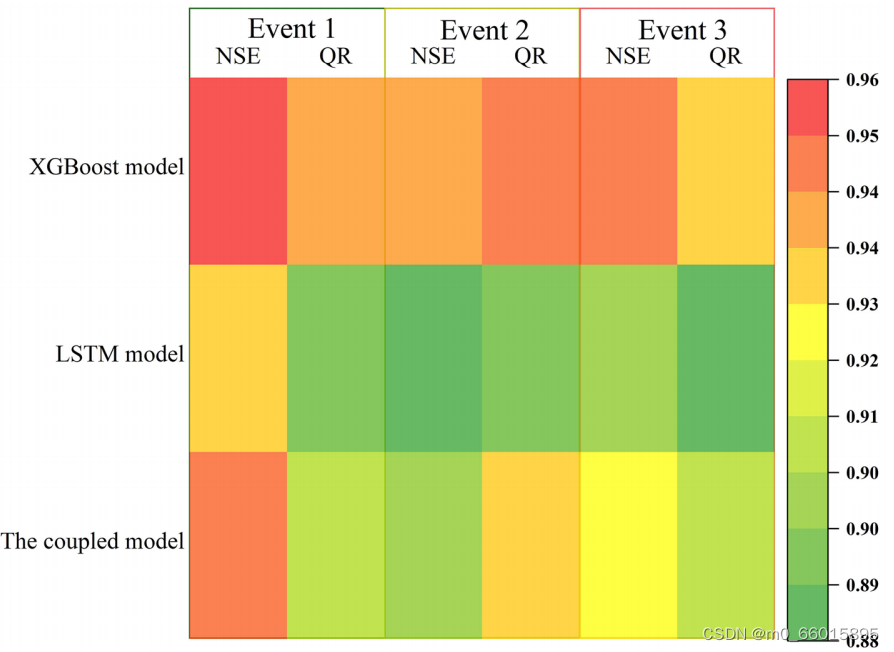
对3次降雨事件的模拟结果进行分析,降雨期间XGBoost模型、降雨后LSTM模型和XGBoost与LSTM模型耦合模型模拟的洪水深度平均误差分别为8.87%、9.77%和9.13%,满足洪水预测的要求。同时,利用NSE和QR来评价模型的效率和精度。耦合模型的平均NSE为0.96,平均预测合格率为90.3%。结果表明,XGBoost与LSTM算法的耦合模型在洪水预报中是有效可行。
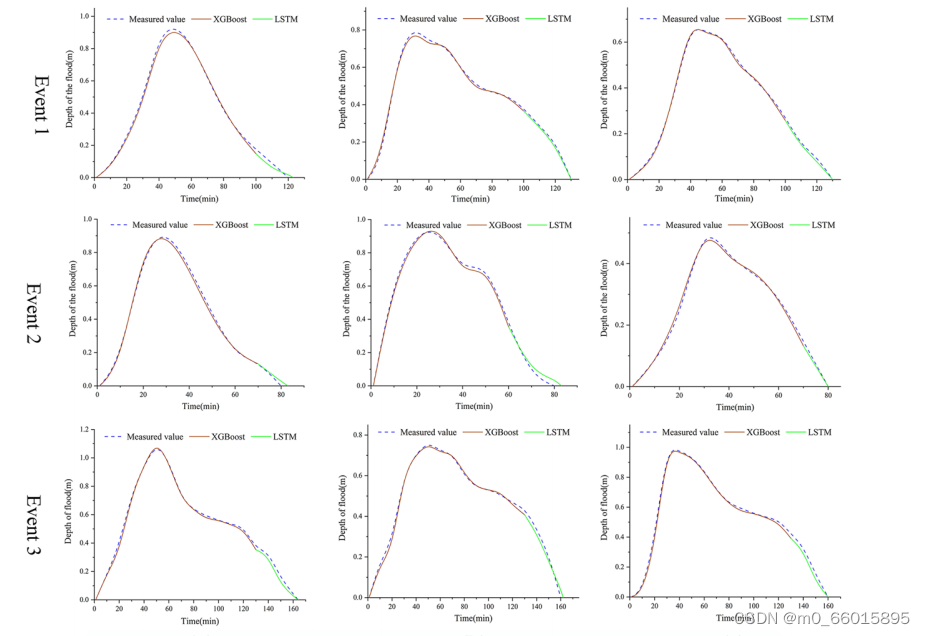
为了评估模拟值与实测值的差异,通过间隔10 min的系统采样生成拟合曲线如右图,结果表明,耦合模型预测值与实测值具有较强的一致性
LSTM变体
Bidirectional LSTM(双向LSTM)
LSTM只能实现单向的传递,无法编码从后到前的信息。当我们语句是承前启后的情况时,自然能完成。但是当语句顺序倒过来,关键次在后面了,LSTM就无能为力了。在更细粒度的分类时,如对于强程度的褒义、弱程度的褒义、中性、弱程度的贬义、强程度的贬义的五分类任务需要注意情感词、程度词、否定词之间的交互。举一个例子,“这个餐厅脏得不行,没有隔壁好”,这里的“不行”是对“脏”的程度的一种修饰,通过BiLSTM可以更好的捕捉双向的语义依赖。
双向LSTM结构中有两个 LSTM 层,一个从前向后处理序列,另一个从后向前处理序列。这样,模型可以同时利用前面和后面的上下文信息。在处理序列时,每个时间步的输入会被分别传递给两个 LSTM 层,然后它们的输出会被合并。通过双向 LSTM,我们可以获得更全面的序列信息,有助于提高模型在序列任务中的性能。
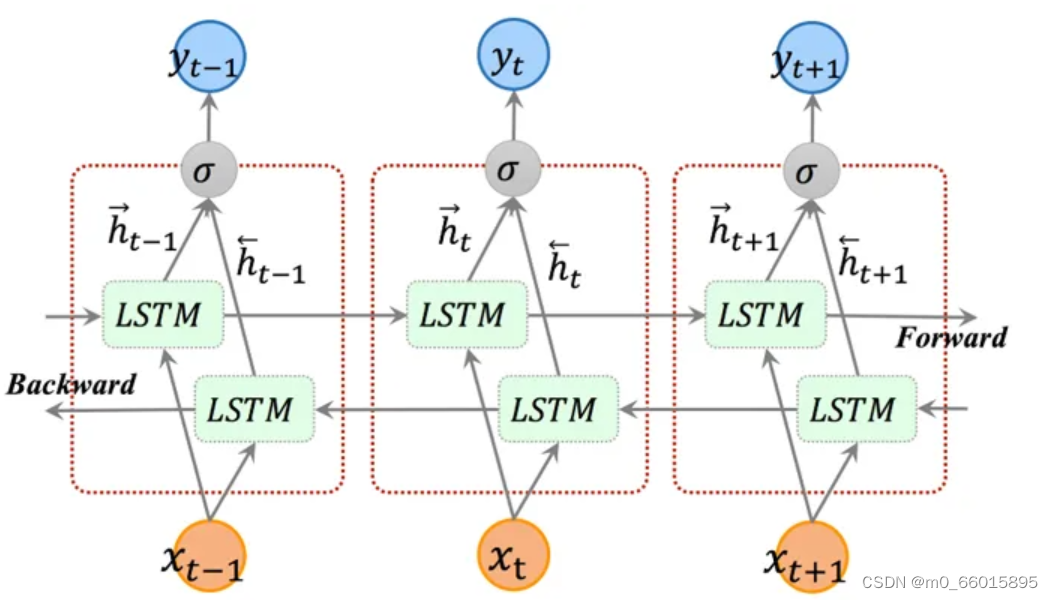
双向神经网络的单元计算与单向的是相通的。但是双向神经网络隐藏层要保存两个值,一个参与正向计算,另一个值参与反向计算,处理完成后将两个LSTM的输出拼接起来

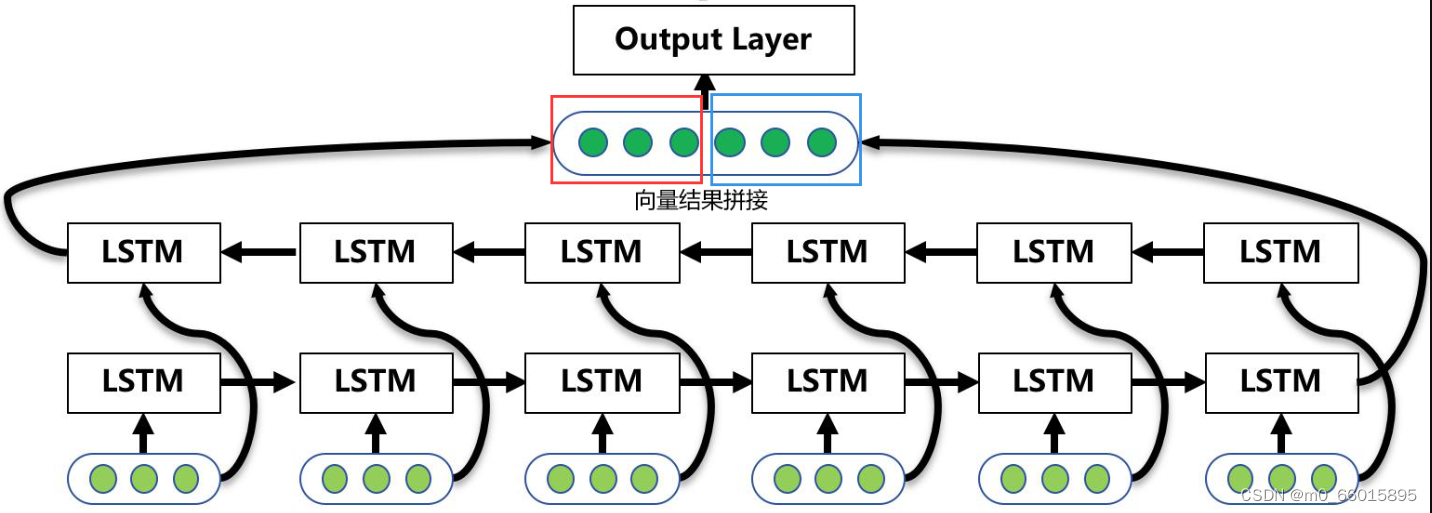
Q:为什么LSTM中经常使用的是双向LSTM?
双向结构的设计可以提高模型的表示能力和性能,特别是好地捕捉序列中的信息、在处理复杂序列数据时。以下是为什么经常使用两层双向LSTM的一些原因:
- 更丰富的上下文信息: 两层LSTM可以提供更丰富的上下文信息。第一层LSTM将原始输入序列的信息进行初步处理,然后将其作为更丰富的输入提供给第二层LSTM。这有助于模型更好地捕捉输入序列中的特征和模式。
- 更强的特征表示: 两层LSTM可以逐步提取更抽象、更高级别的特征表示。第一层LSTM将原始数据进行编码,然后第二层LSTM在第一层的基础上进一步提取更有意义的特征。这有助于提高模型的表达能力,从而更好地建模序列数据
- 双向信息:双向LSTM可以从两个方向(正向和反向)分别获取序列数据的信息。
GRU(门循环控制单元)
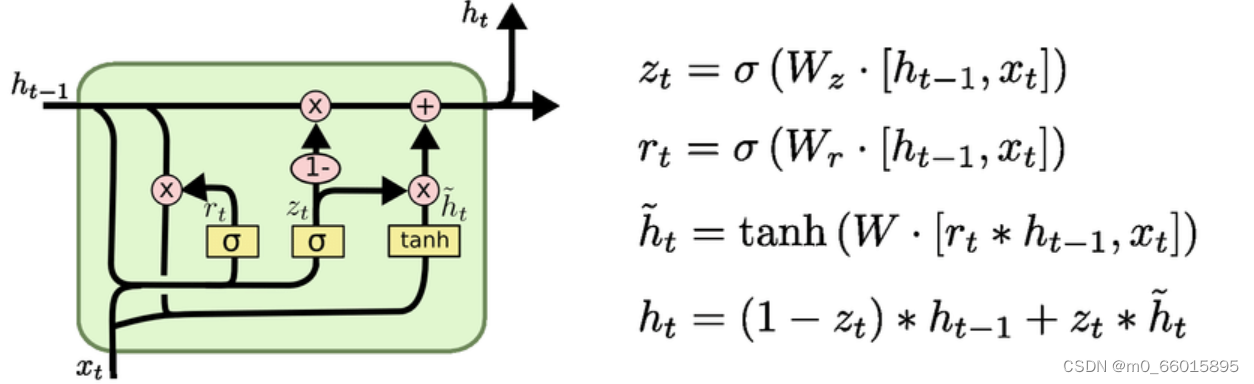
虽然LSTM能够抑制梯度消失问题,但需要以增加时间复杂度和空间复杂度作为代价。GRU在LSTM基础上将忘记门和输入门合并成一个新的门即更新门, GRU包含两个门:更新门与重置门
- 重置门:负责控制忽略前一时刻的状态信息
的程度,重置门的值越小说明忽略的越多。
- 更新门:定义了前面记忆保存到当前时间步的量,更新门的值越大说明上一时刻的状态信息
带入越多。
如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。这两个门控向量决定了哪些信息最终能作为门控循环单元的输出,它们能够保存长期序列中的信息,使得重要信息可以跨越长时间步骤传递,且不会随时间而清除或因为与预测不相关而移除。
GRU的优势:
- 参数更少:从而有效降低过拟合的风险,因此模型泛化能力较好,并且在反向传播的过程中,随着反向传播深度的加深,对应需要反向传播路径相比于LSTM大量减少,从而减小了时间、空间复杂度的负担。
- 训练速度较快: 由于GRU的参数较少,它通常比LSTM更快地训练。
- 对短序列有优势:GRU在某种程度上减少了梯度消失的问题,使其更容易捕捉到短序列中的相关信息。
GRU的缺点:
- 信息保存不如LSTM: GRU的门控机制相对简单,因此它不太适合捕捉长期依赖关系。在某些任务中,尤其是处理需要长期记忆的序列数据时,LSTM可能表现更好。
- 性能不稳定:GRU在某些任务中可能表现得不如LSTM稳定,因为它在不同数据集和问题上的性能差异较大。在一些情况下,LSTM可能更可靠。
Seq2seq模型
所谓Seq2seq(Sequence to Sequence),即序列到序列模型,就是一种能够根据给定的序列,通过特定的生成方法生成另一个序列的方法,同时这两个序列可以不等长。这种结构又叫Encoder-Decoder模型,即编码-解码模型,其是RNN的一个变种,为了解决RNN要求序列等长的问题。同时,Seq2Seq使用的都是RNN单元,一般为LSTM和GRU。
编码器-解码器(encoder-decoder)架构
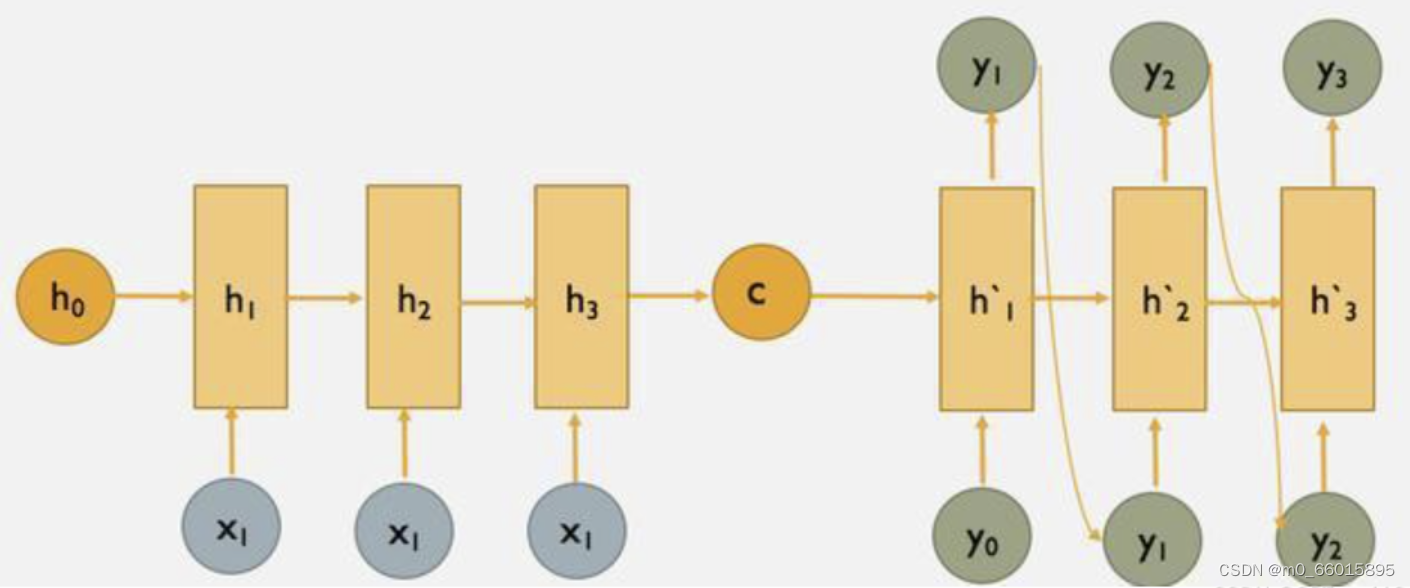
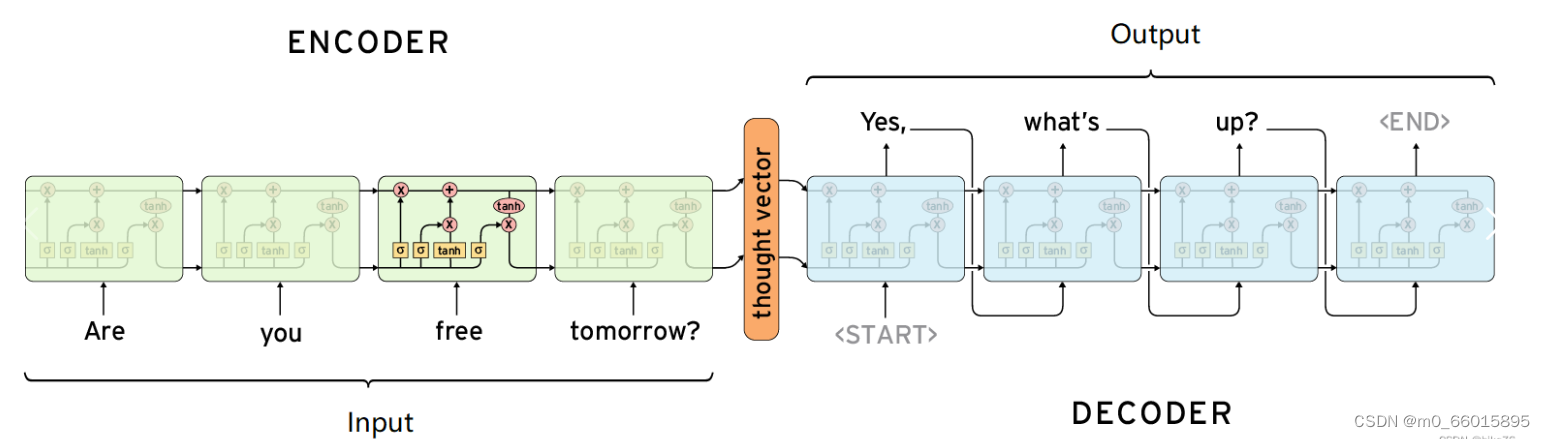
Encode一般有两种方式,将RNN最后一个状态做一个变换得到语义向量C,或者将输入序列的所有隐含状态做一个变换得到语义向量C。
Decoder负责根据语义向量生成指定的序列,即解码。解码器使用另外一个 RNN ,基于输入序列的编码信息和输出序列已经看见的或者生成的词元来预测下一个词元,从而连续生成输出序列的词元。最简单的方式是将语义向量C作为初始状态输入到Encoder的RNN中,得到输出序列。此时上一时刻的输出会成为当前时刻的输入,而且语义向量C只作为初始状态参与运算,后面运算与C无关。第二种方式语义向量C参与序列所有时刻的运算,上一时刻的输出仍然作为当前时刻的输入,但C参与每个时刻的运算。
但需注意的是:
- 编码器是一个RNN,读取输入句子(可以是双向的)
- 解码器使用另一个RNN来输出
- 编码器是没有输出的RNN
- 编码器最后时间步的隐藏状态用作解码器的初始隐藏状态
编码器可以是单向的循环神经网络,其中的隐藏状态只依赖于输入子序列,这个子序列是由输入序列的开始位置到隐藏状态所在的时间步的位置(包括隐藏状态所在的时间步)。组成编码器也可以是双向的循环神经网络,其中隐藏状态依赖于两个输入子序列,两个子序列是由隐藏状态所在的时间步的位置之前的序列和之后的序列(包含隐藏状态所在的时间步),因此隐藏状态对整个序列的信息都进行了编码。双向不能做语言模型,但是双向可以做翻译;双向可以做编码器,但不能做解码器,解码器需要做预测,编码器不需要。
Seq2seq训练
<bos> 表示序列开始词元,代表一个句子的开始,它是解码器的输入序列的第一个词元
<eos> 表示序列结束词元,代表一个句子的结束(解码器输出的句子长度是可以变化的,一旦输出序列生成此词元,模型就会停止预测)
RNN 做编码器可以输入任意长度的序列,最后返回最后时刻的隐藏状态,使用 RNN 编码器最终的隐状态来初始化解码器的隐状态,解码器一直输出,直到看到句子的结束标志为止
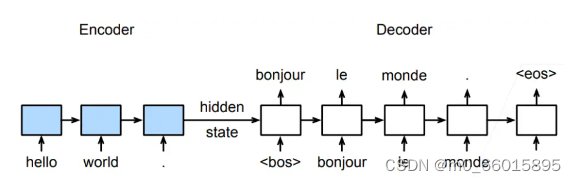
- 训练时将特定的开始词元(“<bos>”)和原始的输出序列(不包括序列结束词元“<eos>”)拼接在一起作为解码器的输入,这也称为强制教学(teacher forcing,因为原始的输出序列(词元的标签)被送入了解码器)
- 也可以将来自上一个时间步的预测得到的词元作为解码器的当前输入
- 训练和推理是不同的:编码器是相同的,但是在训练的时候,解码器是知道目标句子的,它知道真正的翻译是什么样子的,所以解码器的输入(每个 RNN 时刻的输出)所使用的实际上是真正的目标句子的输入,所以就算是在训练的时候翻译错了,下一个时刻的输入还是正确的输入,也就是说,在训练的时候所使用的是真正的目标句子来帮助训练,这样就降低了预测长句子的难度。
双向LSTM对乘客数量进行预测
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Bidirectional
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
#matplotlib inline
#加载数据集:航空乘客数据集
dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python')
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
# X是给定时间(t)的乘客人数,Y是下一次(t + 1)的乘客人数。
# 将值数组转换为数据集矩阵,look_back是步长。
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
# X按照顺序取值
dataX.append(a)
# Y向后移动一位取值
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)
# fix random seed for reproducibility
numpy.random.seed(7)
# 数据缩放
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 将数据拆分成训练和测试,2/3作为训练数据
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
print("原始训练集的长度:",train_size)
print("原始测试集的长度:",test_size)
# 构建监督学习型数据
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
print("转为监督学习,训练集数据长度:", len(trainX))
# print(trainX,trainY)
print("转为监督学习,测试集数据长度:",len(testX))
# print(testX, testY )
# 数据重构为3D [samples, time steps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
print('构造得到模型的输入数据(训练数据已有标签trainY): ',trainX.shape,testX.shape)
# 创建BILSTM模型
model = Sequential()
model.add(Bidirectional(LSTM(4, input_shape=(1, look_back))))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# 打印模型
model.summary()
# 开始预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 逆缩放预测值
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 计算误差
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
#用于绘图的班次预测
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# 用于绘图的偏移测试预测
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
Train Score: 22.97 RMSE
Test Score: 48.23 RMSE