在之前的文章中,我教会大家如何一步一步搭建一个Hadoop集群,但是只提供了代码,怕有些朋友会在一些地方产生疑惑,今天我来以图文混排的方式,一站式交给大家如何搭建一个Hadoop高可用集群包括(HadoopHA,Zookeeper、MySQL、Hbase、Hive、Sqoop、Scala、Spark)。如果对之前文章感兴趣的朋友,可以观看这刊专栏:
大数据技术之Hadoop全生态组件学习与搭建![]() http://t.csdnimg.cn/LMyEn文章较长,附目录,此次安装是在VM虚拟环境下进行。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
http://t.csdnimg.cn/LMyEn文章较长,附目录,此次安装是在VM虚拟环境下进行。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
目录
一,创建集群
一、创建主机
二、解压安装包配置环境变量
一、解压安装包
二、配置环境变量
三、创建从机
二、配置安装应用
1、HadoopHA 及 zookeeper
2、HBase
3、Hive及MySQL
4、sqoop
5、scala 及spark
一,创建集群
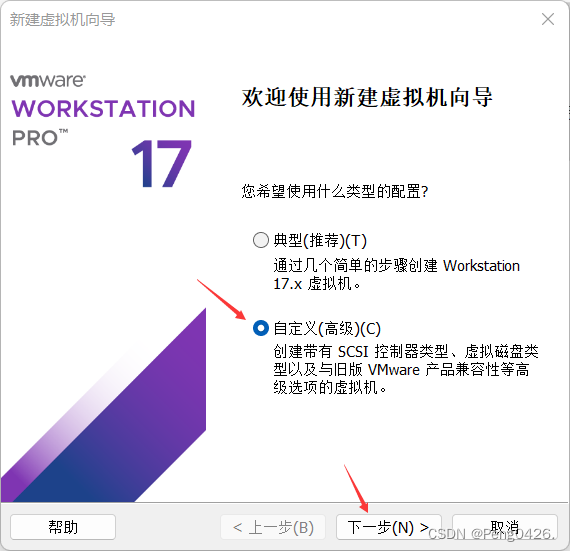
一、创建主机
首先,我们需要在vm里安装新建一台名为BigData01的虚拟机作为我们的主机。
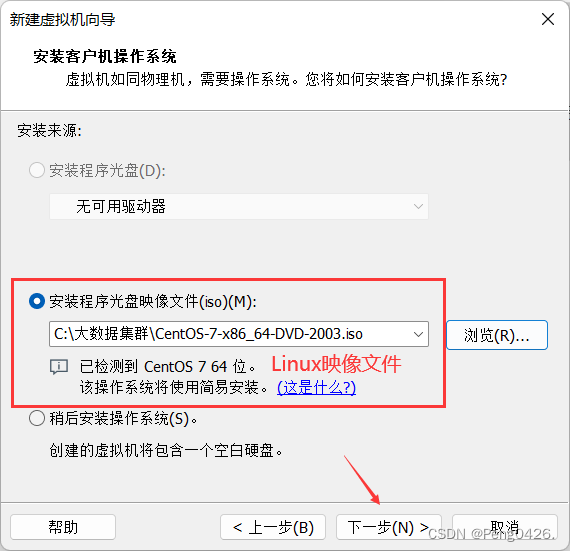
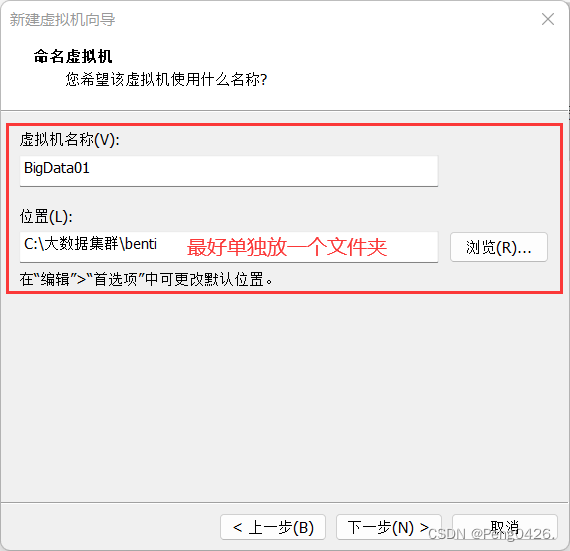

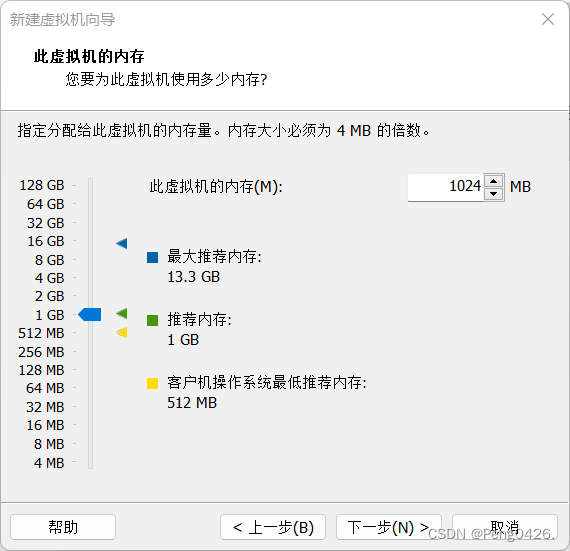
这个内存要注意,如果只是学习搭建,内存不用给很大,如果你的集群搭建是为了工作或别的高需求目的,能给多大就多大。
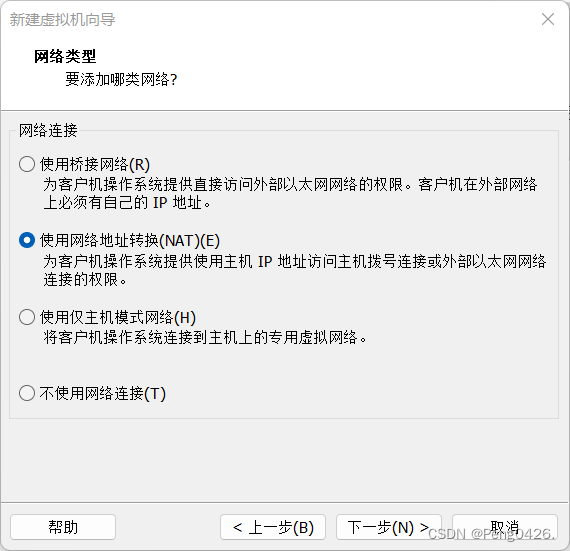
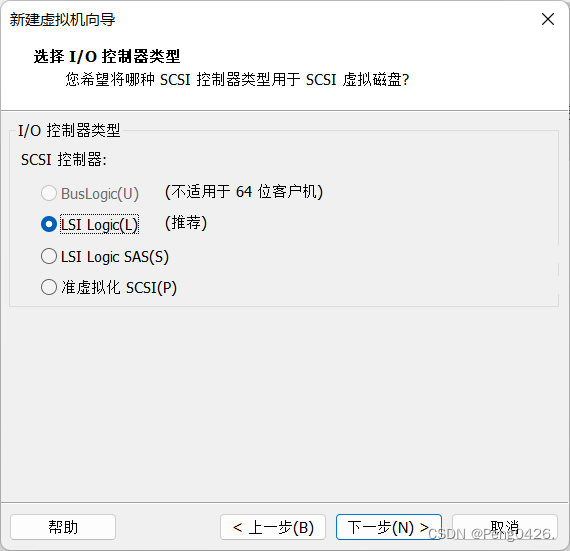
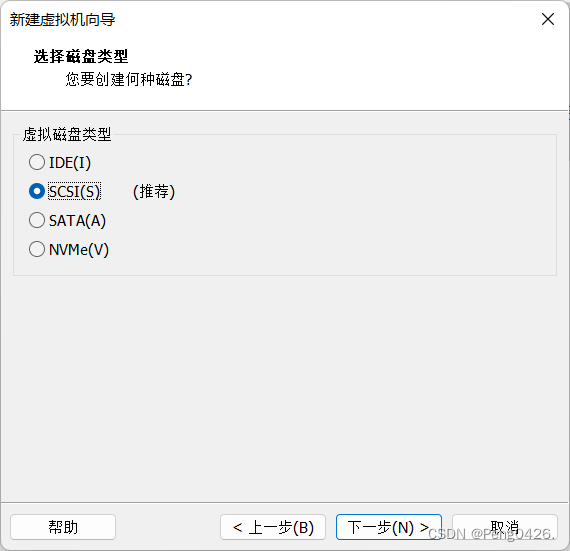
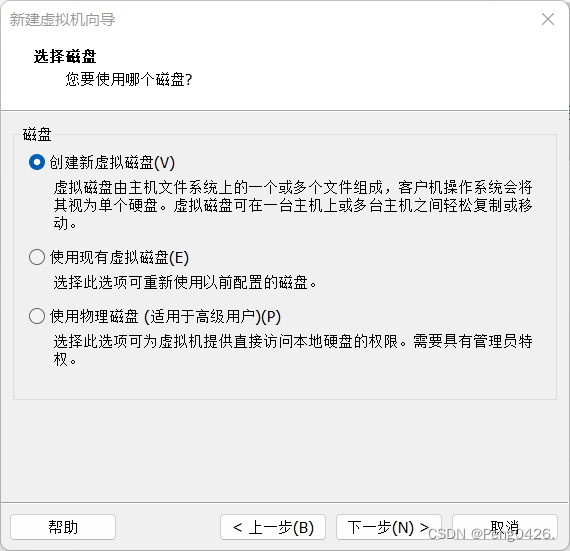
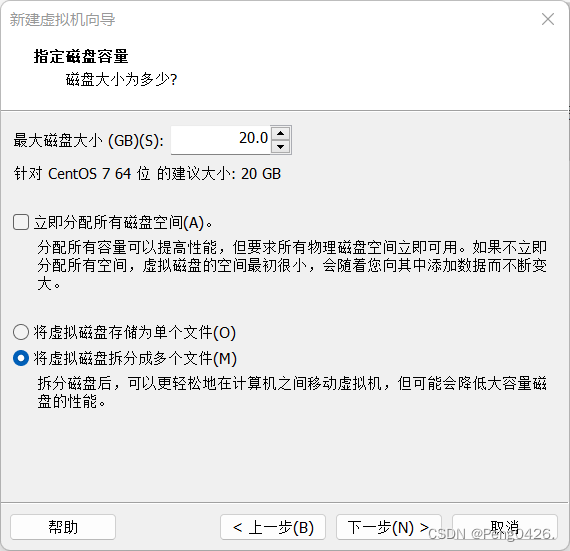
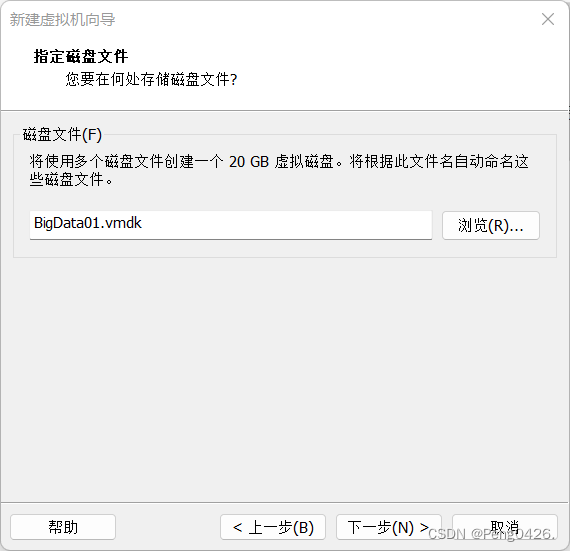
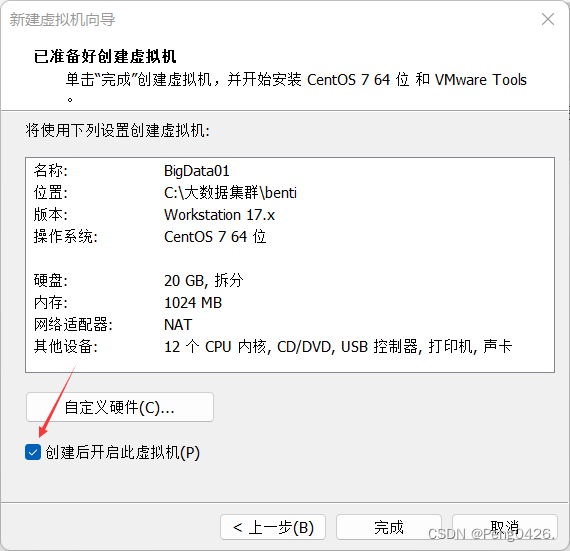
这样,我们就可以开启虚拟机了,第一次需要初始化。
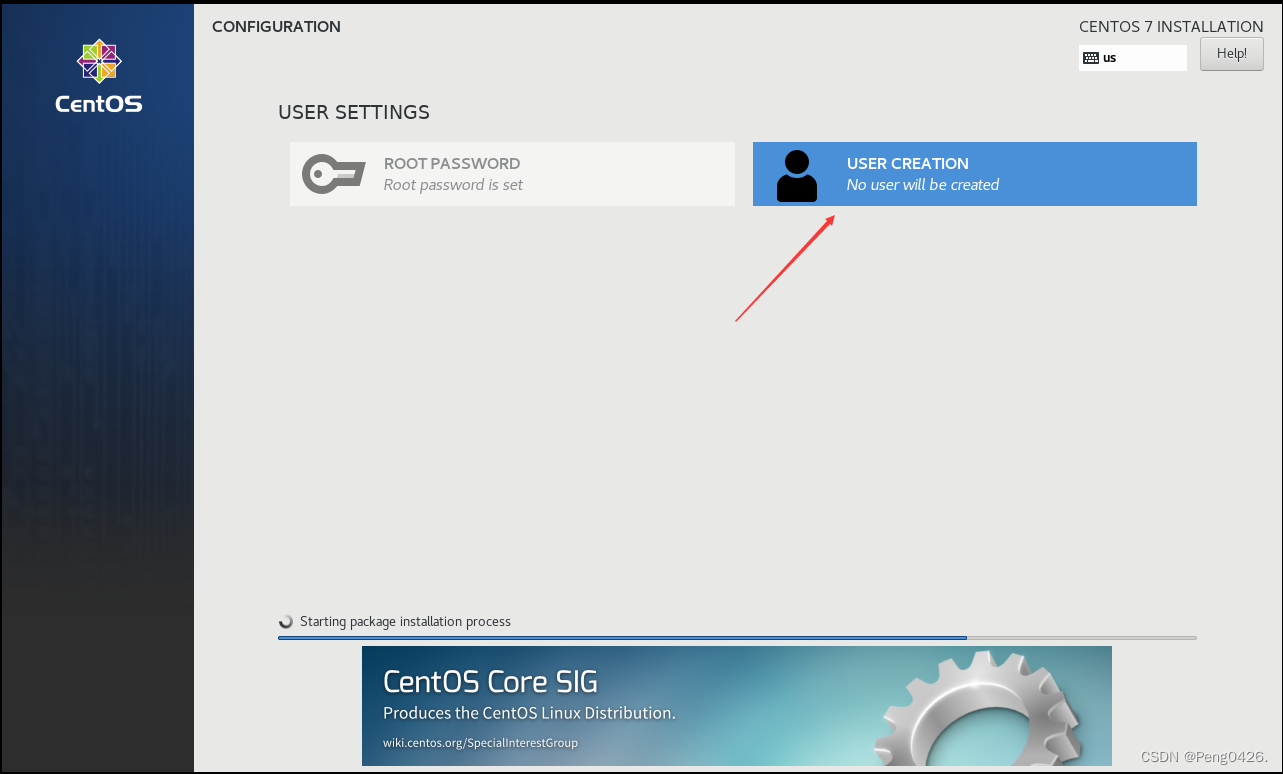
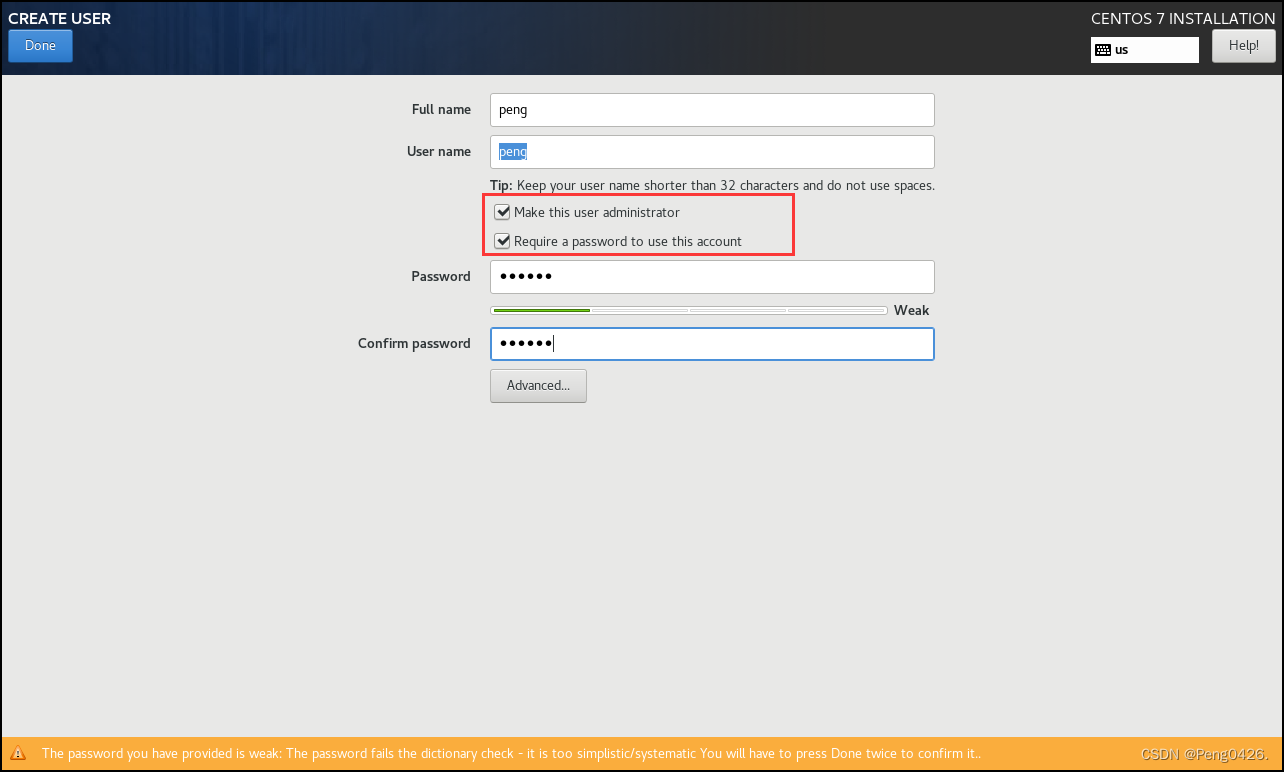
这是添加新用户,name是用户名,password是密码。

这边我们选择用root(管理员)用户来登录,密码就是刚才创建虚拟机时所设置的密码。
将我们所需要的安装包(jdk、Hadoop、zookeeper、hbase、MySQL、MySQL.java、hive、sqoop、Scala、spark)上传到Linux的Downloads中。
二、解压安装包配置环境变量
一、解压安装包
打开终端,解压到opt下
tar zxvf /root/Downloads/jdk-8u171-linux-x64.tar.gz -C/opt/
tar zxvf /root/Downloads/zookeeper-3.4.5.tar.gz -C/opt/
tar zxvf /root/Downloads/hadoop-2.7.5.tar.gz -C/opt/
mv /opt/zookeeper-3.4.5/ /opt/zookeeper
mv /opt/hadoop-2.7.5/ /opt/hadoopHA
tar zxvf /root/Downloads/hbase-1.2.6-bin.tar.gz -C/opt/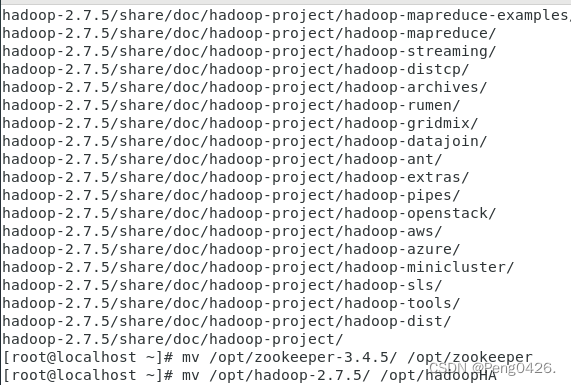

tar zxvf /root/Downloads/apache-hive-2.1.1-bin.tar.gz -C/opt/
mv /opt/apache-hive-2.1.1-bin/ /opt/hive
卸载原有数据库
rpm -qa | grep mariadb(出来的是哪个版本号下面就哪个)
rpm -e --nodeps mariadb-libs-5.5.65-1.el7.x86_64
rpm -e --nodeps mariadb-5.5.68-1.el7.x86_64
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64
安装mysql
cd /opt/
mkdir mysql
cd
tar xvf /root/Downloads/mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar -C/opt/mysql
cd /opt/mysql/
rpm -ivh mysql-community-common-5.7.26-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.26-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.26-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.26-1.el7.x86_64.rpm
检查安装情况
rpm -qa | grep mysql
mv /root/Downloads/mysql-connector-java-5.1.46-bin.jar /opt/hive/lib/

tar -zxvf /root/Downloads/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C/opt/
mv /opt/sqoop-1.4.7.bin__hadoop-2.6.0/ /opt/sqoop
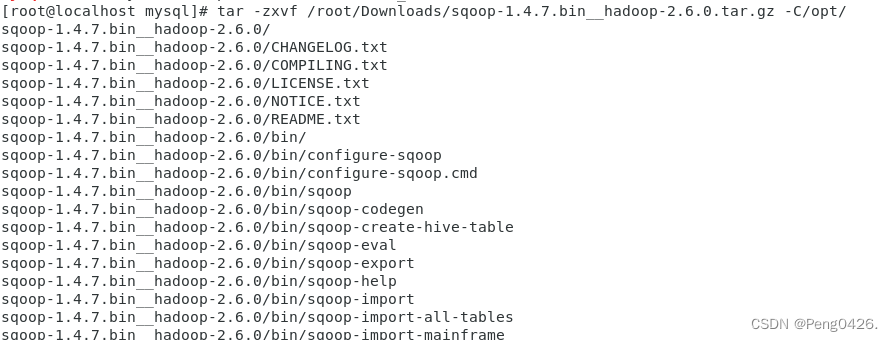

二、配置环境变量
创建所需文件,配置环境变量
cd /opt/zookeeper
mkdir data && mkdir logs
cd
vim /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_171
export HADOOP_HOME=/opt/hadoopHA
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export HBASE_HOME=/opt/hbase-1.2.6
export PATH=$PATH:$HBASE_HOME/bin
export HIVE_HOME=/opt/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HCAT_HOME=$HIVE_HOME/hcatalog
export PATH=$PATH:$HIVE_HOME/bin
export SQOOP_HOME=/opt/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
export SCALA_HOME=/usr/local/soft/scala-2.12.12
export PATH=$PATH:${SCALA_HOME}/bin
export SPARK_HOME=/opt/spark-3.2.1
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin
source /etc/profile

三、创建从机
主机关机,从目前的主机状态克隆出两个从机当集群中的从节点,名称分别为BigData01,BigData02。


BigData03创建方式同上
二、配置安装应用
1、HadoopHA 及 zookeeper
vim /etc/hosts
192.168.67.128 BigData01
192.168.67.129 BigData02
192.168.67.130 BigData03
(根据实际ip改变)
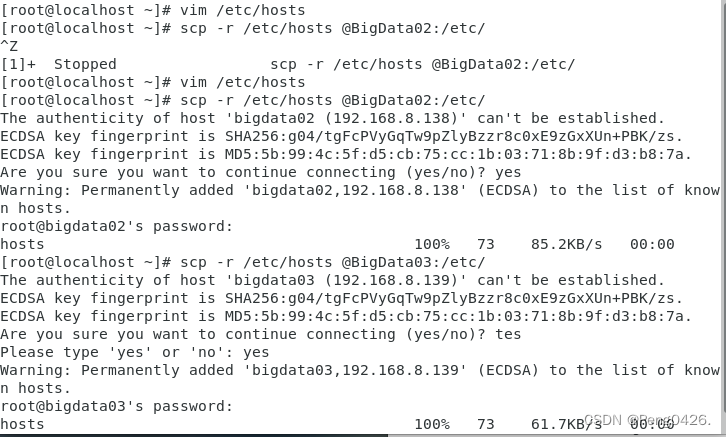
scp -r /etc/hosts @BigData02:/etc/
scp -r /etc/hosts @BigData03:/etc/
(接yes和密码) 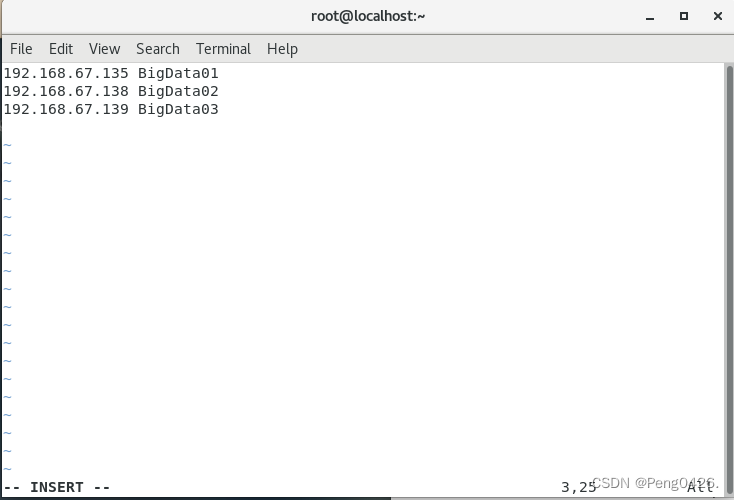
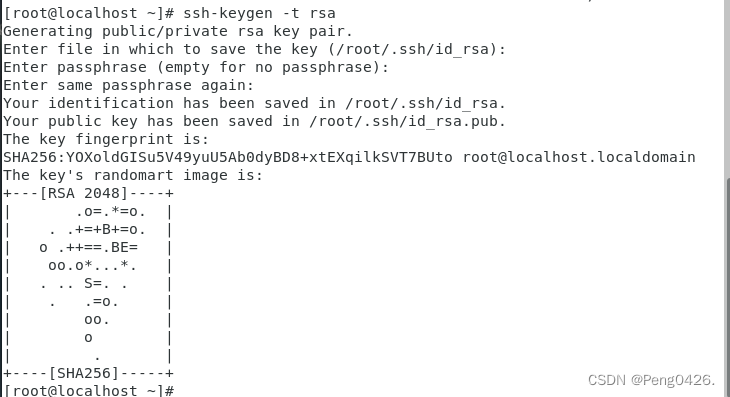
ssh-keygen -t rsa
cd ~/.ssh/
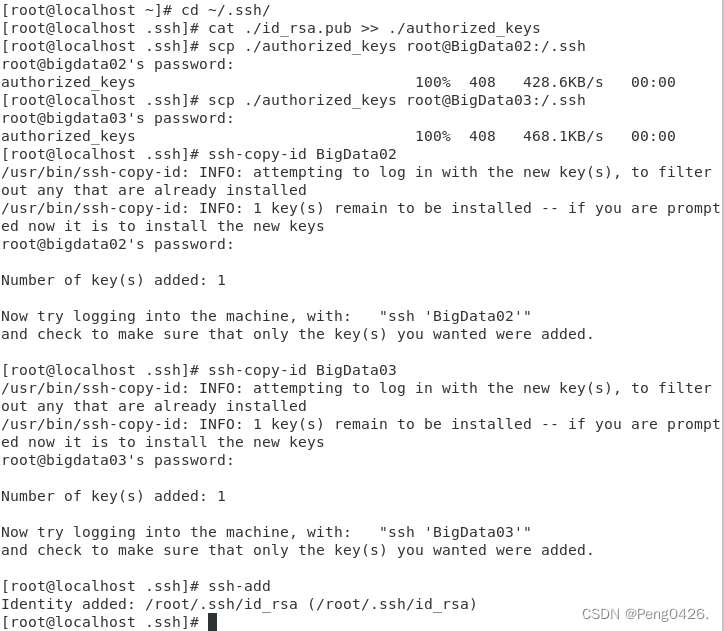
cat ./id_rsa.pub >> ./authorized_keys
产生的授权后的钥匙要发送给s1和s2节点
#scp 发送命令
scp ./authorized_keys root@BigData02:/.ssh
scp ./authorized_keys root@BigData03:/.ssh
ssh-copy-id BigData02
ssh-copy-id BigData03
ssh-add 启动ssh的服务
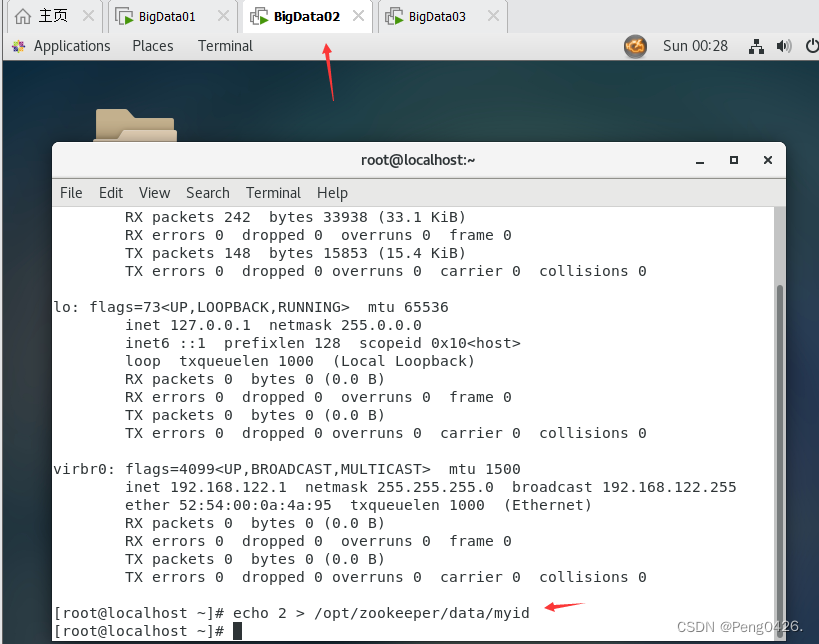
echo 1 > /opt/zookeeper/data/myid
cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
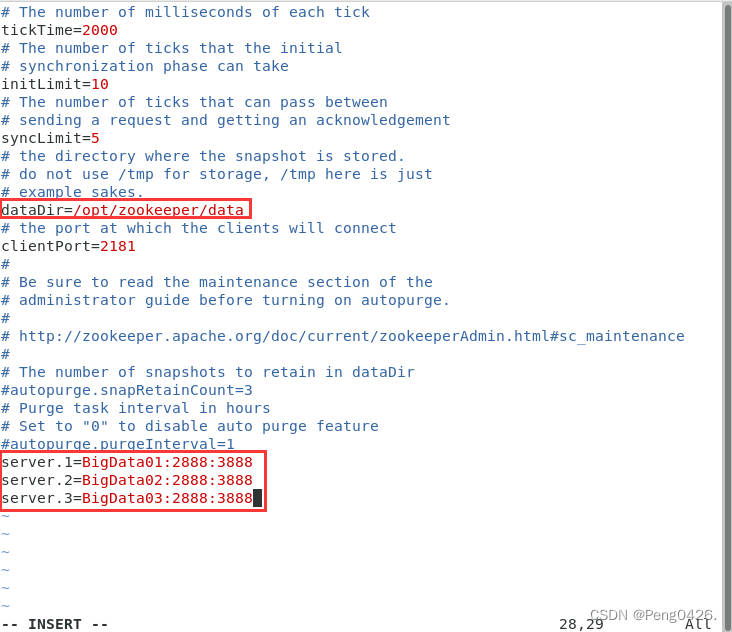
vim /opt/zookeeper/conf/zoo.cfg
修改dataDir=/opt/zookeeper/data
末尾添加:
server.1=BigData01:2888:3888
server.2=BigData02:2888:3888
server.3=BigData03:2888:3888
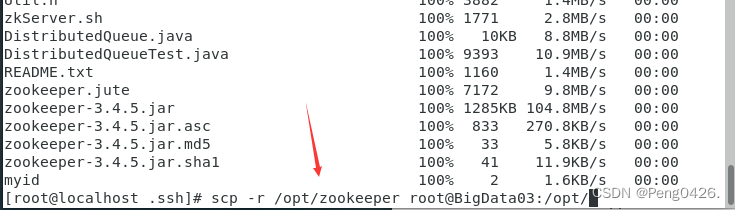
scp -r /opt/zookeeper root@BigData02:/opt/
scp -r /opt/zookeeper root@BigData03:/opt/
02虚拟机下:echo 2 > /opt/zookeeper/data/myid
03虚拟机下:echo 3 > /opt/zookeeper/data/myid
三个节点:
systemctl stop firewalld.service
zkServer.sh start
zkServer.sh status



cd /opt/hadoopHA/
mkdir tmp
scp -r /opt/hadoopHA/tmp @BigData02:/opt/hadoopHA/
scp -r /opt/hadoopHA/tmp @BigData03:/opt/hadoopHA/
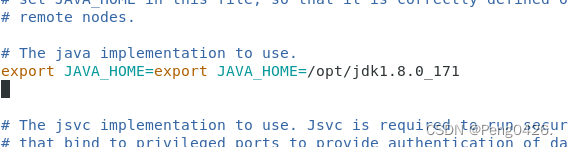
vim /opt/hadoopHA/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_171
vim /opt/hadoopHA/etc/hadoop/core-site.xml
<property>
<!--指定HDFS的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<!--指定hadoop运行时产生文件的存储路径(即临时目录)-->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopHA/tmp</value>
</property>
<property>
<!--指定ZooKeeper地址(2181端口参考zoo.cfg配置文件) -->
<name>ha.zookeeper.quorum</name>
<value>BigData01:2181,BigData02:2181,BigData03:2181</value>
</property>
vim /opt/hadoopHA/etc/hadoop/hdfs-site.xml
<property>
<!--指定HDFS的nameservices为ns1,需要与core-site.xml保持一致-->
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<!--ns1下面设置2个NameNode,分别是nn1,nn2-->
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<!--设置nn1的RPC通信地址-->
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>BigData01:9000</value>
</property>
<property>
<!--设置nn1的http通信地址-->
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>BigData01:50070</value>
</property>
<property>
<!--设置nn2的RPC通信地址-->
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>BigData02:9000</value>
</property>
<property>
<!--设置nn2的http通信地址-->
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>BigData02:50070</value>
</property>
<property>
<!--设置NameNode的元数据在JournalNode上的存放位置-->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://BigData01:8485;BigData02:8485;BigData03:8485/ns1</value>
</property>
<property>
<!--指定JournalNode存放edits日志的目录位置-->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoopHA/tmp/dfs/journal</value>
</property>
<property>
<!--开启NameNode失败自动切换-->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<!--配置失败自动切换实现方式-->
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!--配置隔离机制-->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--设置使用隔离机制时需要的SSH免登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
vim /opt/hadoopHA/etc/hadoop/yarn-site.xml
<property>
<!--设置resourcemanager在哪个节点上-->
<name>yarn.resourcemanager.hostname</name>
<value>BigData01</value>
</property>
<property>
<!--Reducer取数据的方法是mapreduce_shuffle-->
<!--指定nodemanager启动时加载server的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
cd /opt/hadoopHA/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
cd
vim /opt/hadoopHA/etc/hadoop/mapred-site.xml
<property>
<!--指定MR(mapreduce)框架使用YARN方式-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
vim /opt/hadoopHA/etc/hadoop/slaves
BigData01
BigData02
BigData03
scp -r /opt/hadoopHA root@BigData02:/opt/
scp -r /opt/hadoopHA root@BigData03:/opt/
三个节点启动zookeeper,查看状态
zkServer.sh start
zkServer.sh status
jps查看进程
hadoop-daemon.sh start journalnode
主节点下:
hdfs namenode -format
scp -r /opt/hadoopHA/tmp/dfs @BigData02:/opt/hadoopHA/tmp/
hadoop-daemon.sh start namenode
另外一个namenode节点下:
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
主节点下:
hdfs zkfc -formatZK 格式化
启动服务:
start-dfs.sh
start-yarn.sh
查看进程:
jps
关机前关闭集群服务:
stop-yarn.sh
stop-dfs.sh





后面的配置方法同上,就不附图了
2、HBase
在BigData01下:
tar zxvf /root/Downloads/hbase-1.2.6-bin.tar.gz -C/opt/
vim /etc/profile
export HBASE_HOME=/opt/hbase-1.2.6
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile
vim /opt/hbase-1.2.6/conf/hbase-env.sh
export JAVA_HOME=/opt/jdk1.8.0_171(27行)
export HBASE_MANAGES_ZK=false(128)此行下面添加:
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
vim /opt/hbase-1.2.6/conf/hbase-site.xml
<property>
<name>hbase.rootdir</name> <!-- hbase存放数据目录 ,默认值${hbase.tmp.dir}/hbase-->
<!-- 端口要和Hadoop的fs.defaultFS端口一致-->
<!--ns1为hdfs-site.xml中dfs.nameservices的值。或与Hadoop的fs.defaultFS一致-->
<value>hdfs://ns1/data/hbase_db</value>
</property>
<property>
<name>hbase.cluster.distributed</name> <!-- 是否分布式部署 -->
<value>true</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name> <!-- list of zookooper -->
<value>BigData01,BigData02,BigData03</value>
</property>
<property>
<name>hbase.zookeeper.property.datadir</name> <!--zookooper配置、日志等的存储位置 -->
<value>/opt/zookeeper-3.4.12</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
vim /opt/hbase-1.2.6/conf/regionservers
BigData01
BigData02
BigData03
vim /opt/hbase-1.2.6/conf/backup-masters
BigData02
scp /opt/hadoopHA/etc/hadoop/hdfs-site.xml /opt/hbase-1.2.6/conf/
scp -r /etc/profile @BigData02:/etc/
scp -r /etc/profile @BigData03:/etc/
scp -r /opt/hbase-1.2.6 root@BigData02:/opt/
scp -r /opt/hbase-1.2.6 root@BigData03:/opt/
两节点下
source /etc/profile
依次启动zkServer.sh start(检查防火墙)
systemctl stop firewalld
01下:
start-dfs.sh
start-yarn.sh
start-hbase.sh
jps
03下:
mr-jobhistory-daemon.sh start historyserver
jps
浏览器打开查看
http://192.168.67.128:16010
http://192.168.67.128:16030
根据实际ip地址查看
HBase的Shell命令
1)基本Shell命令
1、启动Shell(进入HBase命令行环境)
$ hbase shell
[hadoop@BigData01 ~]$ hbase shell
hbase(main):001:0>
2、查看HBase运行状态
hbase(main):002:0> status
1 active master, 1 backup masters, 3 servers, 0 dead, 0.6667 average load
3、查看版本
hbase(main):003:0> version
4、获得帮助
hbase(main):004:0> help
5、退出Shell
hbase(main):005:0> exit
2)DDL操作命令
1、创建表
create 表名student,列族名address, 列族名info
hbase(main):001:0> create 'student', 'address', 'info'
0 row(s) in 2.9230 seconds
=> Hbase::Table - student
2、列表的形式显示所有数据表
hbase(main):002:0> list
TABLE
student
1 row(s) in 0.0920 seconds
=> ["student"]
3、查看表的结构
hbase(main):003:0> describe 'student'
Table student is ENABLED
student
COLUMN FAMILIES DESCRIPTION
{NAME => 'address', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE',
DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true',
BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE',
DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true',
BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.1420 seconds
4、修改表结构(需要先将表设为不可用)
hbase(main):004:0> disable 'student'
0 row(s) in 2.4820 seconds
4.1)增加列族
hbase(main):005:0> alter 'student', NAME=>'cf3', VERSIONS=>5
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 2.3320 seconds
4.2)删除列族
hbase(main):007:0> alter 'student', NAME=>'cf3', METHOD=>'delete'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 2.2480 seconds
4.3)设表为启用状态
enable 'student'
5、查询表是否存在
exists 'student'
6、查询表是否可用
is_enabled 'student'
7、判断表是否不可用
is_disabled 'student'
8、删除表
先disable表,再drop表
disable 'test'
drop 'test'
2)DML操作命令
假设student表的列族address{province,city,university},info{height,weight,birthday,telephone,qq}
create 'student', 'address', 'info'
Row Key: 姓名(也可根据需要设学号为row key)
1、插入记录数据(put '表名', 'row key', '列族:列', '列的值')
put 'student','zhangsan','info:height','180'
put 'student','zhangsan','info:birthday','1990-01-20'
put 'student','zhangsan','info:weight','70'
put 'student','zhangsan','address:province','Hubei'
put 'student','zhangsan','address:city','Wuhan'
put 'student','zhangsan','address:university','Wenhua College'
2、获取一条数据(get '表名', 'row key')
hbase(main):011:0> get 'student', 'zhangsan'
COLUMN CELL
address:city timestamp=1521772686458, value=Wuhan
address:province timestamp=1521772681481, value=Hubei
address:university timestamp=1521772690856, value=Wenhua College
info:birthday timestamp=1521772670610, value=1990-01-20
info:height timestamp=1521772660840, value=180
info:weight timestamp=1521772675096, value=70
6 row(s) in 0.1980 seconds
3、获取一个ID(row key),一个列族的所有数据
get 'student', 'zhangsan', 'info'
4、获取一个ID(row key),一个列族中某列的所有数据
get 'student', 'zhangsan', 'info:birthday'
5、更新一条记录
put 'student', 'zhangsan', 'info:weight', '75'
6、读出数据(全表扫描)
scan 'student'
7、查询表有多少行(row key的数量)
count 'student'
8、将整表清空
truncate 'student'
9、删除某ID(row key)的某列的值
delete 'student', 'zhangsan', 'info:weight'
3)运行HBase Shell脚本
可以把操作命令写入到文件中,如testHbaseData.sh,再在Linux shell命令下执行:
$ hbase shell testHbaseData.sh
如testHbaseData.sh文件中写入如下内容:
put 'student','lisi','info:height','170'
put 'student','lisi','info:birthday','1991-06-20'
put 'student','lisi','info:weight','65'
put 'student','lisi','address:province','Hubei'
put 'student','lisi','address:city','Wuhan'
put 'student','lisi','address:university','Wuhan University'
3、Hive及MySQL
tar zxvf /root/Downloads/apache-hive-2.1.1-bin.tar.gz -C/opt/
mv /opt/apache-hive-2.1.1-bin/ /opt/hive
关闭防火墙及自启
systemctl stop firewalld
systemctl disable firewalld
卸载原有数据库
rpm -qa | grep mariadb(出来的是哪个版本号下面就哪个)
rpm -e --nodeps mariadb-libs-5.5.65-1.el7.x86_64
rpm -e --nodeps mariadb-5.5.68-1.el7.x86_64
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64
安装mysql
cd /opt/
mkdir mysql
cd
tar xvf /root/Downloads/mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar -C/opt/mysql
cd /opt/mysql/
rpm -ivh mysql-community-common-5.7.26-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.26-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.26-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.26-1.el7.x86_64.rpm
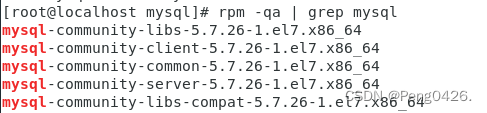
检查安装情况
rpm -qa | grep mysql
修改配置文件
vim /etc/my.cnf
添加到symbolic-links=0 配置信息的下方
default-storage-engine=innodb
innodb_file_per_table
collation-server=utf8_general_ci
init-connect='SET NAMES utf8'
character-set-server=utf8
启动mysql服务
mysqld --initialize --user=mysql
systemctl start mysqld
systemctl status mysqld(出现绿色active (running))
cat /var/log/mysqld.log | grep password(查看默认密码,复制:s/!:!8:kNrf)
mysql -uroot -p(输入拷贝的密码)
set password=password("123456");(修改密码)
update mysql.user set host='%' where user='root';(实现任意主机root用户的远程登录)
flush privileges;(刷新权限表)
quit;(退出,重新登录)
mysql -uroot -p(修改后的密码登录成功即可退出,mysql配置成功)
hive配置
mv /root/Downloads/mysql-connector-java-5.1.46-bin.jar /opt/hive/lib/
修改hive环境变量
vim /etc/profile
export HIVE_HOME=/opt/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HCAT_HOME=$HIVE_HOME/hcatalog
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
配置hive
cd /opt/hive/conf/
cp hive-default.xml.template hive-site.xml
vim /opt/hive/conf/hive-site.xml
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://BigData01:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
(484-488)
(684为true)
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>(928-932)
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
(953-957)
<name>hive.exec.scratchdir</name>
<value>/opt/hive/tmp</value>
<description>Location of Hive run time structured log file</description>(1513-1514)
<name>hive.exec.local.scratchdir</name>
<value>/opt/hive/tmp</value>
<name>hive.downloaded.resources.dir</name>
<value>/opt/hive/tmp/resources</value>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/hive/tmp/operation_logs</value>
创建hive缓存路径
mkdir /opt/hive/tmp
添加Hadoop远程登录配置文件
vim /opt/hadoopHA/etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
scp -r /opt/hadoopHA/etc/hadoop/core-site.xml root@BigData02:/opt/hadoopHA/etc/hadoop/
scp -r /opt/hadoopHA/etc/hadoop/core-site.xml root@BigData03:/opt/hadoopHA/etc/hadoop/
初始化 hive 元数据
cd /opt/hive/lib/
ll
mv log4j-slf4j-impl-2.4.1.jar log4j-slf4j-impl-2.4.1.jar.bak
schematool -initSchema -dbType mysql(报错纠错查看报错原,极大可能是配置文件出错)
mysql -uroot -p
show databases;(出现hive表即配置成功)
启动hive
启动各服务,关闭防火墙
systemctl stop firewalld
stop-all.sh
start-all.sh
依次启动zkServer.sh start(检查防火墙)
01下:
start-dfs.sh
start-yarn.sh
start-hbase.sh
jps
03下:
mr-jobhistory-daemon.sh start historyserver
确保各前置服务启动成功后首次启动hive需初始化
hive --service metastore
出现WARNING!即成功
hive4、sqoop
tar -zxvf /root/Downloads/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C/opt/
mv /opt/sqoop-1.4.7.bin__hadoop-2.6.0/ /opt/sqoop
vim /etc/profile
export SQOOP_HOME=/opt/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
source /etc/profile
scp /opt/hive/lib/mysql-connector-java-5.1.46-bin.jar /opt/sqoop/lib/
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/hadoopHA
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/hadoopHA
#set the path to where bin/hbase is available
export HBASE_HOME=/opt/hbase-1.2.6
#Set the path to where bin/hive is available
export HIVE_HOME=/opt/hive
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/opt/zookeeper
5、scala 及spark
cp /opt/spark-3.2.1/conf/spark-env.sh.template /opt/spark-3.2.1/conf/spark-env.sh
cp /opt/spark-3.2.1/conf/workers.template /opt/spark-3.2.1/conf/workers
vim /opt/spark-3.2.1/conf/spark-env.sh
export SCALA_HOME=/opt/scala-2.12.15
export JAVA_HOME=/opt/jdk1.8.0_171
export SPARK_MASTER_IP=BigData01
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=/opt/HadoopHA
#export SPARK_MASTER_WEBUI_PORT=8080
#export SPARK_MASTER_PORT=7070
vim /opt/spark-3.2.1/conf/workers
BigData02
BigData03
scp -r /opt/spark-3.2.1/ BigData02:/opt/
scp -r /opt/spark-3.2.1/ BigData03:/opt/
vim /etc/profile
export SPARK_HOME=/opt/spark-3.2.1
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin
source /etc/profile
主节点下:
cd /opt/spark-3.2.1/sbin/
./start-all.sh
三个节点分别:
jps
三、效果

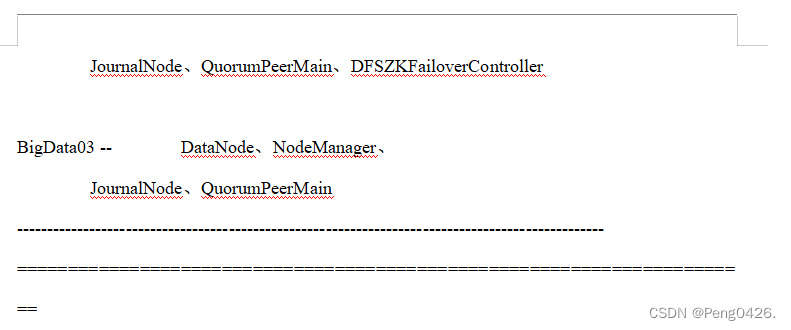




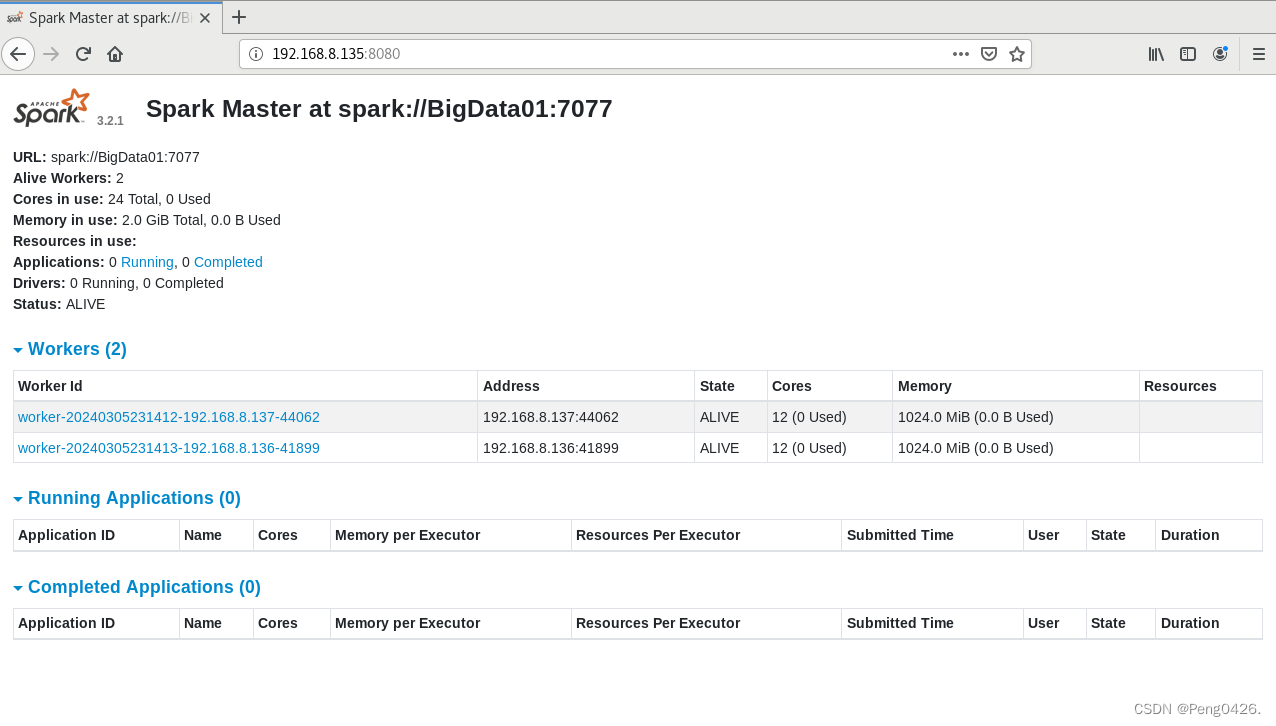
拓展-Hadoop生态系统组件
| 组件 | 简略作用 |
|---|---|
| HDFS (Hadoop Distributed File System) | 用于存储和管理大规模数据集,提供高可靠性、可扩展性和高吞吐量的数据存储。 |
| MapReduce | 分布式计算框架,用于并行处理大规模数据集,实现大数据量的计算和分析。 |
| YARN (Yet Another Resource Negotiator) | 集群资源管理器,负责管理和调度集群中的计算资源,允许多租户并行运行不同的作业。 |
| Hive | 基于Hadoop的数据仓库基础设施,提供类似SQL的查询语言(HiveQL),用于处理和分析结构化数据。 |
| Pig | 数据流编程语言和执行环境,用于在Hadoop上进行数据转换和分析,简化大数据处理过程。 |
| HBase | 分布式列存数据库,用于存储非结构化和半结构化数据,提供高可靠性、高性能的数据存储和访问能力。 |
| ZooKeeper | 分布式协调服务,用于维护服务器状态信息、存储配置信息、实现命名服务和集群管理。 |
| Spark | 快速、通用的大数据处理引擎,可以在内存中进行数据处理,提供高效的数据分析和计算能力。 |
| 组件 | 简略作用 |
|---|---|
| Sqoop | 用于在Hadoop和传统数据库之间进行高效的数据传输,可以实现数据的导入和导出操作。 |
| Oozie | 工作流调度系统,用于定义和管理Hadoop作业的工作流,实现作业的自动化执行和调度。 |
| Flume | 分布式、可靠和高可用的服务,用于有效地收集、聚合和移动大量日志数据。 |
| Ambari | 管理工具,用于安装、配置、监控和管理Hadoop集群,提供直观的用户界面和强大的管理功能。 |
| Tez | 基于Hadoop YARN的框架,用于优化执行速度,使得Hive、Pig等处理引擎能够更快地处理数据。 |
| Flink | 一个流处理和批处理的开源平台,可以在Hadoop上运行,提供高效的数据处理和分析能力。 |