目录
摘要
ABSTRACT
1 论文信息
1.1 论文标题
1.2 论文摘要
1.3 论文背景
2 论文模型
2.1 问题描述
2.2 模型信息
2.2.1 Series-aware Global Tokens(序列感知全局标记)
2.2.2 Graph Structure Learning(图结构学习)
2.2.3 Iterative Message Passing(迭代信息传递)
3 相关代码
摘要
本周阅读了一篇时间序列预测的论文,改论文模型(SageFormer)使用GNN结合Transformer的框架实现。SageFormer在使用Transformer建模序列间依赖关系的同时还注重于使用GNN建模序列间依赖关系,减少跨序列的冗余信息。模型主要包括两个过程:全局标记的生成、迭代的消息传递。全局标记的生成为每个序列添加了随机初始化的可学习标记,以封装它们对应的全局信息,以此增强序列感知能力。迭代的消息传递使得全局信息在每个序列的所有标记之间进行传播,以此捕获序列内部和序列间的依赖关系。
ABSTRACT
This week, We read a paper on time series prediction, which introduces a model called SageFormer that utilizes a framework combining GNN with Transformer. SageFormer focuses on modeling both intra-series and inter-series dependencies using Transformer for the former and GNN for the latter, aiming to reduce redundant information across series. The model mainly consists of two processes: the generation of global tokens and iterative message passing. The generation of global tokens involves adding randomly initialized learnable tokens to each series to encapsulate their corresponding global information, thereby enhancing series awareness. The iterative message passing facilitates the propagation of global information among all tokens within each series, capturing both intra-series and inter-series dependencies.
1 论文信息
1.1 论文标题
SageFormer: Series-Aware Framework for Long-Term Multivariate Time Series Forecasting
1.2 论文摘要
在新兴的物联网生态系统中,多元时间序列(MTS)数据变得无处不在,凸显了时间序列预测在众多应用中的基础作用。长期MTS预测的关键挑战是如何找到能够捕捉序列内和序列间依赖关系的成熟模型。最近深度学习的进展,特别是Transformer中,展现出了解决这一问题的希望。然而,许多流行的方法要么边缘化了序列间的依赖关系,要么完全忽略了它们。为弥补这一缺失,本文提出了一个新的序列感知框架,明确地强调这种依赖关系的重要性。这个框架的核心在于论文模型:SageFormer。作为一种序列感知的图增强Transformer模型,SageFormer可以使用图结构熟练地识别和建模序列之间的复杂关系。除了捕获不同的时间模式,它还减少了跨序列的冗余信息。值得注意的是,序列感知框架与现有的基于Transformer的模型无缝集成,丰富了它们理解序列间关系的能力。在真实数据集和合成数据集上的广泛实验验证了SageFormer相对于当前最先进方法具有更加优秀的性能。
1.3 论文背景
随着物联网(IoT)的兴起,越来越多的互连设备已经进入人们的日常生活,从工业和智能家居到医疗保健和城市规划。这些设备持续产生、交换和处理大量数据,形成了一个复杂的通信网络。在产生的各种数据形式中,多元时间序列(MTS)数据是一种特别普遍且关键的类型。源自物联网设备内部多个传感器或处理器的同时观测,MTS数据呈现出物联网固有的复杂相互作用和时间动态的现象。在这个蓬勃发展的物联网驱动的数据环境中预测未来行为至关重要。在物联网系统中,预测MTS数据优化操作并确保安全,特别是在能源、交通和天气等关键领域。尽管目前的研究大多强调了对短期预测的需求,以应对即时挑战,但长期预测领域同样具有重要意义。长期预测为人们提供了对MTS数据中更大时间模式和关系的洞察。然而,在长时间范围内进行建模会放大即使是十分微小的噪声,使任务变得更加具有挑战性,但也无疑具有重要价值。
近年来,深度学习方法,尤其是采用Transformer架构的方法,在长期多元时间序列(MTS)预测任务中表现出色,超过了传统技术如ARIMA和SSM。许多基于Transformer的模型主要关注时间依赖性,通常通过线性变换将各种序列合并为隐藏的时间嵌入,被称为“序列混合框架”。然而,在这些时间嵌入中,序列间的依赖关系并没有被明确建模,导致信息提取效率低下。有趣的是,一些最近的研究发现,有意排除序列间依赖性的模型,被称为“序列独立框架”,由于其对分布漂移的增强鲁棒性,可以产生显著改进的预测结果。然而,对于某些数据集来说,这种方法可能并不理想,因为它完全忽视了序列间的依赖关系。这凸显了在建模序列内部和序列间依赖关系时所需的复杂平衡,这是MTS预测研究的一个关键领域。
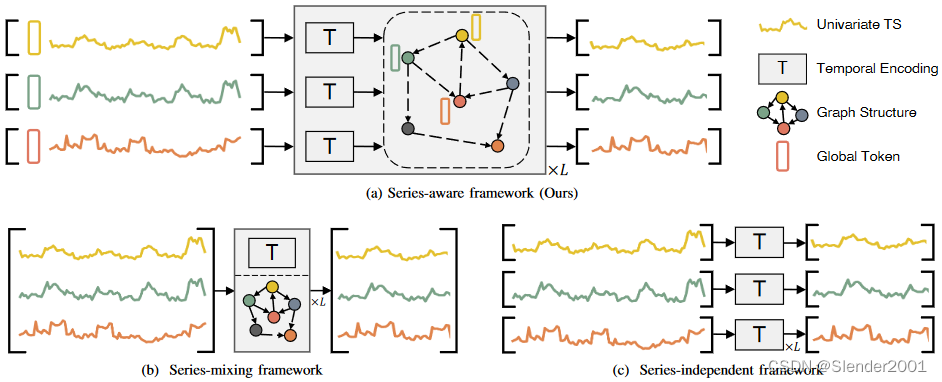
在本文中,作者引入了“序列感知框架”来填补这一研究空白,深入探讨了长期MTS预测问题中序列间依赖关系的复杂性。论文中介绍了旨在精确建模序列间依赖关系的序列感知框架,如Fig.1(a)所示。这个框架以论文模型Series-Aware Graph-Enhanced Transformer(SageFormer)为基础,是一个增强了图神经网络(GNN)的序列感知Transformer模型。通过学习图结构,旨在利用可交互的全局标记区分序列,并通过图聚合提高跨序列的多样化时间模式建模能力。序列感知框架可以作为Transformer结构的通用扩展,更好地利用序列内部和序列间的依赖关系,并在不显著增加模型复杂性的情况下实现卓越性能。
2 论文模型
2.1 问题描述
在论文中,模型专注于长期多元时间序列(MTS)预测任务。设表示时间步
时
个序列的值。给定长度为
的历史MTS序列
,目标是预测接下来的
个时间步的MTS值
。最终的目标是利用提出的模型学习一个映射
(当不会引起歧义时,省略下标
)。
模型采用图来表示多元时间序列(MTS)中的序列间依赖关系,并简要概述相关的图相关概念。从图的角度来看,MTS中的不同序列被视为节点,序列之间的关系则用图的邻接矩阵描述。形式上,MTS数据可以被视为一个信号集合。节点集合
包含MTS数据的
个序列,而
则是一个加权邻接矩阵。元素
表示序列
和
之间的依赖关系。如果它们不相关,则
等于零。
2.2 模型信息
如Algorithm1所示,序列感知框架旨在预测多元时间序列(MTS)数据。框架主要包括两个过程:全局标记的生成、迭代的消息传递。在消息传递机制中,可以利用现代架构来进行序列间和序列内信息的传播。SageFormer是序列感知框架的一个具体实例。它有效地利用图神经网络(GNNs)来建模序列间的依赖关系,同时利用Transformer来捕捉序列内的依赖关系。因此,它确保了模型全面掌握了序列感知设置的基本动态。整体结构遵循Transformer编码器设计,并用更高效的线性解码器头(ForecastingHead)取代传统的Transformer解码器。凭借其独特的GNNs和Transformer的结合,SageFormer成为了捕捉和建模序列内和序列间关系本质的一种十分具有潜力的解决方案。

2.2.1 Series-aware Global Tokens(序列感知全局标记)
在Transformers中的传统方法涉及通过对输入时间序列进行逐点或逐块拆分来获取输入标记。这是为了使这些标记包含局部语义信息,然后通过自注意机制来检查它们之间的相互连接。
论文的方法提出了一个关键的创新点:将全局标记集成到模型中以增强序列感知能力,这一概念受到了自然语言处理模型和视觉Transformer中的类标记的启发。为每个序列添加了随机初始化的可学习标记,以封装它们对应的全局信息。这些全局标记不仅仅是占位符,同时用于在第一层自注意力之后捕获和增强序列内部的时间信息。利用这些全局标记来有效捕获系列间的依赖关系。通过它们参与基于GNN的序列间信息传递,从而增强每个子序列的序列感知能力。


2.2.2 Graph Structure Learning(图结构学习)
在SageFormer中,邻接矩阵是端到端学习的,从而能够捕捉到系列之间的关系,而无需先验知识。在多元时间序列(MTS)预测中,假设序列之间的依赖关系是单向的。例如,尽管电力负载可能影响油温,但反之则不一定成立。这种有向关系在推导的图结构中得到了表示。值得注意的是,许多时间序列缺乏内在的图结构或补充的辅助数据。然而,论文的方法能够仅通过数据推断出图结构,无需外部输入,从而增强了其多功能性和广泛适用性。

2.2.3 Iterative Message Passing(迭代信息传递)
嵌入标记通过SageFormer编码器层进行处理,其中进行了迭代的时间编码和图聚合(Fig.2)。这种方法目的是在GNN阶段收集的全局信息在每个序列的所有标记之间进行传播。因此,模型通过迭代消息传递捕获了序列内部和序列间的依赖关系。

需要注意的是,节点嵌入和全局标记都是随机初始化的,然后通过迭代的消息传递过程进行优化。尽管这种强调标记的独特方法与图聚合中的典型GNN方法一致,但两种方法的输入张量具有相同的格式,其尺寸为(b,n,d),其中代表批大小,
代表图中的节点数,
代表特征维度。此外,由于在初始层引入了一个时间编码操作,所以在图聚合阶段,全局标记不仅仅是随机实体。相反,它们在变量中具有全面的全局信息。这种设计确保了全局标记对模型的收敛产生积极影响。
3 相关代码
Transformer内部多头注意力机制的实现:
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
# 三个线性层做矩阵乘法生成q, k, v.
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
# ScaledDotProductAttention见下方
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# b: batch_size, lq: translation task的seq长度, n: head数, dv: embedding vector length
# Separate different heads: b x lq x n x dv.
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k) # project & reshape
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
# (batchSize, 1, seqLen) -> (batchSize, 1, 1, seqLen)
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
# view只能用在contiguous的variable上
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
# add & norm
q += residual
q = self.layer_norm(q)
return q, attn