文章目录
- 一、什么是消息队列?
- 二、当下主流的消息队列(MQ)
- 三、自我实现一个消息队列服务器的前期准备——需求分析
- 3.1 核心概念
- 3.2 broker server 核心概念
- 3.2.1、虚拟主机(Virtual Host)
- 3.2.2、交换机(Exchange)
- 3.2.2.1 交换机类型
- 3.3.3、队列(Queue)
- 3.3.4、绑定(Binding)
- 3.3.5、消息(Message)
- 3.3 broker server 需要对外提供的接口
- 3.4 存储(涉及持久化存储)
- 3.5 网络通信
- 3.5.1 Connection Channel
- 四、总结
一、什么是消息队列?
消息队列是将阻塞队列这样的数据结构,单独提取成一个程序,独立部署在一组服务器上。但阻塞队列是在一个进程内部进行的,而消息队列是在进程与进程(服务与服务)之间进行的。
如果有同学不知道什么是阻塞队列,点击我前面写的博客多线程的典型例子——阻塞队列进行查漏补缺。
二、当下主流的消息队列(MQ)
当下市场主流的消息队列服务器有 :
1、RabbitMQ(参考RabbitMQ来自我实现一个消息队列)
2、kafka
3、 RocketMQ(阿里自己实现的一个消息队列服务器,一般阿里公司内部在使用,阿里将RocketMQ开源在社区,一些开发者也在使用RocketMQ)
4、ActiveMQ
三、自我实现一个消息队列服务器的前期准备——需求分析
3.1 核心概念
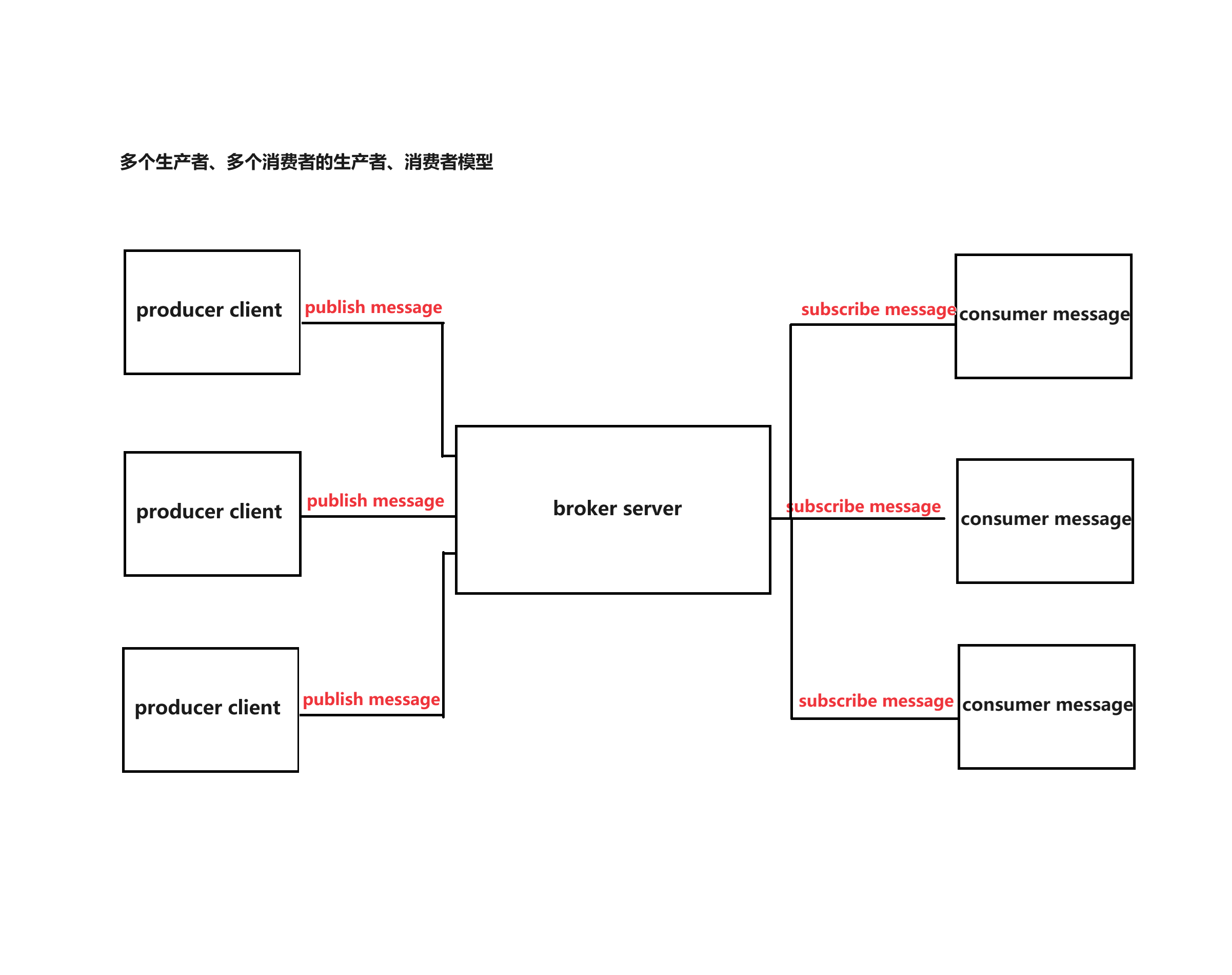
阻塞队列、消息队列都是生产者-消费者模型的应用场景,因此实现一个消息队列的前提是首先了解以下6个概念:
1、生产者(Producer)
一般是生产资源的一方。譬如说客户端-服务器中,客户端向服务器发起请求,这里的用户请求就是生产者生产出来的资源。
2、消费者(Consumer)
获取到资源的一方。譬如说有一个分布式系统,A服务器向B服务器发起请求,B获取到A的请求后(获取到资源),根据该请求计算出响应,把响应返回给A。
3、中间人(Broker)
一般指服务器
4、发布(Publish)
生产者向中间人这里投递消息的过程
5、订阅(Subscribe)
消费者从中间人这里获取数据时这个注册的过程,叫做“订阅”
6、消费(Consume)
消费者从中间人这里取数据的动作。
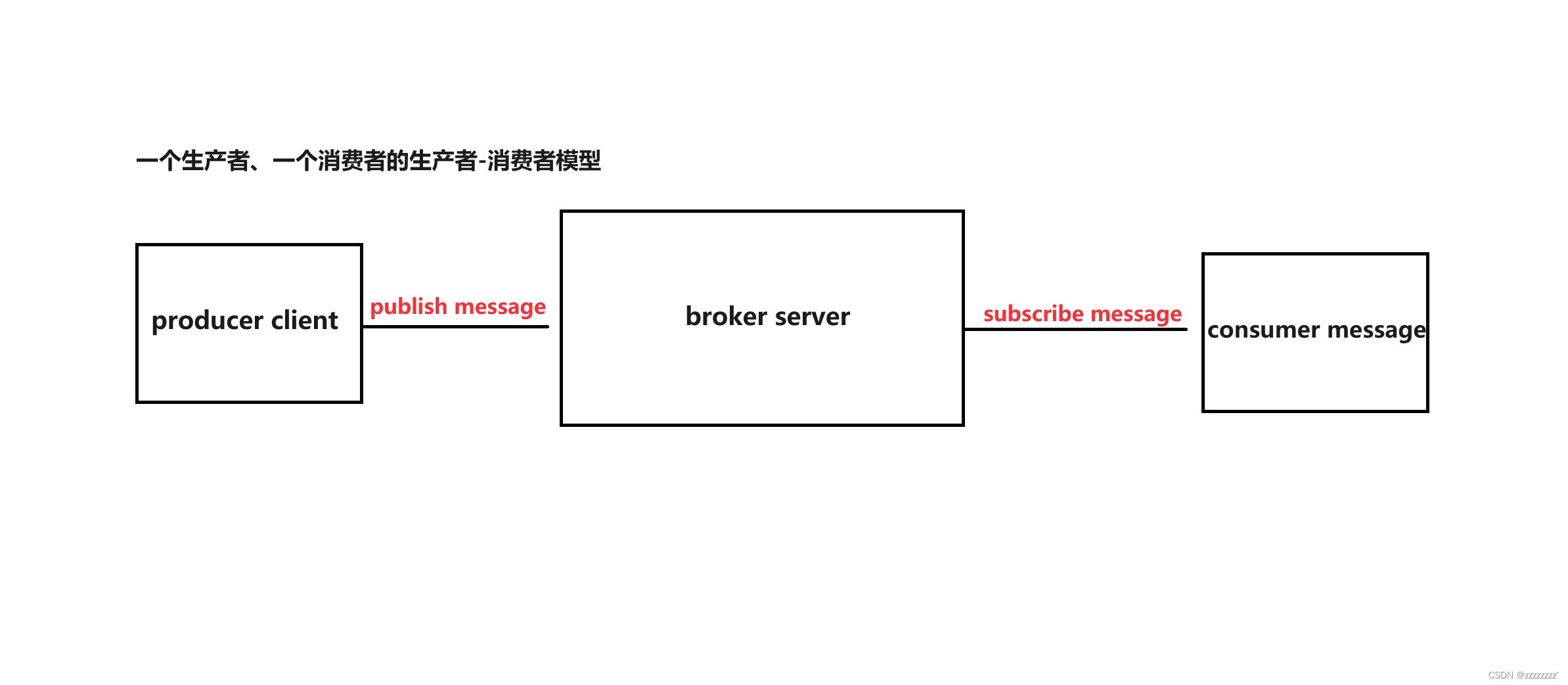
现在常见的生产者-消费者模型:
3.2 broker server 核心概念
上述的这两者模型中,broker server 是最核心的部分,他负责消息的存储和转发。 一个broker server 又存在以下的核心概念:
3.2.1、虚拟主机(Virtual Host)
一个broker server 可以包含多个虚拟主机,虚拟主机的作用就类似于MySQL中的database,算是一个逻辑上的数据集合。 实际开发中,一个 broker server 可能会同时用来管理多组业务线上的数据,此时可以使用 virtual host 进行区分。
举个例子加深印象。日常我们打开百度这样的搜索引擎首页时,其首页会划分许多业务模块,点击不同的业务模块,会体验到不同的功能。譬如下图:

3.2.2、交换机(Exchange)
生产者将消息投递给 broker server,实际上是先把消息交给了 broker server 上的某个交换机,再由交换机把消息转发给对应的队列。
譬如说,某天小明去一家公司面试,来到公司,先找到前台工作人员说明来意,前台工作人员了解之后就会将小明带到相应的部门办公室与面试官进行面试。
此处小明就是消息,前台工作人员就是交换机,公司就是broker server,相应部门的面试官就是队列。
3.2.2.1 交换机类型
RabbitMQ主要实现了四种交换机,不同类型的交换机,在将消息转发给对应队列时,有不同的一套转发规则。
1、Direct (直接交换机)
生产者发送消息时,会指定的要求将此消息发送到指定的队列中,因此会指定一个 “目标队列” 的名字,交换机收到该具有指定队列名字的消息后,会查看当前绑定的队列中是否有匹配的队列,如果有,交换机就会将此消息转发给目标队列,如果该交换机当前绑定的队列中没有目标队列,此时该消息会被直接丢弃。
譬如我们在QQ上发送红包时,我们指定该红包只能被某个好友领取,如果该指定好友不领取该红包,该红包到了时间就会被退回到发送者账户中(相当于丢弃),该指定好友领取的QQ红包,其他好友是没办法领取的。
2、Fanout (扇出交换机)
生产者发送消息时,交换机收到消息后,会将此将消息转发给当前自己绑定的所有队列中。
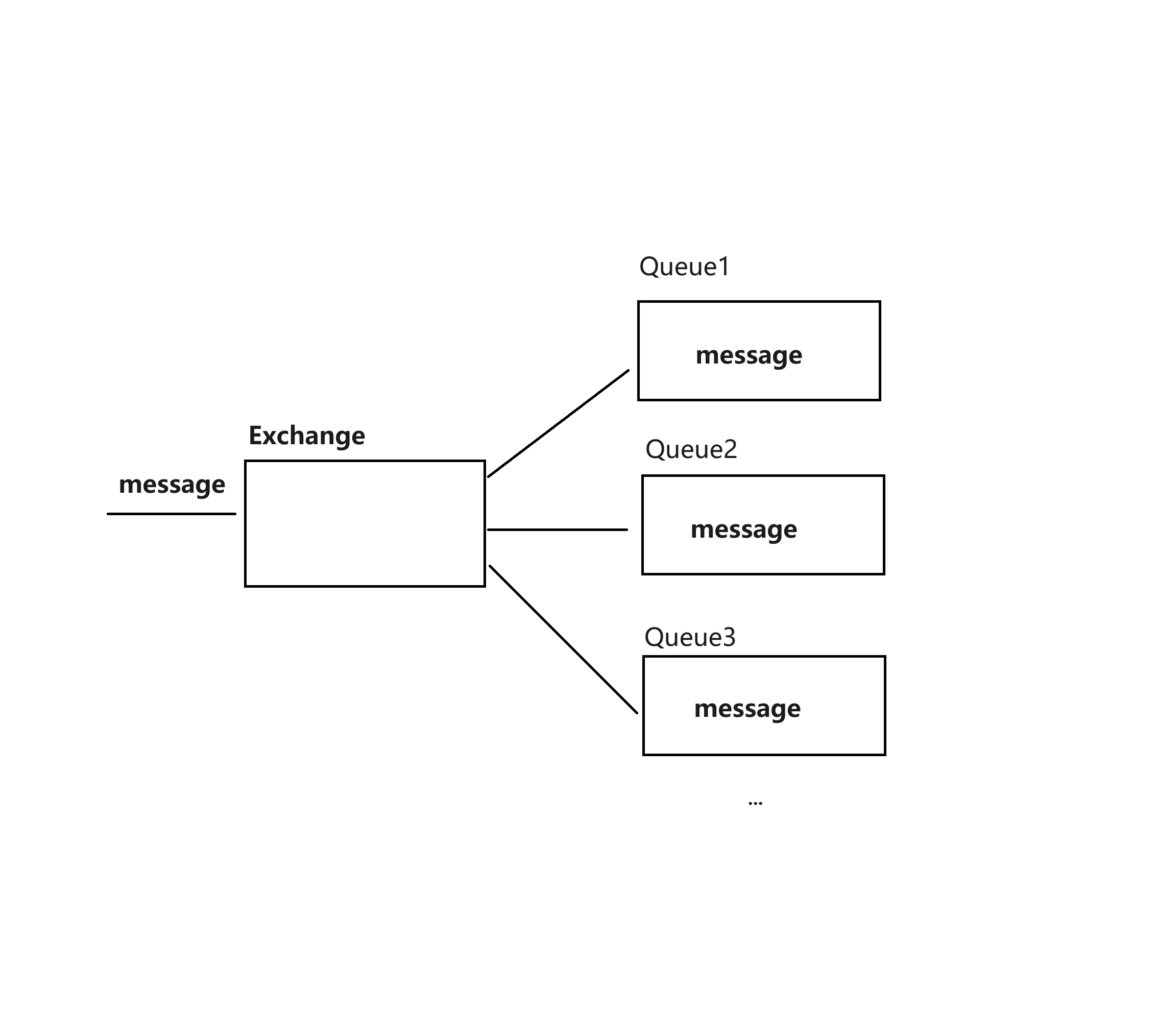
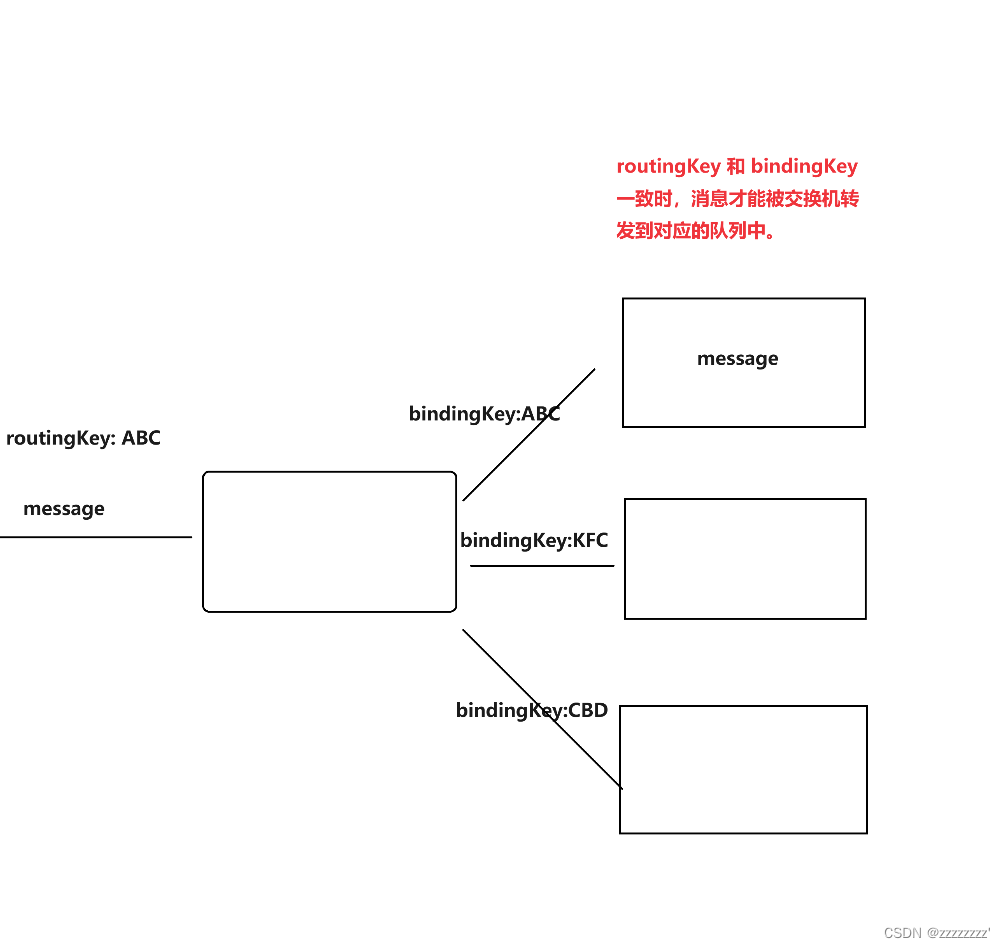
3、Topic (主题交换机)
这个交换机的转发规则则比前两个复杂一点。具有两个关键字。
1)、bindingKey:队列和交换机绑定的时候,队列指定一个单词。
2)、routingkey:生产者发送消息时,也指定一个单词。
如果当前 bindingKey 和 routingkey 能够一致(对上暗号),此时交换机就可以把这个消息转发到对应的队列中了。
bindingKey 就像是房子的锁,routingKey 就像是钥匙,只有钥匙和锁芯一样,才能打开这个房子。
4、Header (消息头交换机)
规则复杂,应用场景较少。
3.3.3、队列(Queue)
队列是真正用来存储待处理消息的实体,后续消费者也是从对应的队列中取数据。我们要把消息队列(Message Queue)和队列(Queue)区分开来,一个消息队列里,可以有很多个队列。
3.3.4、绑定(Binding)
把交换机和队列之间,建立起关联关系。可以把交换机和队列的关系视为数据库中的“多对多”关系。在数据库中,表示多对多关系,会使用一个中间表/关联表,在中间表中,A表的主键是B表的外键,B表的主键是C表的外键…在消息队列中,也是有这样一个中间表,通常将交换机的身份标识和队列的身份标识作为绑定的身份标识。
一个交换机可以为多个队列转发消息,譬如说,一家公司一天有应聘不同部门的人过来面试,前台工作人员在了解情况后,会将应聘不同部门的人领到不同的面试官面前;同样的,一个队列也可以被多个交换机投递消息,公司的前台工作人员A上午为接待前来面试的小明,小明与面试官面试完以后,下午又过来面试别的岗位,此时由前台工作人员B接待了小明,将小明带到了相应的部门办公室与面试官进行面试。
3.3.5、消息(Message)
具体来说,可以认为是服务器A给B发的请求(该请求通过MQ转发),就是一个消息。服务器B给A返回的响应(通过MQ转发),也是一个消息。一个消息,可以视为是一个 字符串(二进制数据),消息中具体包含怎样的数据,都是程序员自己定义的。
RabbitMQ就是按照下图的结构组织的,我们自己实现的MQ是基于RabbitMQ作为参照,因此结构也是由如下结构组织的一样。那为什么RabbitMQ是按照这样的结构组织的呢?这些概念并不是我们凭空想象出来的,而是遵从了AMQP这个协议的规定。

那我们知道了broker server 是为了进行数据的存储和转发,那么其他服务器(譬如一些生产者客户端(producer client)、消费者客户端(consumer client)…)想要使用这个服务器进行数据交互时,broker server 就需要提供对外的接口(API)给其他服务器进行调用完成业务。
3.3 broker server 需要对外提供的接口
因此,broker server 需要提供如下9个对外的接口:
1、创建交换机(exchangeDeclare)
此处创建队列的方法名不起作 exchangeCreate 是因为,此处的方法是在交换机不存在的情况下才创建一个新的创建机,如果交换机存在,那就不创建。
2、销毁交换机(exchangeDelete)
3、创建队列(queueDeclare)
4、销毁队列(queueDelete)
5、创建绑定(queueBind)
6、解除绑定(queueUnbind)
7、发布消息(basicPublish)
8、订阅消息(basicConsume)
9、确认消息(basicAck)
这个接口起到的效果是为了,当消费者将存储在broker server 中的消息获取到了之后,消费者显式地告诉 broker server 这个消息我已经使用、处理完毕了,此时这个消息的后续由broker server 进行管理,是继续持久化存储在broker server 中还是定期删除,由 broker server 自己进行处理。此时提高了系统的可靠性,保证消息处理没有遗漏。
举个例子。譬如一些办公软件:微信企业版、钉钉…招聘网站:boss直聘、拉钩…这些网站,当进行发送消息时,如果接收者收到消息后,消息旁会提示一个“已读”,此时发送者就可以通过这个“已读”提示,清楚的知道消息已经被接受者接收到了,至于接收者收到消息之后是进行回复还是已读未回,这些都不是发送者该考虑的事情了,发送者只要通过这个“已读”提示确保这个消息已经发送成功即可。
确认消息(basicAck)有两种应答模式:
1、自动应答:消费者取走该消息之后,就算应答(相当于没有应答)
2、手动应答。即消费者取走该消息之后,调用 basicAck() 进行应答。
我们的 broker server 中,这两种应答模式都支持。
3.4 存储(涉及持久化存储)
上述所说的这些概念:虚拟主机、交换机、队列、绑定、消息 都由 broker server 进行管理,这些概念所对应的数据,都需要存储和管理起来。我们考虑将这些概念对应产生的数据在内存和硬盘各自存储一份,主要以内存为主,硬盘为辅。
对于MQ来说,能够高效的转发、处理消息,是关键的指标。因此使用内存来组织上述数据得到的效率比在硬盘中存储高得多。但是如果将数据直接存储在内存中,由于内存断电重启数据易失,因此为了防止内存中的数据随着进程/主机重启而丢失,再将数据存一份在硬盘中。(硬盘能够持久化存储数据,但一般硬盘能存储数据的时间最多是十几年,因此这个持久化也只是相对的)。
3.5 网络通信
其他的服务器(生产者/消费者)想要和 broker server 进行数据交互时,就需要通过网络进行通信。此处我们设定使用TCP + 自定义的应用层协议,实现生产者(producer client)/消费者(consumer client) 和 broker server 之间的交互工作。
自定义应用层协议要做的主要工作:让客户端可以远程通过网络调用 broker server 里对外提供的接口。因此客户端里也需要具有 broker server 中的接口,但客户端里的这些与 broker server 名称相同的接口不需要进行具体的业务逻辑实现,是为了进行发送请求和接收响应的,而broker server 中的接口需要进行数据的处理所以需要进行具体的业务逻辑实现,以便客户端调用后进行具体业务实现。
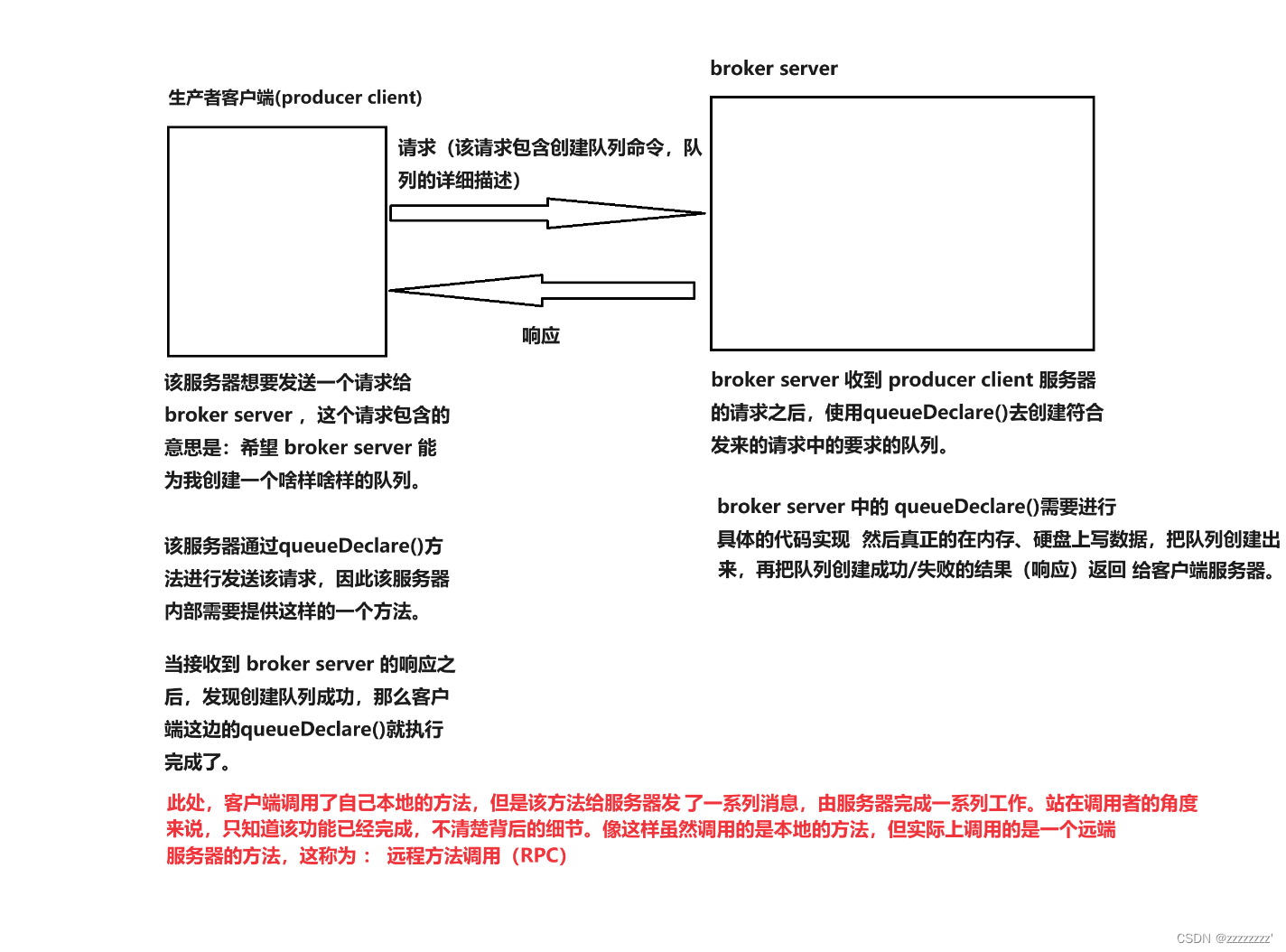
对远程方法调用这个概念举个例子吧。通常大学生在校需要完成一些课程设计,小明觉得课程设计太难了,自己不会写,在网络上找了专业的代写团队代写该课程设计,然后上交该作业。老师收到小明的课程设计作业,也不知道这个作业是小明自己写的还是抄的,他只知道小明已经按时上交了作业。
3.5.1 Connection Channel
客户端除了具有上述9个与 broker server 相同的api外,还需要4个api。分别是:
1、创建连接(connectionDeclare)
2、销毁连接(connectionClose)
3、创建信道(channelDeclare)
4、销毁信道(channelClose)
我们的 broker server 和其他的服务器进行通信时,使用TCP协议以及我们自定义的应用层协议,在前面的网络通信课程中,我们学习了TCP协议,知道频繁地使用TCP建立连接(3次握手)和断开连接(4次握手)的成本较高,因此此处我们定义Connection,一个Connection就相当于一个TCP连接,而一个Connection里可以含有多个Channel,每个Channel上传输的数据互不相干。
使用 connectionDeclare() 建立TCP连接后,在TCP中创建一个Channel,使用Channel进行通信,通信完成后,我们不着急断开TCP连接,只需要将Channel销毁即可,TCP连接不变。Channel只是一个逻辑上的概念,其创建、销毁成本较低,比较轻量。引入Channel就是为了复用TCP。
四、总结
通过上述需求分析,了解到了实现一个消息队列服务器需要进行的工作有:
1、需要实现 生产者、消费者、broker server 三个部分。
2、针对生产者(producer client)和消费者(consumer client)来说,主要编写的是 客户端(client)和服务器(server) 进行网络通信的部分。
客户端 和 服务器 进行网络通信的方式:客户端内部需要提供与服务器内部相同的api,但是其作用与服务器中的api作用不同,客户端通过本地的api,调用远程服务器上的api,完成业务。至于生产者的数据从哪里来,消费者取到消息之后要干啥…这些生产者、消费者的具体业务逻辑,我们并不关心。
因此我们此时实现的消息队列服务器可以给任何客户端使用,只要该客户端是需要使用 broker server 进行 数据的存储、转发。因此此时的消息队列服务器是通用的,并不涉及业务代码的实现。每个需要进行数据存储、转发的客户端都能够使用该服务器实现。
3、重点实现 broker server 以及 broker server 内部的基本概念以及核心接口(api)
broker server 内部的基本概念:就是前面提到的 虚拟主机(Virtual Host)、交换机(Exchange)、队列(Queue)、绑定(Binding)、消息(Message)。这些都是由我们的 broker server 进行管理,他们需要在内存和硬盘(持久化存储)中各存一份。
broker server 的 核心接口(api):上述提到过的9个api:
1、创建交换机(exchangeDeclare)
2、销毁交换机(exchangeDelete)
3、创建队列(queueDeclare)
4、销毁队列(queueDelete)
5、创建绑定(queueBind)
6、解除绑定(queueUnbind)
7、发布消息(basicPublish)
8、订阅消息(basicConsume)
9、确认消息(basicAck)
实现上述核心api时,都需要用到broker server 内部基本概念的数据。
上述所做的工作,是为了实现一个 “分布式系统下” 的一个生产者消费者模型。 但是当前我们实现的 broker server 并不支持分布式部署,只是一个单机的 broker server(broker server 里面只含有一个 Virtual Host),可为多个生产者消费者提供服务。
但是如今主流的MQ:RabbitMQ、kafka…这些消息队列都是支持分布式部署(集群功能)(broker server 里含有多个 虚拟主机)。分布式部署能够提高mq的可用性,处理更高的并发,数据相互备份以致数据不易丢失。
分布式部署的mq比单机版的mq复杂,因此此处我们暂时只实现单机版的消息队列,但是单机版的mq也为了后续支持分布式部署保留了接口。