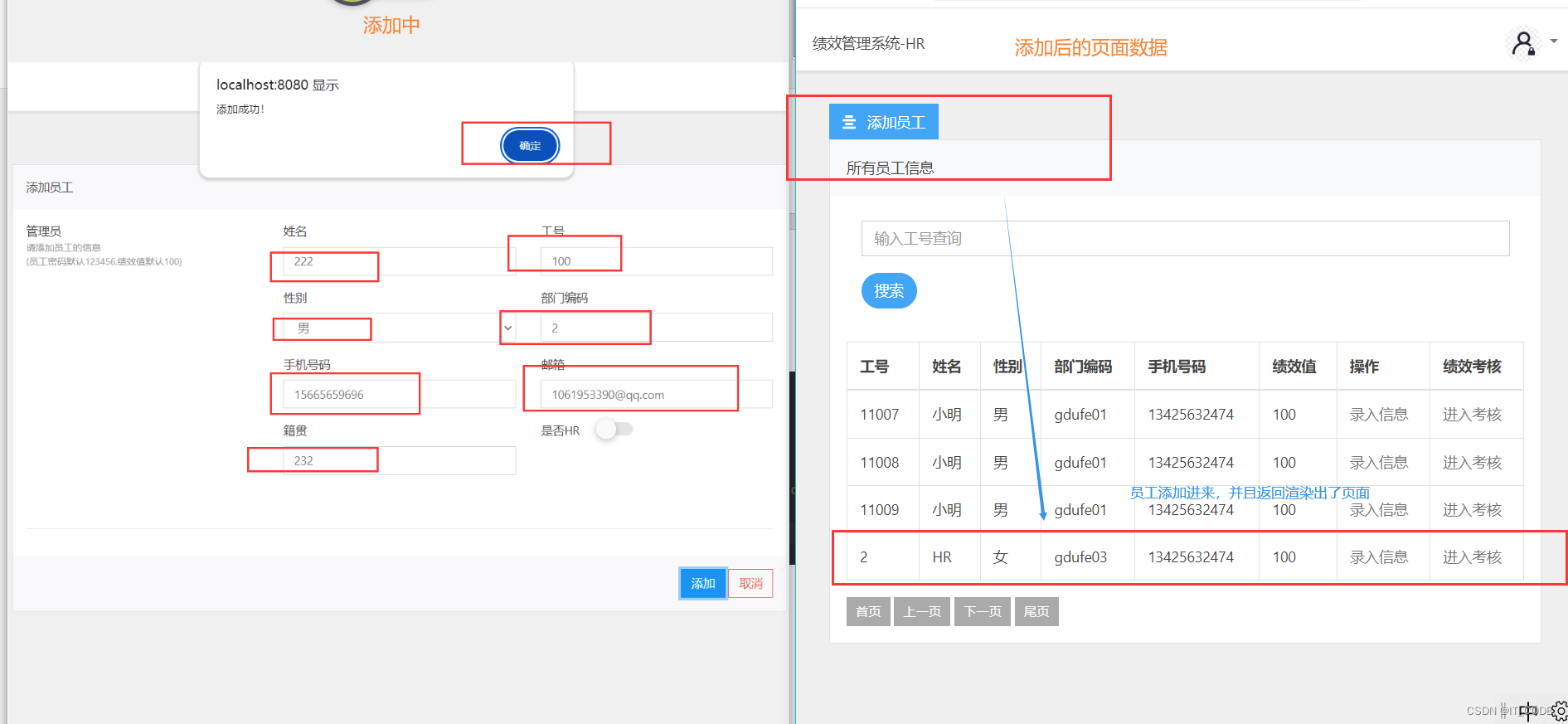
What:Swin Transformer
用了移动窗口的层级式的Vision Transformer.
Swin Transformer的思想是让Vision Transformer也能像CNN一样也能分成几个block,也能做层级式的特征提取,从而让提取的特征具有多尺度的概念。(设计的初衷是作为计算机视觉领域通用的骨干网络)
SW-MSA:shifted windows-multi-head self-attention
缺点:但是在模型大一统上,也就是 unified architecture 上来说,其实 ViT 还是做的更好的,因为它真的可以什么都不改,什么先验信息都不加,就能让Transformer在两个领域都能用的很好,这样模型不仅可以共享参数,而且甚至可以把所有模态的输入直接就拼接起来,当成一个很长的输入,直接扔给Transformer去做,而不用考虑每个模态的特性
Why:
1、因为ViT 在结论的部分指出,他们那篇论文只是做了分类任务,把下游任务比如说检测和分割留给以后的人去探索,所以说在 ViT 出来之后,大家虽然看到了Transformer在视觉领域的强大潜力,但是并不确定Transformer能不能把所有视觉的任务都做掉,所以 Swin Transformer这篇论文的研究动机就是想告诉大家用 Transformer没毛病,绝对能在方方面面上取代卷积神经网络,接下来大家都上 Transformer 就好了
Challenge:
Transformer在计算机视觉领域的应用仍然面临着一些挑战
- 对目标的多尺度检测(Transformer没有卷积,没有对图像做下采样,所以他没有检测多尺度的能力,VIT每个层级都是用的16x的下采样,无法精准识别多尺度窗口)
至于为什么卷积能提取多尺度信息:每个卷积核的感受野是指它在输入特征图上能够看到的区域大小。在浅层的卷积层中,卷积核的感受野较小,只能看到输入特征图的局部区域。但随着网络的深入,每个卷积层都会通过较大的卷积核和步幅来扩大感受野,以便捕捉更广阔的上下文信息。
池化操作的主要作用是通过降采样的方式减小特征图的空间尺寸,从而减少计算量和参数数量,同时保留主要的特征信息。在池化过程中,通常使用最大值池化或平均值池化等方法。通过池化操作,每个池化窗口内的特征被汇聚成一个单一的值,这个值代表了该窗口内的主要特征。当池化操作应用于卷积层输出时,特征图的尺寸会减小,但是池化窗口的大小可以自由选择。通过适当选择池化窗口的大小和步幅,可以扩大卷积核的感受野。池化层的输出作为下一层的输入,使得下一层的卷积核能够看到更广阔的感受野。
目标检测用FPN抓住不同尺寸的物体特征
对物体分割用UNet抓住不同尺寸的物体特征
(对计算机视觉的下游任务,尤其是密集预测型的任务(检测,分割),有多尺寸的特征是至关重要的)
- 图像经过处理放入Transformer的token个数往往比一个句子转化过后的token个数多得多。如果要以像素点作为基本单位的话,序列的长度就变得高不可攀,计算量就会变得非常的大所以说之前的工作要么就是用后续的特征图来当做Transformer的输入,要么就是把图片打成 patch 减少这个图片的 resolution,要么就是把图片画成一个一个的小窗口,然后在窗口里面去做自注意力,所有的这些方法都是为了减少序列长度
- 作者采用2中的法三,但是法三的问题是,窗口间的attention无法计算,窗口和窗口之间没有通讯,窗口之间会成为孤立的自注意力,这样就达不到全局建模了,会限制模型的能力。
- 采用移动窗口之后计算attention会面临窗口大小不一的问题
- 解决了窗口大小不一的问题又会面临新窗口内的patch不相邻的问题
Idea:为了解决2、作者将原图画成小窗口,为了解决3,作者提出移动窗口的思想,能够让相邻的两个窗口之间有了交互,所以上下层之间就可以有cross-window connection从而变相地达到了一种全局建模的能力,为了解决1,作者提出hierarchical Transformer,其中层级之间包含了patchmerging操作,(把相邻的小patch和成一个大patch,这样合并出来的这一个大patch其实就能看到之前四个小patch看到的内容,它的感受野就增大了,同时也能抓住多尺寸的特征)相当于CNN中的池化操作,为了解决4,作者提出了一种移动再拼接再分窗的办法,为了解决5,作者提出了一种窗口掩码后再进行attention的方法。
Model:
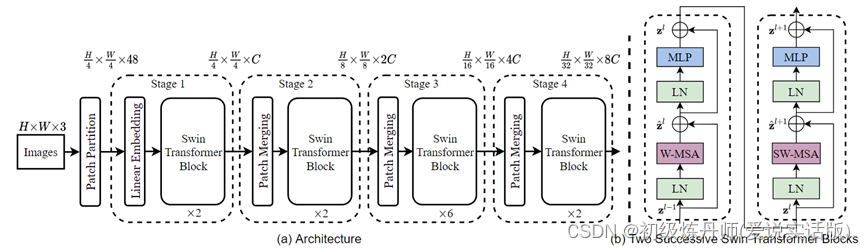
层级式与窗口
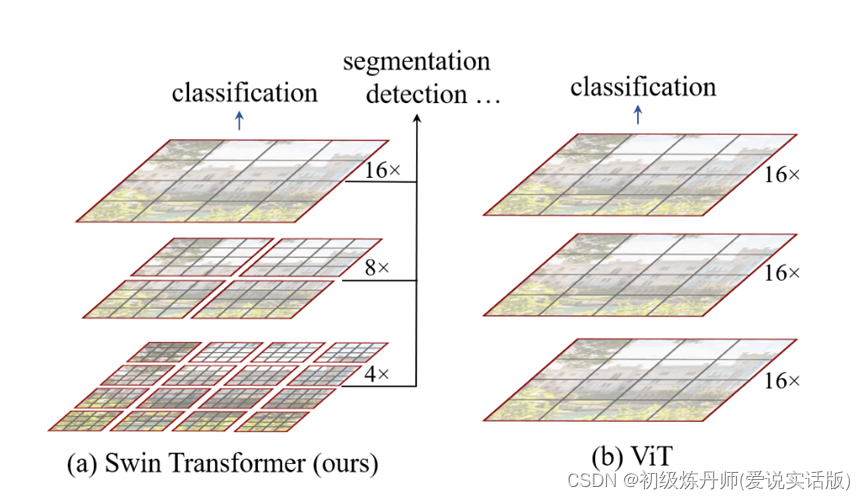
Swin Transformer 刚开始的下采样率是4倍,然后变成了8倍、16倍,之所以刚开始是4×的,是因为最开始的 patch 是4乘4大小的,一旦有了多尺寸的特征信息,有了这种4x、8x、16x的特征图,那自然就可以把这些多尺寸的特征图输给一个 FPN,从而就可以去做检测了(用UNet做分割)
采用窗口计算子注意力的计算复杂度为什么低?
以标准的多头自注意力为例
- 如果现在有一个输入,自注意力首先把它变成 q k v 三个向量,这个过程其实就是原来的向量分别乘了三个系数矩阵
- 一旦得到 query 和 k 之后,它们就会相乘,最后得到 attention,也就是自注意力的矩阵
- 有了自注意力之后,就会和 value 做一次乘法,也就相当于是做了一次加权
- 最后因为是多头自注意力,所以最后还会有一个 projection layer,这个投射层会把向量的维度投射到我们想要的维度
如果这些向量都加上它们该有的维度,也就是说刚开始输入是 h*w*c

首先,to_q_k_v()函数相当于是用一个 h*w*c 的向量乘以一个 c*c 的系数矩阵,最后得到了 h*w*c。所以每一个计算的复杂度是 h*w*c^2,因为有三次操作,所以是三倍的 h*w*c^2
然后,算自注意力就是 h*w*c乘以 k 的转置,也就是 c*h*w,所以得到了 h*w*h*w,这个计算复杂度就是(h*w)^2*c
接下来,自注意力矩阵和value的乘积的计算复杂度还是 (h*w)^2*c,所以现在就成了2*(h*w)^2*c
最后一步,投射层也就是h*w*c乘以 c*c 变成了 h*w*c ,它的计算复杂度就又是 h*w*c^2
最后合并起来就是最后的公式(1)
基于窗口的自注意力计算复杂度又是如何得到的呢?
因为在每个窗口里算的还是多头自注意力,所以可以直接套用公式(1),只不过高度和宽度变化了,现在高度和宽度不再是 h * w,而是变成窗口有多大了,也就是 M*M,也就是说现在 h 变成了 M,w 也是 M,它的序列长度只有 M * M 这么大
所以当把 M 值带入到公式(1)之后,就得到计算复杂度是4 * M^2 * c^2 + 2 * M^4 * c,这个就是在一个窗口里算多头自注意力所需要的计算复杂度
那我们现在一共有 h/M * w/M 个窗口,现在用这么多个窗口乘以每个窗口所需要的计算复杂度就能得到公式(2)了
对比公式(1)和公式(2),虽然这两个公式前面这两项是一样的,只有后面从 (h*w)^2变成了 M^2 * h * w,看起来好像差别不大,但其实如果仔细带入数字进去计算就会发现,计算复杂的差距是相当巨大的,因为这里的 h*w 如果是56*56的话, M^2 其实只有49,所以是相差了几十甚至上百倍的
滑动窗口:Shift的操作

最后shift完就得到下边右图的结果
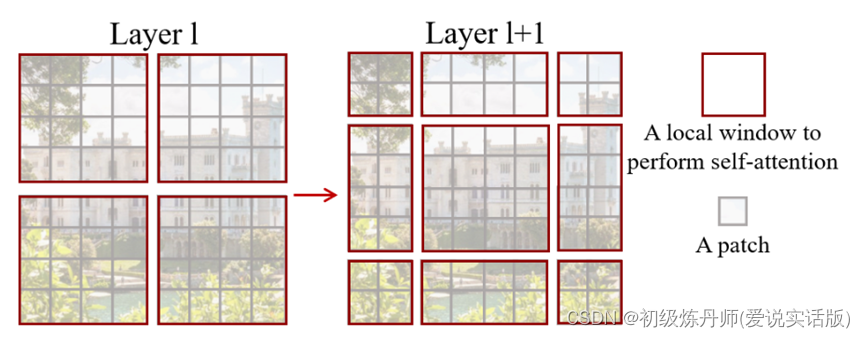
滑动窗口的目的是使窗口与窗口之间可以进行互动,因为如果按照原来的方式,就是没有 shift,这些窗口之间都是不重叠的,如果每次自注意力的操作都在小的窗口里头进行了,每个窗口里的 patch 就永远无法注意到别的窗口里的 patch 的信息,窗口内的自注意力就都变成孤立自注意力,就没与全局建模的能力。这就达不到使用 Transformer 更好的理解上下文的初衷
但如果加上 shift 的操作,每个 patch 原来只能跟它所在的窗口里的别的 patch 进行交互,但是 shift 之后,这个 patch就可以跟新的窗口里的别的 patch就进行交互了,而这个新的窗口里所有的 patch 其实来自于上一层别的窗口里的 patch,这也就是作者说的能起到 cross-window connection,就是窗口和窗口之间可以交互了
再配合上之后提出的 patch merging,合并到 Transformer 最后几层的时候,每一个 patch 本身的感受野就已经很大了,就已经能看到大部分图片了,然后再加上移动窗口的操作,它所谓的窗口内的局部注意力其实也就变相的等于是一个全局的自注意力操作了
Patch Merging操作
Patch Merging顾名思义就是把临近的小patch合并成一个大patch,这样就可以起到下采样一个特征图的效果了,文中的的patch Merging是想下采样两倍,所以说在选点的时候是每隔一个点选一个,经过隔一个点采一个样之后,原来这个张量就变成了四个张量,,如果原张量的维度是h*w*c,经过这次采样之后就得到了四个张量,每个张量的大小是h/2、w/2,4c它的尺寸都缩小了一倍,相当于用空间上的维度换了更多的通道数。通过这个操作,就把原来一个大的张量变小了,通道数变成了原来的四倍,但是卷积神经网络里池化操作是让特征的通道数翻倍而不是变成四倍,这里为了跟CNN保持一致,就在c的维度上用一个1*1的卷积,把通道数降下来变成2c,通过这个操作就能把原来一个大小为h*w*c的张量变成h/2*w/2*2c的一个张量,也就是说空间大小减半,但是通道数乘2,这样就跟卷积神经网络对等起来了
掩码操作:略
位置编码:在attention中改变公式,使用相对位置编码,(在B中体现)
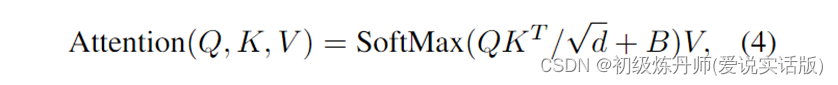
参考:
Swin Transformer论文精读【论文精读】_哔哩哔哩_bilibili