背景:将一本书,存入我们的数据库中,并可以查出来
采用:第三范式(3NF)设计模式
设计数据库模板
-
第一范式(1NF):确保表的每一列都是不可分割的原子数据项。
-
第二范式(2NF):在满足第一范式的基础上,非主键列必须完全依赖于整个主键,而不是主键的一部分。
-
第三范式(3NF):在满足第二范式的基础上,非主键列之间不存在传递依赖关系,即一个非主键列不能依赖于另一个非主键列。
我们通过迭代,一步一步完成到第三范式
第一步:分析书籍是由什么组成的,这样我们才能更好的完成第一范式。
身边有书就拿起书,没书咱们就感谢前辈的努力(crrl+左键)PS:文字作者的休闲时刻奇妙幻想
第一眼,我们可以看见一个叫封面
第二眼,我们可以看见一个叫书名
第三眼,我们可以看见作者的名字
第四眼,侧边有一个出版社(实体书)
第五眼,侧边话还有一个时间
第六眼,书的背面有大佬点评(实体书)
第七眼,我们可以看见字数总和
第八眼,我们可以看见浏览量
第一层组成:封面,书名,作者,出版社,时间,点评,字数,浏览量(我拿三本书看到的信息)
翻开一页,利用上面的那个网站作为例子的,直接看下面就好(点个赞!)
又来了,
第一眼,我们可以看见作者的介绍(目前不涉及)
第二眼,作者写这本书的目的,也就是前言
第二层组成:介绍,前言
再翻几页,我们发现就是那密密麻麻的章节了,没有的按开始提供的网页进行参考
第一眼,我们可以看见加粗的h1标签的章节(凭感觉应该可以看出这个明细是h1打印出来的)
第二眼,每一篇的小标题
第三眼,页数
第三层组成:总章节,每一篇的小标题
第四层就是我们最熟悉的小标题+内容了
这样我们的第一步就完成了,将四层组合一如下
第一层组成:封面,书名,作者,出版社,时间,点评,字数,浏览量
第二层组成:介绍,前言
第三层组成:总章节,每一篇的小标题
第四层组成:小标题,内容
第二步:在第一步的基础上,完成1nf的分析,不可分割的原子数据项。
第一层:封面,书名,作者,出版社,时间,点评,字数,浏览量,已经完成条件不可分割
第二层:介绍,前言,同上
第三层,第四层一样
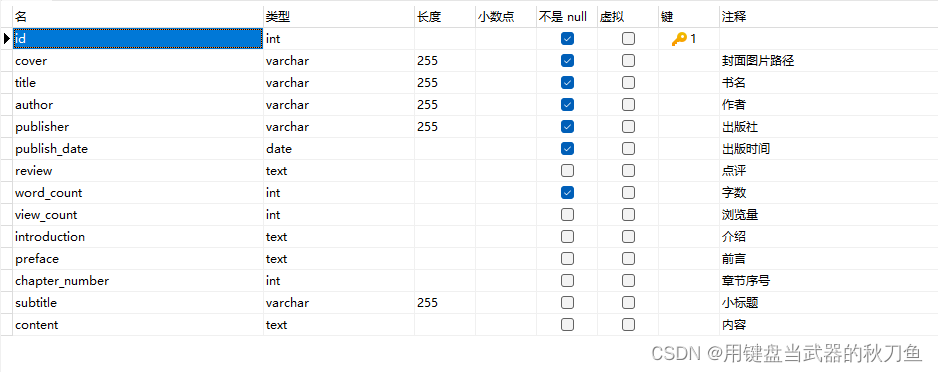
第一层1nf代码如下,
CREATE TABLE ak47 (
id INT AUTO_INCREMENT PRIMARY KEY,
cover VARCHAR(255) NOT NULL COMMENT '封面图片路径',
title VARCHAR(255) NOT NULL COMMENT '书名',
author VARCHAR(255) NOT NULL COMMENT '作者',
publisher VARCHAR(255) NOT NULL COMMENT '出版社',
publish_date DATE NOT NULL COMMENT '出版时间',
review TEXT COMMENT '点评',
word_count INT NOT NULL COMMENT '字数',
view_count INT DEFAULT 0 COMMENT '浏览量',
introduction TEXT COMMENT '介绍',
preface TEXT COMMENT '前言',
chapter_number INT COMMENT '章节序号',
subtitle VARCHAR(255) COMMENT '小标题',
content TEXT COMMENT '内容'
);
第三步:将其化为2nf
在满足第一范式的基础上,非主键列必须完全依赖于整个主键,而不是主键的一部分。
分析一下这句话,核心是必须完全依赖于整个主键
拆出来:必须完全,整个主键
整个主键:一整个表只能有一个主键,那么前面这句一整个表好理解,主键是什么呢?
主键:具有代表整个表的关键词(编号,身份证,表单的身份证)
一山不容二虎,除非他是子表
根据这个内容,我们的1nf范式,去进行一个拆解
我们可以分为三大类:第一类:书籍基本信息
第二类:书籍章节
第三类:书籍评价
这一个表就被拆成如下:
第一类:(主键)书籍编号,封面,书名,作者,出版社,出版时间
第二类:书籍编号(父表),书籍章节(主键),章节标题,章节内容,浏览量,字数
第三类:书籍编号(父表),评论ID(主键),评论内容,评论时间
为什么这么拆:封面,书名,作者,出版社,出版时间这些只能通过书籍编号获取,非主键列必须完全依赖于整个主键,
完全依赖,就是指,书名只能通过一个东西去获得,不能通过其他的去得到
第一个原则:重复性,当一个元素能重复时,他就不具有做主键的代表性
所以在选择主键的时候,考虑他可能重复吗?这里我们又可以进行拆一次
第一类:(主键)书籍编号,封面,书名,出版社,出版时间
第二类:作者(主键),作者名字,作者账号,作者简介,作品(父表)
第三类:书籍编号(父表),书籍章节(主键),章节标题,章节内容,浏览量,字数
第四类:书籍编号(父表),评论ID(主键),评论内容,评论时间
这时,作品又可以分类讨论了:一个本书没问题,两本书难不成像文章一样吗,
用《第一本》,《第二本吗》,放在同一个列中吗,很显然不可能
这样看着是不是怪怪的
再分就成五类了
第一类作者信息:作者账号(主键),作者名字,作者简介
第二类书籍信息:(主键)书籍编号,封面,书名,出版社,出版时间
第三类章节信息:书籍编号(父表),书籍章节(主键),章节标题,章节内容,浏览量,字数
第四类评论信息:书籍编号(父表),评论ID(主键),评论内容,评论时间
第五类作者作品:作者编号(父表),书籍编号(父表)
为什么第五类这么拆,我们可以根据查询语句,直接查出父表的内容,说人话就是
父表的内容可以直接被查出来,这样设计就有一点MVC模式了
类拆好了,那么该实现代码了
CREATE TABLE authors (
-- 作者账号,作为主键,具有唯一性
author_account VARCHAR(255) PRIMARY KEY UNIQUE,
-- 作者名字
author_name VARCHAR(255) NOT NULL,
-- 作者简介
author_bio TEXT
);第二类
CREATE TABLE books (
-- 书籍编号,作为主键,具有唯一性
book_id INT PRIMARY KEY UNIQUE,
-- 封面
cover VARCHAR(255),
-- 书名
title VARCHAR(255) NOT NULL,
-- 出版社
publisher VARCHAR(255),
-- 出版时间
publication_date DATE
);第三大类
CREATE TABLE chapters (
-- 书籍编号,作为父表引用书籍信息表
book_id INT,
-- 书籍章节编号,与书籍编号组合作为复合主键,具有唯一性
chapter_number INT,
-- 章节标题
chapter_title VARCHAR(255) NOT NULL,
-- 章节内容
chapter_content TEXT,
-- 浏览量
view_count INT DEFAULT 0,
-- 字数
word_count INT,
-- 设置复合主键
PRIMARY KEY (book_id, chapter_number),
-- 设置父表约束
FOREIGN KEY (book_id) REFERENCES books(book_id)
);第四类:
CREATE TABLE comments (
-- 评论ID,作为主键,具有唯一性
comment_id INT PRIMARY KEY UNIQUE,
-- 书籍编号,作为父表引用书籍信息表
book_id INT,
-- 评论内容
comment_content TEXT NOT NULL,
-- 评论时间,默认为当前时间戳
comment_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-- 设置父表约束
FOREIGN KEY (book_id) REFERENCES books(book_id)
);第五类
CREATE TABLE author_works (
-- 作者账号,作为父表引用作者信息表,具有唯一性(与书籍编号组合)
author_account VARCHAR(255),
-- 书籍编号,作为父表引用书籍信息表,具有唯一性(与作者账号组合)
book_id INT,
-- 设置复合主键,确保作者与书籍的关联唯一
PRIMARY KEY (author_account, book_id),
-- 设置父表约束
FOREIGN KEY (author_account) REFERENCES authors(author_account),
FOREIGN KEY (book_id) REFERENCES books(book_id)
);总结2nf的一个原则,不可重复性,当出现了重复性,那么我们就要将其分出来
进入第四步,将其化为3nf
第三范式(3NF):在满足第二范式的基础上,非主键列之间不存在传递依赖关系,即一个非主键列不能依赖于另一个非主键列。
说人话就是,除了主键和父键以外的列,他们是独立存在的,互不影响,就和国家与国家一样,
第一类作者信息:作者账号(主键),作者名字,作者简介
第二类书籍信息:(主键)书籍编号,封面,书名,出版社,出版时间
第三类章节信息:书籍编号(父表),书籍章节(主键),章节标题,章节内容,浏览量,字数
第四类评论信息:书籍编号(父表),评论ID(主键),评论内容,评论时间
第五类作者作品:作者编号(父表),书籍编号(父表)
来来看看父表和主键之外的内容有没有联系
能通过作者名字去确定一个作者的简介吗?很显然不能,因为名字可重复,但是账号不可重复
除非你把账号和作者的名字改一下
A和B之间没有直接的关系,独立,互不影响,但是硬要深挖他们就是属于书的一部分
总结一下:三段范式,是属于叠加态,简称父子关系,而他们的父亲
具体关系如下,1nf是父,2nf是儿,3nf就是孙子
每一代都继承了父代的优势
1nf是原子性,即本质性
2nf是具有原子性,诞生了不可重复性
3nf是具有原子性,不可重复性,独立互不影响性
第一步:拆解,拆解成1
例子:12,就拆成12个1
第二步:确定唯一主键和父键,如果有需求可以再来一个义父键
例子:A,B,C
A是父键,B是主键,C是列
他们直接的联系就是,A是连接B的,B是用来连接C的
第三步:看除主键父键以外的内容,是否是独立互不影响性
0.1版本,2024/3/16数据库3nf范式模板