目录
1. 基本题
1.1 基本题1
1.2 基本题2
1.3 基本题3
2. turtle画图
3. 大题
3.1 大题1
3.2 大题2
1. 基本题
1.1 基本题1
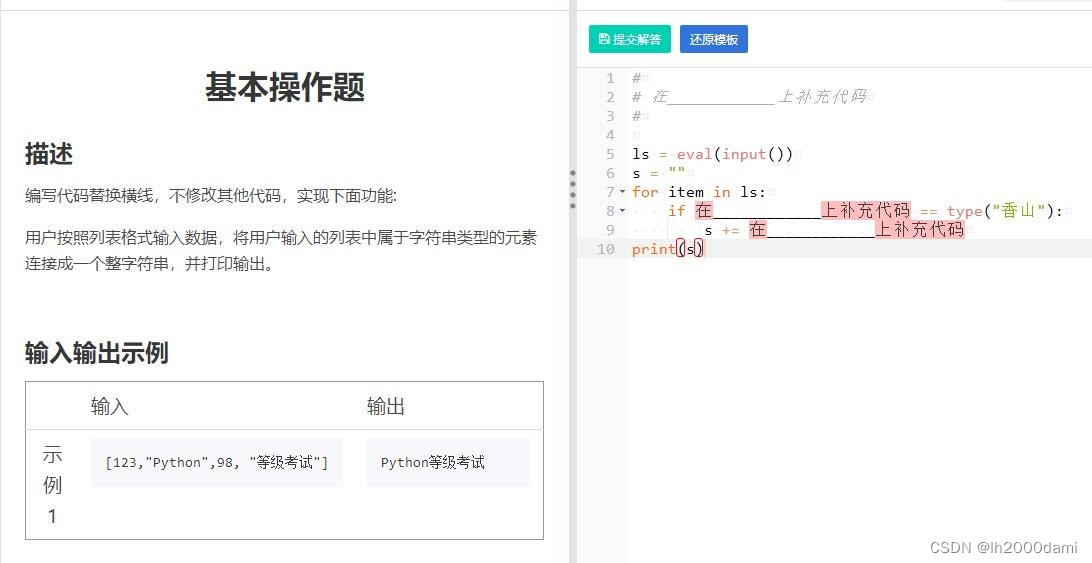
ls=eval(input())
s=""
for item in ls:
if type(item)==type("香山"):
s+= item
print(s)1.2 基本题2

import random
random.seed(25)
n=random.randint(1,100)
for m in range(1,7):
x=eval(input("请输入猜测数字:"))
if x==n:
print("恭喜你,猜对了!")
break
elif x>n:
print("大了,再试试")
else:
print("小了,再试试")
if m==6:
print("谢谢!请休息后再猜")1.3 基本题3
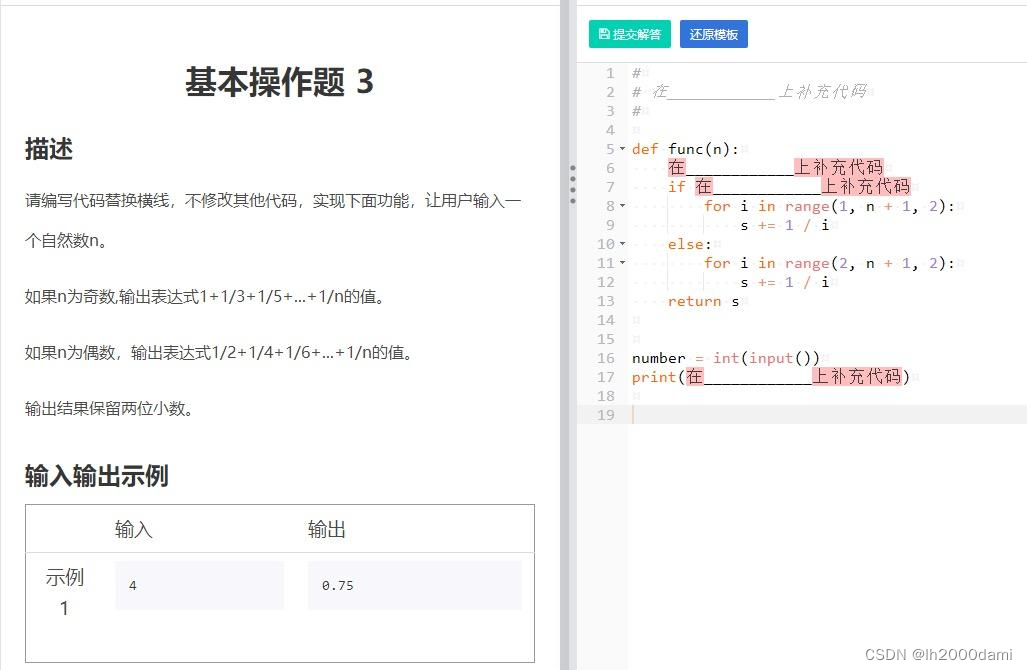
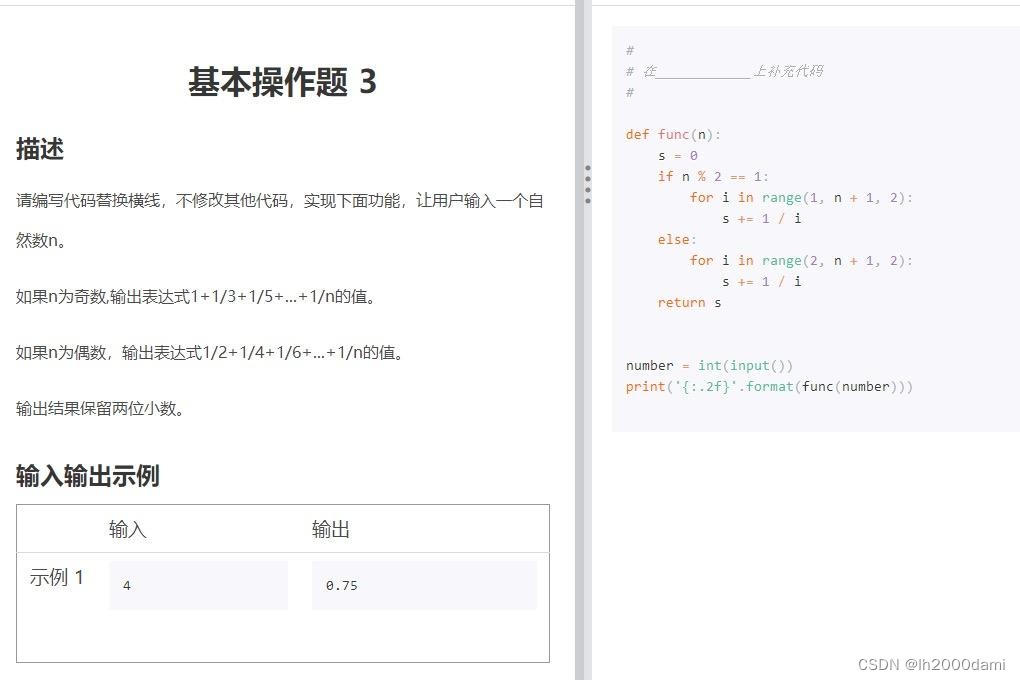
def func(n):
s=0
if n%2==1:
for i in range(1,n+1,2):
s+=1/i
else:
for i in range(2,n+1,2):
s+=1/i
return s
number=int(input())
print("{:.2f}".format(func(number)))注意:s=0; 和{:.2f}不要少了冒号
2. turtle画图
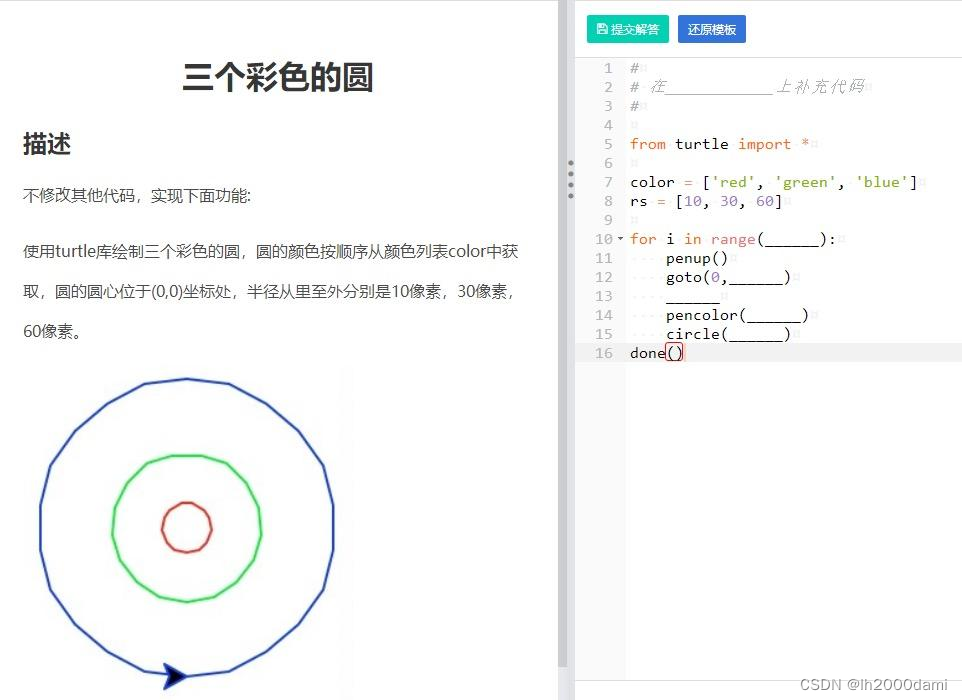
from turtle import *
color=['red','green','blue']
rs=[10,30,60]
for i in range(3):
penup()
goto(0,-rs[i])
pendown()
pencolor(color[i])
circle(rs[i])
done()turtle.circle()中的参数是圆的半径,逆时针画圆
3. 大题
3.1 大题1

import jieba
s=input("请输入一段中文文本,句子之间以逗号或句号分隔:")
slist=jieba.lcut(s)
m=0
for i in slist:
if i in",。":
continue
else:
m+=1
print(i,end="/")
print("\n中文词语数是:{}\n".format(m))
poetry=''
for i in s:
if i in ',。':
print('{:^20}'.format(poetry))
poetry=''
continue
poetry+=i
注意第二问的编程思路,以及continue的用法
3.2 大题2
第一问:
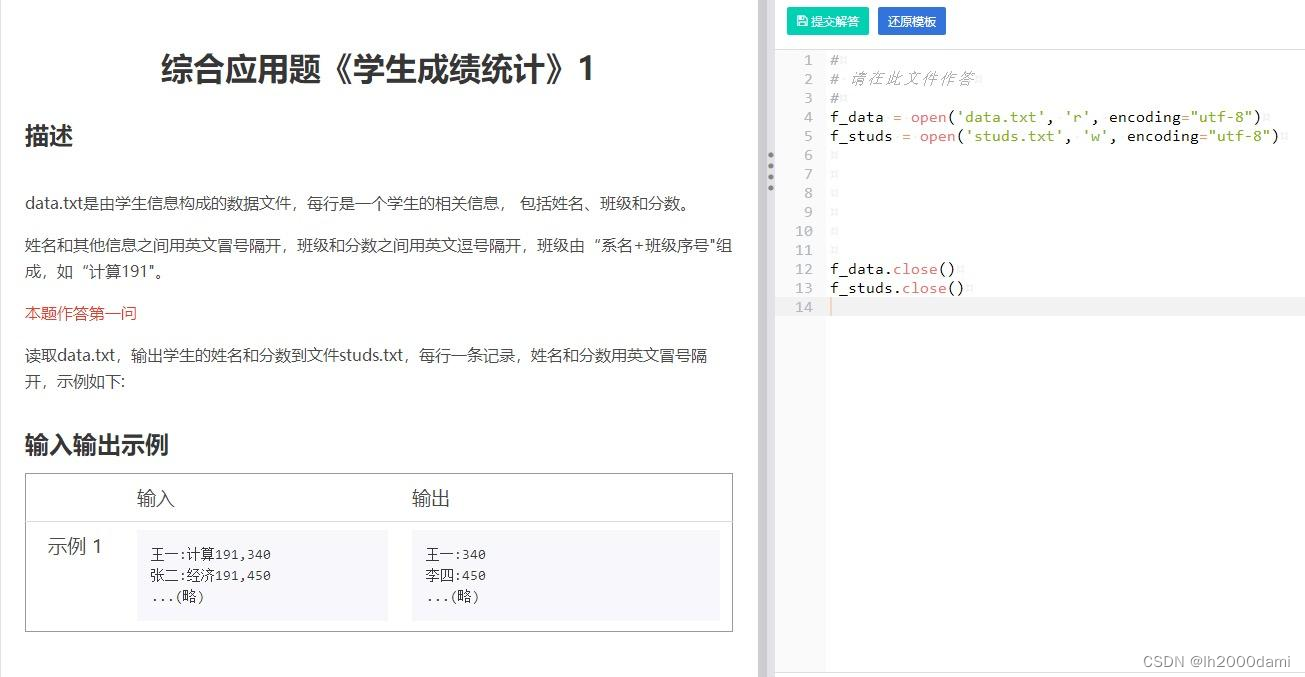
f_data=open('data.txt','r',encoding="utf-8")
f_studs=open('studs.txt','w',encoding="utf-8")
ls=f_data.readlines()
for item in ls:
a=item.strip().split(':')[0]+':'+item.split(',')[-1]
f_studs.write(a)
f_data.close()
f_studs.close()
f_studs.write()每行写完自带换行符
第二问:
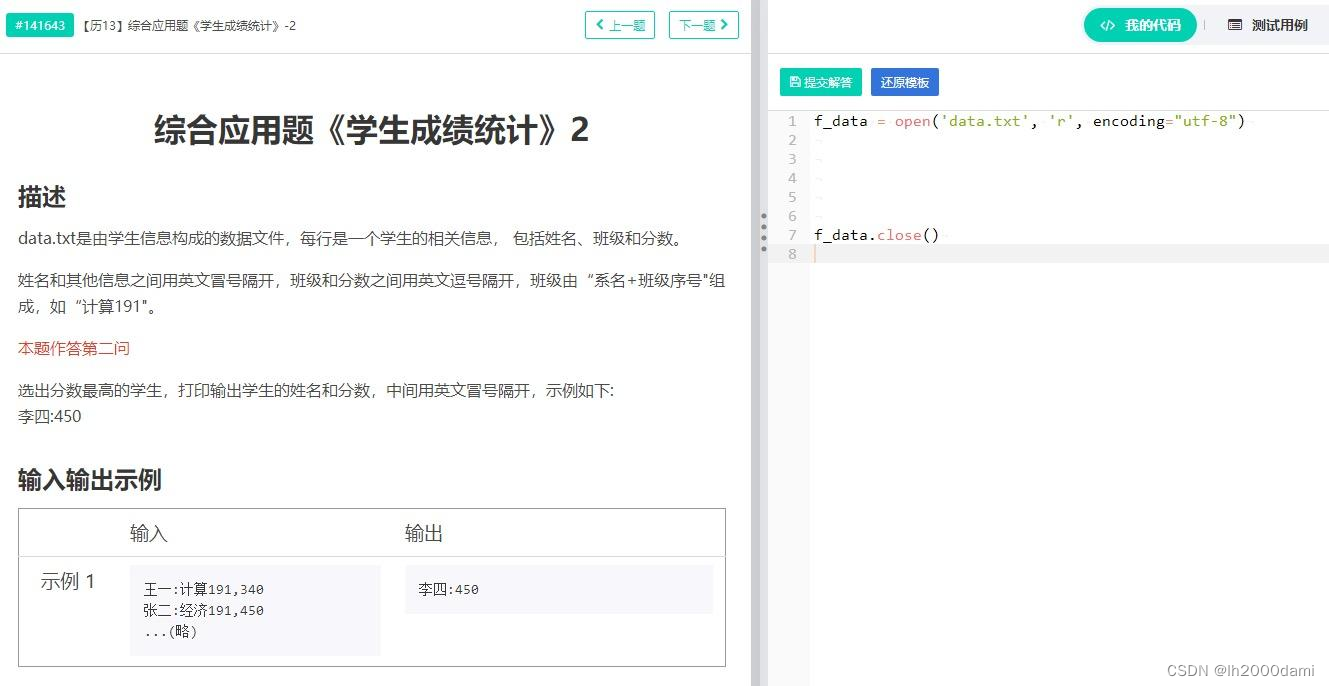
f_data=open('data.txt','r',encoding="utf-8")
ls=f_data.readlines()
lst=[]
for item in ls:
name=item.split(':')[0]
score=item.split(',')[-1]
lst.append([name,score])
lst.sort(key=lambda x:eval(x[1]),reverse=True)
print(lst[0][0]+':'+lst[0][1])
f_data.close()利用lst.append()向列表中增加元素;注意排序的程序写法
第三问:
自己写的:
f_data=open('data.txt','r',encoding="utf-8")
ls=f_data.readlines()
d={}
p={}
for item in ls:
classname=item.split(':')[-1].split(',')[0]
score=item.split(',')[-1]
d[classname]=d.get(classname,0)+int(score)#班级总分
p[classname]=p.get(classname,0)+1#班级人数
for i in d:
print("{}:{:.2f}".format(i,d[i]/p[i]))
f_data.close()
参考答案:
f_data=open('data.txt','r',encoding="utf-8")
students=f_data.readlines()
d={}
for student in students:
student=student.strip().split(':')
Class,score=student[1].split(',')
d[Class]=d.get(Class,[])+[eval(score)]#班级总分
for key in d:
avg_score=sum(d[key])/len(d[key]) #每个key对应一个分数列表
print("{}:{:.2f}".format(key,avg_score))
f_data.close()
key对应的是一个列表