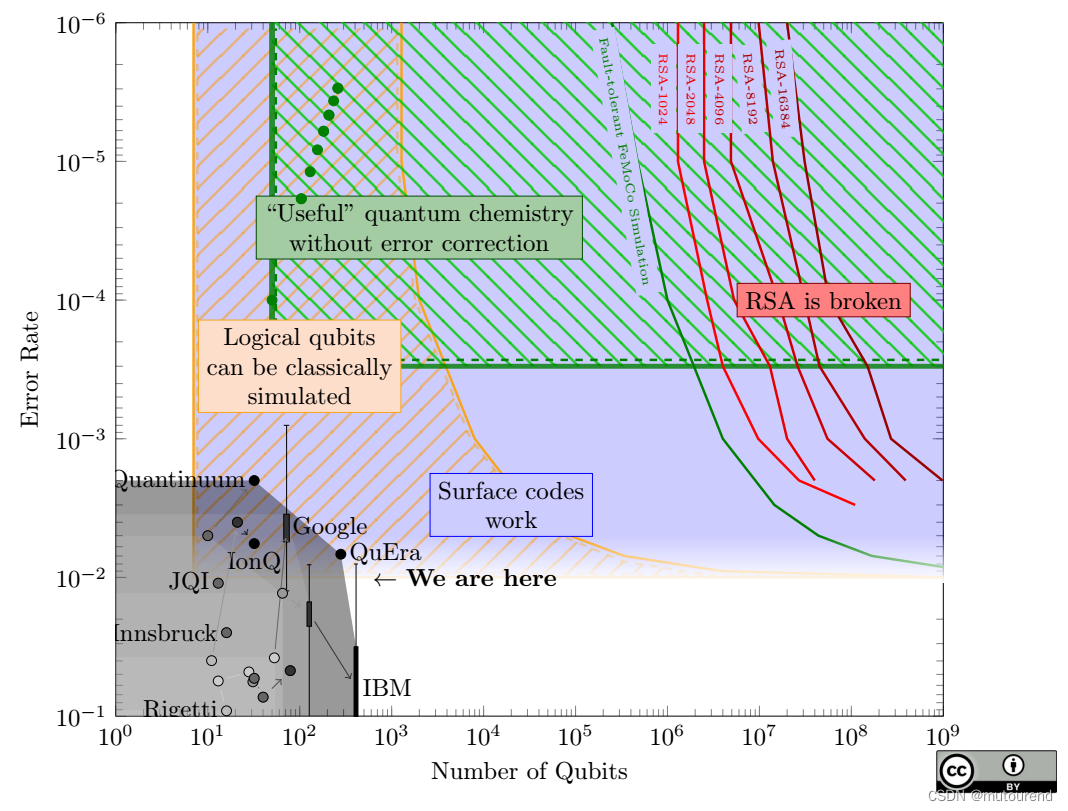
1.什么是线性判别分析法(FDA)?
线性判别分析是一种对于监督数据降维的经典方法。通过对数据标准化,求得类内散度矩阵和类间散度矩阵,寻找一个投影矩阵W,使得同类样例的投影点尽可能接近,异类样例的投影点尽可能远离,然后根据新的投影点来判别分类。所以可以利用LDA来减少样本点的维数。
2.什么是多分类学习?
多分类学习基本思路是将若干个多分类任务拆解成多个二分类任务,对每一个二分类任务训练一个分类器进行求解,这些分类器(classifier)的预测结果合成以获得最终多分类结果。最经典的拆分方法有OvO(一对一),OvR(一对其余),MvM(多对多)。
3.什么是类别不平衡问题?(class imbalance)
类别不平衡问题是指多分类任务中不同类别样例数目差很大的情况。解决这个问题可以使用“再缩放”(rescaling),公式如下,其中y表达了实际上正例的可能性,m+表示正例数目,m-表示反例数目。
式1
如何解决训练集不是真实样本总体的无偏采样问题?(1)欠采样(undersampling):去除一些反例使得正反例数目接近(2)过采样(oversampling):通过插值增加一些正例使得正反例数目接近(3)阈值移动(threshold-moving) :用原始的训练集得到的分类器进行学习,使用“式1”进行决策。




![[题解]无厘头题目——无聊的军官](https://img-blog.csdnimg.cn/direct/80c3d32b306e410eb90cb54002223291.png)