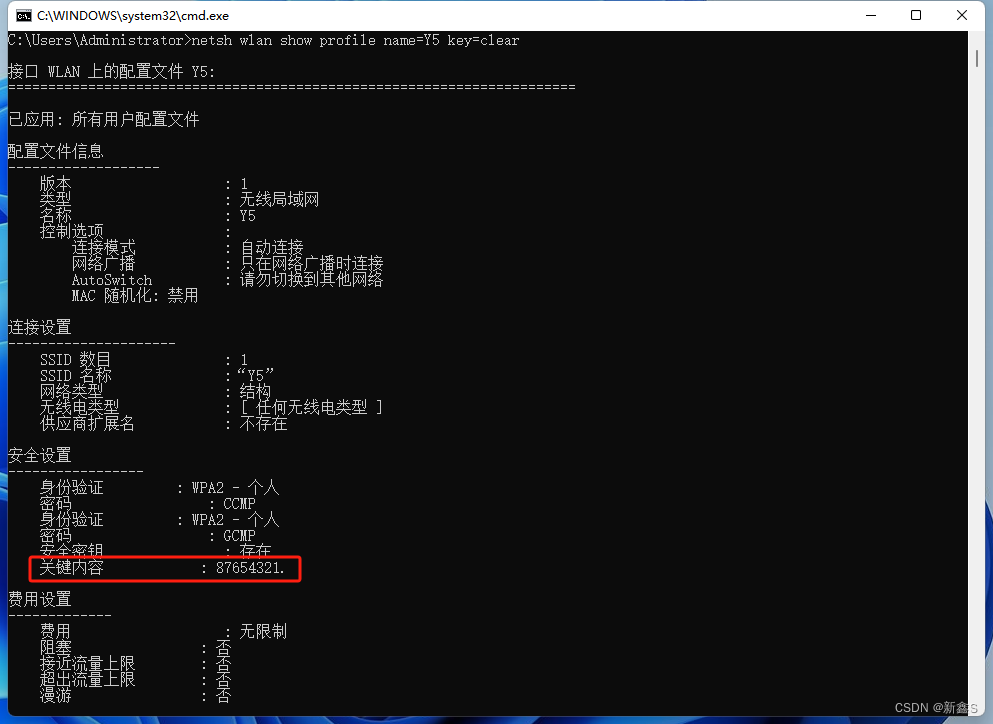
k8s的pod和svc相互访问时网络链路解析
- 1. k8s环境中pod相互访问
- 1.1. k8s中pod相互访问的整体流程
- 1.2. k8s的相同机器的不同pod相互访问
- 1.3. k8s的不同机器的不同pod相互访问
- 2. k8s访问svc
- 2.1 nat操作
- 2.2 流量进入到后端pod
- 3. 疑问和思考
- 3.1 访问pod相互访问为什么不用做nat?
- 3.2 访问svc时为什么需要做nat?
- 4. 参考文档
在常用的k8s环境中,通常会面临同机器pod的相互访问、跨机器之间的pod访问以及通过svc访问相互,这几种模式下,k8s底层网络的访问规则不同。本文希望针对这几种场景下的流量访问链路和访问规则,从而探索k8s针对网络层面的设计逻辑。k8s层面svc访问的详细规则可以参考k8s的svc流量通过iptables和ipvs转发到pod的流程解析
1. k8s环境中pod相互访问
1.1. k8s中pod相互访问的整体流程
k8s内部pod相互之间的访问架构如下,我们使用一个相互新的网络架构,进行整体网络解析。

这个架构使用的cilium进行作为网络插件提供网络服务。在基于 vxlan 的 overlay 组网情况下,主机上的网络发生了以下变化:在主机的 root 命名空间,新增了如下图所示的四个虚拟网络接口
- cilium_vxlan 主要是对数据包进行 vxlan 封装和解封装操作;
- cilium_net 和 cilium_host 是一对 veth-pair,cilium_host 作为该节点所管理的 Cluster IP 子网的网关
- lxc_health,用于节点之间的健康检测。
在每个主机上,可以进入 Cilium Agent,能够记录pod-host之间的网络关系,能够通过pod找到对应的机器host,并为对应的机器创建隧道列表。 比如进入主机 easyk8s1 上的 Cilium Agent,运行 cilium bpf tunnel list,可以看到
- 其为集群中的另一台主机 easyk8s2 上的虚拟网络 10.244.1.0 创建了一个隧道
- 同样在 easyk8s1 上也有一条这样的隧道配置。

每台服务器也将为每台node、pod、svc创建相关的路由表,当相关流量到达cilium_host后,会通过进一步访问的目的地址查找和匹配的路由表,从而决定下一跳的访问流量。
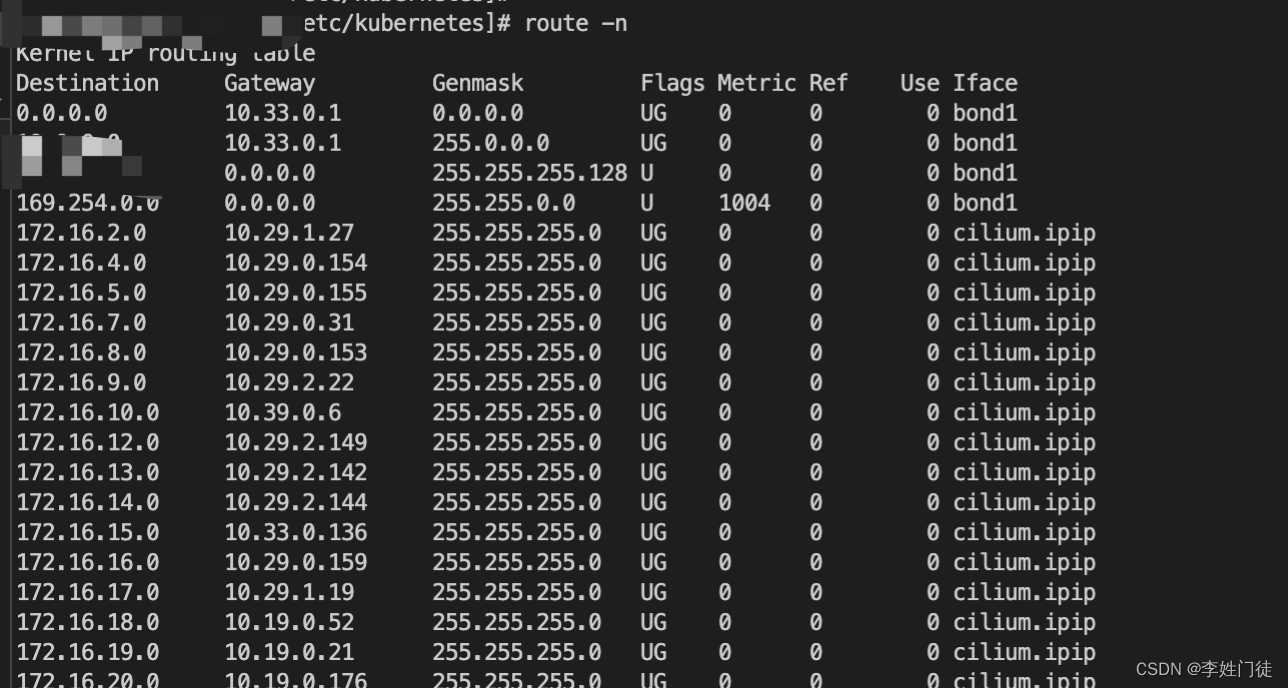
k8s之间的pod访问就是通过veth-pair、路由表从而决定整体的转发策略。
1.2. k8s的相同机器的不同pod相互访问
以 busybox1 ping busybox2 为例
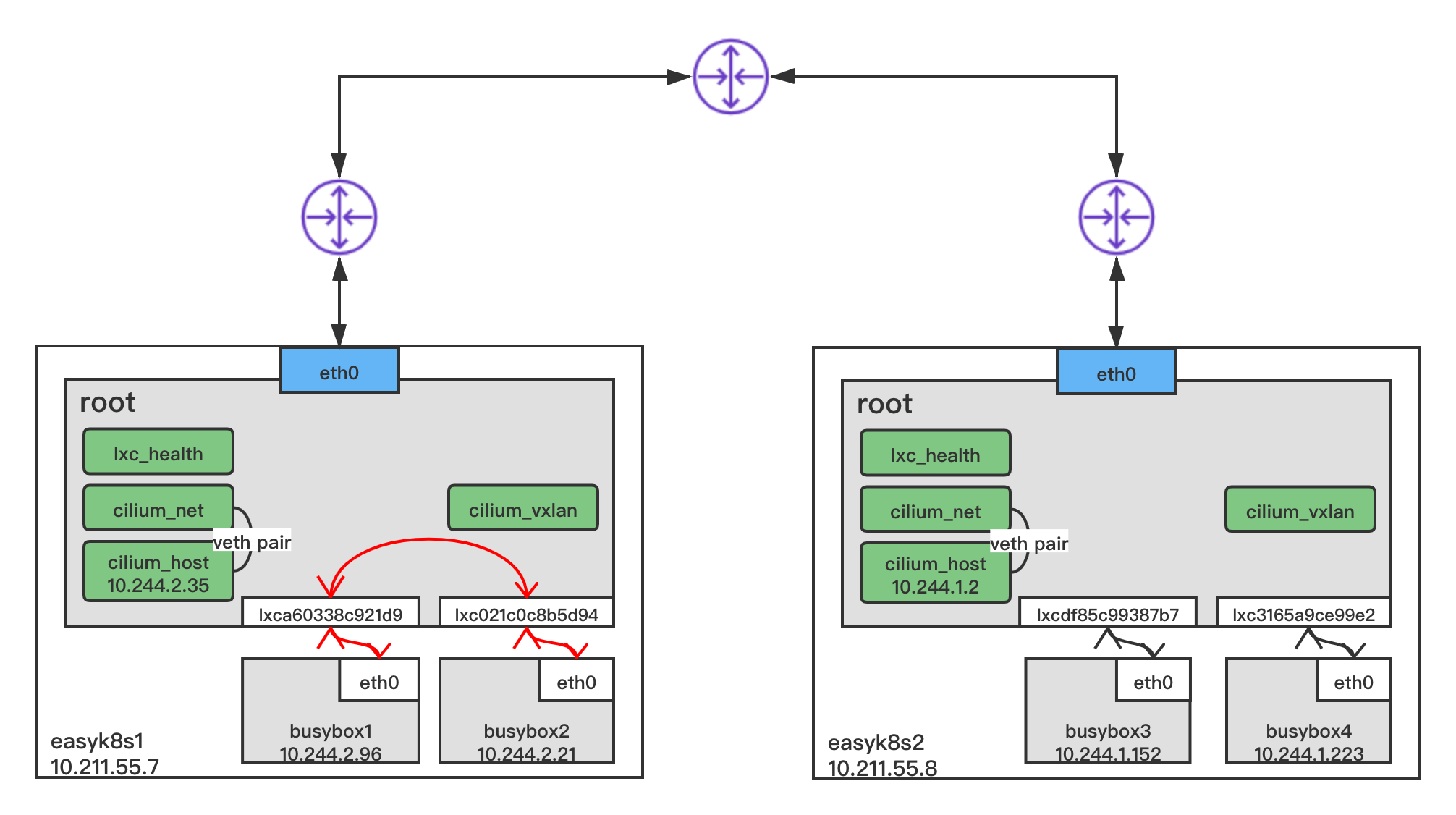
busybox1 的 IP 地址为 10.244.2.96/32,busybox2 的 IP 地址为 10.244.2.21/32,掩码均为 32 位。
-
当 busybox1 准备发送 ping 包时,数据包逐层封装,网络层 (3 层) 源 IP 为 10.244.2.96/32,目的 IP 为 10.244.2.21/32,其通过路由表(注:每个 Node 上所有的容器路由表一样)查询到下一跳为 10.244.2.35
-
数据链路层 (2 层) 源 MAC 地址为 0a:c5:89:f9:04:84,目的 MAC 地址因初始状态下 Pod 内的 ARP 表为空,busybox1 需发送 ARP 请求目的 MAC 地址
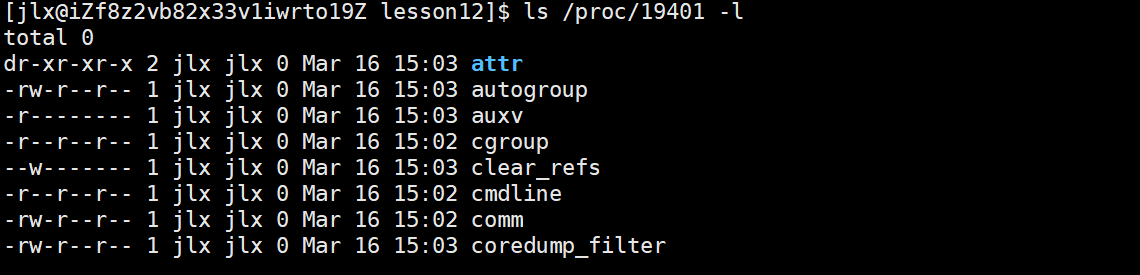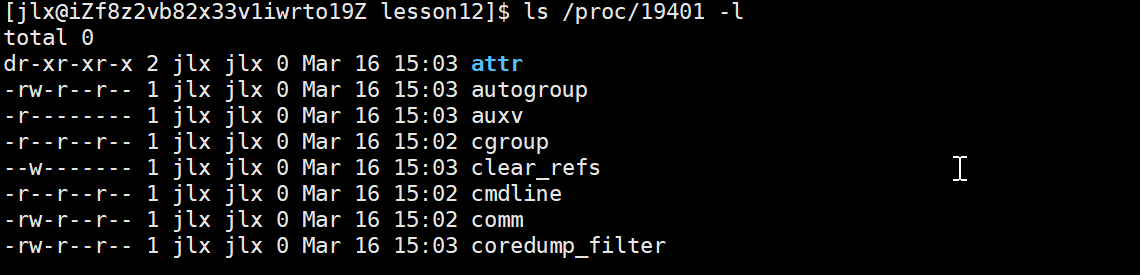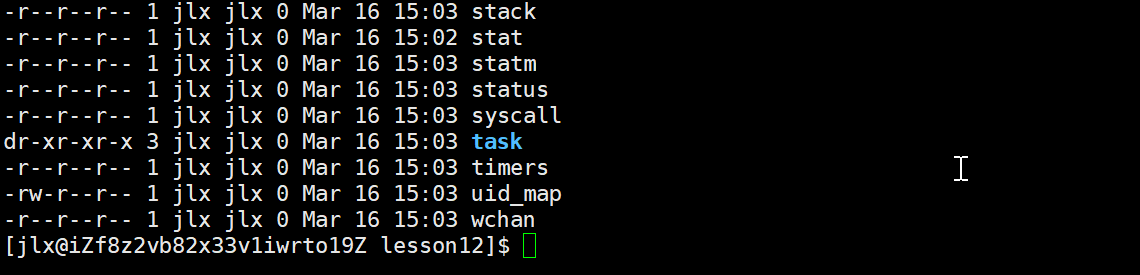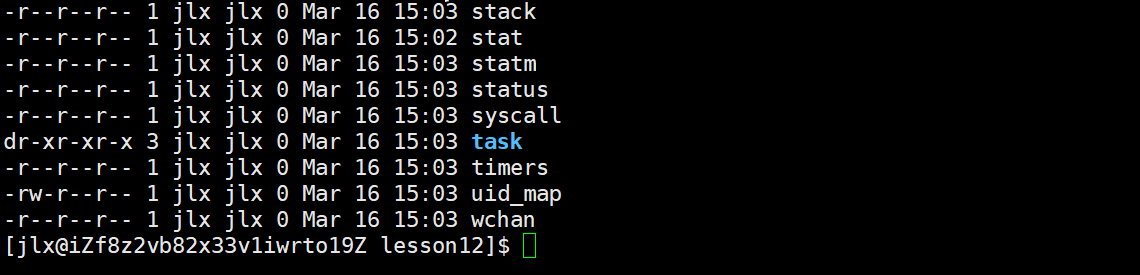
[root@easyk8s1 ~]# kubectl exec -ti busybox1 -- route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 10.244.2.35 0.0.0.0 UG 0 0 0 eth0 10.244.2.35 0.0.0.0 255.255.255.255 UH 0 0 0 eth0 [root@easyk8s1 ~]# kubectl exec -ti busybox1 -- arp如上busybox1中的路由表,busybox1出去的流量目标地址是10.244.2.35 ,会通过eth0端口出来流量。busybox1的 eth0 网卡是一对 veth-pair 设备,另一端 ifindex 为 16 的 lxca60338c921d9 在 Node 节点 easyk8s1 上,从而busybox1的流量就会转发到easyk8s1上。lxca60338c921d9 绑定在cilium_host(类似网桥),可以根据路由表进一步决定流量的去向。
-
lxca60338c921d9 网卡收到 ARP 请求包,内核处理 ARP 请求,发现地址就在本机,但是地址所属网卡 cilium_host 为 NOARP 状态,根据 Cilium Agent 挂载的 eBPF 程序实现,将使用接收 ARP 请求包的 lxca60338c921d9 网卡的 MAC 地址进行响应。(分别在网卡 cilium_host 和 lxca60338c921d9 抓取 MAC 报文,后者收到报文。报文中 MAC 回包的 mac 地址是 lxca60338c921d9 的 MAC 地址 e2:d8:51:8b:44:d4)
[root@easyk8s1 ~]# ip addr show ... 6: cilium_net@cilium_host: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether d6:99:91:04:02:a5 brd ff:ff:ff:ff:ff:ff inet6 fe80::d499:91ff:fe04:2a5/64 scope link valid_lft forever preferred_lft forever 7: cilium_host@cilium_net: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 6e:5e:1e:d7:c2:07 brd ff:ff:ff:ff:ff:ff inet 10.244.2.35/32 scope link cilium_host valid_lft forever preferred_lft forever inet6 fe80::6c5e:1eff:fed7:c207/64 scope link valid_lft forever preferred_lft forever [root@easyk8s1 ~]# tcpdump -nnn -vvv -i lxca60338c921d9 arp tcpdump: listening on lxca60338c921d9, link-type EN10MB (Ethernet), capture size 262144 bytes 15:29:03.640538 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 10.244.2.35 tell 10.244.2.96, length 28 15:29:03.640654 ARP, Ethernet (len 6), IPv4 (len 4), Reply 10.244.2.35 is-at e2:d8:51:8b:44:d4, length 28 -
busybox1 收到 ARP 应答后,获取到目的 MAC 地址并缓存,然后组装 ICMP REQUEST 包并发送
[root@easyk8s1 ~]# kubectl exec -ti busybox1 -- ip neigh 10.244.2.35 dev eth0 lladdr e2:d8:51:8b:44:d4 used 0/0/0 probes 1 STALE -
lxca60338c921d9 网卡收到 ICMP REQUEST 报文,解封装,发现二层目的 MAC 地址是自身,继续解分装,发现三层目的 IP 地址是 10.244.2.21/32,查询路由表(所有主机的路由表 podsubnet 网段内的路由都指向 cilium_host),路由表指向cilium_host(cilium_host 是 eBPF 埋钩子的地方,eBPF 进行 ingress 方向的转发逻辑,包括 prefilter、解密、L3/L4 负载均衡、L7 Policy 等)
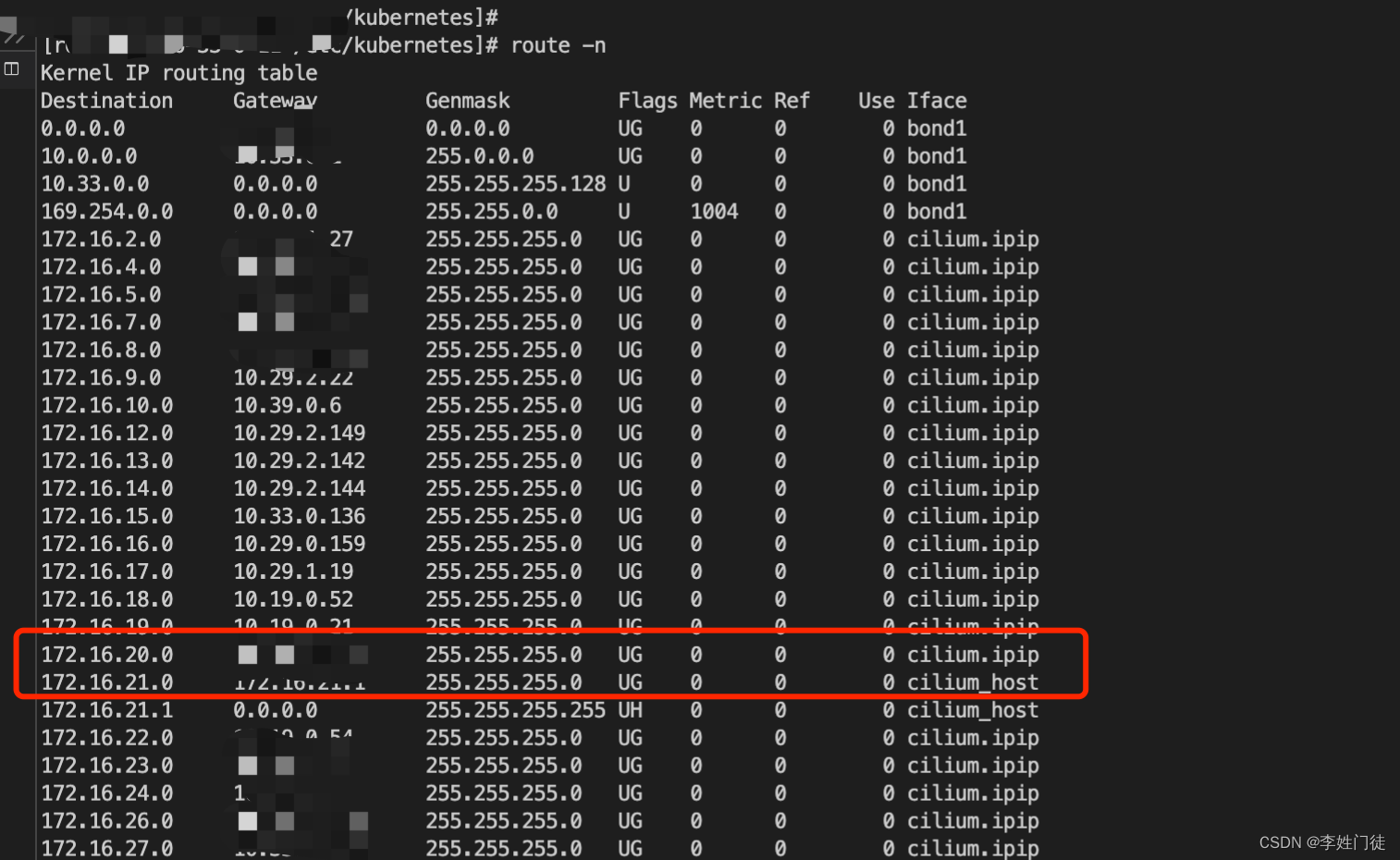
-
cilium_host进一步通过的Cilium Agent
cilium bpf endpoint list的相关转发规则,重新对数据包进行封装,发送给 busybox2 容器的 veth-pair 接口 lxc021c0c8b5d94[root@easyk8s1 ~]# kubectl exec -ti cilium-wtdbp -n kube-system -- cilium bpf endpoint list IP ADDRESS LOCAL ENDPOINT INFO 10.244.2.21:0 id=6 flags=0x0000 ifindex=18 mac=2E:5A:9A:9E:01:00 nodemac=36:33:68:68:1F:DD 10.244.2.96:0 id=890 flags=0x0000 ifindex=16 mac=0A:C5:89:F9:04:84 nodemac=E2:D8:51:8B:44:D4 10.211.55.10:0 (localhost) 10.211.55.7:0 (localhost) 10.244.2.35:0 (localhost) 10.244.2.172:0 id=109 flags=0x0000 ifindex=10 mac=22:4F:87:F3:0C:94 nodemac=C6:F5:CD:16:6D:E2 -
busybox2 收到 ICMP REQUEST 包并处理,回应 ICMP REPLY 包,回包过程与上面过程相反,此处不再赘述
1.3. k8s的不同机器的不同pod相互访问

整体流程跟相同节点的不同pod之间访问类似,前面5个步骤相同。从第6步 开始,有差异
-
cilium_host根据隧道转发规则去往 10.244.1.0/24 网段的流量将发送给 10.211.55.8,也就是 easyk8s2 节点。于是将 ICMP REQUEST 包重新封装发送给 easyk8s1 的 cilium_vxlan 网卡。cilium_vxlan 网卡会进行 VXLAN 封装(Cilium 默认使用 UDP 8472 端口),通过 underlay 层路由,由物理网卡 eth0 发送给 10.211.55.8,即 easyk8s2 节点
[root@easyk8s1 ~]# kubectl exec -ti cilium-wtdbp -n kube-system -- cilium bpf tunnel list TUNNEL VALUE 10.244.1.0:0 10.211.55.8:0 -
asyk8s2 节点的 eth0 网卡收到报文以后,发现是 VXLAN 报文,便发给 cilium_vxlan 进行解封装,并根据内部目的地址路由。
-
路由表同样指向 easyk8s2 节点的 cilium_host 网卡,eBPF 进行 ingress 方向的转发逻辑(包括 prefilter、解密、L3/L4 负载均衡、L7 Policy 等)。进入 easyk8s2 节点的 Cilium Agent 通过 cilium bpf endpoint list 可以查询其转发规则。根据规则将数据包发送给 busybox3 容器的 veth-pair 接口 lxcdf85c99387b7
[root@easyk8s1 ~]# kubectl exec -ti cilium-l2wpw -n kube-system -- cilium bpf endpoint list IP ADDRESS LOCAL ENDPOINT INFO 10.244.1.2:0 (localhost) 10.211.55.8:0 (localhost) 10.244.1.253:0 id=959 flags=0x0000 ifindex=10 mac=EA:1F:11:A8:CF:0D nodemac=DE:44:26:5F:50:CC 10.244.1.223:0 id=1419 flags=0x0000 ifindex=22 mac=C2:11:E1:7D:27:30 nodemac=92:C7:C1:10:8D:7C 10.244.1.152:0 id=3207 flags=0x0000 ifindex=20 mac=62:1B:E4:C9:4D:44 nodemac=EA:60:B5:7D:42:32 -
busybox3 收到 ICMP REQUEST 包并处理,回应 ICMP REPLY 包,回包过程与上面过程相反,此处不再赘述
从如上流程可以看出,pod之间的相互访问主要依赖 eth-pair、cilium_host(对应其他网络插件的网桥)、以及路由表,进行路由转发。并不需要针对pod进行nat操作,因此也不涉及iptables等相关规则。
2. k8s访问svc
2.1 nat操作
客户端访问(k8s的pod或者node)访问svc时,虽然实际上是访问svc后端的pod(实际的服务提供方),但是由于svc的存在,使得能够完全屏蔽svc后端的相关配置。对于客户端而言,并不感知svc后端的相关服务情况。
如果客户端正好是k8s的pod或者node时,当流量从node的网卡出包时,会被iptables进行nat操作,将客户端ip进行snat成node的ip。而当流量从svc返回客户端时,会进行逆向转换将node进行dnat解析成客户端ip。
该nat操作时通过iptables KUBE-MARK-MASQ规则实现的,具体的实现方式可以参考 k8s的svc流量通过iptables和ipvs转发到pod的流程解析
每台k8s服务器都会配置KUBE-MARK-MASQ相关规则,因此当pod流量出服务器网卡时,就会自动完成转换。

2.2 流量进入到后端pod
svc能够通过负载均衡配置,将相关的流量分权重,转换到后端pod,具体可以参考 k8s的svc流量通过iptables和ipvs转发到pod的流程解析
当访问流量完成nat,进入到目标pod后,相关的流程跟pod访问流程类似,不在继续复述
3. 疑问和思考
3.1 访问pod相互访问为什么不用做nat?
不需要进行nat。
因为pod到pod时相同的网段,每个pod都被分配ip,并且在k8s环境中,每个node有对应的pod cidrs,因此针对每个pod而言,能够清晰的构建每个podip对应的转发路由表,因此不需要进行nat。网访问客户端的pod出流量进入到网桥(cilium_host)后,能够通过本地的路由表查找到目标pod所在的下一条地址。只需要做简单封装后,就能够进行流量之间的相互访问。
3.2 访问svc时为什么需要做nat?
在 Kubernetes 中,Service 是一种抽象层,用于将一组 Pod 暴露给其他 Pod 或外部网络。当一个外部客户端尝试访问 Service 时,请求首先到达集群的节点。这时候,由于 Service 的 IP 地址是虚拟的,它不属于任何节点的 IP 地址范围,因此node节点无法直接识别该请求应该转发给哪个具体的 Pod。
为了解决这个问题,Kubernetes 使用了网络地址转换(Network Address Translation,NAT)技术。当一个请求到达节点时,节点会使用 NAT 将请求的目标 IP 地址转换为 Service 对应 Pod 的 IP 地址,然后将请求转发给该 Pod。
通过使用 NAT,Kubernetes 可以将 Service 的虚拟 IP 地址与实际运行的 Pod 关联起来,从而实现请求的转发和负载均衡。同时,这也使得 Service 的 IP 地址可以根据需要动态变化,而不会影响到外部客户端的访问。
4. 参考文档
暂无