背景
滴滴集团作为生活服务领域的头部企业,其中橙心优选经过一年多的数据体系建设,逐渐将一部分需要实时交互查询,即席查询的多维数据分析需求由ClickHouse迁移到了StarRocks中,接下来以StarRocks实现的漏斗分析为例介绍StarRocks在橙心优选运营数据分析应用中的实践。
一、需求介绍
当前数据门户上的漏斗分析看板分散,每个看板通常只能支持一个场景的漏斗分析,不利于用户统一看数或横向对比等,看板无法支持自选漏斗步骤,下钻拆解等灵活分析的功能。因此,需要一款能覆盖更全的流量数据,支持灵活筛选维度,灵活选择漏斗,提供多种分析视角的漏斗分析工具,并定位流失人群、转化人群、从而缩小问题范围,精准找到运营策略、产品设计优化点,实现精准化运营。
二、技术选型
电商场景的流量日志,行为日志一般会比传统场景下的数据量大很多,因此在这样的背景下做漏斗分析给我们带来了两大技术挑战:
- 日增数据量大:日增千万级数据,支持灵活选择维度,如何快速对亿级数据量进行多维分析
- 对数据分析时效性要求高:如何快速地基于亿级数据量,获取符合条件的用户数量
StarRocks在易用性和可维护性上都比ClickHouse更胜一筹,下面这张表格是在使用过程中对两者功能的一个简单对比:

经过不断的对比和压测,最终决定使用StarRocks来存储需要进行漏斗分析的数据,因为StarRocks在SQL监控,运维方面相比ClickHouse的优势明显,而且可以为了满足不同的查询场景,基于漏斗分析明细表创建各种各样的物化视图,提高多维数据分析的速度。
三、系统架构

系统各层职责说明如下:
- 数据源:主要是web端、客户端的埋点日志。这些埋点日志会源源不断地上传给我们的数据接入层。
- 数据接入层:
(1)数据接入总线:提供多种数据源的接入接口,接收并校验数据,对应用层屏蔽复杂的数据格式,对埋点日志进行校验和简单的清洗,转换后,将日志数据推送到Kafka集群。
(2)kafka集群:数据接入总线与数据计算集群的中间层。数据接入总线的对应接口仅数据接收并校验完成后,将数据统一推送到Kafka集群。Kafka集群解耦了数据接入总线和数据计算集群,利用Kafka自身的能力,实现流量控制,释放高峰时日志数据量过大对下游计算集群,存储系统造成的压力。
- 数据计算与存储层:
(1)数据计算集群:数据存入Kafka集群后,根据不同的业务需求,使用Flink或者Spark对数据进行实时和离线ETL,并批量保存到StarRocks数据仓库。
(2)StarRocks数据仓库:Spark+Flink通过流式数据处理方式将数据存入StarRocks,我们可以根据不同的业务场景在StarRocks里创建明细表,聚合表和更新表以及物化视图,满足业务方多样的数据使用要求。
- 数据服务层:内部统一指标定义模型,指标计算逻辑,为各个应用方提供统一的离线查询接口和实时查询接口。
- 漏斗分析系统:支持灵活创建和编辑漏斗,支持漏斗数据查看,漏斗明细数据导出
- 数据中台:围绕大数据的数据生产与使用场景,提供元数据管理,数据地图,作业调度等通用基础服务,提升数据生产与使用效率。
四、详细设计
目前,基于StarRocks的bitmap类型只能接受整型值作为输入,由于我们原始表的user_id存在字母数字混合的情况,无法直接转换成整型,因此为了支持bitmap计算,需要将当前的user_id转换成全局唯一 的数字ID。我们基于StarRocks+Hive的方式构建了原始用户ID与编码后的整型用户ID——映射的全局字典,全局字典本身就是一张Hive表,Hivev表有两列,一个是原始值,一个是编码的int值。以下是全局字典的构建流程。
step1:将原始表的字典列去重生成临时表:
临时表定义:
create table 'temp_table'{
'user_id' string COMMENT '原始表去重后的用户ID'
}字典列去重生成临时表:
insert overwrite table temp_table select user_id from fact_log_user_hive_table group by user_idstep2: 临时表和全局字典进行left join, 悬空的词典项为新value,对新value进行编码并插入全局字典:
全局字典表定义:
create table 'global_dict_by_userid_hive_table'{
'user_id' string COMMENT '原始用户ID',
'new_user_id' int COMMENT '对原始用户ID编码后的整型用户ID'
}将临时表和全局字典表进行关联,未匹配中的即为新增用户,需要分配新的全局ID,并追加到全局字典表中。全局ID的生成方式,是用历史表中当前的最大的用户ID加上新增用户的行号:
--4 更新Hive字典表
insert overwrite global_dict_by_userid_hive_table
select user_id, new_user_id from global_dict_by_userid_hive_table
--3 与历史的字段数据求并集
union all select t1.user_id,
--2 生成全局ID:用全局字典表中当前的最大用户ID加上新增用户的行号
(row_number() over(order by t1.user_id) + t2.max_id) as new_user_id
--1 获得新增的去重值集合
from
(
select user_id from temp_table
where user_id is not null
) t1
left join
(
select user_id, new_user_id, (max(new_user_id) over()) as max_id from
global_dict_by_userid_hive_table
) t2
on
t1.user_id = t2.user_id
where t2.newuser_id is nullstep3: 原始表和更新后的全局字典表进行left join , 将新增用户的ID和编码后的整型用户ID插入到原始表中:
insert overwrite fact_log_user_hive_table
select
a.user_id,
b.new_user_id
from
fact_log_user_hive_table a left join global_dict_by_userid_hive_table b
on a.user_id=b.user_idstep4:创建Spark离线同步任务完成Hive原始表到StarRocks明细表的数据同步:StarRocks表fact_log_user_doris_table定义(Hive表fact_log_user_hive_table与该表的结构一致):
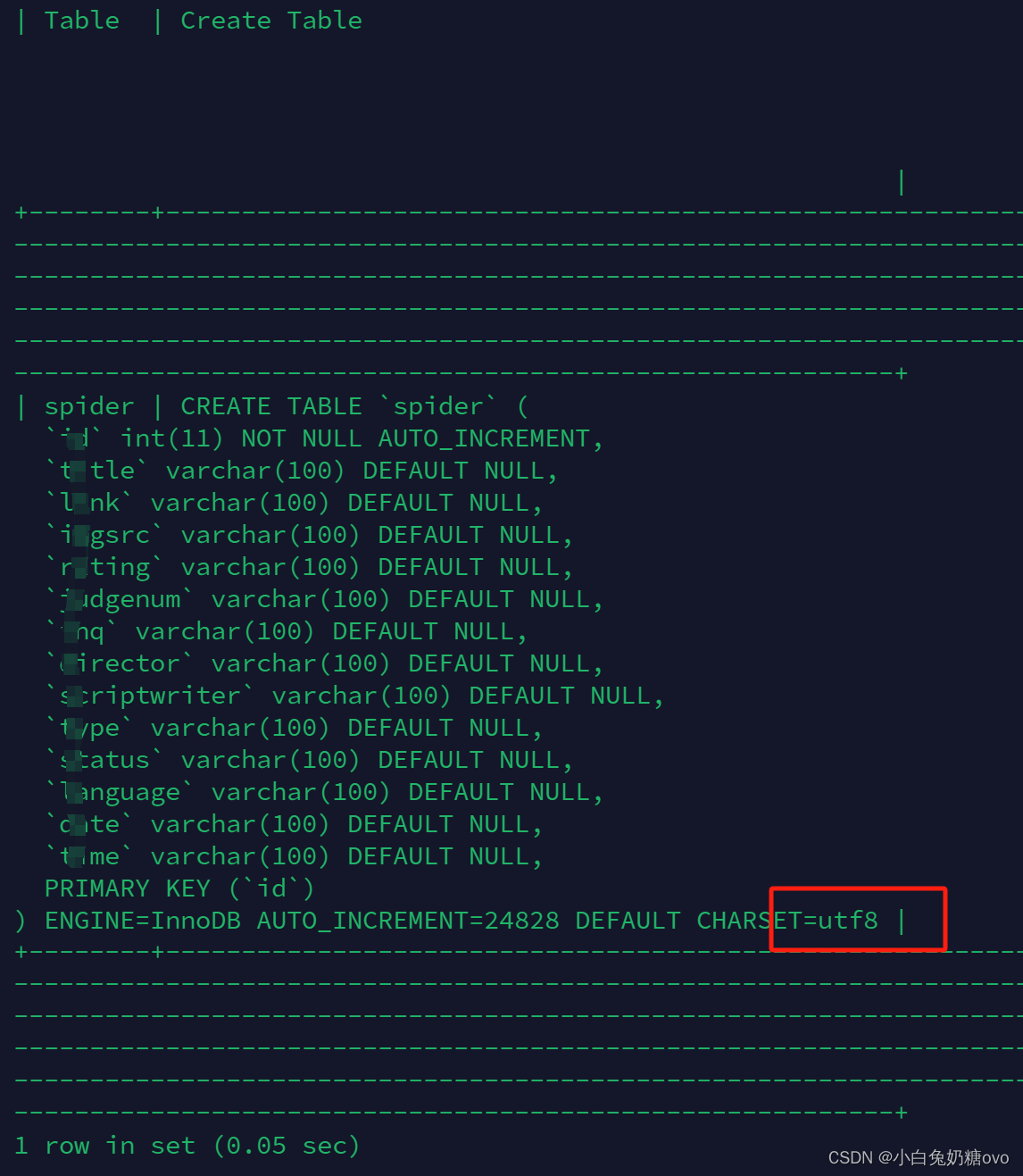
CREATE TABLE `fact_log_user_doris_table` (
`new_user_id` bigint(20) NULL COMMENT "整型用户id",
`user_id` varchar(65533) NULL COMMENT "用户id",
`event_source` varchar(65533) NULL COMMENT "端(1:商城小程序 2:团长小程序 3:独立APP 4:主端)",
`is_new` varchar(65533) NULL COMMENT "是否新用户",
`identity` varchar(65533) NULL COMMENT "用户身份(团长或者普通用户)",
`biz_channel_name` varchar(65533) NULL COMMENT "当天首次落地页渠道名称",
`pro_id` varchar(65533) NULL COMMENT "省ID",
`pro_name` varchar(65533) NULL COMMENT "省名称",
`city_id` varchar(65533) NULL COMMENT "城市ID",
`city_name` varchar(65533) NULL COMMENT "城市名称",
`dt` date NULL COMMENT "分区",
`period_type` varchar(65533) NULL DEFAULT "daily" COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`index_id`, `user_id`, `biz_channel_name`, `pro_id`, `city_id`)
PARTITION BY RANGE(`dt`)(
PARTITION p20210731 VALUES [('2021-07-31'), ('2021-08-01')),
PARTITION p20210801 VALUES [('2021-08-01'), ('2021-08-02')),
PARTITION p20210802 VALUES [('2021-08-02'), ('2021-08-03')),
PARTITION p20210803 VALUES [('2021-08-03'), ('2021-08-04')),
PARTITION p20210804 VALUES [('2021-08-04'), ('2021-08-05')),
PARTITION p20210805 VALUES [('2021-08-05'), ('2021-08-06')),
PARTITION p20210806 VALUES [('2021-08-06'), ('2021-08-07')),
PARTITION p20210807 VALUES [('2021-08-07'), ('2021-08-08')),
PARTITION p20210808 VALUES [('2021-08-08'), ('2021-08-09')))
DISTRIBUTED BY HASH(`index_id`, `user_id`) BUCKETS 10
PROPERTIES (
"replication_num" = "3",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.replication_num" = "-1",
"dynamic_partition.buckets" = "3",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);在这里使用了StarRocks的明细模型来建表,满足用户查询漏斗明细数据的使用场景,在明细表上根据不同的多维漏斗分析查询需求创建相应的物化视图,来满足用户选择不用维度查看漏斗模型每一个步骤用户精准去重数量的使用场景。
step5:创建bitmap_union物化视图提升查询速度,实现count(distinct) 精确去重:
由于用户想要在漏斗模型上查看一些城市用户转化情况,如下图的结果:

查询一般为:
select city_id, count(distinct new_user_id) as countDistinctByID from fact_log_user_doris_table where `dt` >= '2021-08-01' AND `dt` <= '2021-08-07' AND `city_id` in (11, 12, 13) group by city_id针对这种根据城市求精确用户数量的场景,我们可以在明细表fact_log_user_doris_table上创建一个带 bitmap_union 的物化视图从而达到一个预先精确去重的效果,查询时StarRocks会自动将原始查询路由到物化视图上,提升查询性能。针对这个case创建的根据城市分组,对user_id进行精确去重的物化视图如下:
create materialized view city_user_count as select city_id, bitmap_union(to_bitmap(new_user_id)) from fact_log_user_doris_table group by city_id;在StarRocks中,count(distinct)聚合的结果和bitmap_union_count聚合的结果是完全一致的。而bitmap_union_count等于bitmap_union的结果求 count,所以如果查询中涉及到count(distinct) 则通过创建带bitmap_union聚合的物化视图方可加快查询。因为new_user_id本身是一个INT类型,所以在 StarRocks 中需要先将字段通过函数to_bitmap转换为bitmap类型然后才可以进行bitmap_union聚合。
采用这种构建全局字典的方式,我们通过每日凌晨跑Spark离线同步任务实现全局字典的更新,以及对原始表中value列的替换,同时对spark任务配置基线和数据质量报警,保障任务的正常运行和数据的准确性,确保次日运营和市场同学能看到之前的运营活动对用户转化率产生的影响,以便他们及时调整运营策略,保证日常运营活动效果。
五、最终效果及收益
经过产品和研发的努力,从需要查询的城市数量,时间跨度,数据量三个维度对精确去重功能进行优化,亿级数量下150个城市ID精确区去重查询整体耗时3秒以内,以下是漏斗分析的最终效果:
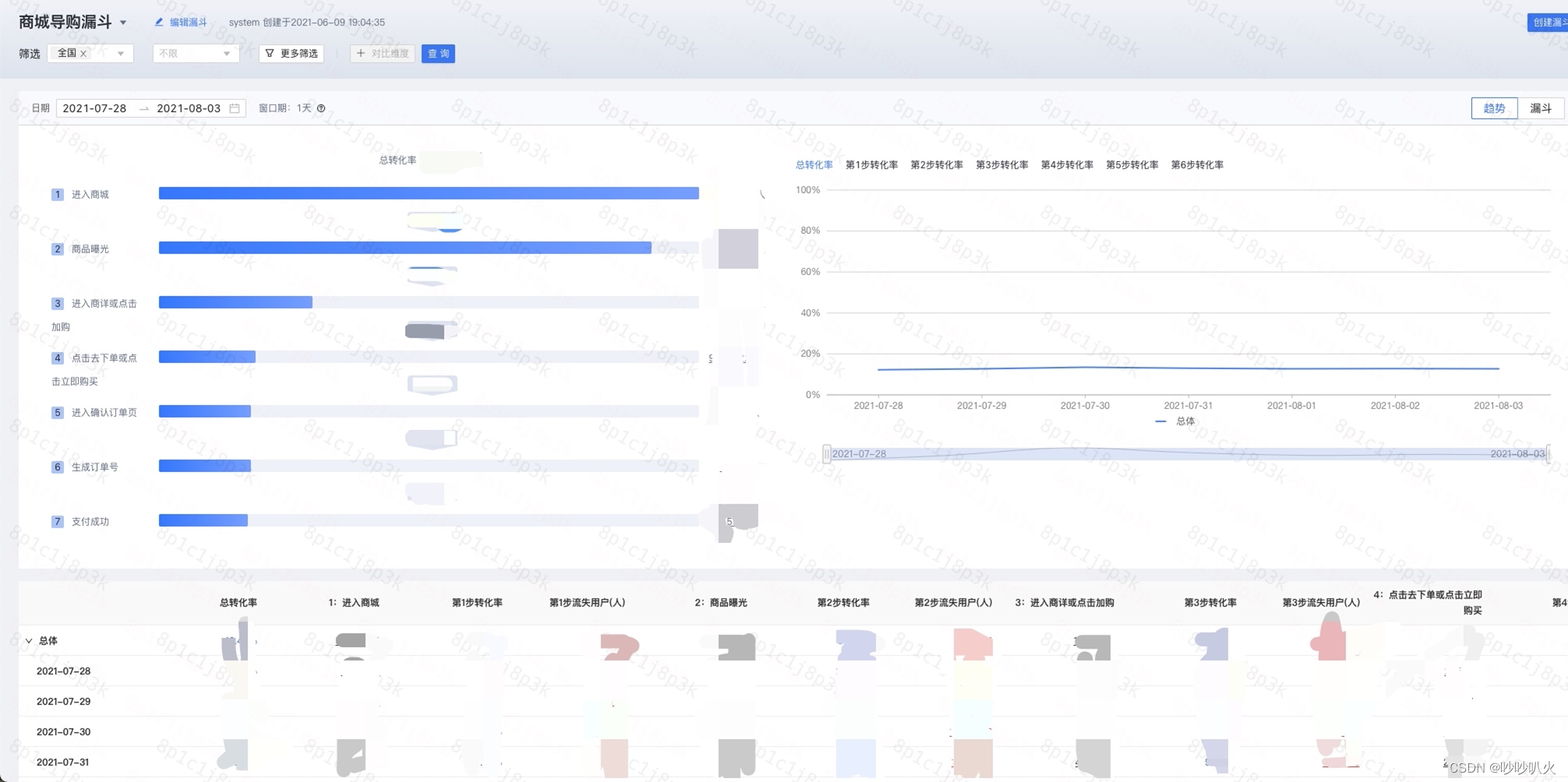
六、未来规划
完善StarRocks内部工具链的开发,同滴滴大数据调度平台和数据开发平台整合,实现Mysql、ES、HIve等数据表一键计入StarRocks。
StarRocks流批一体建设,由于StarRocks提供了丰富的数据模型,我们可以基于更新模型和明细模型以及物化视图构建流批一体的数据计算与存储模型,目前正在方案落地阶段,完善后会推广到橙心各个方向的数据产品上。
基于StarRocks on ElasticSearch的能力,实现异构数据源的统一OLAP查询,赋能不同场景的业务需求,加速数据价值产出。
后续我们也会持续关注 StarRocks ,在内部不断的升级迭代。期待 StarRocks 能提供更丰富的功能,和更开放的生态。StarRocks 后续也会作为OLAP平台的重要组件,实现OLAP层的统一存储,统一分析,统一管理。
参考文章:
滴滴 x StarRocks:极速多维分析创造更大的业务价值-腾讯云开发者社区-腾讯云







![[论文笔记]LLaMA: Open and Efficient Foundation Language Models](https://img-blog.csdnimg.cn/img_convert/5438e10bf23516a6eb5033737338c247.png)
