引言
今天带来经典论文 LLaMA: Open and Efficient Foundation Language Models 的笔记,论文标题翻译过来就是 LLaMA:开放和高效的基础语言模型。
LLaMA提供了不可多得的大模型开发思路,为很多国产化大模型打开了一片新的天地,论文和代码值得仔细研读。
作者引入了LLaMA系列模型,包含从7B到65B参数规模的模型。在万亿级tokens上训练,证明了仅使用公开数据集就可能训练得到SOTA的模型。具体地,LLaMA-13B在大多数基准上的表现优于GPT-3(175B),而LLaMA-65B可以和最好的模型Chinchilla-70B1和PaLM-540B2不相上下。
总体介绍
大语言模型(Large Languages Models, LLMs)在大规模文本语料库上训练后,已经展现出能够根据文本指示(textual instructions)或少量样本执行新任务的能力。
这些少样本特性第一次出现在模型达到足够规模后,导致后来一系列工作着重于进一步扩大模型规模。认为模型参数越多,最终的效果也越好。然而近期的工作1表明,在给定计算预算下,最好的性能并不是由最大的模型实现的,而是由在更多数据上训练的较小模型实现的。
Hoffmann等人1提出的规模定律(scaling laws)的目标是在给定训练计算预算下,最佳的数据集规模和模型大小是什么。然而它的目标忽略了推理成本,当成规模部署大模型时会是一个重要问题。因此,更好的模型不是训练有多快,而是推理有多快,训练一个较小的模型更久最终在推理时会更经济。例如,虽然Hoffmann等人建议在200B个标记上训练一个10B模型,但作者发现即使在训练1T个标记之后,7B模型的性能仍在持续提高。
本篇工作的重点是训练一系列语言模型,使用比通常更多的token数来进行训练,在不同的推理预算下实现最佳性能。最后得到的模型称为LLaMA,参数范围从7B到65B,与现有最佳的大语言模型相比具有竞争力的性能。
与Chinchilla、PaLM或GPT-3不同的是,仅使用公开可用的数据,使得这篇工作的效果理论上更易于复现且更开源。
方法
作者的训练方法类似GPT和PaLM,并受到Chinchilla的规模定律启发。在大量文本数据上使用标准的优化器训练大型的Transformer。作者强调更多的训练数据更加重要,本节主要介绍使用了哪些公开的训练数据。
预训练数据
预训练数据集由不同数据源组成,数据来源和比重如表1所示。
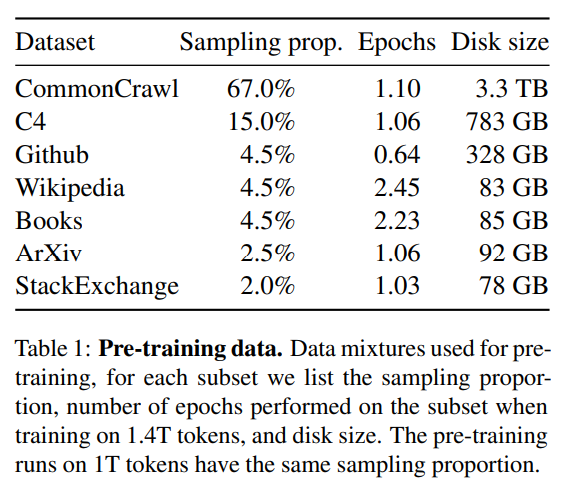
限制只使用公开可用且与开源兼容的数据。得到以下数据混合以及它们在训练集中所占的百分比:
English CommonCrawl [67%] 对来自2017年至2020年的五个CommonCrawl存储进行预处理,使用CCNet管道。该过程在行级别对数据进行去重,使用fastText线性分类器进行语言识别以删除非英语页面,并使用ngram语言模型过滤低质量内容。此外,还训练了一个线性模型来对维基百科中用作参考的页面进行分类,与随机抽样页面进行对比,并丢弃未被分类为参考的页面。
C4 [15%] 在探索性实验中,作者观察到使用多样化预处理的CommonCrawl数据集可以提高性能。因此,在数据中包括了公开可用的C4数据集。C4的预处理也包括去重和语言识别步骤:与CCNet的主要区别在于质量过滤,这主要依赖于启发式方法,如网页中标点符号的存在或单词和句子的数量 。
Github [4.5%] 使用了公开的GitHub数据集。只保留了根据Apache、BSD和MIT许可证分发的项目。此外,使用基于行长度或字母数字字符比例的启发式方法过滤低质量文件,并使用正则表达式去除了诸如标题之类的样板文件。最后,在文件级别对结果数据集进行了去重,使用精确匹配的方式。
Wikipedia [4.5%] 添加了涵盖20种语言的维基百科存储数据,时间跨度为2022年6月至8月。对数据进行处理,去除超链接、注释和其他格式化模板。
Gutenberg and Books3 [4.5%] 在训练数据集中包含了两个书籍语料库:Gutenberg,其中包含公有领域的图书,以及ThePile的部分。在书籍级别进行了去重处理,删除了内容重叠度超过90%的书籍。
ArXiv [2.5%] 处理arXiv的LaTeX文件,将科学数据添加到数据集中。删除了第一节之前的所有内容以及参考文献部分。还删除了.tex文件中的注释,并对用户编写的定义和宏进行了内联扩展,以增加论文之间的一致性。
Stack Exchange [2%] 包含了Stack Exchange的一个数据备份,这是一个高质量的问答网站,涵盖了从计算机科学到化学等各种领域。保留了最大的28个网站的数据,从文本中删除了HTML标签,并按照得分(从高到低)对回答进行了排序。
Tokenizer 使用SentencePiece包实现的字节对编码算法(Byte-Pair Encoding BPE)对数据进行分词。将数字的每一位单独分开,避免出现数字不一致的问题,可以更好地理解和处理数值,极大地提高了数学能力。同时在遇到罕见词时使用byte编码分解未知的UTF-8 字符,做到未知词覆盖。
总体来说,整个训练数据集包含大约1.4T的标记。对于大部分训练数据,每个标记在训练过程中只使用一次,除了维基百科和图书领域对其进行了大约两个epoch的训练。
架构
基于Transformer架构,同时采用了后续的一些改进。下面是这篇工作主要引入的改进以及灵感来源(在方括号中):
Pre-normalization[GPT3] 为了提升训练稳定性,对每个Transformer子层的输入也进行归一化,而不是对归一化输出。同时使用由3提出的RMSNorm归一化方法。
SwiGLU激活函数[PaLM] 替换ReLU激活函数为4提出的SwiGLU函数以提升性能。使用 2 3 4 d \frac{2}{3}4d 324d的维度而不是PaLM中的 4 d 4d 4d。
旋转嵌入[GPTNeo] 没有使用绝对位置嵌入,而是使用旋转位置嵌入(Rotary Positional Embedding,RoPE),由苏神5等人提出。
作者四个不同规模模型的超参数细节可见表2。
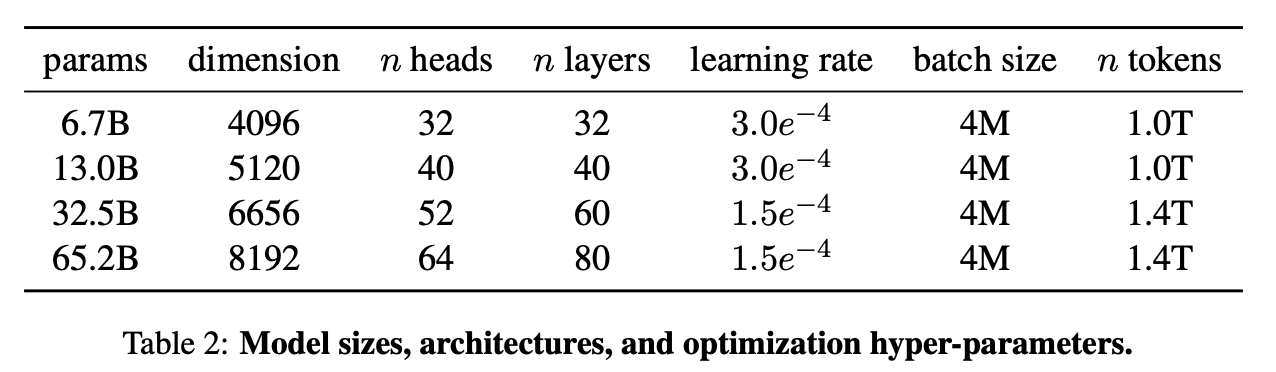
可以看到参数量越大,批大小不变的情况下,学习率越小的趋势。
优化器
- 使用AdamW优化器训练,参数为: β 1 = 0.9 , β 2 = 0.95 \beta_1=0.9,\beta_2=0.95 β1=0.9,β2=0.95。
- 使用余弦学习率调度,这样最终的学习率等于最大学习率的10%。
- 使用权重衰退率为0.1。
- 梯度裁剪为1.0。
- 预热步为2000。
- 学习率和批大小根据模型规模而不同(见表2)。
高效实现
作者做了一些优化来提升训练速度。
首先,使用了一个因果多头注意力的高效实现来减少运行时的内存占用,该实现由可通过xformers获取,受到了Selfattention does not need o ( n 2 ) o(n^2) o(n2) memory的启发。并采用了FlashAttention6,基于语言建模任务的自回归性质,通过未存储注意力权重和未计算key/query得分来实现高效地反向传播。
同时为了进一步提升训练效率,通过检查点减少在反向传播时重复计算的激活值数量。具体地,存储了消耗较大的激活函数的计算结果,比如线性层的输出。这通过手动为Transformer实现反向传播函数,而不是利用PyTorch实现。为了充分利用该优化,需要使用7提出的模型和序列并行技术来减少模型内存的占用。此外,还尽可能地重叠激活计算和GPU之间的网络通信(通过all_reduce操作)。
当训练一个65B参数的模型,在2048个80G显存的A100上的处理速度约为380个标记/秒/GPU。这意味着使用包含1.4T个标记的数据集进行训练大约需要21天的时间。
主要结果
本节介绍了作者报告的结果。
涉及了零样本和少样本任务,一共报告了20个基准:
- 零样本 提供了一个任务的文本描述和一个测试样本,模型要么通过开发式生成答案要么对提供的答案进行排序。
- 少样本 提供了任务的一些样本(1~64之间)和一个测试样本。模型以这个文本作为输入并生成答案或对不同的选项进行排序。
在自由生成任务和多项选择任务上评估LLaMA。
常识推理
考虑了8个标准的尝试推理基准。
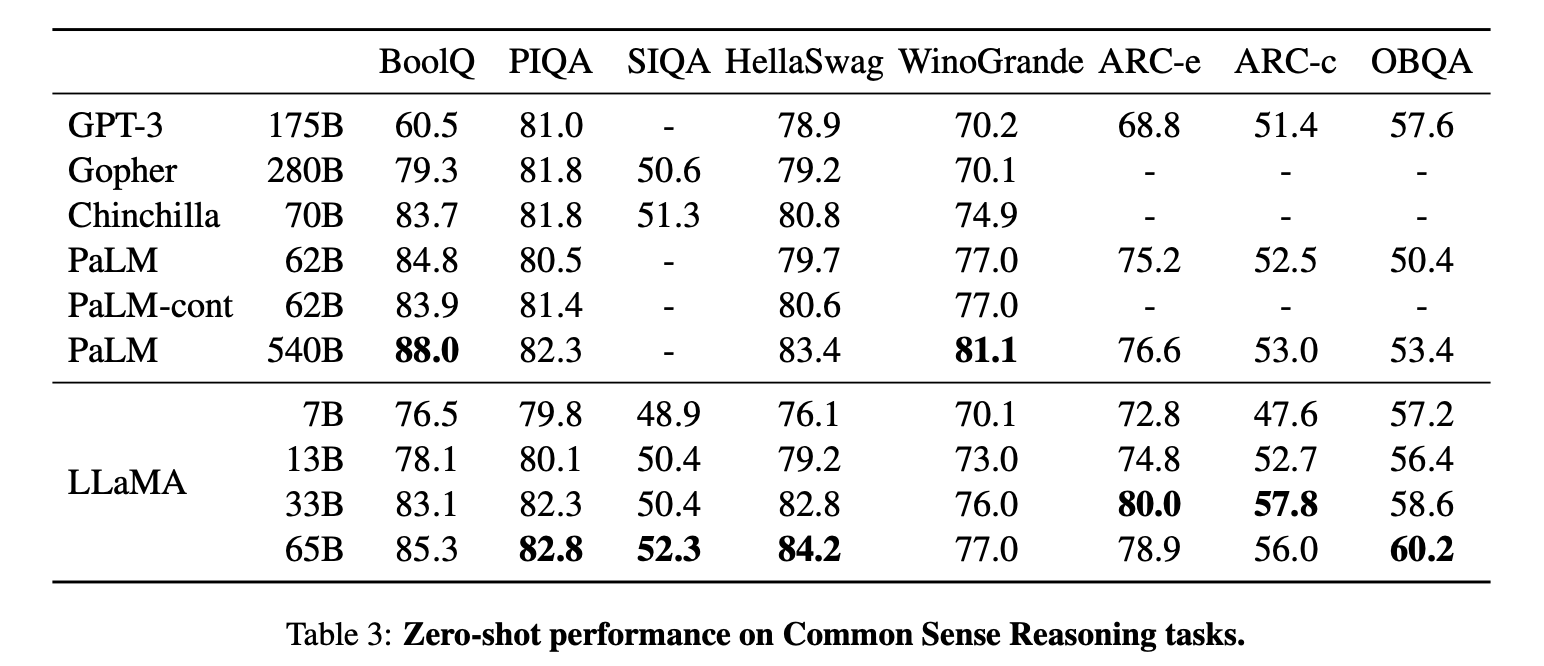
如表3所示,LLaMA-65B在绝大多数基准上超越了Chinchilla-70B。而LLaMA-13B也在大多数基准上超越了GPT-3,尽管前者比后者小了10倍以上。
闭卷问答
将LLaMA与现有的LLM在两个闭卷问题回答基准中进行比较:自然问题(Natural Questions)和TriviaQA。
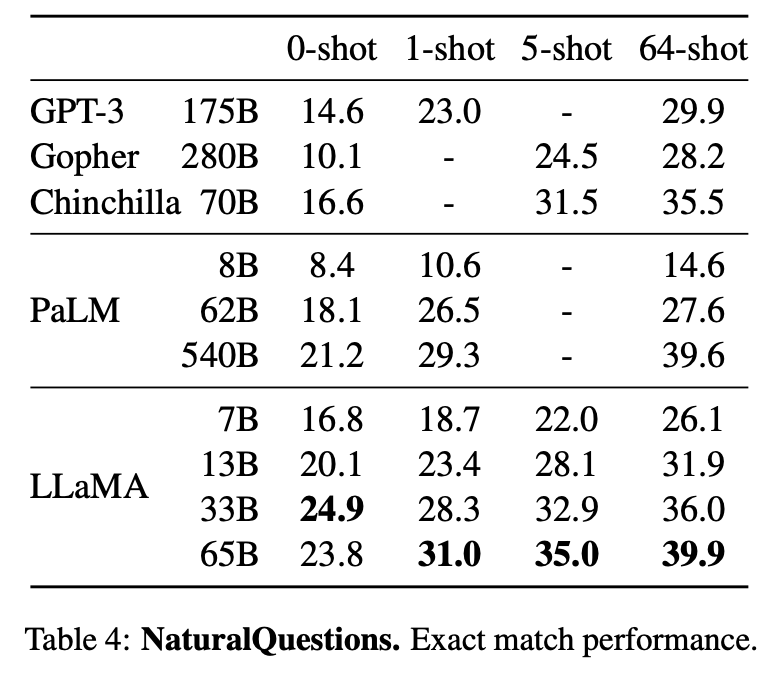
在表4中,作者报告了在自然问题上的性能,而在表5中,报告了在TriviaQA上的性能。
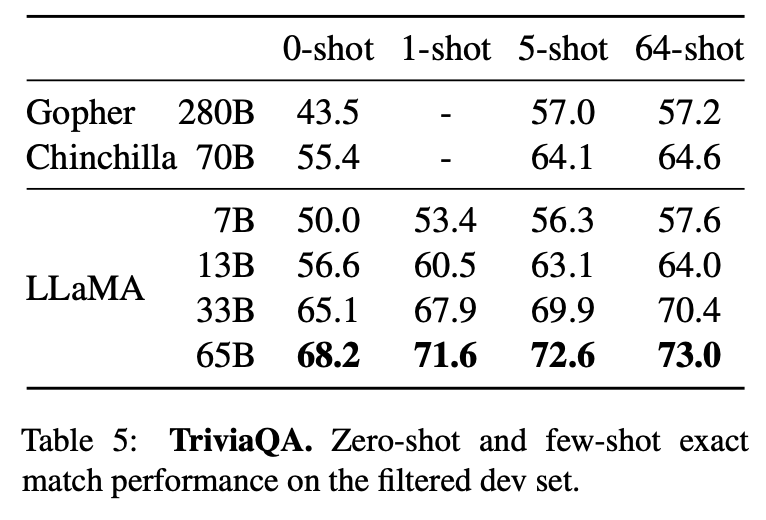
在这两个基准测试中,LLaMA-65B在零样本和少样本设置下取得了SOTA的性能。更重要的是,尽管LLaMA-13B的规模较小,但在这些基准测试中也具有竞争力。
阅读理解
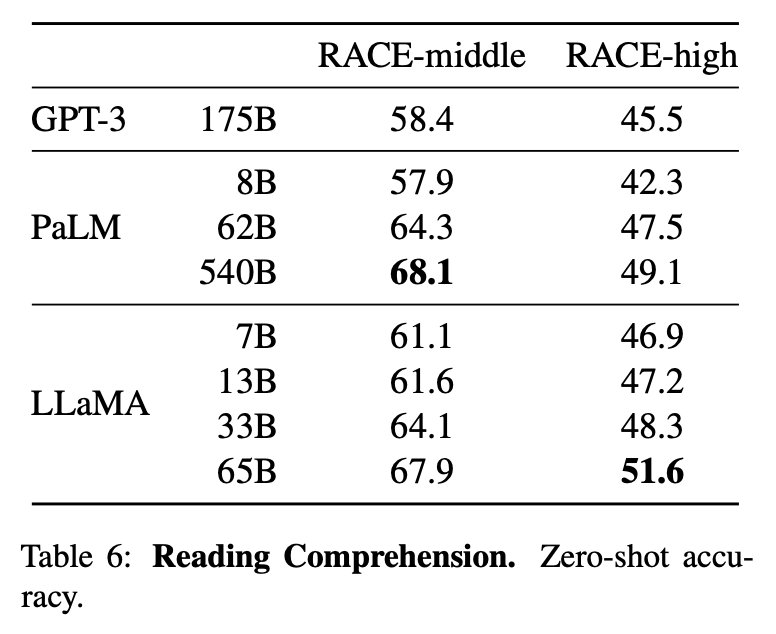
如表6所示,在基准测试中,LLaMA-65B与PaLM-540B相媲美,而LLaMA-13B的性能也比GPT-3高出几个百分点。
数学推理
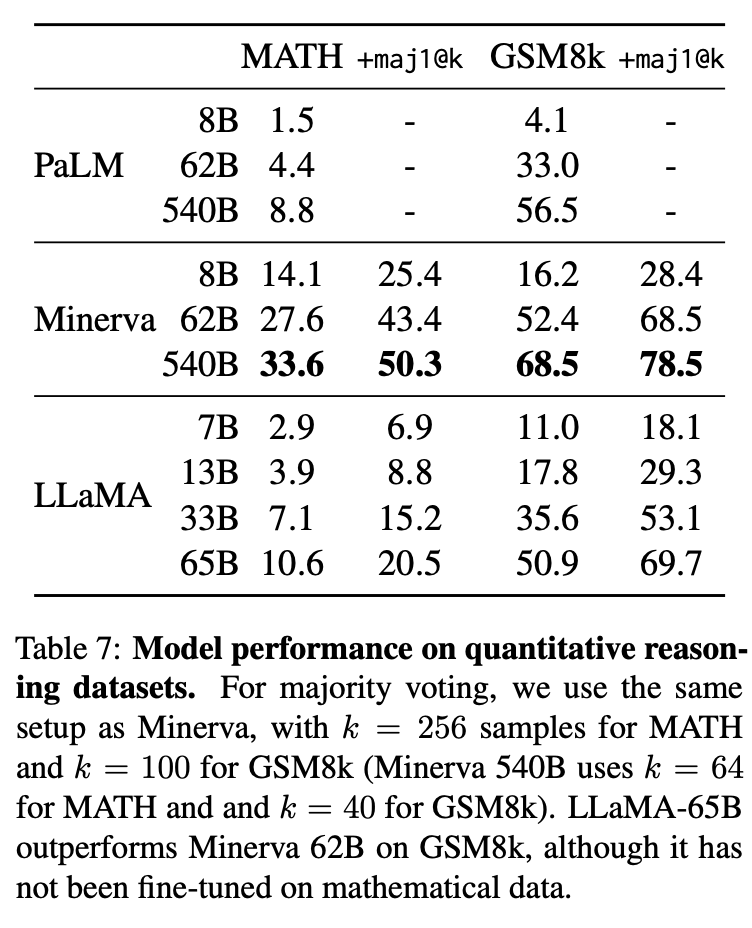
在表7中,与PaLM和Minerva进行了比较。Minerva是一系列在ArXiv和数学网页中提取的38.5B标记上微调的PaLM模型,而PaLM和LLaMA都没有在数学数据上进行微调。在GSM8k上,可以看到LLaMA-65B的性能优于Minerva-62B。
代码生成
还在HumanEval和MBPP基准测试上评估根据自然语言描述编写代码的能力。模型需要生成一个符合描述并满足测试用例的Python程序。
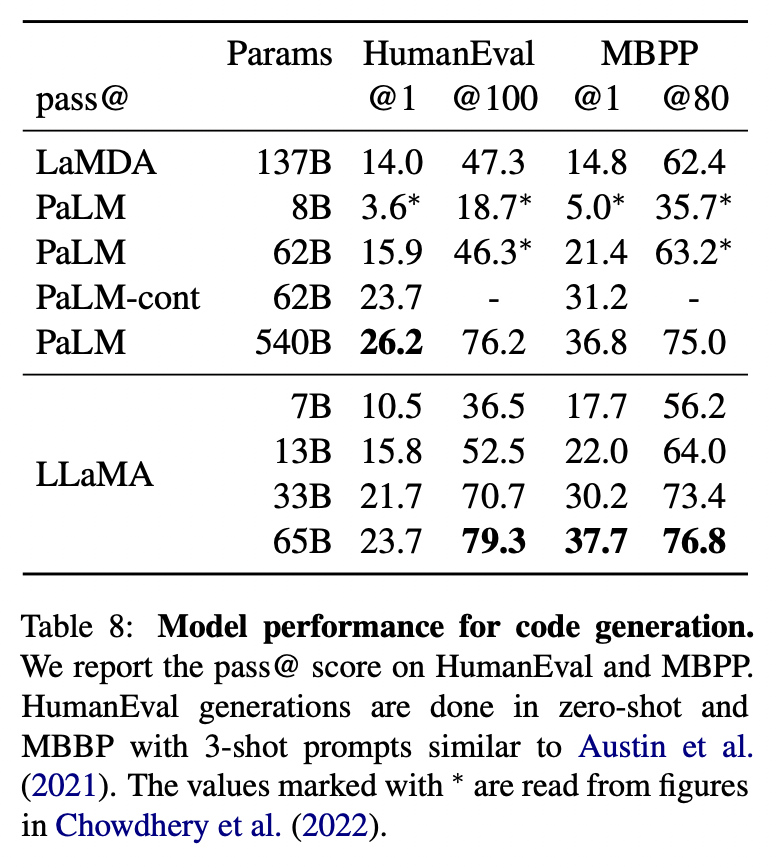
如表8所示,对于类似的规模上,LLaMA在性能上优于其他通用模型,如LaMDA和PaLM。LLaMA在HumanEval和MBPP上的13B参数以上的性能也超过了LaMDA 137B。LLaMA-65B也优于PaLM-62B。
在包含代码的数据上进行微调可以提高模型的代码性能,同时还能提高模型的逻辑推理能力。
大规模多任务语言理解
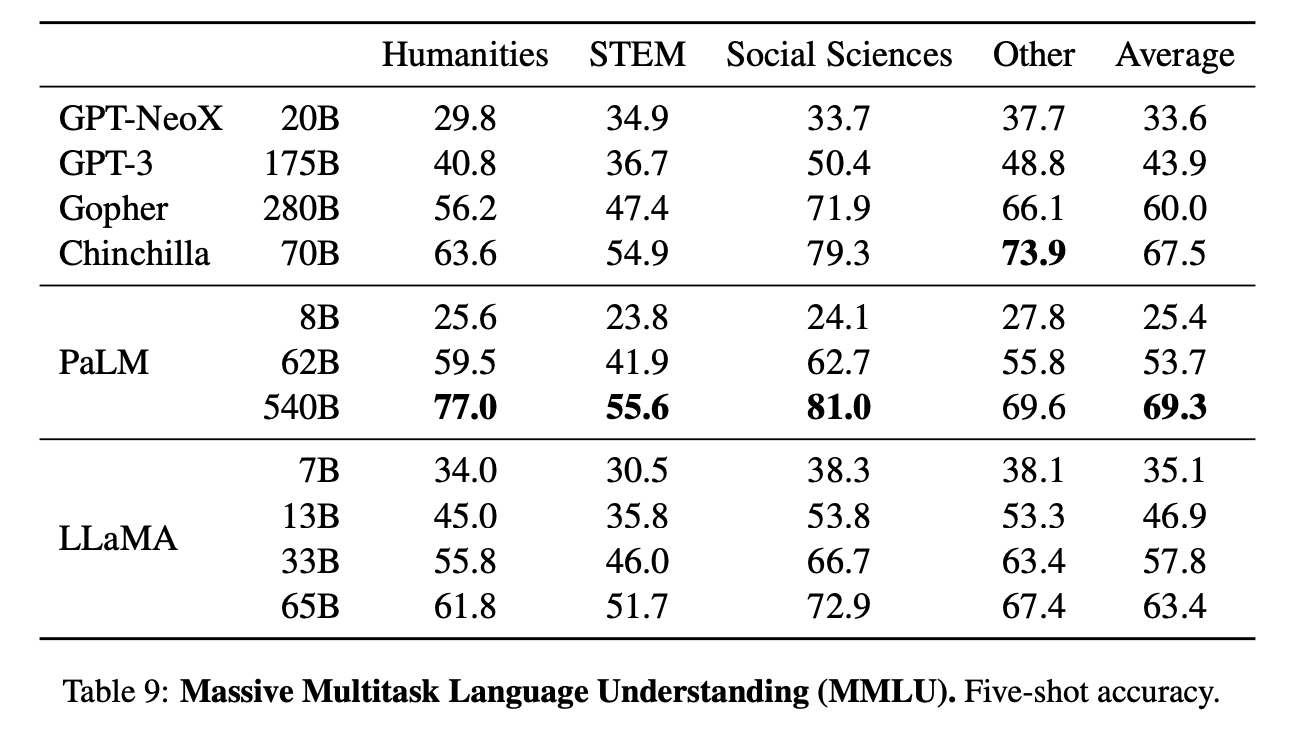
在表9中的结果所示,在这个基准测试中,LLaMA-65B在平均值和大多数领域上都落后于Chinchilla-70B和PaLM-540B几个百分点。一个可能的解释是,LLaMA在预训练数据中使用的书籍和学术论文数量有限,即ArXiv、Gutenberg和Books3,总计只有177GB,而这些模型是在多达2TB的书籍上进行训练的。
训练期间的性能评估
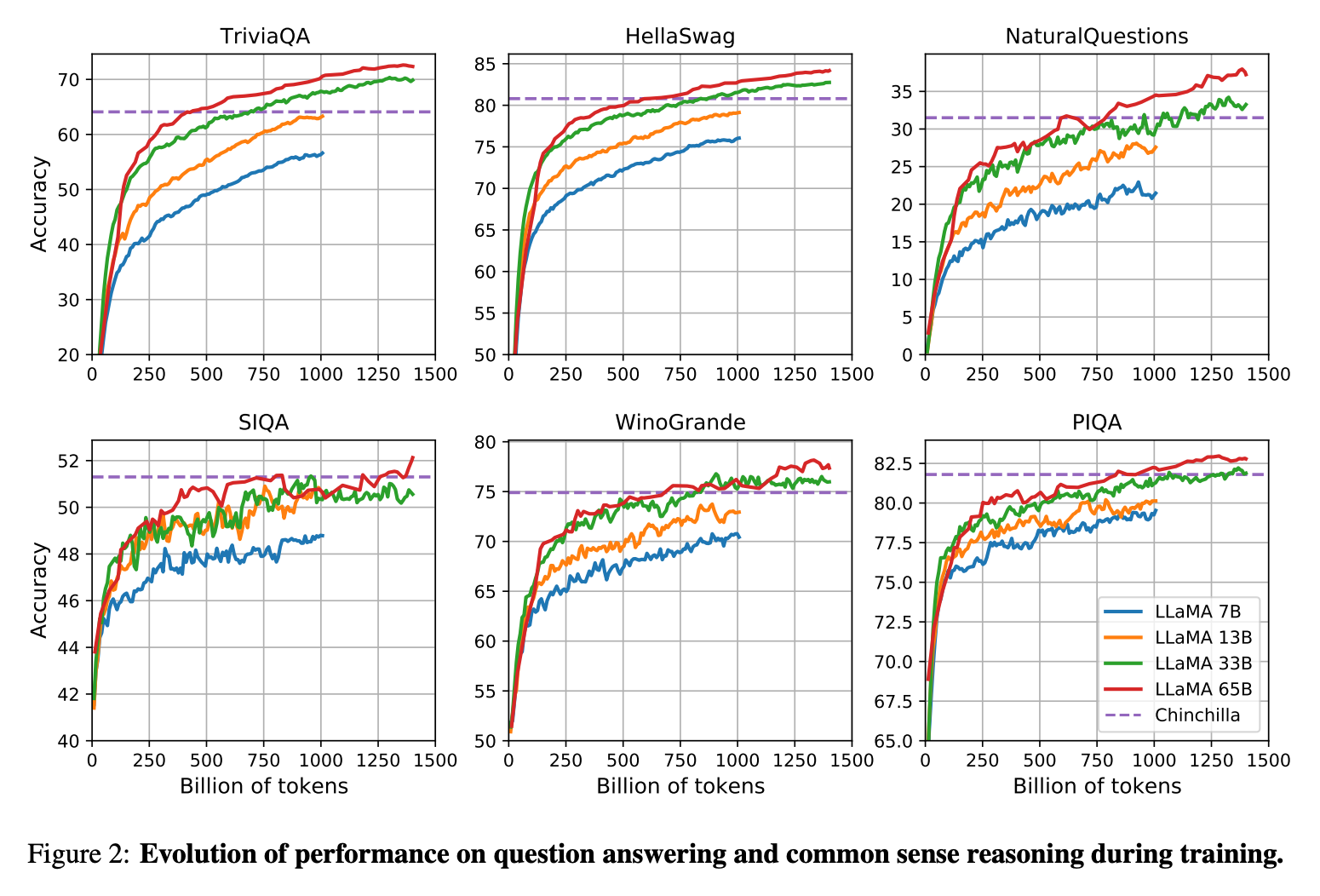
在训练过程中,作者追踪了模型在一些问答和常识基准测试中的性能(图2)。在大多数基准测试中,性能稳步提高,并与模型的训练困惑度相关(见图1)。但有两个例外,即SIQA和WinoGrande。特别是在SIQA上,可以观察到性能存在很大的变化,可能是该基准测试不太可靠。在WinoGrande上,性能与训练困惑度的相关性不太明显:LLaMA-33B和LLaMA-65B在训练过程中的性能相似。
指令微调
在本节中,作者展示了简单的微调指令数据可以迅速改善MMLU的性能。作者观察到少量样本的微调就可以提高在MMLU上的性能,并进一步提高模型遵循指令的能力。
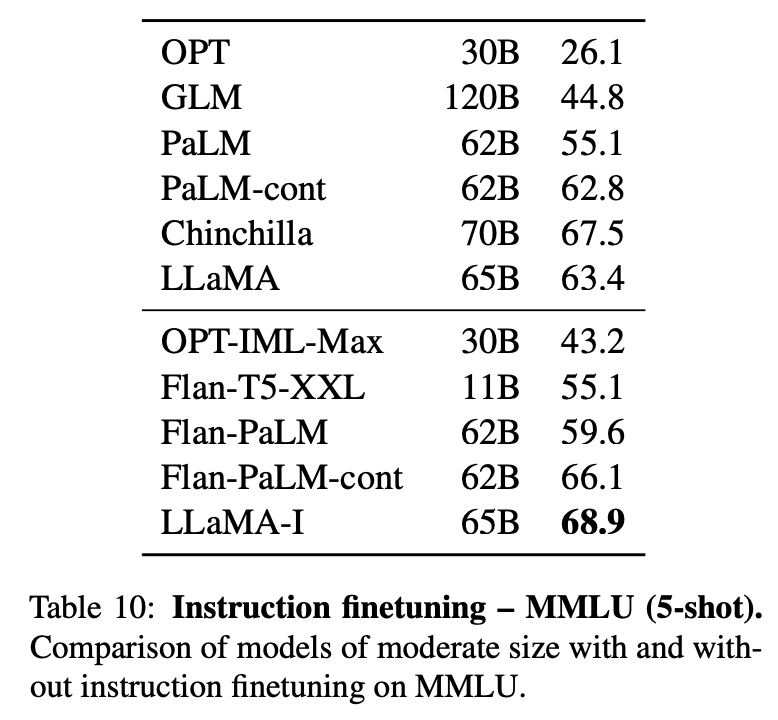
在表10中,可以看到指令模型LLaMA-I在MMLU上的结果,并与现有中等规模的指令微调模型进行了比较,包括OPT-IML和Flan-PaLM系列。尽管这里使用的指令微调方法相对简单,但在MMLU上达到了68.9%的性能。虽然LLaMA-I(65B)在MMLU上的表现优于现有的中等规模指令微调模型,但仍然远远落后于最先进的水平,即GPT code-davinci-002在MMLU上的77.4。
偏见/毒性/错误
LLM被证明会重现并强化存在与训练数据中的偏见,并生成毒性或冒犯性内容。由于训练数据集包含了大量来自网络的数据,作者认为确定模型生成此类内容的可能性是至关重要的。为了了解LLaMA-65B的潜在危害,在不同的基准测试上进行了评估,这些测试衡量了有害内容的生成和偏见的检测。虽然选择了一些用于指示这些模型存在问题的标准基准测试,但这些评估并不足以完全理解与这些模型相关的风险。
RealToxicityPrompts
语言模型可以生成有毒内容,例如侮辱、仇恨言论或威胁。RealToxicityPrompts包含约10万个提示,模型必须补全这些提示;然后通过向PerspectiveAPI进行请求来自动评估毒性得分。
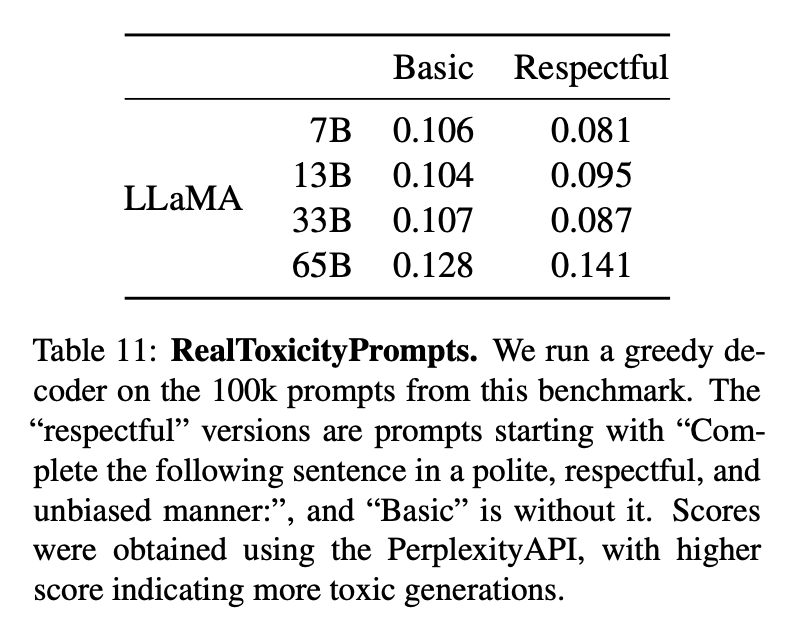
对于这10万个提示中的每一个,使用模型贪婪地生成,并测量它们的毒性得分。每个提示的得分范围从0(非毒性)到1(毒性)。在表11中,报告了在RealToxicityPrompts的Basic和Respectful类别上的平均得分。可以观察到,毒性随模型规模增加而增加,尤其是对于Respectful的提示。但毒性与模型大小之间的关系可能仅适用于模型系列内部。
CrowS-Pairs
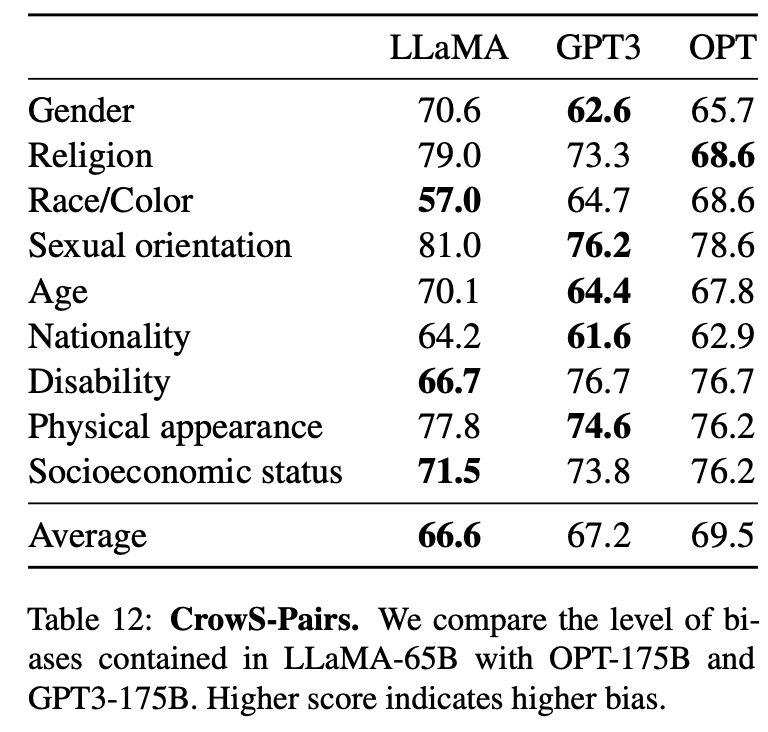
在CrowSPairs数据集上评估了模型的偏见,该数据集可以衡量9个类别的偏见:性别、宗教、种族/肤色等。使用零样本设置中两个句子的困惑度来衡量模型对偏见句子的偏好。因此,得分较高表示偏见较高。在表12中与GPT-3和OPT-175B进行了比较。在平均水平上,LLaMA与这两个模型相比稍微有些优势。作者认为这些偏见可能来自于CommonCrawl,尽管经过了多次过滤步骤。
WinoGender
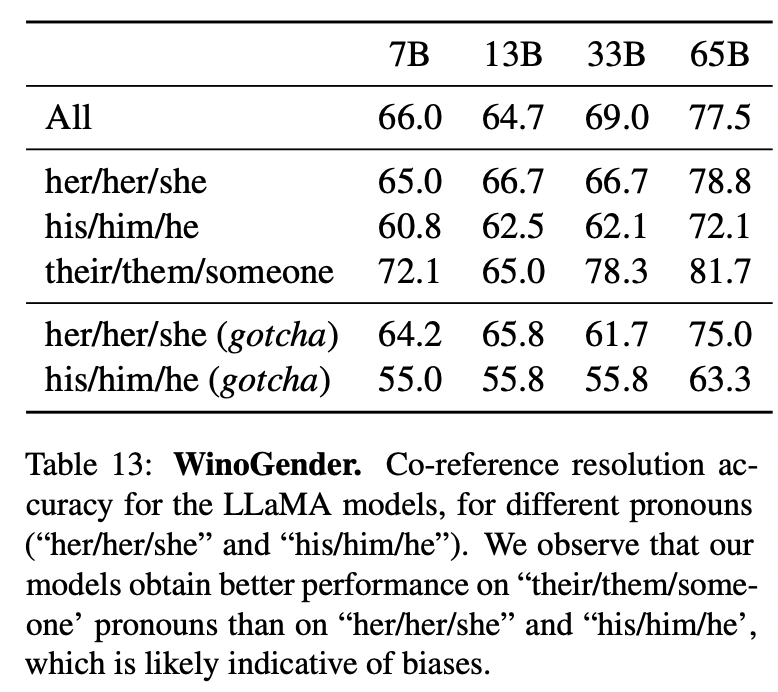
进一步研究了在性别上的偏见。还测试了WinoGender基准,这是一个共指消解数据集,通过确定模型的共指消解性能是否受到代词性别的影响来评估偏见。
每个句子都有三个指代:一个职业,一个参与者和一个代词,其中代词要么指代职业,要么指代参与者。目标是揭示模型是否捕捉到与职业相关的社会偏见。
在表13中,看到了模型数据集中包含的三个不同代词的共指分数。模型在their/them/someone代词的共指消解上要比her/her/she和his/him/he代词表现显著更好,这很可能表明存在性别偏见。
TruthfulQA
TruthfulQA旨在衡量模型的真实性,即其识别声明是否真实的能力。该基准测试可以评估模型生成错误信息或虚假声明的风险。问题以多样的风格编写,涵盖了38个类别,并且被设计为对抗性的。
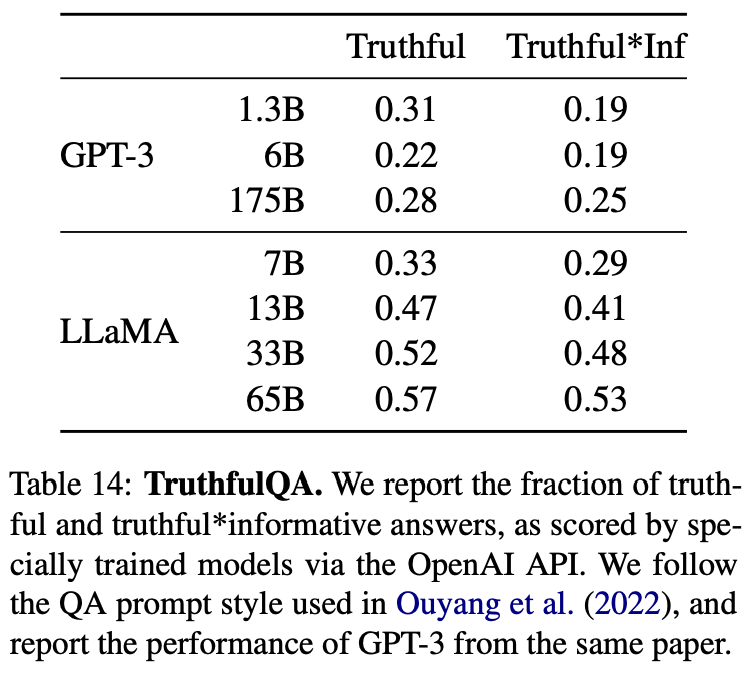
在表14中,可以看到模型在衡量真实模型和真实且信息丰富的问题上的表现。与GPT-3相比,虽然LLaMA在这两个类别中得分更高,但正确答案的比率仍然较低,表明LLaMA很可能会产生不正确的答案。
相关工作
语言模型 语言模型是对单词、标记或字符序列的概率分布表示。这个任务通常被称为下一个标记预测,并且长期以来一直被认为是自然语言处理中的核心问题。由于图灵提出通过“模仿游戏”来使用语言来衡量机器智能,因此语言建模已被提出作为衡量人工智能进展的基准。
架构 传统上,语言模型基于n-gram计数统计,并提出了各种平滑技术来改善对罕见事件的估计。在过去的二十年中,神经网络已成功应用于语言建模任务,从前馈模型、循环神经网络到LSTM。近来,基于自注意力机制的Transformer网络取得了重要的改进,特别是在捕捉长距离依赖性方面。
规模 语言模型的扩充有着悠久的历史。无论是模型还是数据集的规模。Brants等人展示了在2万亿标记上训练的语言模型的优势,结果是有3000亿个n-gram,对机器翻译的质量有所提升。Heafield等人后来展示了如何将Kneser-Ney平滑技术扩展到Web规模的数据上。这使得能够在来自CommonCrawl的9750亿标记上训练一个5-gram模型,产生了具有5000亿个n-gram的模型。
在神经语言模型的背景下,Jozefowicz通过将LSTM扩展到10亿个参数,在十亿字基准测试中取得了最先进的结果。后来,通过扩展Transformer在许多自然语言处理任务上取得了改进。值得注意的模型包括BERT、GPT-2、MegatronLM和T5。重要的突破是通过GPT-3取得的,这是一个具有1750亿个参数的模型。这导致了一系列大规模语言模型的出现,例如Jurassic-1、Megatron-Turing NLG、Gopher(、Chinchilla、PaLM、OPT和GLM。Hestness等人研究了扩展对深度学习模型性能的影响,展示了模型和数据集大小与系统性能之间存在的幂律关系。Kaplan等人专门为基于Transformer的语言模型推导了幂律关系,后来由Hoffmann等人通过调整学习率调度来改进。最后,Wei等人研究了扩展规模对大型语言模型能力的影响。
结论
在本论文中,作者介绍了一系列开放的语言模型,并与最先进的基准模型进行了竞争。与以前的研究不同,作者展示了通过仅使用公开可用的数据进行训练,而无需使用专有数据集,可以实现最先进的性能。
总结
⭐ 作者提出了LLaMMA系列模型,可以说天不生LLaMMA,开源大模型万古如黑夜。比较详细的介绍了模型实现细节,重要的是开源了实现代码。除了提供了在模型实现优化上的思路外,还给出了提高训练(推理)效率的方法。
参考
Training Compute-Optimal Large Language Models ↩︎ ↩︎ ↩︎
PaLM: Scaling Language Modeling with Pathways ↩︎
Root Mean Square Layer Normalization ↩︎
GLU Variants Improve Transformer ↩︎
ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING ↩︎
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness ↩︎
Reducing Activation Recomputation in Large Transformer Models ↩︎




![[数据集][目标检测]零售柜零食检测数据集VOC+YOLO格式5422张113类](https://img-blog.csdnimg.cn/direct/7a4d2cc4bc99494182c1537f7f797699.png)