知网链接
一种修正评分偏差并精细聚类中心的协同过滤推荐算法 - 中国知网 (cnki.net)
摘要
协同过滤作为国内外学者普遍关注的推荐算法之一,受评分失真和数据稀疏等问题影响,算法推荐效果不尽如人意。为解决上述问题,本文提出了一种改进的聚类协同过滤推荐算法。首先,该算法利用无监督情感挖掘技术将评论情感映射为一个固定区间中的值,通过加权修正用户评分偏差;随后,构建修正后用户-产品评分矩阵的数据场,利用启发式寻优算法计算最佳聚类数和最优初始聚类中心,进而对用户进行划分聚类,结合最近邻用户相似性与评分产生推荐;最后,基于三个自建真实数据集对所提算法性能和有效性进行全面评估。实验结果表明,改进算法在Precision精度、Recall召回率和F1-Score评价指标上的表现均优于其它算法,能够有效应对数据稀疏,提升推荐系统的推荐效果。
1.引言
近年来,推荐系统作为传统搜索引擎的重要补充,成为帮助用户专注有用信息和缓解信息过载的重要工具,而协同过滤是个性化推荐系统中使用最普遍的推荐算法[1]。为应对协同过滤算法的数据稀疏性等问题,既有研究往往结合聚类[2]、回归[3, 4]、图[5]等算法或矩阵分解[6]、多模态数据融合[7]、矩阵填充[1]等技术进行组合推荐。在聚类算法方面,划分聚类算法因具有准确率高和可操作性强等优点常被学者加以改进后对用户进行聚类。
针对划分聚类算法存在不足,既有研究主要利用手肘法[8]、轮廓系数[9]、谱聚类[10]、粗聚类[11]等算法进行改进。尽管上述改进算法在一定程度上提升了基于划分聚类的协同过滤推荐(Divide Clustering-based Collaborative Filtering Recommender, DC-CFR)算法的推荐效果,但仍存在以下不足值得进一步研究:(1)评分失真且评分区分度小。现有产品评分多为“5星评价”,离散有限数值往往难以准确量化用户真实喜好[12],而这种偏差会进一步影响用户聚类中高维稀疏评分向量间的空间距离测算,影响DC-CFR算法表现。此外,受从众效应和可得性效应影响,用户评分分布较为集中[13, 14],信息量小,通过空间距离或相关系数比较用户间异同的难度增大;(2)初始聚类中心随机。自由参数问题是划分聚类算法的主要缺陷。相比于最佳聚类数的确定,初始聚类中心的选择较少被讨论和研究。而随机初始聚类中心不仅易使聚类结果陷入局部最优,而且会增加聚类迭代次数,累积数据稀疏造成的用户聚类偏差,影响DC-CFR算法推荐效果。
鉴于此,本文提出一种基于评论情感挖掘与数据场聚类的协同过滤推荐算法(Comment Sentiment Mining and Data Field Clustering-based Collaborative Filtering Recommender, CSM-DFC-CFR),该算法首先利用高频词性路径规则等无监督情感挖掘技术量化评论情感来修正用户-产品评分矩阵中的评分,然后利用数据场算法计算划分聚类自由参数的取值,接着通过基于相似用户的聚类协同过滤推荐算法生成产品推荐列表,最后在三个真实数据集上进行实验,验证改进算法的推荐效果。
2.基于划分聚类的协同过滤推荐算法


3.基于评论情感挖掘与数据场聚类的协同过滤算法(参考原文)
3.1 评论情感挖掘
3.2 数据场算法
3.3 改写的协同过滤推荐算法
3.3.1 算法模型构建
3.3.2 算法描述
3.3.3 算法流程
4.实验设计与结果讨论
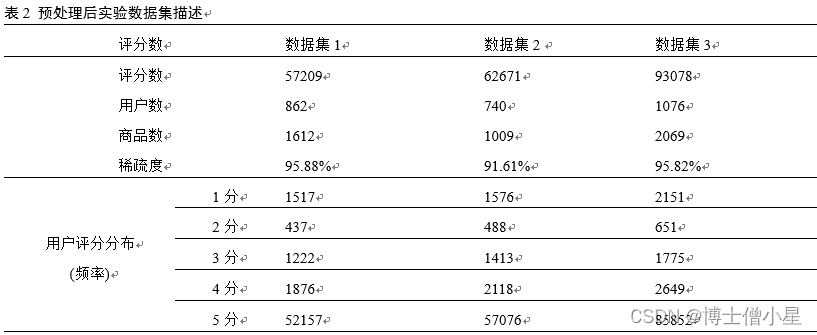
4.1 数据来源与处理
遵循网站robots协议,利用爬虫采集了某知名电商平台1190个类目下153129个商品的评分及评论文本(2015/6/17~2020/5/9) ,从中随机抽取三组数据作为实验数据集,分别占原始评分数据的0.8%(数据集1)、0.9%(数据集2)和1.1%(数据集3)。同时,剔除历史评分总数为0的用户行和产品列,并按用户评分时间先后将前80%数据作为训练集,后20%数据作为测试集,以供模型训练使用。实验数据集描述如表2所示。
4.2 评价指标与对照算法
采用Precision(公式(15))、Recall(公式(16))和F1-Score(公式(17))共三种常见评价指标[鑫1] 对算法推荐效果进行评价[15, 22, 23]。特别的,所有评价指标均依据产品推荐列表R(u)和测试集用户选择列表T(u)计算得出。
关于对照算法,选择基于用户的协同过滤推荐(U-CFR) 算法、基于K-means的协同过滤推荐 (KM-CFR) 算法、融合Canopy和K-means的协同过滤推荐 (CKM-CFR) 算法、基于评论情感挖掘的协同过滤推荐 (CSM-CFR) 算法、基于数据场聚类的协同过滤推荐 (DFC-CFR) 算法以及本文所提算法 (CSM-DFC-CFR) 共六种算法在三个实验数据集上进行实验,所有实验结果为1折15次交叉实验结果的平均。
4.3 实验结果
4.3.1 参数影响
对于评分修正幅度Δ,分别取Δ为0.1、0.2、0.3、0.4和0.5,探讨Δ最佳取值。由图2可知,CSM-DFC-CFR算法精度在Δ=0.4时最优(召回率也相对较优),算法表现最佳。
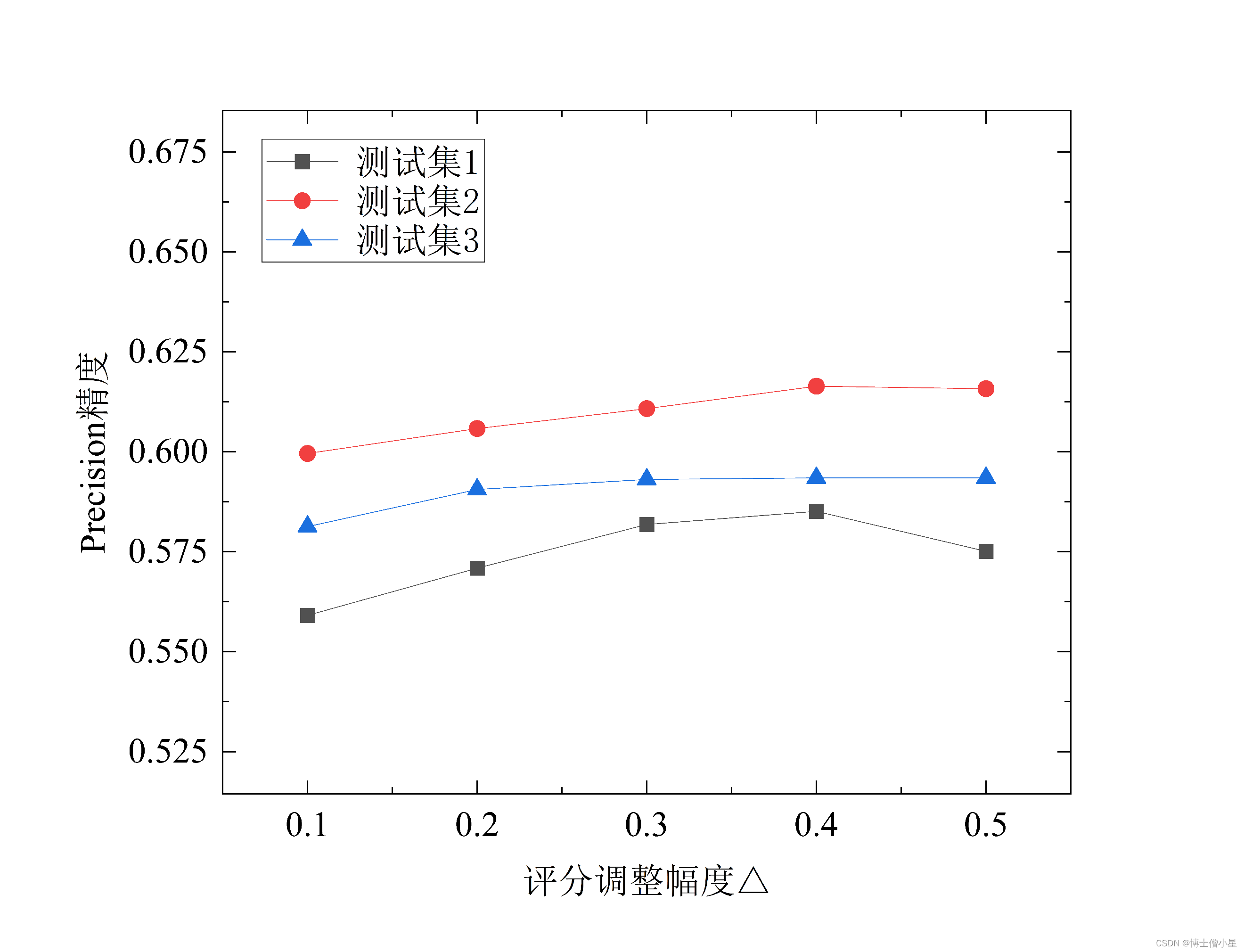
图2 不同评分调整幅度Δ对CSM-DFC-CFR算法精度影响
对于最近邻域大小|Nu|,很容易理解,最近邻数量增加会降低目标用户与邻居之间的评分相似度,如果取值过大势必会影响算法表现。参照文献[24],将所有算法最近邻域大小取值为5。此外,参照文献[25]令各算法推荐列表长度z=15。
4.3.2 不同算法性能比较
不同对照算法在三个测试集中的1折15次Precision、Recall和F-measure表现如图3[鑫1] 所示。对比U-CFR算法和CSM-DFC-CFR算法的两种变体算法(CSM-CFR和DFC-CFR)的结果发现,评论情感挖掘修正用户评分和数据场聚类方法均能提升协同过滤算法的性能,且数据场聚类的方法对算法推荐效果提升更大。此外,进一步对比CSM-DFC-CFR和它的两种变体算法,我们发现,评论情感挖掘修正用户评分和数据场聚类两种方法的结合要比任意一种方法对算法推荐性能的提升效果都要明显。对比U-CFR、KM-CFR、CKM-CFR和CSM-DFC-CFR算法,结果表明,本文所提CSM-DFC-CFR算法在三个不同评价指标上推荐性能均最佳,CKM-CFR算法次之,而KM-CFR和U-CFR算法较差。
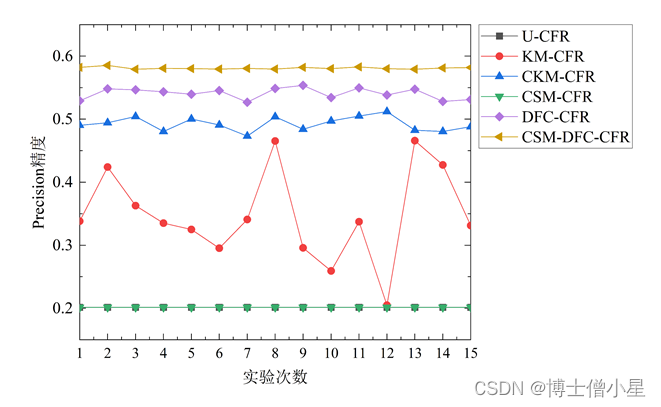
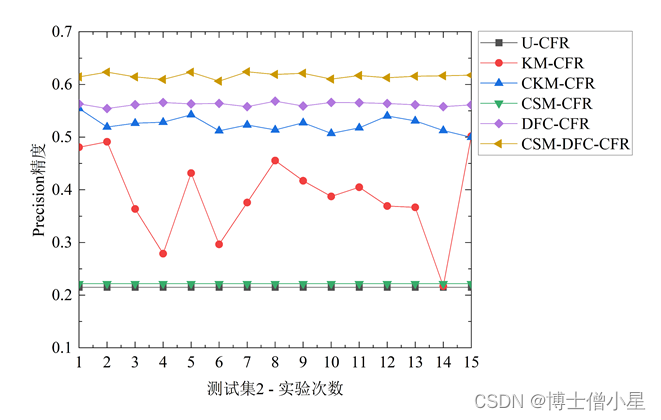


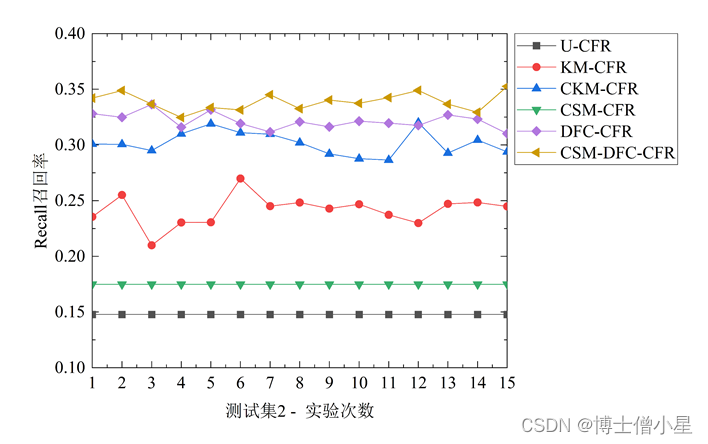
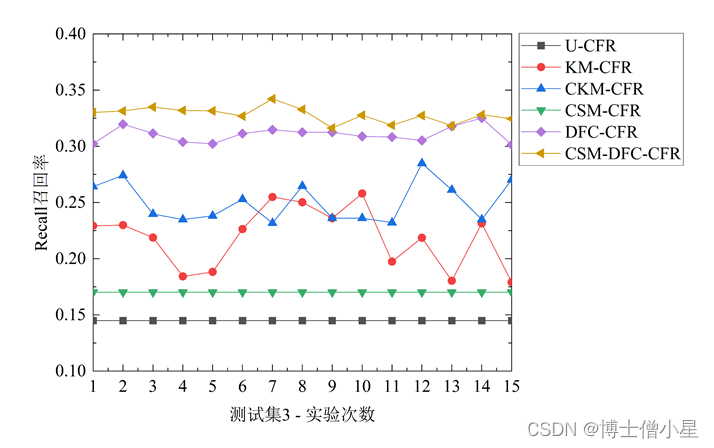
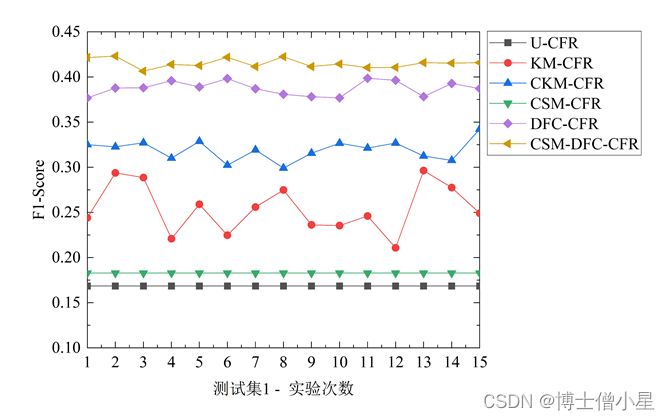
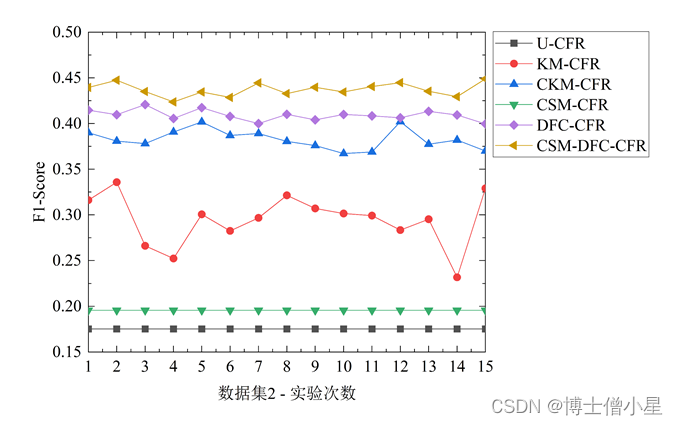
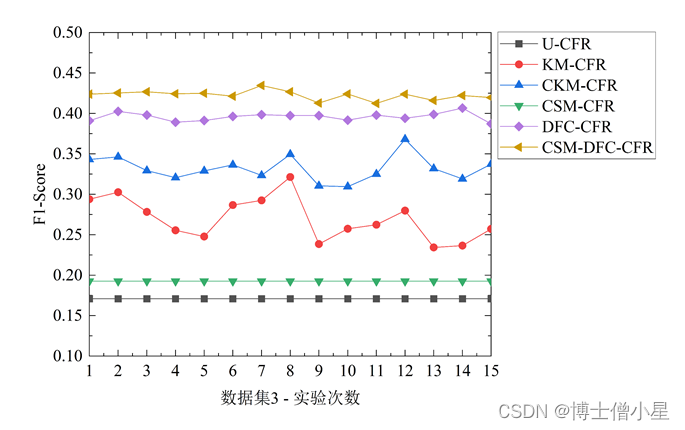
图3 不同测试集中推荐算法的性能表现
4.3.3 算法有效性分析
为充分证明本文所提算法的有效性,进一步利用Kruskal-Wallis检验方法对CSM-DFC-CFR与U-CFR、KM-CFR、CKM-CFR和CSM-CFR[鑫1] 算法的1折15次交叉验证结果进行了组间差异比较。结果(表3)表明,在P=0.05置信区间上,各测试集CSM-DFC-CFR算法的性能表现均显著优于其它对照算法 (p<.05)。还发现,尽管CSM-DFC-CFR与DFC-CFR算法在各评价指标结果之间并不存在显著组间差异,但平均而言,CSM-DFR-CFR的Precision、Recall和F1-score均优于DFC-CFR。以上结果充分证明了本文所提推荐算法的有效性,算法的优化思路与实际数据相吻合。
5 结语
针对当前DC-CFR算法存在的评分失真和区分度小以及自由参数问题,提出了一种基于评论情感挖掘和数据场聚类的协同过滤推荐算法。其中,评论情感挖掘是指利用无监督情感挖掘技术对评论整体情感进行量化,通过加权方式修正用户评分,以提升评分区分度 (细化了评分粒度),缩小评分与用户真实喜好之间的偏差。数据场聚类是指利用数据场计算最佳聚类数和最优初始聚类中心,对用户进行划分聚类,以缩小最近邻域检索范围,优化高维数据聚类表现。三个真实数据集的实验结果表明,与其它算法相比,本文所提算法在Precision、Recall和F1-Score指标上的表现均最优。
本文不足之处在于未处理虚假用户评论,即假定评论中不存在不实消费经历及对商品实体的鼓吹或诽谤[26],未来将考虑运用文体或元数据特征识别并剔除虚假评论,对本文算法进行改进。
参考文献
- [1] 向小东,黄飘,邱梓咸.基于综合相似度加权Slope One算法的协同过滤算法[J].统计与决策,2020,36(24):10-14.
- [2] Li J, Zhang K, Yang X, et al.Category preferred canopy–K-means based collaborative filtering algorithm[J]. Future Generation Computer Systems,2019,93:1046-1054.
- [3] 陈爱霞,李宁.基于极速学习机和最近邻的回归推荐算法[J].河北大学学报(自然科学版),2017,37(06):662-666.
- [4] 谢国民,张婷婷,刘明,等.基于SDAE特征表示的协同主题回归推荐模型[J].计算机工程与科学,2019,41(05):924-932.
- [5] ZENGIN ALP Z, GüNDüZ ÖĞüDüCü Ş. Identifying topical influencers on twitter based on user behavior and network topology[J]. Knowledge-Based Systems,2018,141:211-221.
- [6] Hammou B, Lahcen A, Mouline S. An effective distributed predictive model with Matrix factorization and random forest for Big Data recommendation systems[J]. Expert Systems with Applications,2019,137:253-265.
- [7] Natarajan S, Vairavasundaram S, Natarajan S, et al.Resolving data sparsity and cold start problem in collaborative filtering recommender system using Linked Open Data[J]. Expert Systems with Applications,2020,149:113248.
- [8] 王建仁,马鑫,段刚龙.改进的K-means聚类k值选择算法[J].计算机工程与应用,2019,55(08):27-33.
- [9] 马鑫,段刚龙,王建仁,等.基于改进轮廓系数法的航空公司客户分群研究[J].运筹与管理,2021,30(01):140-146.
- [10] 张文,崔杨波,李健,等.基于聚类矩阵近似的协同过滤推荐研究[J].运筹与管理,2020,29(04):171-178.
- [11] 唐泽坤,黄柄清,李廉.基于改进Canopy聚类的协同过滤推荐算法[J].计算机应用研究,2020,37(09):2615-2619+2639.
- [12] 王红霞,陈健,程艳芬.采用评论挖掘修正用户评分的改进协同过滤算法[J].浙江大学学报(工学版),2019,53(03):522-532.
- [13] Liu Q, Karahanna E. The dark side of reviews: The swaying effects of online product reviews on attribute preference construction[J]. MIS Q,2017,41(2):427-448.
- [14] Lee S, Ha T, Lee D, et al. Understanding the majority opinion formation process in online environments: an exploratory approach to Facebook[J]. Information Processing & Management,2018,54(6):1115-1128.
- [15] 马鑫,王芳.融合类目偏好和数据场聚类的协同过滤推荐算法研究[J].现代情报,2023,43(01):6-18.
- [16] Yang H, Suh Y. Sentiment analysis of online customer reviews for product recommendation: comparison with traditional cf-based recommendation[J]. Korea Management Information Society Conference,2015:801-805.
- [17] Luo R, Xu J, Zhang Y, et al.Pkuseg: A toolkit for multi-domain chinese word segmentation[J].arXiv preprint arXiv:190611455,2019.
- [18] 周清清,章成志.在线用户评论细粒度属性抽取[J].情报学报,2017,36(05):484-493.
- [19] 张乐,闫强,吕学强.面向短文本的情感折射模型[J].情报学报,2017,36(02):180-189.
- [20] 李德毅.信息安全技术的发展及其对公共安全的影响[J].计算机安全,2002(01):15-19.
- [21] 淦文燕,李德毅,王建民.一种基于数据场的层次聚类方法[J].电子学报,2006,34(02):258-262.
- [22] 熊回香,李晓敏,杜瑾.基于学术关键词与共被引的学者推荐研究[J].情报学报,2021,40(07):725-733.
- [23] Deng J, Guo J, Wang Y. A Novel k-medoids clustering recommendation algorithm based on probability distribution for collaborative filtering[J]. Knowledge-Based Systems,2019,175:96-106.
- [24] 韦素云,肖静静,业宁.基于联合聚类平滑的协同过滤算法[J].计算机研究与发展,2013,50(S2):163-169.
- [25] Afoudi Y, Lazaar M, AI Achhab M. Hybrid recommendation system combined content-based filtering and collaborative prediction using artificial neural network[J]. Simulation Modelling Practice and Theory,2021,113:102375.
- [26] 马鑫,王芳,段刚龙.面向电商内容安全风险管控的协同过滤推荐算法研究[J].情报理论与实践,2022,45(10):176-187.