目录
- Shell流程控制
- 条件测试
- 注意事项
- 示例
- [ condition ]与[[ condition ]]的区别
- if条件
- 单分支
- 语法
- 示例1:统计根分区使用率
- 示例2:创建目录
- 双分支if条件语句
- 语法
- 案例1:备份mysql数据库
- 案例2:判断apache是否启动,如果没有启动则自动启动
- 多分支if条件语句
- 语法
- 案例:判断用户输入的是什么文件
- 多分支case条件语句
- 语法
- 注意事项
- 案例
- for循环
- 语法1:
- 示例1:打印时间
- 示例2:批量解压
- 语法2:
- 示例1:1~100累加
- 示例2:批量添加指定数量的用户
- 示例3:批量删除指定数量的用户
- while循环
- 语法
- 案例1:1~100累加
- 案例2:输入的数值进行比较判断
- until循环
- 语法
- 案例:1~100累加
- 函数
- 语法
- 定义函数四种方式
- 案例:1~输入的数字进行累加
- 特殊流程控制语句(exit、break、continue)
- exit
- 语法:
- 注意:
- 示例
- break
- 示例
- continue
- 示例
- 字符截取、替换和处理命令
- 正则表达式
- 字符截取、替换命令
- cut 列提取命令
- 示例
- awk 编程
- printf 格式化输出
- 示例
- awk 基本使用
- 基本用法
- awk 的条件
- BEGIN
- END
- 关系运算符
- 正则表达式
- awk 内置变量
- awk常用统计实例
- 示例
- awk 流程控制
- 分析
- 在awk编程中,因为命令语句非常长,在输入格式时需要注意以下内容:
- awk 函数
- 语法
- awk 中调用脚本
- sed 文本选取、替换、删除、新增的命令
- 语法
- 举例:假设我想查看下student.txt的第二行,那么就可以利用“p”动作了:
- 追加行数据
- 删除行数据
- 替换行数据
- 字符串替换
- 字符处理命令
- sort 排序命令
- 示例
- uniq 取消重复行
- wc 统计命令
Shell流程控制
条件测试
三种条件测试语法
- test condition:比较时有空格
- [ condition ]:前后有空格
- [[ condition ]]:前后有空格
注意事项
- 条件非空即为true,[ aaa ]返回true,[ ]返回false。
- 0真,1假。
- 判断时需要空格
示例
[root@localhost ~]# a=hello
[root@localhost ~]# test $a = hello
[root@localhost ~]# echo $?
0
[root@localhost ~]# test $a = Hello
[root@localhost ~]# echo $?
1
[root@localhost ~]# a=Hello
[root@localhost ~]# test $a = Hello
[root@localhost ~]# echo $?
0
[root@localhost ~]#
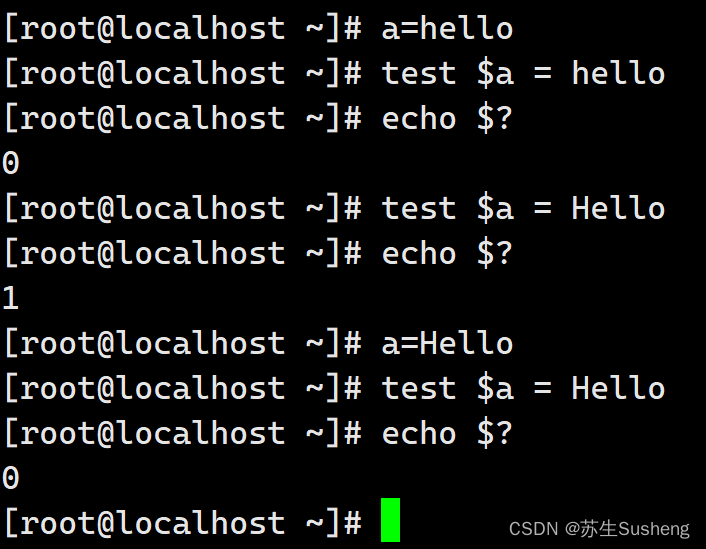
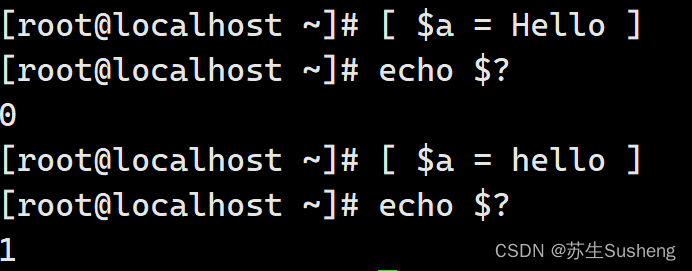
[root@localhost ~]# [ $a = Hello ]
[root@localhost ~]# echo $?
0
[root@localhost ~]# [ $a = hello ]
[root@localhost ~]# echo $?
1
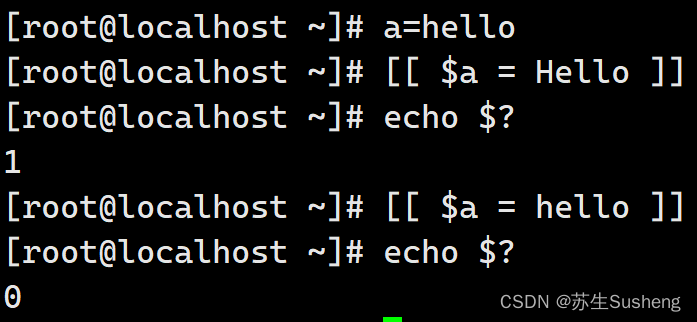
[root@localhost ~]# a=hello
[root@localhost ~]# [[ $a = Hello ]]
[root@localhost ~]# echo $?
1
[root@localhost ~]# [[ $a = hello ]]
[root@localhost ~]# echo $?
0
[ condition ]与[[ condition ]]的区别
- [ ]是符合POSIX标准的测试语句,兼容性更强,几乎可以运行在所有的Shell解释器中;[[ ]]仅可运行在特定的几个Shell解释器中(如Bash等)
- <和>在[[ ]]中用作排序,而[ ]不支持
- [ ]中使用-a和-o表示逻辑与和逻辑或,[[ ]]使用&&和||来表示
- 在[ ]中==是字符匹配,在[[ ]]中是模式匹配
- [ ]不支持正则匹配,[[ ]]支持用=~进行正则匹配
- [ ]仅在部分Shell中支持用()进行分组,[[ ]]均支持
- [ ]中如果变量没有定义,那么需用双引号引起来,[[ ]]中不需要
if条件
单分支
语法
if [ 条件判断式 ]
then
程序
fi
示例1:统计根分区使用率
[root@localhost ~]$ vim sh/if1.sh
#!/bin/bash
#统计根分区使用率
#把根分区使用率作为变量值赋予变量rate
rate=$(df -h | grep "/dev/sda2" | awk '{print $5}'| cut -d "%" -f1)
#判断rate的值如果小于等于80,则执行then程序
if [[ $rate -le 80 ]]
then
#打印信息。在实际工作中,也可以向管理员发送邮件。
echo "less 80%"
fi
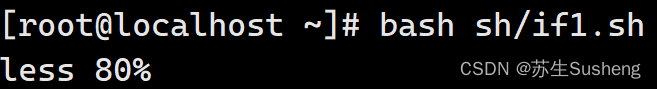
示例2:创建目录
[root@localhost ~]$ vim sh/add_dir.sh
#!/bin/bash
#创建目录,判断是否存在,存在就结束,反之创建
echo "当前脚本名称为$0"
DIR="/media/cdrom"
if [ ! -e $DIR ]
then
mkdir -p $DIR
fi
echo "$DIR 创建成功"
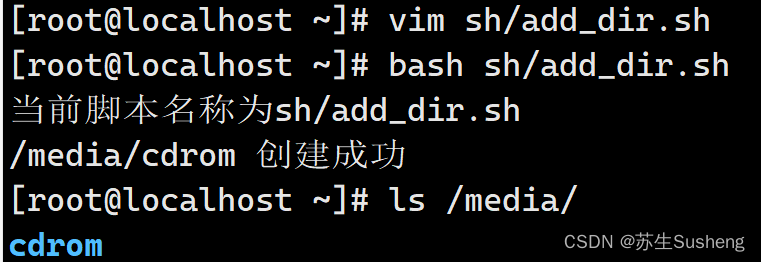
双分支if条件语句
语法
if [ 条件判断式 ]
then
条件成立时,执行的程序
else
条件不成立时,执行的另一个程序
fi
案例1:备份mysql数据库
[root@localhost ~]$ vim sh/bakmysql.sh
#!/bin/bash
#备份mysql数据库。
ntpdate asia.pool.ntp.org &>/dev/null
#同步系统时间
date=$(date +%y%m%d)
#把当前系统时间按照“年月日”格式赋子变量date
size=$(du -sh/var/lib/mysql)
#统计mysql数据库的大小,并把大小赋予size变量
if [ -d /tmp/dbbak ]
#判断备份目录是否存在,是否为目录
then
#如果判断为真,执行以下脚本
echo "Date : $date!" > /tmp/dbbak/dbinfo.txt
#把当前日期写入临时文件
echo "Data size : $size" >> /tmp/dbbak/dbinfo.txt
#把数据库大小写入临时文件
cd/tmp/dbbak
#进入备份目录
tar -zcf mysql-lib-$date.tar.gz /var/lib/mysql dbinfo.txt &> /dev/null
#打包压缩数据库与临时文件,把所有输出丢入垃圾箱(不想看到任何输出)
rm -rf /tmp/dbbak/dbinfo.txt
#删除临时文件
else
mkdir /tmp/dbbak
#如果判断为假,则建立备份目录
echo "Date : $date!" > /tmp/dbbak/dbinfo.txt
echo "Data size : $size" >> /tmp/dbbak/dbinfo.txt
#把日期和数据库大小保存如临时文件
cd /tmp/dbbak
tar -zcf mysql-lib-$date.tar. gz dbinfo.txt /var/lib/mysql &> /dev/null
#压缩备份数据库与临时文件
rm -rf/tmp/dbbak/dbinfo.txt
#删除临时文件
fi
案例2:判断apache是否启动,如果没有启动则自动启动
[root@localhost ~]$ vi sh/autostart.sh
#!/bin/bash
#判断apache是否启动,如果没有启动则自动启动
port=$(nmap -sT 192.168.4.210 | grep tcp | grep http | awk '{print $2}’)
#使用nmap命令扫描服务器,并截取 apache服务的状态,赋予变量port
#只要状态是open,就证明正常启动
if [ "$port" == "open"]
#如果变量port的值是“open”
then
echo "$(date) httpd is ok!” >> /tmp/autostart-acc.log
#则证明apache 正常启动,在正常日志中写入一句话即可
else
/etc/rc.d/init.d/httpd start &>/dev/null
#否则证明apache没有启动,自动启动apache
echo "$(date) restart httpd !!" >> /tmp/autostart-err.log
#并在错误日志中记录自动启动apche 的时间
fi
nmap端口扫描命令,格式如下:
[root@localhost ~]$ nmap -sT 域名或IP
选项:
-s 扫描
-T 扫描所有开启的TCP端口
#知道了nmap命令的用法,我们在脚本中使用的命令就是为了截取http的状态,只要状态是“or.
#就证明apache启动正常,否则证明apache启动错误。来看看脚本中命令的结果:
[root@localhost ~]$ nmap -sT 192.168.4.210 | grep tcp | grep http | awk ' fprint $2}’
#扫描指定计算机,提取包含tcp 的行,在提取包含httpd 的行,截取第二列open
#把截取的值赋予变量port
多分支if条件语句
语法
if [ 条件判断式1 ]
then
当条件判断式1成立时,执行程序1
elif [ 条件判断式2 ]
then
当条件判断式2成立时,执行程序2
…省略更多条件…
else
当所有条件都不成立时,最后执行此程序
fi
案例:判断用户输入的是什么文件
[root@localhost ~]$ vim sh/if-elif.sh
#!/bin/bash
#判断用户输入的是什么文件
read -p "请输入文件名称: " file
#接收键盘的输入,并赋予变量file
if [ -z "$file” ]
#判断file变量是否为空
then
echo "错误!文件名不能为空"
#如果为空,执行程序1,也就是输出报错信息
exit 1
#退出程序,并返回值为Ⅰ(把返回值赋予变量$P)
elif [ ! -e "$file” ]
#判断file的值是否存在
then
echo "输入的不是一个文件!"
#如1果不存在,则执行程序2
exit 2
#退出程序,把并定义返回值为2
elif [ -f "$file” ]
#判断file的值是否为普通文件
then
echo "$file 是一个普通文件!”
#如果是普通文件,则执行程序3
elif [ -d "$file” ]
#到断file的值是否为目录文件
then
echo "$file 是一个目录!"
#如果是目录文件,网执行程序4
else
echo "$file 是其他文件!”
#如果以上判断都不是,则执行程序5
fi
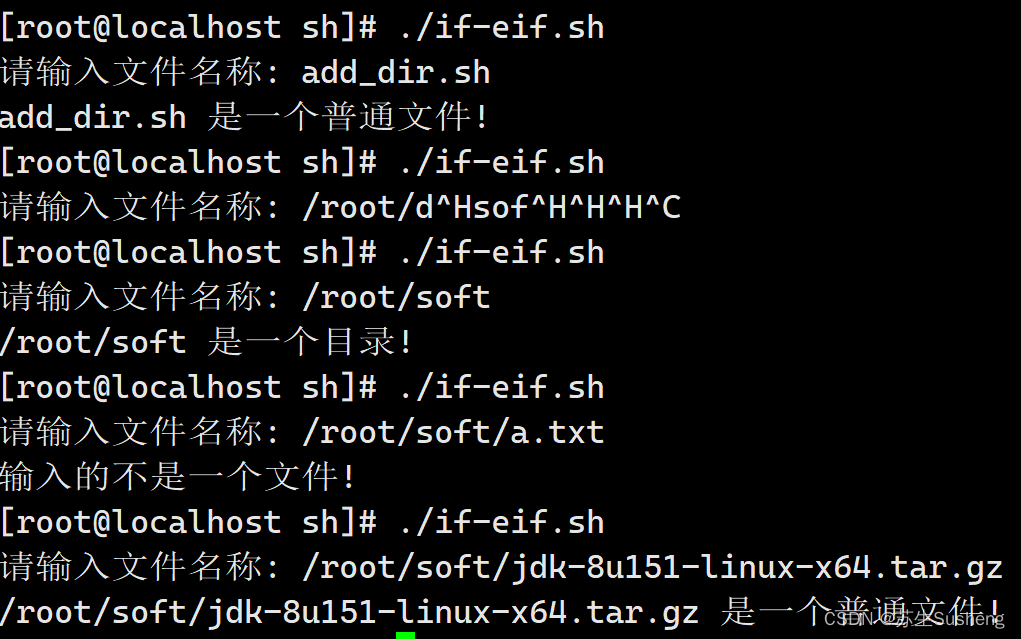
多分支case条件语句
case语句和if…elif…else语句一样都是多分支条件语句,不过和if多分支条件语句不同的是,case语句只能判断一种条件关系,而if语句可以判断多种条件关系。
语法
case $变量名 in
"值1")
如果变量的值等于值1,则执行程序1
;;
"值2")
如果变量的值等于值2,则执行程序2
::
…省略其他分支…
*)
如果变量的值都不是以上的值,则执行此程序
;;
esac
注意事项
- case语句,会取出变量中的值,然后与语句体中的值逐一比较。如果数值符合,则执行对应的程序,如果数值不符,则依次比较下一个值。如果所有的值都不符合,则执行 “*)” (*代表所有其他值)中的程序。
- case语句以“case”开头,以“esac”结尾。
- 每一个分支程序之后要通过“;;”双分号结尾,代表该程序段结束(千万不要忘记,每次写case语句,都不要忘记双分号)。
案例
[root@localhost ~]$ vim sh/if-case.sh
#!/bin/bash
read -p "请输入一个字符,并按Enter确认:" KEY
case "$KEY" in
[a-z]|[A-Z])
echo "您输入的是字母"
;;
[0-9])
echo "您输入的是数字"
;;
*)
echo "您输入的是其他字符"
;;
esac
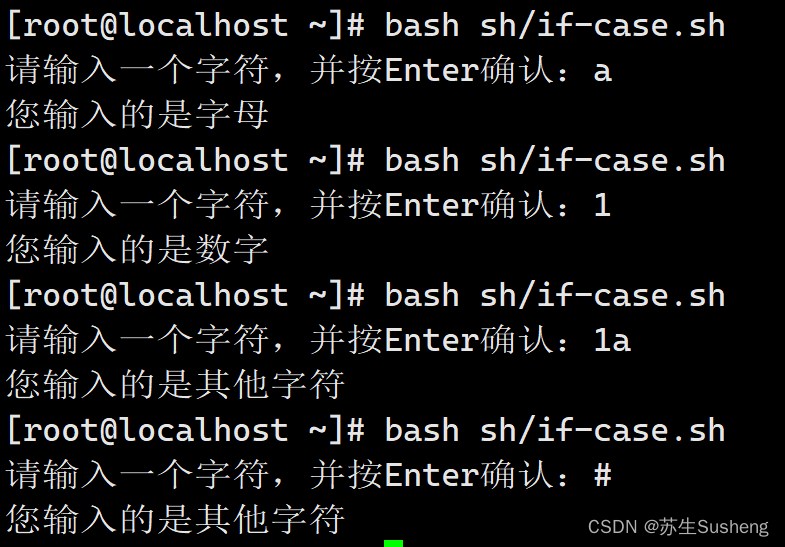
for循环
for循环是固定循环,也就是在循环时已经知道需要进行几次的循环,有时也把for循环称为计数循环。for的语法有如下两种:
语法1:
for 变量 in 值1 值2 值3 …(可以是一个文件等)
do
程序
done
这种语法中for循环的次数,取决于in后面值的个数(空格分隔),有几个值就循环几次,并且每次循环都把值赋予变量。
也就是说,假设in后面有三个值,for会循环三次,第一次循环会把值1赋予变量,第二次循环会把值2赋予变量,以此类推。
示例1:打印时间
[root@localhost ~]$ vi sh/for.sh
#!/bin/bash
#打印时间
for time in morning noon afternoon evening
do
echo "This time is $time!"
done
示例2:批量解压
[root@localhost ~]$ vi sh/auto-tar. sh
#!/bin/bash
#批量解压缩脚本
cd/lamp
#进入压缩包目录
ls *.tar.gz > ls.log
#把所有.tar.gz结尾的文件的文件覆盖到ls.log 临时文件中
for i in $(cat ls.log) `
#或者这样写for i in `cat ls.log`
#读取ls.log文件的内容,文件中有多少个值,就会循环多少次,每次循环把文件名赋予变量i
do
tar -zxf $i &>/dev/null
#加压缩,并把所有输出都丢弃
done
rm -rf /lamp/ls.log
#删除临时文件ls.log
语法2:
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done
注意:
- 初始值:在循环开始时,需要给某个变量赋予初始值,如i=1;
- 循环控制条件:用于指定变量循环的次数,如i<=100,则只要i的值小于等于100,循环就会继续;
- 变量变化:每次循环之后,变量该如何变化,如i=i+1。代表每次循环之后,变量i的值都加1。
示例1:1~100累加
[root@localhost ~]$ vi sh/add. sh
#!/bin/bash
#从1加到100
s=0
for (( i=1;i<=100;i=i+1 ))
#定义循环100 次
do
s=$(( $s+$i ))
#每次循环给变量s赋值
done
echo "The sum of 1+2+...+100 is : $s"
#输出1加到100的和
示例2:批量添加指定数量的用户
[root@localhost ~]$ vi useradd.sh
#!/bin/bash
#批量添加指定数量的用户
read -p "Please input user name: " -t 30 name
#让用户输入用户名,把输入保存入变量name
read -p "Please input the number of users: " -t 30 num
#让用户输入添加用户的数量,把输入保存入变量num
read -p "Please input the password of users: " -t 30 pass
#让用户输入初始密码,把输入保存如变量pass
if [ ! -z "$name" -a ! -z "$num"-a ! -z "$pass"]
#判断三个变量不为空
then
y=$(echo $num | sed 's/[0-9]//g')
#定义变量的值为后续命令的结果
#后续命令作用是,把变量num 的值替换为空。如果能替换为空,证明num 的值为数字
#如果不能替换为空,证明num的值为非数字。我们使用这种方法判断变量num 的值为数字
if [ -z "$y"]
#如果变量y的值为空,证明num变量是数字
then
for (( i=1 ; i<=$num; i=i+1 ))
#循环num变量指定的次数
do
/usr/sbin/useradd $name$i &>/dev/null
#添加用户,用户名为变量name 的值加变量i的数字
echo $pass | /usr/bin/passwd --stdin $name$i &>/dev/null
#给用户设定初始密码为变量pass 的值
done
fi
fi
示例3:批量删除指定数量的用户
[root@localhost ~]$ vi sh/userdel.sh
#!/bin/bash
#批量删除用户
user=$(cat /etc/passwd | grep " /bin/bash"|grep -v "root"Icut -d ":" -f 1)
#读取用户信息文件,提取可以登录用户,取消root用户,截取第一列用户名
for i in $user
#循环,有多少个普通用户,循环多少次
do
userdel -r $i
#每次循环,删除指定普通用户
done
while循环
对while循环来讲,只要条件判断式成立,循环就会一直继续,直到条件判断式不成立,循环才会停止。
语法
while [ 条件判断式 ]
do
程序
done
案例1:1~100累加
[root@localhost ~]$ vi sh/addnum.sh
#!/bin/bash
#从1加到100
i=1
s=0
#给变量i和变量s赋值
while [ $i -le 100 ]
#如果变量i的值小于等于100,则执行循环
do
s=$(( $s+$i ))
i=$(( $i+1 ))
done
echo "The sum is: $s"
案例2:输入的数值进行比较判断
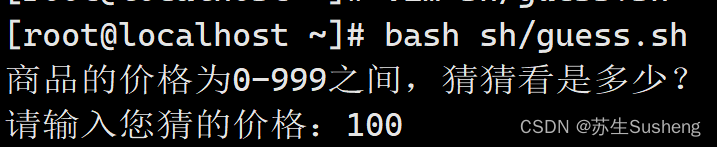
[root@localhost ~]$ vi sh/guess.sh
#!/bin/bash
PRICE=$(expr $RANDOM % 1000)
TIMES=0
echo "商品的价格为0-999之间,猜猜看是多少?"
while true
do
read -p "请输入您猜的价格:" INT
let TIMES++
if [ $INT -eq $PRICE ] ; then
echo "恭喜您猜对了,实际价格是 $PRICE"
echo "您总共猜了 $TIMES 次"
exit 0
elif [ $INT -gt $PRICE ] ; then
echo "太高了"
else
echo "太低了"
fi
done

until循环
和while循环相反,until循环时只要条件判断式不成立则进行循环,并执行循环程序。一旦循环条件成立,则终止循环。
语法
until [ 条件判断式 ]
do
程序
done
案例:1~100累加
[root@localhost ~]$ vi sh/until.sh
#!/bin/bash
#从1加到100
i=1
s=0
#t给变量i和变量s赋值
until [ $i -gt 100 ]
#循环直到变量i的值大于100,就停止循环
do
s=$(( $s+$i ))
i=$(( $i+1 ))
done
echo "The sum is: $s"
函数
语法
function 函数名 () {
程序
}
定义函数四种方式
function funname()
{
函数体
}
funname()
{
函数体
}
function funname()
{
函数体
return n
}
funname()
{
函数体
return n
}
案例:1~输入的数字进行累加
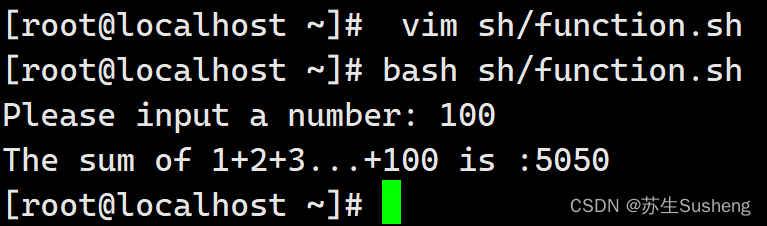
[root@localhost ~]$ vim sh/function.sh
#!/bin/bash
#接收用户输入的数字,然后从1加到这个数字
function sum () {
#定义函数sum
s=0
for (( i=0; i<=$num;i=i+1 ))
#循环直到i大于$1为止。$1是函数sum 的第一个参数
#在函数中也可以使用位置参数变量,不过这里的$1指的是函数的第一个参数
do
s=$(( $i+$s ))
done
echo "The sum of 1+2+3...+$1 is :$s"
#输出1加到$1的和
}
read -p "Please input a number: " -t 30 num
#接收用户输入的数字,并把值赋予变量num
y=$(echo $num | sed 's/[0-9]//g')
#把变量num的值替换为空,并赋予变量y
if [ -z "$y"]
#判断变量y是否为空,以确定变量num中是否为数字
then
sum $num
#调用sum函数,并把变量num的值作为第一个参数传递给sum函数
else
echo "Error!! Please input a number!"
#如果变量num 的值不是数字,则输出报错信息
fi
特殊流程控制语句(exit、break、continue)
exit
系统是有exit命令的,用于退出当前用户的登录状态。可是在Shell脚本中,exit语句是用来退出当前脚本的。也就是说,在Shell脚本中,只要碰到了exit语句,后续的程序就不再执行,而直接退出脚本。
语法:
exit [返回值]
注意:
- 如果exit命令之后定义了返回值,那么这个脚本执行之后的返回值就是我们自己定义的返回值。可以通过查询$?这个变量,来查看返回值。
- 如果exit之后没有定义返回值,脚本执行之后的返回值是执行exit 语句之前,最后执行的一条命令的返回值。
示例
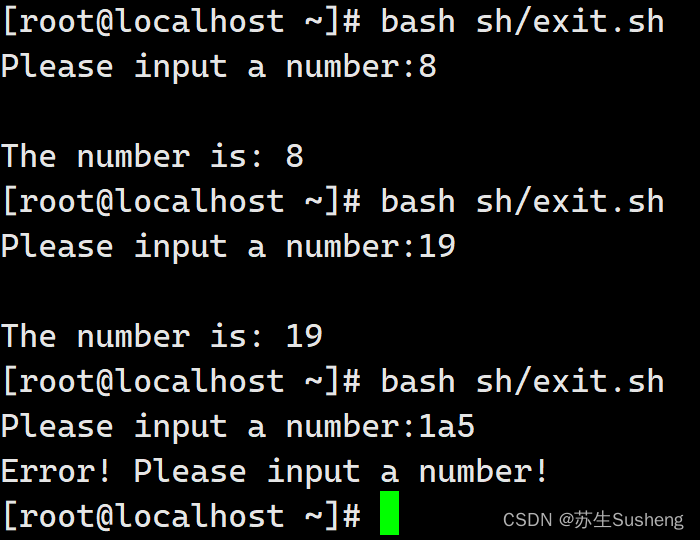
[root@localhost ~]$ vim sh/exit.sh
#!/bin/bash
#演示exit的作用
read -p "Please input a number:" -t 30 num
#接收用户的输入,并把输入赋予变量num
y=$(echo $num|sed 's/[0-9]//g')
#如果变量num的值是数字,则把num的值替换为空;否则不替换
#把替换之后的值赋予变量y
[ -n "$y" ] && echo "Error! Please input a number!" && exit 18
#判断变量y的值,如果不为空,则输出报错信息,退出脚本,>退出返回值为18
echo "The number is: $num"
#如果没有退出脚本,则打印变量num中的数字
break
当程序执行到break语句时,会结束整个当前循环。而continue 语句也是结束循环的语句,不过continue 语句单次当前循环,而下次循环会继续。
示例
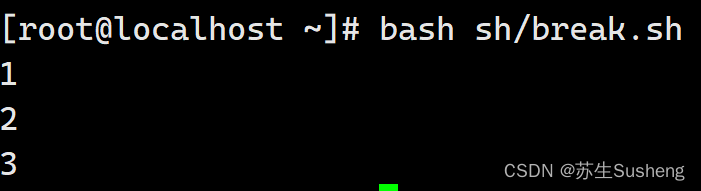
[root@localhost ~]$ vim sh/break.sh
#!/bin/bash
#演示break 跳出循环
for (( i=1;i<=10; i=i+1 ))
#循环十次
do
if ["$i" -eq 4 ]
#如果变量i的值等于4
then
break
#退出整个循环
fi
echo $i
#输出变量i的值
done
continue
continue也是结束流程控制的语句。如果在循环中,continue语句只会结束单次当前循环。
示例
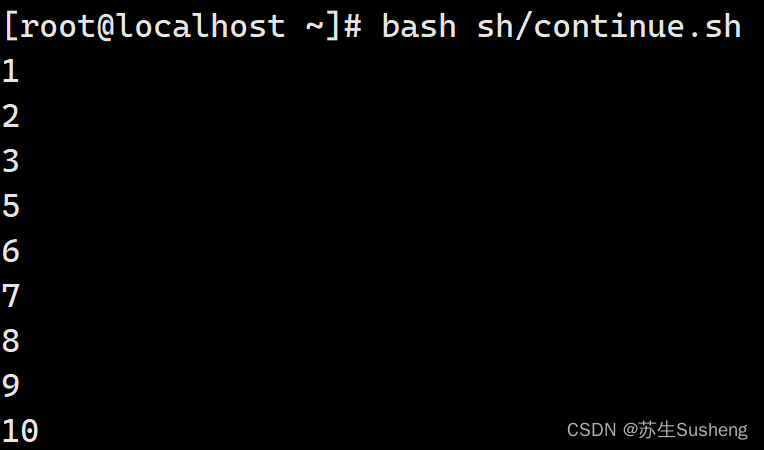
[root@localhost ~]$ vim sh/continue.sh
#!/bin/bash
#演示continue
for (( i=1;i<=10;i=i+1 ))
#循环十次
do
if ["$i" -eq 4 ]
#如果变量i的值等于4
then
continue
#退出换成continue
fi
echo $i
#输出变量i的值
done
字符截取、替换和处理命令
正则表达式
| 元字符 | 描述 | 示例 |
|---|---|---|
| \ | 转义符,将特殊字符进行转义,忽略其特殊意义 | a.b匹配a.b,但不能匹配ajb,.被转义为特殊意义 |
| ^ | 匹配行首,awk中,^则是匹配字符串的开始 | ^tux匹配以tux开头的行 |
| $ | 匹配行尾,awk中,$则是匹配字符串的结尾 | tux$匹配以tux结尾的行 |
| . | 匹配除换行符\n之外的任意单个字符 | ab.匹配abc或abd,不可匹配abcd或abde,只能匹配单字符 |
| [ ] | 匹配包含在[字符]之中的任意一个字符 | coo[kl]可以匹配cook或cool |
| [^] | 匹配[^字符]之外的任意一个字符 | 123[^45]不可以匹配1234或1235,1236、1237都可以 |
| [-] | 匹配[]中指定范围内的任意一个字符,要写成递增 | [0-9]可以匹配1、2或3等其中任意一个数字 |
| ? | 匹配之前的项1次或者0次 | colou?r可以匹配color或者colour,不能匹配colouur |
-
| 匹配之前的项1次或者多次 | sa-6+匹配sa-6、sa-666,不能匹配sa-
-
| 匹配之前的项0次或者多次| co*l匹配cl、col、cool、coool等
-
() | 匹配表达式,创建一个用于匹配的子串 | ma(tri)?匹配max或maxtrix
-
{n} | 匹配之前的项n次,n是可以为0的正整数 |[0-9]{3}匹配任意一个三位数,可以扩展为[0-9][0-9][0-9]
-
{n,}| 之前的项至少需要匹配n次 | [0-9]{2,}匹配任意一个两位数或更多位数不支持{n,}{n,}{n,}
-
{n,m}| 指定之前的项至少匹配n次,最多匹配m次,n<=m | [0-9]{2,5}匹配从两位数到五位数之间的任意一个数字
-
|| 交替匹配|两边的任意一项 | ab(c|d)匹配abc或abd
字符截取、替换命令
cut 列提取命令
[root@localhost ~]$ cut [选项] 文件名
选项:
-f 列号: 提取第几列
-d 分隔符: 按照指定分隔符分割列
-n 取消分割多字节字符
-c 字符范围: 不依赖分隔符来区分列,而是通过字符范围(行首为0)来进行字段提取。“n-”表示从第n个字符到行尾;“n-m”从第n个字符到第m个字符;“一m”表示从第1个字符到第m个字符。
--complement 补足被选择的字节、字符或字段
--out-delimiter 指定输出内容是的字段分割符
cut命令的默认分隔符是制表符,也就是“tab”键,不过对空格符可是支持的不怎么好啊
示例
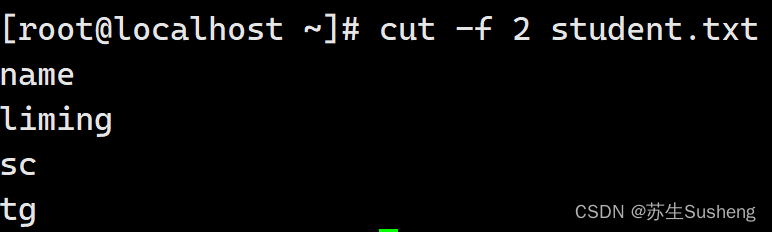
[root@localhost ~]$ vim student.txt
id name gender mark
1 liming m 86
2 sc m 67
3 tg n 90
[root@localhost ~]$ cut -f 2 student.txt
#提取第二列内容
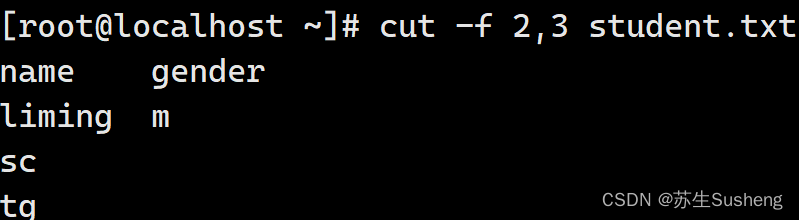
 提取多列需要列号直接用“,”分开,命令如下:
提取多列需要列号直接用“,”分开,命令如下:
[root@localhost ~]$ cut -f 2,3 student.txt
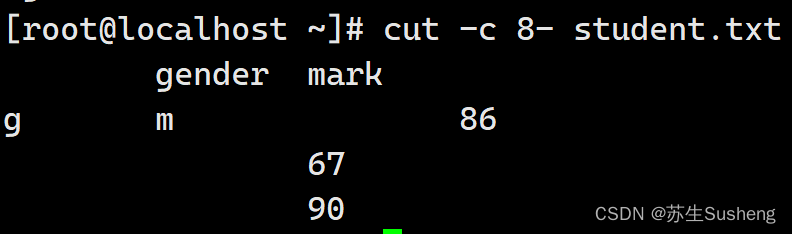
 cut可以按照字符进行提取,需要注意“8-”代表的是提取所有行的第十个字符开始到行尾,而“10-20”代表提取所有行的第十个字符到第二十个字符,而“-8”代表提取所有行从行首到第八个字符:
cut可以按照字符进行提取,需要注意“8-”代表的是提取所有行的第十个字符开始到行尾,而“10-20”代表提取所有行的第十个字符到第二十个字符,而“-8”代表提取所有行从行首到第八个字符:
[root@localhost ~]$ cut -c 8- student.txt
#提取第八个字符开始到行尾,好像很乱啊,那是因为每行的字符个数不相等啊
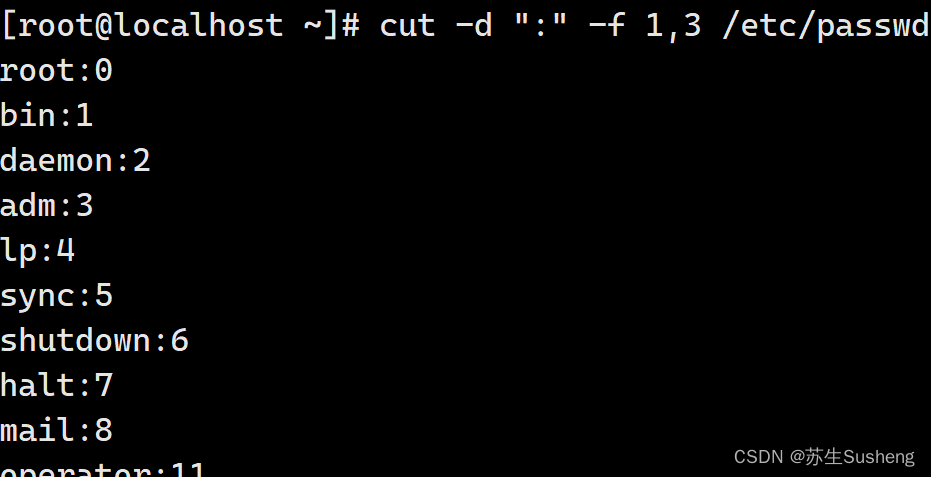
[root@localhost ~]$ cut -d ":" -f 1,3 /etc/passwd
#以“:”作为分隔符,提取/etc/passwd_文件的第一列和第三列
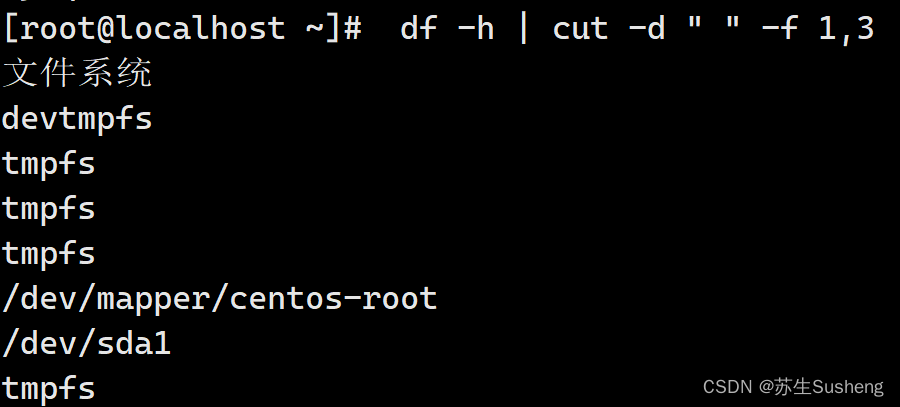
 如果我想用cut命令截取df命令的第一列和第三列,就会出现这样的情况:
如果我想用cut命令截取df命令的第一列和第三列,就会出现这样的情况:
[root@localhost~]$ df -h | cut -d " " -f 1,3
awk 编程
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
printf 格式化输出
[root@localhost ~]$ printf ‘输出类型输出格式’ 输出内容
输出类型:
%c: ASCII字符.显示相对应参数的第一个字符
%-ns: 输出字符串,减号“-”表示左对齐(默认右对齐),n是数字指代输出几个字符,几个参数就写几个%-ns
%-ni: 输出整数,n是数字指代输出几个数字
%f: 输出小数点右边的位数
%m.nf: 输出浮点数,m和n是数字,指代输出的整数位数和小数位数。如%8.2f代表共输出8位数,其中2位是小数,6位是整数。
输出格式:
\a: 输出警告声音
\b: 输出退格键,也就是Backspace键
\f: 清除屏幕
\n: 换行
\r: 回车,也就是Enter键
\t: 水平输出退格键,也就是Tab 键
\v: 垂直输出退格键,也就是Tab 键
示例
需要修改下刚刚cut命令使用的student.txt文件,文件内容如下:
[root@localhost ~]$ vim student.txt
ID Name php Linux MySQL Average
1 AAA 66 66 66 66
2 BBB 77 77 77 77
3 CCC 88 88 88 88
#printf格式输出文件
[root@localhost ~]$ printf '%s\t %s\t %s\t %s\t %s\t %s\t \n' $(cat student.txt)
#%s分别对应后面的参数,6列就写6个
 如果不想把成绩当成字符串输出,而是按照整型和浮点型输出,则要这样:
如果不想把成绩当成字符串输出,而是按照整型和浮点型输出,则要这样:
printf '%i\t %s\t %i\t %i\t %i\t %8.2f\t \n' \ $(cat student.txt | grep -v Name)

awk 基本使用
[root@localhost ~]$ awk‘条件1{动作1} 条件2{动作2}…’ 文件名
条件(Pattern):
一般使用关系表达式作为条件。这些关系表达式非常多,例如:
x > 10 判断变量x是否大于10
x == y 判断变量x是否等于变量y
A ~ B 判断字符串A中是否包含能匹配B表达式的子字符串
A !~ B 判断字符串A中是否不包含能匹配B表达式的子字符串
动作(Action) :
格式化输出
流程控制语句
常用参数:
-F 指定输入时用到的字段分隔符
-v 自定义变量
-f 从脚本中读取awk命令
-m 对val值设置内在限制
基本用法
[root@localhost ~]$ awk '{printf $2 "\t" $6 "\n"}' student.txt
#输出第二列和第六列

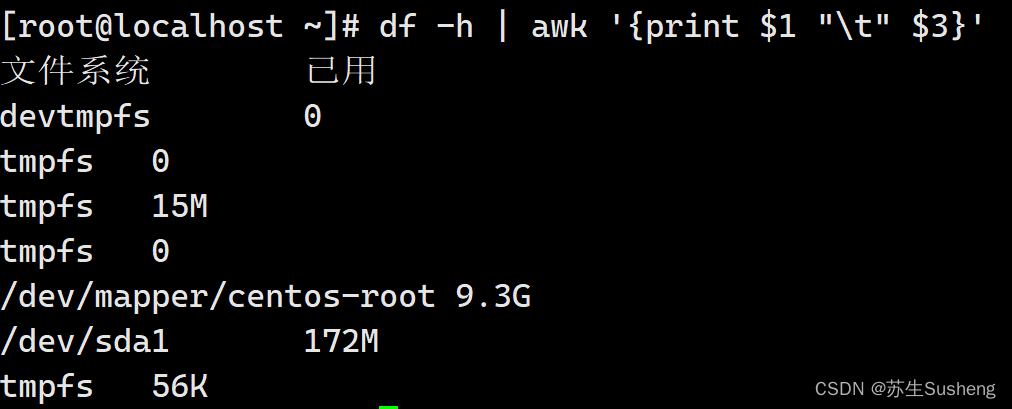
比如刚刚截取df命令的结果时,cut命令已经力不从心了,我们来看看awk命令:
[root@localhost ~]$ df -h | awk '{print $1 "\t" $3}'
#截取df命令的第一列和第三列
awk 的条件
| 条件的类型 | 条件 | 说明 |
|---|---|---|
| awk保留字 | BEGIN | 在awk程序一开始时,尚未读取任何数据之前执行。BEGIN后的动作只在程序开始时执行一次 |
| awk保留字 | END | 在awk程序处理完所有数据,即将结束时执行。END后的动作只在程序结束时执行一次 |
| 关系运算符 | > | 大于 |
| 关系运算符 | < | 小于 |
| 关系运算符 | >= | 大于等于 |
| 关系运算符 | <= | 小于等于 |
| 关系运算符 | == | 等于。用于判断两个值是否相等,如果是给变量赋值,请使用“”号 |
| 关系运算符 | != | 不等于 |
| 关系运算符 | A~B | 判断字符串A中是否包含能匹配B表达式的子字符串 |
| 关系运算符 | A!~B | 判断字符串A中是否不包含能匹配B表达式的子字符串 |
| 正则表达式 | /正则/ | 如果在"//"中可以写入字符,也可以支持正则表达式 |
BEGIN
BEGIN是awk的保留字,是一种特殊的条件类型。BEGIN的执行时机是“在 awk程序一开始时,尚未读取任何数据之前执行”。一旦BEGIN后的动作执行一次,当awk开始从文件中读入数据,BEGIN的条件就不再成立,所以BEGIN定义的动作只能被执行一次。
例如:
[root@localhost ~]$ awk 'BEGIN{printf "This is a transcript \n" } {printf $2 "\t" $6 "\n"}' student.txt
#awk命令只要检测不到完整的单引号不会执行,所以这个命令的换行不用加入“|”,就是一行命令
#这里定义了两个动作
#第一个动作使用BEGIN条件,所以会在读入文件数据前打印“这是一张成绩单”(只会执行一次)
#第二个动作会打印文件的第二字段和第六字段

END
END也是awk保留字,不过刚好和BEGIN相反。END是在awk程序处理完所有数据,即将结束时执行。END后的动作只在程序结束时执行一次。例如:
[root@localhost ~]$ awk 'END{printf "The End \n"} {printf $2 "\t" $6 "\n"}' student.txt
#在输出结尾输入“The End”,这并不是文档本身的内容,而且只会执行一次

关系运算符
假设我想看看平均成绩大于等于87分的学员是谁,就可以这样输入命令:
[root@localhost ~]$ cat student.txt | grep -v Name | awk '$6 >= 87 {printf $2 "\n"}'
#使用cat输出文件内容,用grep取反包含“Name”的行
#判断第六字段(平均成绩)大于等于87分的行,如果判断式成立,则打第六列(学员名$2)

加入了条件之后,只有条件成立动作才会执行,如果条件不满足,则动作则不运行。通过这个实验,大家可以发现,虽然awk是列提取命令,但是也要按行来读入的。这个命令的执行过程是这样的:
- 1)如果有BEGIN条件,则先执行BEGIN定义的动作。
- 2)如果没有BEGIN条件,则读入第一行,把第一行的数据依次赋予$0、$1、$2等变量。其中$0代表此行的整体数据,$1代表第一字段,$2代表第二字段。
- 3)依据条件类型判断动作是否执行。如果条件符合,则执行动作,否则读入下一行数据。如果没有条件,则每行都执行动作。
- 4)读入下一行数据,重复执行以上步骤。
如果想看看AAA用户的平均成绩呢:
[root@localhost ~]$ awk '$2 ~ /AAA/ {printf $6 "\n"}' student.txt
#如果第二字段中输入包含有“AAA”字符,则打印第六字段数据
 这里要注意在awk中,使用“//”包含的字符串,awk命令才会查找。也就是说字符串必须用“//”包含,awk命令才能正确识别。
这里要注意在awk中,使用“//”包含的字符串,awk命令才会查找。也就是说字符串必须用“//”包含,awk命令才能正确识别。
正则表达式
如果要想让awk 识别字符串,必须使用“//”包含,例如:
[root@localhost ~]$ awk '/BBB/ {print}' student.txt
#打印BBB的成绩

awk 内置变量
| awk内置变量 | 作用 |
|---|---|
| $0 | 代表目前awk所读入的整行数据。我们已知awk是一行一行读入数据的,$0就代表当前读入行的整行数据。 |
| $n | 代表目前读入行的第n个字段。比如,$1表示第1个字段(列),$2表示第2个字段(列),如此类推 |
| NF | 当前行拥有的字段(列)总数。 |
| NR | 当前awk所处理的行,是总数据的第几行。 |
| FS | 用户定义分隔符。awk的默认分隔符是任何空格,如果想要使用其他分隔符(如“:”),就需要FS变量定义。 |
| ARGC | 命令行参数个数。 |
| ARGV | 命令行参数数组。 |
| FNR | 当前文件中的当前记录数(对输入文件起始为1)。 |
| OFMT | 数值的输出格式(默认为%.6g)。 |
| OFS | 输出字段的分隔符(默认为空格)。 |
| ORS | 输出记录分隔符(默认为换行符)。 |
| RS | 输入记录分隔符(默认为换行符)。 |
awk常用统计实例
1、打印文件的第一列(域) :
awk '{print $1}' filename
2、打印文件的前两列(域) :
awk '{print $1,$2}' filename
3、打印完第一列,然后打印第二列 :
awk '{print $1 $2}' filename
4、打印文本文件的总行数 :
awk 'END{print NR}' filename
5、打印文本第一行 :
awk 'NR==1{print}' filename
6、打印文本第二行第一列 :
sed -n "2, 1p" filename | awk 'print $1'
1. 获取第一列
ps -aux | grep watchdog | awk '{print $1}'
#root
#root
#root
2. 获取第一列,第二列,第三列
ps -aux | grep watchdog | awk '{print $1, $2, $3}'
3. 获取第一行的第一列,第二列,第三列
ps -aux | grep watchdog | awk 'NR==1{print $1, $2, $3}'
4. 获取行数NR
df -h | awk 'END{print NR}'
5. 获取列数NF(这里是获取最后一行的列数,注意每行的列数可能是不同的)
ps -aux | grep watchdog | awk 'END{print NF}'
6. 获取最后一列
ps -aux | grep watchdog | awk '{print $NF}'
7. 对文件进行操作
awk '{print $1}' fileName
8. 指定分隔符(这里以:分割)
ps -aux | grep watchdog |awk -F':' '{print $1}'
9. 超出范围不报错
ps -aux | grep watchdog | awk '{print $100}'

示例
[root@localhost ~]$ cat /etc/passwd | grep "/bin/bash" | awk '{FS=":"} {printf $1 "\t" $3 "\n"}'
#查询可以登录的用户的用户名和UID

这里“:”分隔符生效了,可是第一行却没有起作用,原来我们忘记了“BEGIN”条件,那么再来试试;
[root@localhost ~]$ cat /etc/passwd | grep "/bin/bash" | awk 'BEGIN {FS=":"} {printf $1 "\t" $3 "\n"}'
 如果我只想看看sshd这个伪用户的相关信息,则可以这样使用:
如果我只想看看sshd这个伪用户的相关信息,则可以这样使用:
[root@localhost ~]$ cat /etc/passwd | awk 'BEGIN {FS=":"} $1=="sshd" {printf $1 "\t" $3 "\t 行号:" NR "\t 字段数:" NF "\n"}'
#可以看到sshd 伪用户的UID是74,是/etc/passwd_文件的第28行,此行有7个字段

awk 流程控制
先来看看该如何在awk中定义变量与调用变量的值。假设我想统计PHP成绩的总分,那么就应该这样
[root@localhost ~]$ awk 'NR==2 {php1=$3}
NR==3 {php2=$3}
NR==4 {php3=$3;totle=phpl+php2+php3;print "totle php is " totle}' student.txt
#统计PHIP成绩的总分

分析
- “NR== 2 {iphp1=$3}” (条件是NR==2,动作是php1=$3) 这句话是指如果输入数据是第二行(第一行是标题行),就把第二行的第三字段的值赋予变量“php1”。
- “NR==3 {php2=$3}" 这句话是指如果输入数据是第三行,就把第三行的第三字段的值赋予变量“php2”。
- “NR==4 {php3=$3;totle=phpl+php2+php3;print “totle php is " totle}”(“NR ==4”是条件,后面(中的都是动作)这句话是指如果输入数据是第四行﹐就把第四行的第三字段的值赋予变量"php3”;然后定义变量totle的值是“php1+php2+php3”;然后输出“totle php is”关键字,后面加变量totle的值。
在awk编程中,因为命令语句非常长,在输入格式时需要注意以下内容:
多个条件 {动作} 可以用空格分割,也可以用回车分割。
在一个动作中,如果需要执行多个命令,需要用 “;” 分割,或用回车分割。
在awk中,变量的赋值与调用都不需要加入“$”符。
条件中判断两个值是否相同,请使用 “==”,以便和变量赋值进行区分。
在看看该如何实现流程控制,假设如果Linux成绩大于80,就是一个好男人:
[root@localhost ~]$ awk '{if (NR>=2) {if ($4>80) printf $2 "is a good man!\n"}}' student.txt
#程序中有两个if判断,第一个判断行号大于2,第二个判断Linux成绩大于80分

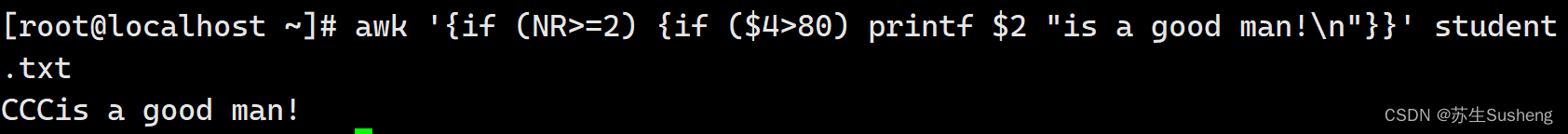 其实在 awk中 if判断语句,完全可以直接利用awk自带的条件来取代,刚刚的脚本可以改写成这样:
其实在 awk中 if判断语句,完全可以直接利用awk自带的条件来取代,刚刚的脚本可以改写成这样:
[root@localhost ~]$ awk 'NR>=2 {test=$4} test>80 {printf $2 "is a good man! \n"}' student.txt
#先判断行号如果大于2,就把第四字段赋予变量test
#在判断如果test的值大于80分,就打印好男人
awk 函数
awk编程也允许在编程时使用函数,我们讲讲awk的自定义函数。
语法
function 函数名(参数列表){
函数体
}
我们定义一个简单的函数,使用函数来打印student.txt的学员姓名和平均成绩,应该这样来写函数:
[root@localhost ~]$ awk 'function test(a,b) { printf a "\t" b "\n"} { test($2,$6) } ' student.txt
#awk 'function test(a,b) { printf a "\t" b "\n"}:定义函数test,包含两个参数,函数体的内容是输出这两个参数的值
#其中{ test($2,$6) } ' student.txt:调用函数test,并向两个参数传递值。

awk 中调用脚本
对于小的单行程序来说,将脚本作为命令行自变量传递给awk是非常简单的,而对于多行程序就比较难处理。当程序是多行的时候,使用外部脚本是很适合的。首先在外部文件中写好脚本,然后可以使用awk的-f选项,使其读入脚本并且执行。
例如,我们可以先编写一个awk脚本:
[root@localhost ~]$ vi pass.awk
BEGIN {FS=":"}
{ print $1 "\t" $3}
然后可以使用“一f”选项来调用这个脚本:
[root@localhost ~]$ awk -f pass.awk /etc/passwd
rooto
bin1
daemon2
…省略部分输出…
sed 文本选取、替换、删除、新增的命令
sed主要是用来将数据进行选取、替换、删除、新增的命令。
语法
[root@localhost ~]$ sed [选项] ‘[动作]’ 文件名
选项:
-n: 一般sed命令会把所有数据都输出到屏幕,如果加入此选择,则只会把经过sed命令处理的行输出到屏幕。
-e: 允许对输入数据应用多条sed命令编辑。
-f 脚本文件名: 从sed脚本中读入sed操作。和awk命令的-f非常类似。
-r: 在sed中支持扩展正则表达式。
-i: 用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出
动作:
num a \: 追加,在当前行后添加一行或多行。添加多行时,除最后一行外,每行末尾需要用“\”代表数据未完结。num表示第几行
c \: 行替换,用c后面的字符串替换原数据行,替换多行时,除最后一行外,每行末尾需用“”代表数据未完结。
num i \: 插入,在当期行前插入一行或多行。插入多行时,除最后一行外,每行末尾需要用“”代表数据未完结。num表示第几行
d ; 删除,删除指定的行。
p : 打印,输出指定的行。
s : 字串替换,用一个字符串替换另外一个字符串。格式为“行范围s/"旧字串/新字串/g”(和vim中的替换格式类似)。
对sed命令,sed所做的修改并不会直接改变文件的内容(如果是用管道符接收的命令的输出,这种情况连文件都没有),而是把修改结果只显示到屏幕上,除非使用“-i”选项才会直接修改文件。
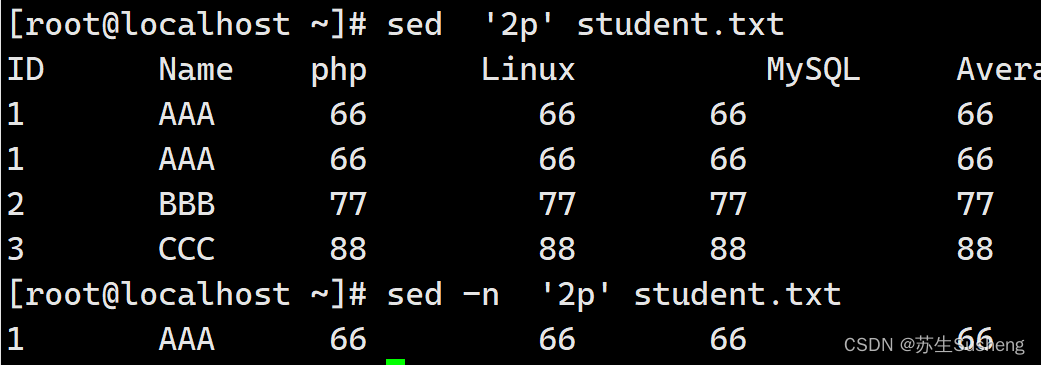
举例:假设我想查看下student.txt的第二行,那么就可以利用“p”动作了:
[root@localhost ~]$ sed '2p' student.txt
指定输出某行,使用-n选项
[root@localhost ~]$ sed -n '2p' student.txt
1 AAA 66 66 66 66
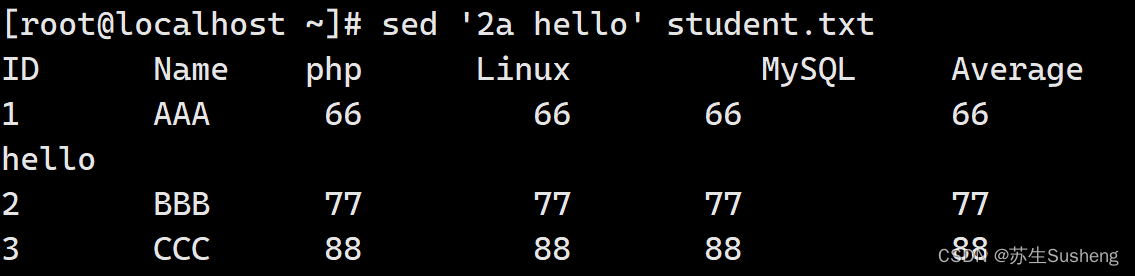
追加行数据
[root@localhost ~]$ sed '2a hello' student.txt
#在第二行后加入 hello
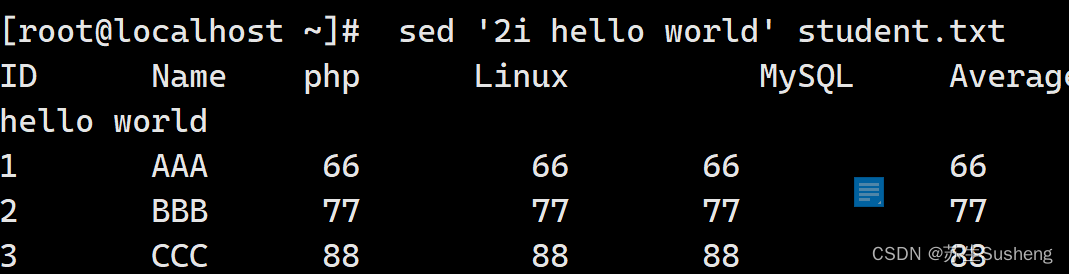
 “a”会在指定行后面追加入数据,如果想要在指定行前面插入数据,则需要使用“i”动作:
“a”会在指定行后面追加入数据,如果想要在指定行前面插入数据,则需要使用“i”动作:
[root@localhost ~]$ sed '2i hello world' student.txt
#在第二行前插入两行数据
如果是想追加或插入多行数据,除最后一行外,每行的末尾都要加入“\”代表数据未完结。再来看看“-n”选项的作用:
[root@localhost ~]$ sed -n '2i hello world' student.txt
#只查看sed命令操作的数据

删除行数据
[root@localhost ~]$ sed '2,4d' student.txt
#删除第二行到第四行数据

替换行数据
“-n”只查看sed命令操作的数据,而不是查看所有数据。
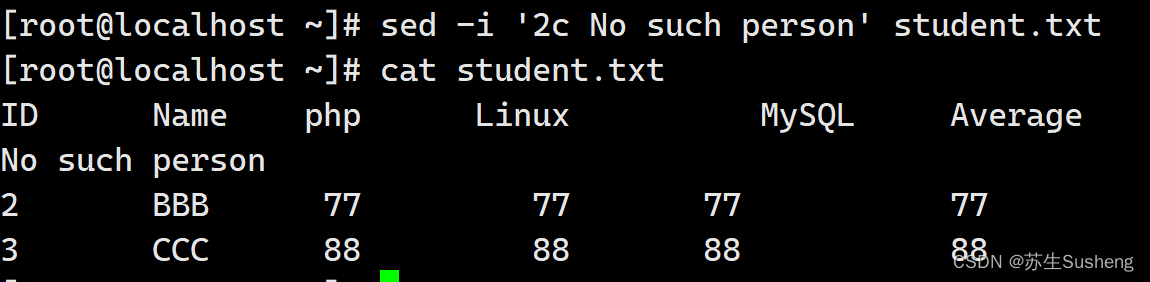
再来看看如何实现行数据替换,假设AAA的成绩太好了,我实在是不想看到他的成绩刺激我,那就可以使用"c"动作:
[root@localhost ~]$ cat student.txt | sed '2c No such person'
 sed命令默认情况是不会修改文件内容的,如果我确定需要让 sed命令直接处理文件的内容,可以使用“-i”选项。不过要小心啊,这样非常容易误操作,在操作系统文件时请小心谨慎。可以使用
sed命令默认情况是不会修改文件内容的,如果我确定需要让 sed命令直接处理文件的内容,可以使用“-i”选项。不过要小心啊,这样非常容易误操作,在操作系统文件时请小心谨慎。可以使用
这样的命令:
[root@localhost ~]$ sed -i '2c No such person' student.txt
字符串替换
“c”动作是进行整行替换的,如果仅仅想替换行中的部分数据,就要使用“s”动作了。g 使得 sed 对文件中所有符合的字符串都被替换, 修改后内容会到标准输出,不会修改原文件。
[root@localhost ~]$ sed 's/旧字串/新字串/g' 文件名
[root@localhost ~]$ sed '行范围s/旧字串/新字串/g' 文件名
替换的格式和vim非常类似,假设我觉得我自己的PHP成绩太低了,想作弊给他改高点,就可以这样来做:
[root@localhost ~]$ sed '3s/77/99/g' student.txt
#在第三行中,把74换成99
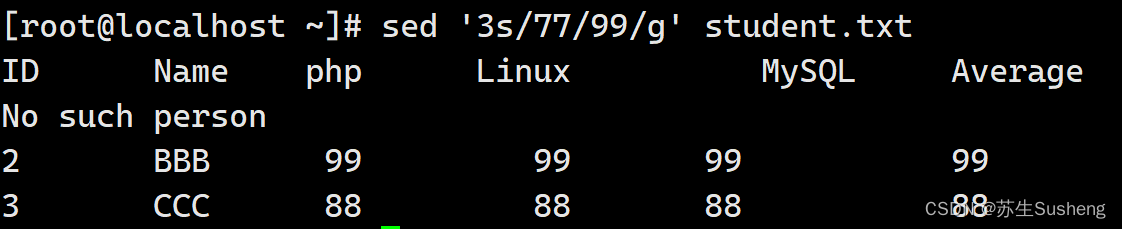
这样看起来就比较爽了吧。如果我想把AAA老师的成绩注释掉,让他不再生效。可以这样做:
[root@localhost ~]$ sed '2s/^/#/g' student.txt
#这里使用正则表达式,“^”代表行首
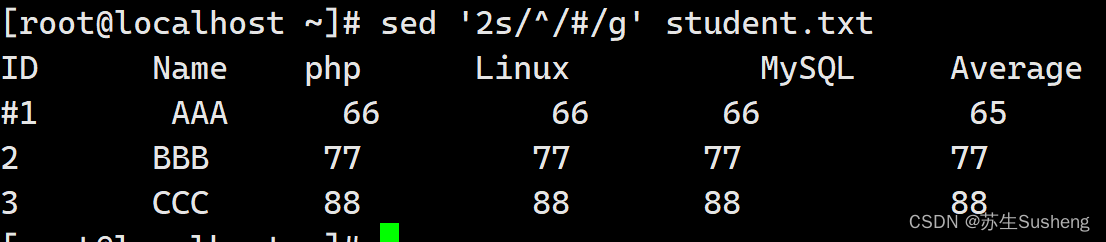 在sed中只能指定行范围,所以很遗憾我在他们两个的中间,不能只把他们两个注释掉,那么我们可以这样:
在sed中只能指定行范围,所以很遗憾我在他们两个的中间,不能只把他们两个注释掉,那么我们可以这样:
[root@localhost ~]$ sed -e 's/AAA//g ; s/BBB//g' student.txt
#同时把“AAA”和“BBB”替换为空
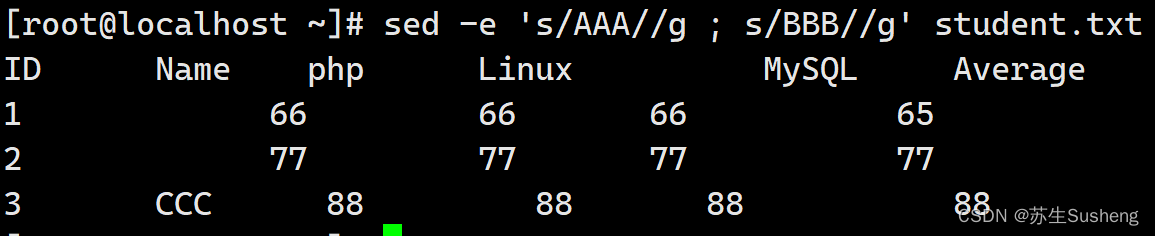 “-e”选项可以同时执行多个sed动作,当然如果只是执行一个动作也可以使用“-e”选项,但是这时没有什么意义。还要注意,多个动作之间要用“;”号或回车分割,例如上一个命令也可以这样写:
“-e”选项可以同时执行多个sed动作,当然如果只是执行一个动作也可以使用“-e”选项,但是这时没有什么意义。还要注意,多个动作之间要用“;”号或回车分割,例如上一个命令也可以这样写:
[root@localhost ~]$ sed -e 's/CCC//g;s/AAA//g' student.txt
sed -e 's/CCC//g
> s/AAA//g' student.txt


字符处理命令
sort 排序命令
[root@localhost~]$ sort [选项] 文件名
选项:
-f: 忽略大小写
-b: 忽略每行前面的空白部分
-n: 以数值型进行排序,默认使用字符串型排序
-r: 反向排序
-u: 删除重复行。就是uniq命令
-t: 指定分隔符,默认是分隔符是制表符
-k n[,m]: ―按照指定的字段范围排序。从第n字段开始,m字段结束(默认到行尾)
示例
sort命令默认是用每行开头第一个字符来进行排序的,比如:
[root@localhost~]$ sort /etc/passwd
#排序用户信息文件
#反向排序
sort -r/etc/passwd
如果想要指定排序的字段,需要使用“-t”选项指定分隔符,并使用“-k”选项指定字段号。加入我想要按照UID字段排序/etc/passwd文件:
[root@localhost~]$ sort -t ":" -k 3,3 /etc/passwd
#指定分隔符是“:”,用第三字段开头,第三字段结尾排序,就是只用第三字段排序
因为sort默认是按照字符排序,前面用户的UID的第一个字符都是1,所以这么排序。要想按照数字排序,请使用“-n”选项:
[root@localhost~]$ sort -n -t ":" -k 3,3 /etc/passwd
当然“-k”选项可以直接使用“-k 3”,代表从第三字段到行尾都排序(第一个字符先排序,如果一致,第二个字符再排序,知道行尾)。
uniq 取消重复行
[root@localhost~]$ uniq [选项] 文件名
选项:
-i:忽略大小写
wc 统计命令
[root@localhost~]$ wc [选项] 文件名
选项:
-l:只统计行数
-w:只统计单词数
-m:只统计字符数