【半监督医学图像分割 2022 CVPR】S4CVnet论文翻译
论文题目:When CNN Meet with ViT: Towards Semi-Supervised Learning for Multi-Class Medical Image Semantic Segmentation
中文题目:当CNN与ViT相遇:面向多类医学图像语义分割的半监督学习
论文链接:https://arxiv.org/abs/2208.06449

摘要
由于医学影像界缺乏高质量标注,半监督学习方法在图像语义分割任务中受到高度重视。
为了充分利用视觉转换器(ViT)和卷积神经网络(CNN)在半监督学习中的强大功能,本文提出了一种基于一致性感知伪标签的自集成方法。我们提出的框架包括一个由ViT和CNN相互增强的特征学习模块,以及一个用于一致性感知目的的健壮的指导模块。伪标签由特征学习模块中的CNN视图和ViT视图分别循环地推断和利用,以扩展数据集,彼此有益。同时,对特征学习模块设计了扰动方案,并利用平均网络权值设计了制导模块。
通过这样做,该框架结合了CNN和ViT的特征学习优势,通过双视图联合训练增强了性能,并以半监督的方式实现了一致性感知监督。详细验证了使用CNN和ViT的所有替代监督模式的拓扑探索,展示了我们的方法在半监督医学图像分割任务上最有前途的性能和特定设置。实验结果表明,该方法在具有多种指标的公共基准数据集上达到了最先进的性能。
1. 介绍
医学图像分割是计算机视觉和医学图像分析领域的重要课题,近年来,深度学习方法在医学图像分割领域占据主导地位。当前深度学习研究有希望的结果,不仅依赖于CNN的架构工程[28,34,9,43],还依赖于对数据集进行足够的高质量注释[2,13,48,11]。然而,临床医学图像数据最常见的情况是少量标记数据和大量原始图像,如CT、超声、MRI和腹腔镜手术的视频[30,17,44,47]。在最近的神经网络体系结构工程研究中,单纯基于自我注意的Transformer[40]由于能够对远程依赖进行建模,其性能优于CNN和RNN[27,13]。
在最近的神经网络体系结构工程研究中,单纯基于自我注意的Transformer[40]由于能够对远程依赖进行建模,其性能优于CNN和RNN[27,13]。基于以上对数据情况的关注,以及最近网络架构工程的成功,我们在此提出了一个旨在同时充分利用CNN和ViT的功能的半监督医学图像语义分割框架,称为S4CVnet。S4CVnet的框架由一个特征学习模块和一个引导模块组成,图1简要描述了这两个模块。该设置受到student-teacher style框架[15,39,48]的启发,对学生网络施加扰动,通过指数移动平均(EMA)[26]更新教师网络的参数,使得教师网络具有很强的鲁棒性,从而在一致性感知关注下指导带有伪标签的学生网络的学习。为了同时利用CNN和ViT的特征学习能力,避免两个网络架构不同造成的障碍,我们在特征学习模块中提出了双视图联合训练方法[47,10]。两种不同的网络视图同时推断伪标签,用原始数据扩大数据集的规模,在训练过程中相互补充、相互受益。一个特征学习网络也被认为是一个桥梁,应用网络扰动和通过学生-教师风格的方案学习知识的转移。
以下是S4CVnet的贡献
- 为了充分利用CNN和ViT的特征学习能力,提出了一种增强型双视图协同训练模块。CNN和ViT都具有相同的u型编码器-解码器风格的分割网络,以便进行公平的比较和探索
- 提出了一种基于计算高效u型ViT的鲁棒制导模块,并设计了一种基于EMA的一致性感知师生式方法。
- 提出了一种先进的半监督多类医学图像语义分割框架,在公共基准数据集上使用各种评估指标进行评估,并在相同的设置和特征信息分布下,与其他半监督方法保持最佳状态[39,52,41,42,51,45,32,30,47,48],
- 通过对CNN和ViT的所有替代监督模式的拓扑探索研究以及烧蚀研究,验证了以半监督方式利用CNN和ViT的全貌,并证明了S4CVnet最合适的设置和有前途的性能。
2. 相关工作
语义分割
卷积神经网络(convolutional neural network, CNN)用于图像语义分割,作为一种密集预测任务,自2015年开始被广泛研究,即FCN[28]。这是第一个以监督方式训练的基于cnn的网络,用于像素到像素的预测任务。随后的分割研究以CNN为主,主要有三个方面的贡献:骨干网、网络块和训练策略。例如,最有前途的骨干网络之一是UNet[34],它是一种具有跳过连接的编码器-解码器风格的网络,可以有效地传输多尺度语义信息。注意机制[35,24]、剩余学习[16]、密集连接[18]、扩张CNN[8]等多种进一步提高CNN性能的高级网络块被应用到骨干网络UNet中,形成了UNet族[21,44,46,23]。然而,在最近的研究中,用于密集预测任务的CNN缺乏对长期依赖关系建模的能力,被源自自然语言处理[40]的纯自注意网络Transformer击败。Transformer在计算机视觉任务中被广泛探索,即视觉变压器(ViT)[13],围绕分类、检测和分割任务[27,38,6,4]。本文在主干方面,重点探讨了CNN和ViT同时的特征学习能力,使两者相互有益,并具体解决了基于多视图协同训练自集成方法的半监督密集预测任务
半监督语义分割
除了骨干网络和网络块的研究外,根据数据集的不同场景,训练策略也是必不可少的研究,如处理低质量注释的弱监督学习[53,5,36],噪声注释[44],多评级者注释[25],多质量注释[33]的混合监督学习。
医学影像数据最常见的情况是标记数据量小,原始数据量大,因为标记成本高,因此半监督学习具有重要的探索价值。联合训练和自我训练是半监督学习中被广泛研究的两种方法。
自我训练,也称为自标记,是首先用标记的数据初始化一个分割网络。然后通过分割网络对未标记数据生成伪分割掩码[50,7,20,54,31,29]。设定伪分割掩码的选择条件,通过多次扩展训练数据对分割网络进行再训练。基于gan的方法主要研究如何使用判别器学习设置条件来区分预测和ground-truth分割[19,37]。另一种方法是联合训练,通常是将两个独立的网络训练为两个视图。因此,这两个网络扩大了训练数据的规模,并相互补充。深度联合训练在[32]中首次提出,指出了利用单一数据集(即“崩溃神经网络”)进行联合训练的挑战。在同一数据集上训练两个网络不能实现多视图特征学习,因为两个网络最终必然是相似的。
基于分歧的三网(trinet)提出了三视图,并通过“视图差异”对伪标签编辑的多样性增强进行改进,以解决“崩溃神经网络”[12,45]。不确定性估计也是一种能够利用可靠的伪标签来训练其他视图的方法[49,48,10]。
目前Co-training的重点研究主要集中在:(a)实现两种观点的多样性;(b)为再培训网络正确/自信地生成伪标签。在本文的训练策略方面,我们在特征学习模块中采用了两个完全不同的分割网络来鼓励两个视图之间的差异。此外,受学生-教师风格方法[39,26]的启发,开发了基于vitc的指导模块,该模块借助摄动和平均模型权重的特征学习模块[26,14],具有更强的鲁棒性。在整个半监督过程中,引导模块能够通过伪标签对特征学习模块的两个网络进行自信而恰当的监督。
3. 方法
在用于图像分割任务的一般半监督学习中,
L
,
U
\mathbf{L}, \mathbf{U}
L,U和
T
\mathbf{T}
T通常表示少量有标记的数据,大量无标记的数据,以及一个测试数据集。
对于带标签的训练和测试数据。我们将一批有标记的数据记为 ( X l , Y g t ) ∈ L , ( X t , Y g t ) ∈ T \left(\boldsymbol{X}_{\mathrm{l}}, \boldsymbol{Y}_{\mathrm{gt}}\right) \in \mathbf{L},\left(\boldsymbol{X}_{\mathrm{t}},\boldsymbol{Y}_{\mathrm{gt}}\right) \in \mathbf{T} (Xl,Ygt)∈L,(Xt,Ygt)∈T
将一批只有原始数据的数据记为 ( X u ) ∈ U \left(\boldsymbol{X}_{\mathrm{u}}\right) \in \mathbf{U} (Xu)∈U,其中 X ∈ R h × w \boldsymbol{X} \in \mathbb{R}^{h \times w} X∈Rh×w表示二维灰度图像。
Y
p
\boldsymbol{Y}_{\mathrm{p}}
Yp是分割网络
f
(
θ
)
:
X
↦
Y
p
f(θ):\boldsymbol{X} \mapsto \boldsymbol{Y}_{\mathrm{p}}
f(θ):X↦Yp以
θ
\theta
θ为网络
f
f
f的参数所预测的稠密映射。
Y p \boldsymbol{Y}_{\mathrm{p}} Yp可以看作是对未标记数据 ( X u , Y p ) ∈ U \left(\boldsymbol{X}_{\mathrm{u}},\boldsymbol{Y}_{\mathrm{p}}\right) \in \mathbf{U} (Xu,Yp)∈U的一批伪标签,用于再训练网络。
根据 T \mathbf{T} T的 Y g t \boldsymbol{Y}_{\mathrm{gt}} Ygt和 Y p \boldsymbol{Y}_{\mathrm{p}} Yp的差值计算最终评价结果。
S4CVnet框架的训练是根据每个网络分别与 Y p \boldsymbol{Y}_{\mathrm{p}} Yp和 Y g t \boldsymbol{Y}_{\mathrm{gt}} Ygt的推理差,最小化监督损失 L o s s s u p Loss_{\mathrm{sup}} Losssup和半监督损失 L o s s s e m i Loss_{\mathrm{semi}} Losssemi的总和。在我们的研究中, L , U \mathbf{L}, \mathbf{U} L,U和 T \mathbf{T} T没有重叠。
S4CVnet的框架如图1所示,由一个特征学习模块和一个基于三个网络
f
f
f的引导模块组成,即一个基于CNN的网络
f
C
N
N
(
θ
)
f_{\mathrm{CNN}}(\theta)
fCNN(θ)和两个基于vit的网络
f
V
i
T
(
θ
)
f_{\mathrm{ViT}}(\theta)
fViT(θ)。
特征学习模块各网络的 θ \theta θ分别初始化,以促进两种学习观点的差异,引导模块的 θ \theta θ通过EMA从具有相同结构的特征学习网络中更新。
S4CVnet的最终推理被认为是制导模块 f V i T ( θ ˉ ) : X ↦ Y f_{\mathrm{ViT}}(\bar{\theta}): \boldsymbol{X} \mapsto \boldsymbol{Y} fViT(θˉ):X↦Y的输出。
CNN和ViT网络、特征学习模块和引导模块的细节分别在下面的3.1节、3.2节和3.3节讨论。
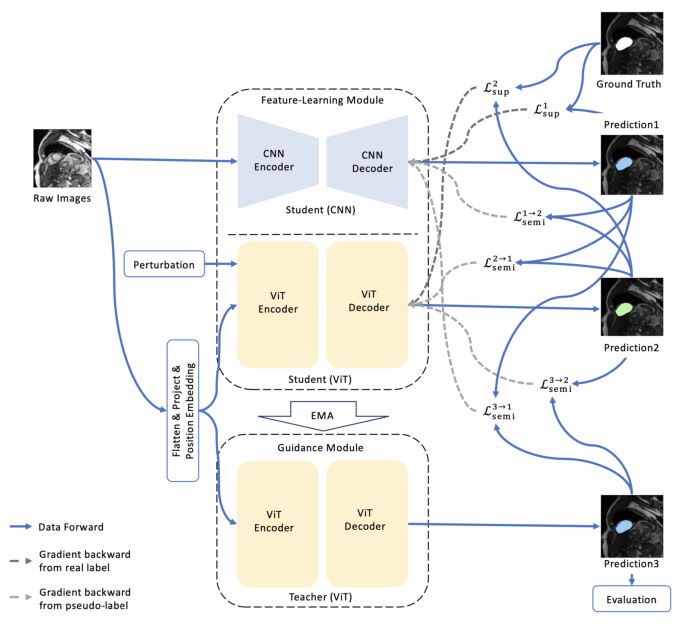
图1所示。S4CVnet的框架。它是一种融合了CNN和ViT功能的半监督医学图像语义分割框架,由特征学习模块(CNN & ViT)和引导模块(ViT)组成。监督机制通过最小化预测和(伪)标签之间的差异(也称为损失)来说明。
3.1 CNN & ViT
为了比较、分析和探索CNN和ViT的特征学习能力,我们提出了一种u型编码器-解码器风格的多类医学图像语义分割网络,该网络可以分别用纯CNN网络块或ViT网络块构建。
在U-Net[34]跳过连接成功的激励下,我们首先提出了一个u型分割网络,由4个编码器和解码器通过跳过连接连接,如图2 (a)所示。
通过图2 (b)所示的网络块替换编码器和解码器,可以直接构建一个纯CNN或ViT分割网络。在每个基于CNN的块中,在此基础上,开发了两个 3 × 3 3\times 3 3×3卷积层和两个批量归一化[22]。
基于vit的块基于swing - transformer块[27],没有进一步的修改[6,4]。
与传统的变压器块[13]不同,利用shiftwindow开发了层归一化LN[1]、多头自注意、残差连接[16]、带GELU的MLP,得到了基于窗口的多头自注意(WMSA)和基于移位窗口的多头自注意(SWMSA)。
WMSA和SWMSA分别应用于图2 (b)上方所示的两个连续变压器块。通过基于自注意的WMSA、SWMSA、MLP进行ViT特征学习的数据管道细节总结在公式1、2、3、4、5中,其中 i ∈ 1 ⋯ L i\in 1\cdots L i∈1⋯L, L L L为块数。
自注意机制包括三个点状线性层,将标记映射到中间表示:查询Q、键K和值V,在公式5中介绍。
这样,变压器块将输入序列
Z
0
=
[
z
L
,
1
,
…
,
z
L
,
N
]
\boldsymbol{Z}_{0}=\left[z_{L, 1}, \ldots, z_{L, N}\right]
Z0=[zL,1,…,zL,N]位置映射到
Z
L
=
[
z
L
,
1
,
…
,
z
L
,
N
]
\boldsymbol{Z}_{L}=\left[z_{L, 1}, \ldots, z_{L, N}\right]
ZL=[zL,1,…,zL,N],充分的语义特征信息(全局依赖关系)通过基于ViT的块进行充分的提取和收集。
Z
i
−
1
=
WMSA
(
LN
(
Z
i
−
1
)
)
+
Z
i
−
1
Z
i
=
MLP
(
LN
(
Z
i
)
)
+
Z
i
Z
i
+
1
=
SWMSA
(
LN
(
Z
i
)
)
+
Z
i
Z
i
+
1
=
MLP
(
LN
(
Z
i
+
1
)
)
+
Z
i
+
1
MSA
(
Z
′
)
=
softmax
(
Q
K
D
)
V
\begin{gathered} \boldsymbol{Z}_{i-1}=\operatorname{WMSA}\left(\operatorname{LN}\left(\boldsymbol{Z}_{i-1}\right)\right)+\boldsymbol{Z}_{i-1} \\ \boldsymbol{Z}_i=\operatorname{MLP}\left(\operatorname{LN}\left(\boldsymbol{Z}_i\right)\right)+\boldsymbol{Z}_i \\ \boldsymbol{Z}_{i+1}=\operatorname{SWMSA}\left(\operatorname{LN}\left(\boldsymbol{Z}_i\right)\right)+\boldsymbol{Z}_i \\ \boldsymbol{Z}_{i+1}=\operatorname{MLP}\left(\operatorname{LN}\left(\boldsymbol{Z}_{i+1}\right)\right)+\boldsymbol{Z}_{i+1} \\ \operatorname{MSA}\left(\boldsymbol{Z}^{\prime}\right)=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}}{\sqrt{D}}\right) \boldsymbol{V} \end{gathered}
Zi−1=WMSA(LN(Zi−1))+Zi−1Zi=MLP(LN(Zi))+ZiZi+1=SWMSA(LN(Zi))+ZiZi+1=MLP(LN(Zi+1))+Zi+1MSA(Z′)=softmax(DQK)V
其中
Q
,
K
,
V
∈
R
M
2
×
d
\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V} \in \mathbb{R}^{M^2 \times d}
Q,K,V∈RM2×d,
M
2
M^2
M2表示窗口中的补丁数量,d为查询和键的维度。
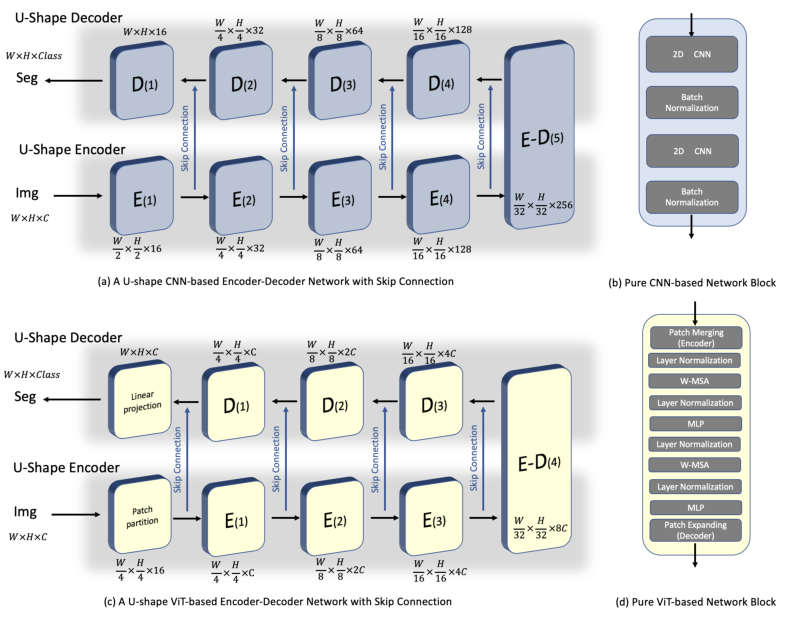
图2所示。主干分割网络。
(a,c)基于u型cnn或基于vit的编码器-解码器风格的分割网络,
(b,d)纯基于cnn或基于vit的网络块。这两个网络块可以直接应用于u形编码器解码器网络,从而形成一个纯粹的基于CNN或vv的分割网络。
与传统的基于cnn的区块在每个编码器或解码器之间进行下采样和上采样不同,在每个基于vit的编码器或解码器之间分别设计合并层和扩展层[6,4]。
合并层(patch merging)的设计目的是减少2倍的令牌数量,增加2倍的特征维度。它将输入补丁分为4个部分,并将它们连接在一起。应用线性层将尺寸统一为2倍。
扩展层(patch expanding)设计用于将输入特征图的尺寸重塑为2倍大,并将特征维减小到输入特征图维的一半。它采用线性层增加特征维数,然后采用重排操作扩大特征维数,将特征维数减小到输入维数的四分之一。
图2 (A)简要说明了每个步骤中特征映射的大小,其中W、H、C表示特征映射的宽度、高度和通道维度。
为了使ViT与CNN具有相同的计算效率,便于公平比较和互补,我们提出了这样的设置:patch大小为4,输入通道为3,嵌入式维数为96,自注意头数为3,6,12,24,窗口大小为7,每个编码器/解码器有2个基于swin-transformer的块,并使用ImageNet[11]预训练ViT。关于CNN和ViT骨干网的详细信息请参见附录。
3.2 特征学习模块
半监督学习,特别是基于伪标签的方法,已经在图像分割中得到了研究[3,32,12]。它将来自一个网络的未标记数据的分割推理作为伪标签来重新训练另一个网络,即多视图联合训练方法[15,30]。
交叉伪标签监督[10]有两个网络 f ( θ 1 ) f(\theta_1) f(θ1), f ( θ 2 ) f(\theta_2) f(θ2)具有相同的架构,但分别初始化以鼓励双重观点的差异,受其最近成功的激励,我们进一步提出了一个特征学习模块,旨在相互探索ViT和CNN的力量。
除了两个网络的参数当然是分开初始化外,还设计了
f
C
N
N
(
θ
1
)
,
f
V
i
T
(
θ
2
)
f_{\mathrm{CNN}}(\theta_1),f_{\mathrm{ViT}}(\theta_2)
fCNN(θ1),fViT(θ2)两个完全不同的网络架构,通过多视图学习使彼此受益,从而提高双视图学习的性能。本文提出的用于生成伪标签的特征学习模块如下图所示:
P
1
=
f
C
N
N
(
X
;
θ
1
)
,
P
2
=
f
V
i
T
(
X
;
θ
2
)
P_1=f_{\mathrm{CNN}}\left(X ; \theta_1\right), P_2=f_{\mathrm{ViT}}\left(X ; \theta_2\right)
P1=fCNN(X;θ1),P2=fViT(X;θ2)
其中
θ
1
,
θ
2
\theta_1,\theta_2
θ1,θ2分别表示网络初始化,
P
1
,
P
2
P_1,P_2
P1,P2分别表示用
f
C
N
N
(
θ
1
)
,
f
V
i
T
(
θ
2
)
f_{\mathrm{CNN}}(\theta_1),f_{\mathrm{ViT}}(\theta_2)
fCNN(θ1),fViT(θ2)进行分割推断。然后利用基于
P
1
,
P
2
P_1,P_2
P1,P2的伪标签进行监督和互补。CNN主要基于局部卷积运算,而ViT是通过自注意[13]对特征的全局依赖进行建模,因此两个分割推论
P
1
,
P
2
P_1,P_2
P1,P2具有不同的预测性质,并且没有明确的约束来强制两个相似的推论。同时互补的监督细节(ViT和CNN的更新参数)在3.4节中讨论。
3.3 引导模块
除了特征学习模块使两个网络能够从数据中学习外,还在一致性意识的考虑下设计了一个健壮的指导模块,以提高性能,并作为S4CVnet评估的最终模块。
引导网络的设计灵感来自于temporal ensembling[26]和self ensembling[39],目的是进一步监督被扰动的网络,最小化不一致性。在训练过程中,首先对特征学习模块中的网络进行扰动。其次,采用反向迭代的方法对网络参数进行迭代更新。然后通过特征学习模块的指数移动平均(EMA)对制导模块的网络进行更新。最后,一个比特征学习网络更健壮、更有可能正确的指导模块,用于监督两个具有一致性关注的特征学习网络。在S4CVnet中,引导模块基于与特征学习网络中的ViT具有相同架构的ViT,通过从数据[26]中学习ViT网络参数的EMA来不断更新引导ViT。本文提出的生成伪标签的指导模块可以说明为:
P
3
=
f
V
i
T
(
X
;
θ
‾
)
P_3=f_{\mathrm{ViT}}(X;\overline{\theta})
P3=fViT(X;θ)
其中
θ
\theta
θ表明网络ViT是基于平均网络权重,而不是直接由数据训练。
θ
\theta
θ根据特征学习 ViT模型的参数
θ
t
\theta_t
θt在过去的训练步骤t上进行更新,可以表示为
θ
‾
=
α
θ
t
−
1
+
(
1
−
α
)
θ
t
\overline{\theta}=\alpha\theta_{t-1}+(1-\alpha)\theta_t
θ=αθt−1+(1−α)θt。
α
\alpha
α是一个权重因子,计算公式为
α
=
1
−
1
t
+
1
\alpha=1-\frac{1}{t+1}
α=1−t+11。
P
3
P_3
P3表示
f
V
i
T
(
θ
‾
)
f_{\mathrm{ViT}}(\overline{\theta})
fViT(θ)的分割推理,用于监督特征学习模块遵循一致性意识的关注。通过引导模块对特征学习ViT和CNN的监督细节在章节3.4中讨论。
3.4 目标
训练目标是使三个网络
f
C
N
N
(
θ
1
)
,
f
V
i
T
(
θ
2
)
f_{\mathrm{CNN}}(\theta_1),f_{\mathrm{ViT}}(\theta_2)
fCNN(θ1),fViT(θ2)和
f
V
i
T
(
θ
‾
)
f_{\mathrm{ViT}}(\overline{\theta})
fViT(θ)之间的监督损失
L
s
u
p
\mathcal{L}_{\mathrm{sup}}
Lsup和半监督
L
s
e
m
i
\mathcal{L}_{\mathrm{semi}}
Lsemi的总和最小化,因此在训练过程中优化S4CVnet的总体损失如式8所示:
L
=
L
sup
1
+
L
sup
2
+
λ
1
(
L
semi
1
+
L
semi
2
)
+
λ
2
(
L
semi
3
+
L
semi
4
)
\mathcal{L}=\mathcal{L}_{\text {sup} 1}+\mathcal{L}_{\text {sup} 2}+\lambda_1\left(\mathcal{L}_{\text {semi } 1}+\mathcal{L}_{\text {semi } 2}\right)+\lambda_2\left(\mathcal{L}_{\text {semi }3}+\mathcal{L}_{\text {semi } 4}\right)
L=Lsup1+Lsup2+λ1(Lsemi 1+Lsemi 2)+λ2(Lsemi 3+Lsemi 4)
其中,
λ
1
,
λ
2
\lambda_1,\lambda_2
λ1,λ2为交叉监督双视图损失和一致性感知损失的权重因子,每150次迭代[26]更新一次。这是一个权衡权重,在训练过程中不断增加,使S4CVnet在初始化时关注有标签的数据,然后用我们提出的半监督方法将焦点转移到无标签的数据。这是在S4CVnet能够逐步推断出很多可靠伪标签的假设下做出的。权重因子如式9所示。
λ
=
e
−
5
×
(
1
−
t
iteration
/
t
maxiteration
)
2
\lambda=e^{-5 \times\left(1-t_{\text {iteration }} / t_{\text {maxiteration }}\right)^2}
λ=e−5×(1−titeration /tmaxiteration )2
其中t为完整训练过程中当前的迭代次数。
L
s
u
p
\mathcal{L}_{\mathrm{sup}}
Lsup和
L
s
e
m
i
\mathcal{L}_{\mathrm{semi}}
Lsemi分别讨论如下:
基于CrossEntropy CE计算各网络
L
s
e
m
i
\mathcal{L}_{\mathrm{semi}}
Lsemi之间的半监督损失,如式10所示:
L
semi
=
CE
(
argmax
(
f
1
(
X
;
θ
)
,
f
2
(
X
;
θ
)
)
)
\mathcal{L}_{\text {semi }}=\operatorname{CE}\left(\operatorname{argmax}\left(f_1(\boldsymbol{X} ; \theta), f_2(\boldsymbol{X} ; \theta)\right)\right)
Lsemi =CE(argmax(f1(X;θ),f2(X;θ)))
以及四个半监督损失,
(
f
1
(
X
;
θ
)
,
f
2
(
X
;
θ
)
)
\left(f_1(\boldsymbol{X} ; \theta), f_2(\boldsymbol{X} ; \theta)\right)
(f1(X;θ),f2(X;θ)).
这个损失对应的网络,有以下4个
( f C N N ( X ; θ ) , f V i T ( X ; θ ) ) \left(f_\mathrm{CNN}(\boldsymbol{X} ; \theta), f_\mathrm{ViT}(\boldsymbol{X} ; \theta)\right) (fCNN(X;θ),fViT(X;θ))
( f V i T ( X ; θ ) , f C N N ( X ; θ ) ) \left(f_\mathrm{ViT}(\boldsymbol{X} ; \theta), f_\mathrm{CNN}(\boldsymbol{X} ; \theta)\right) (fViT(X;θ),fCNN(X;θ))
( f V i T ( X ; θ ‾ ) , f V i T ( X ; θ ) ) \left(f_\mathrm{ViT}(\boldsymbol{X} ; \overline{\theta}), f_\mathrm{ViT}(\boldsymbol{X} ; \theta)\right) (fViT(X;θ),fViT(X;θ))
( f V i T ( X ; θ ‾ ) , f C N N ( X ; θ ) ) \left(f_\mathrm{ViT}(\boldsymbol{X} ; \overline{\theta}), f_\mathrm{CNN}(\boldsymbol{X} ; \theta)\right) (fViT(X;θ),fCNN(X;θ))
根据CE和Dice系数Dice计算各网络的监管损失
L
s
u
p
\mathcal{L}_{\mathrm{sup}}
Lsup,如式11所示:
L
sup
=
1
2
×
(
CE
(
Y
g
t
,
f
(
X
;
θ
)
)
+
Dice
(
Y
g
t
,
f
(
X
;
θ
)
)
)
\mathcal{L}_{\text {sup }}=\frac{1}{2} \times\left(\operatorname{CE}\left(Y_{\mathrm{gt}}, f(\boldsymbol{X} ; \theta)\right)+\operatorname{Dice}\left(Y_{\mathrm{gt}}, f(\boldsymbol{X} ; \theta)\right)\right)
Lsup =21×(CE(Ygt,f(X;θ))+Dice(Ygt,f(X;θ)))
这里我们简单地用一个网络
f
(
X
;
θ
)
f(\boldsymbol{X} ; \theta)
f(X;θ),可以认为是
f
C
N
N
(
θ
1
)
,
f
V
i
T
(
θ
2
)
f_{\mathrm{CNN}}(\theta_1),f_{\mathrm{ViT}}(\theta_2)
fCNN(θ1),fViT(θ2),因为每个用标记数据
Y
g
t
Y_{gt}
Ygt集训练的网络都直接以相同的方式进行训练。S4CVnet和第4节中报告的所有其他基线方法具有相同的损耗设计,包括CE, Dice for
L
s
u
p
\mathcal{L}_{\mathrm{sup}}
Lsup和
L
s
e
m
i
\mathcal{L}_{\mathrm{semi}}
Lsemi,以便进行公平的比较。
4. 实验结果
-
数据集设置
我们的实验验证了S4CVnet和所有其他基线方法在自动心脏诊断MICCAI挑战2017[2]的MRI心室分割数据集上的有效性。数据来自100名患者(近6000张图像),涵盖不同分布的特征信息,横跨五个均匀分布的亚组:正常、心肌梗死、扩张型心肌病、肥厚性心肌病和异常右心室。所有图片大小调整为224×224。选择20%的图像作为测试集,其余数据集用于训练(包括验证)。
-
实验细节
我们的代码在Ubuntu 20.04 Python 3.8.8下开发,使用Pytorch 1.10和CUDA 11.3,使用四个Nvidia GeForce RTX 3090 GPU和Intel® Intel Core i9-10900K。运行时间平均在5小时左右,包括数据传输、训练、推断和评估。对数据集进行二维图像分割处理。S4CVnet训练30,000次迭代,批大小设置为24,优化器为SGD,初始学习率设置为0.01,动量为0.9,权重衰减为0.0001。每200次迭代保存网络权重并在验证集上进行评估,最后使用验证性能最好的制导模块网络进行最终测试。该设置也可以直接应用于其他基线方法,无需任何修改。
-
backbone
S4CVnet由两种类型的网络组成,如图1所示。一种是基于cnn的具有跳过连接的分割网络UNet[34],另一种是基于vitn的具有移动窗口[27]和跳过连接的分割网络SwinUNet[4]。为了进行公平的比较,两个网络都是u型架构,纯基于CNN或vi的块作为编码器和解码器。本研究选择微型版本的ViT,使计算成本和训练效率与CNN相似。
-
基线方法
所有的方法,包括S4CVnet和其他基线方法,都是用相同的超参数设置和相同的特征分布来训练的。随机选取测试集、标记训练集和未标记训练集只进行一次,然后用所有基线方法和S4CVnet一起进行测试。报道的基线方法包括:MT [39], DAN [52], ICT [41], ADVENT [42], UAMT [51], DCN [32], CTCT[30],以CNN为骨干分割网络。
-
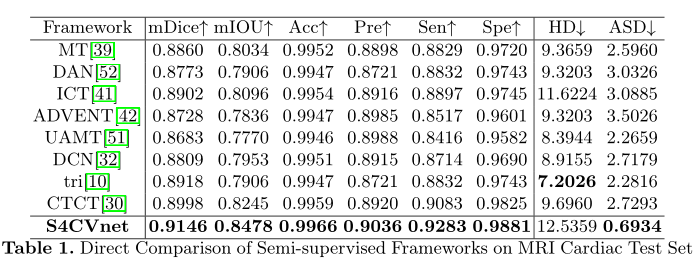
评估方法
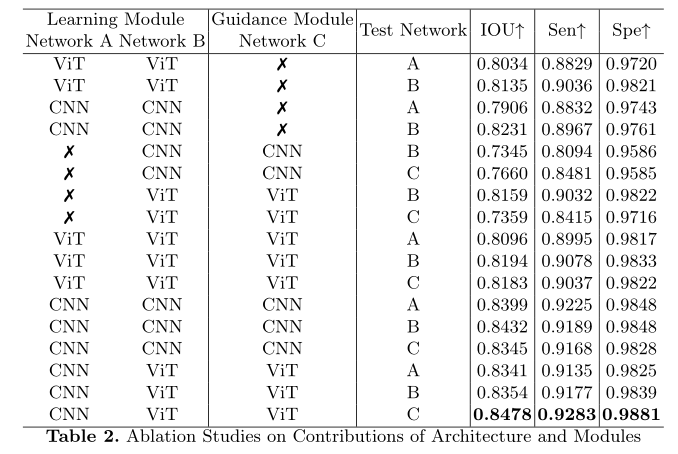
S4CVnet与其他基线方法进行直接对比实验,采用多种评价指标,包括相似度度量:Dice, IOU, Accuracy, Precision, Sensitivity, Specificity,数值越高越好。研究了不同的测量方法:豪斯多夫距离(HD)和平均表面距离(ASD),其值越低越好。报告这些指标的平均值,因为数据集是一个多类分割数据集。当将S4CVnet与其他基线方法进行比较时,报告了完整的评估措施,以及所有替代框架的拓扑探索。IOU作为最常用的指标也被选择来报告所有基线方法和S4CVnet在不同标签数据/总数据比率的假设下的性能。IOU, Sensitivity和Specificity被选择来报告不同网络的消融研究,我们提出的贡献有不同的组合。
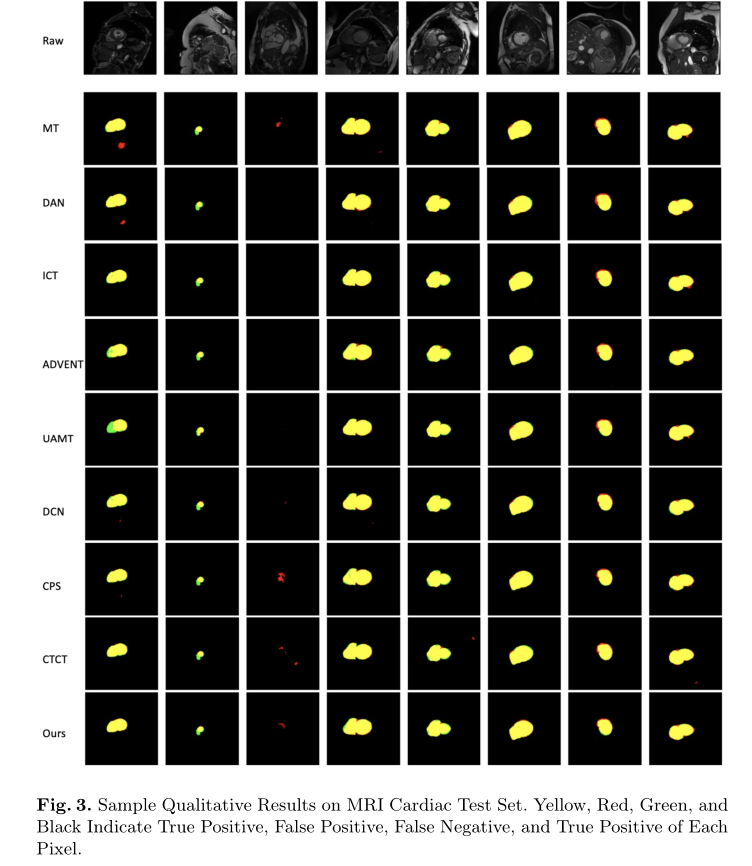
定性结果
图3展示了8张随机选择的样本原始图像,其中黄色、红色、绿色和黑色分别代表像素级的真阳性(TP)、假阳性(FP)、假阴性(FN)和真阴性(TN)推断。这说明了与其他方法相比,S4CVnet可以产生更少的FP像素和更低的ASD。
定量结果
表1报告了S4CVnet与其他半监督方法(包括相似度量和差异度量)的直接比较,假设标记数据/总数据的比率为10%。表中不同措施的最佳结果加粗显示。图4 (A)简要地描绘了对数尺度的折线图,其中x轴是标记数据/总数据的比率,y轴是IOU性能,说明了S4CVnet相对于其他基线方法的有价值的性能,特别是在标记数据/总数据的低比率时。S4CVnet和基线方法在不同标签数据/总数据比例假设下的量化结果详见附录。图4 (b)中简单描绘了一个直方图,表示预测图像的IOU性能的累积分布,其中x轴是IOU阈值,y轴是测试集中预测图像的数量,表明S4CVnet比其他方法更有可能预测IOU高的图像。
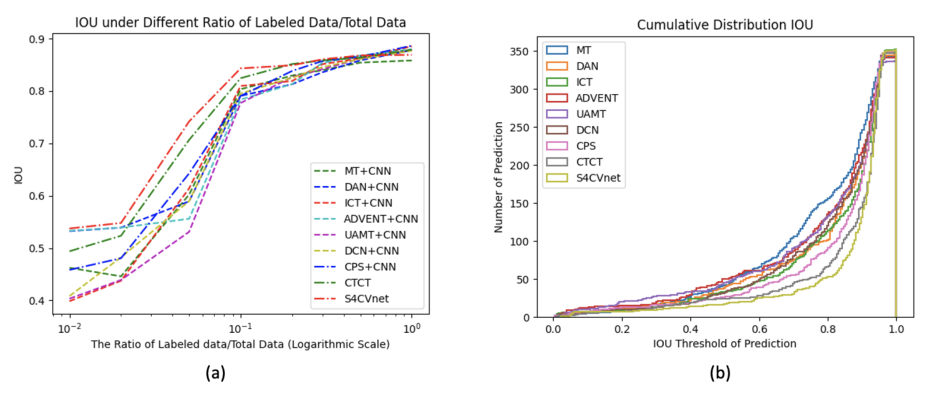
S4CVnet相对于其他基线方法的性能。(a)在不同的训练标签/总数据比值假设下,mIOU结果在测试集上的折线图。(b)直方图表示预测图像的IOU性能在测试集上的累积分布。
消融实验
为了分析每种提出的贡献和组合的效果,包括网络的设置、特征学习模块和引导模块的机制以及S4CVnet每个网络的鲁棒性,进行了大量的烧蚀实验,并报告在表2中。表示取消了一个特征学习模块或制导模块的网络,并探索了所有可选的网络设置(CNN或ViT)。在提出的贡献的不同组合下,也分别测试了所有可用的网络,消融研究表明,通过师生指导方案和双视图联合训练特征学习方法,提出的S4CVnet在半监督图像语义分割中具有最合适的设置,能够充分利用CNN和ViT的力量。
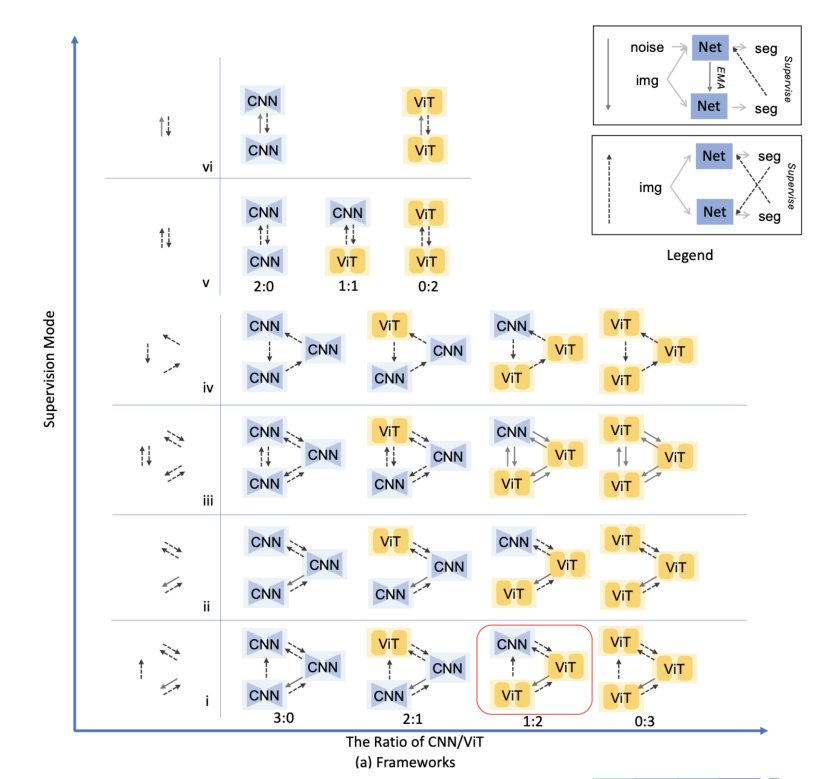
监管模式探索
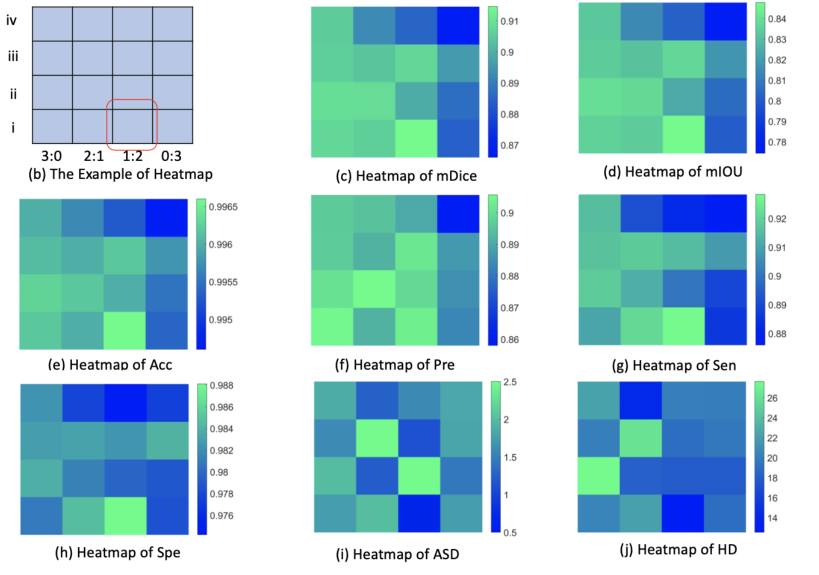
除了对网络、特征学习模块和引导模块的不同设置和组合的消融研究,我们还通过对CNN和ViT所有替代监督模式的拓扑探索,充分探索半监督学习在医学图像语义分割中的应用。可选框架的完整列表如图5所示,在图的图例中简要地描绘了两种监督模式。 → \rightarrow →为Student-Teacher式督导模式, ⇢ \dashrightarrow ⇢为交叉伪标签式督导模式。
图5 (a)用两个轴简要说明了所有的替代框架,y轴表示从三网到两网的不同监管模式,x轴表示CNN/ViT网络数量的比值,提出的S4CVnet在红色包围框中。图5 (a)中所示的所有框架都已经测试过,并直接用热图格式进行了报告。
图5 (b)是一个热图示例,表示CNN/ViT信息的监管模式和比例取决于热图的位置,并以红色包围框表示S4CVnet的位置。
图5 (c,d,e,f,g,h,i,j)表示了mDice、mIOU、准确率、精密度、灵敏度、特异性、ASD和HD验证性能的热图,展示了基于CNN和ViT的半监督医学图像分割CNN和ViT的半监督学习的全貌,以及我们提出的S4CVnet的命名位置。拓扑探测定量结果详见附录。
5. 结论
本文介绍了一种先进的医学图像语义分割半监督学习框架S4CVnet,旨在同时充分利用CNN和ViT的强大功能。S4CVnet由特征学习模块和引导模块组成。提出了一种双视图特征学习方法——特征学习模块,通过伪标签监督实现两个网络的互补。
指导模块基于平均网络权重来监督一致性关注下的学习模块。我们提出的方法使用各种评估指标和不同的假设,标签数据/总数据与其他半监督学习基线具有相同的超参数设置,并在公共基准数据集上保持最先进的位置。除了全面的消融研究外,使用CNN和ViT进行的拓扑探索说明了在半监督学习中使用CNN和ViT的整体情况。


![[ 数据结构 ] 背包问题(动态规划)](https://img-blog.csdnimg.cn/img_convert/535b7a89319ab66170ef73a8a0894aef.png)