目录
前言
关于“二八定律”
使用Redis作为缓存
为什么关系型数据库性能不高
为什么并发量高了就容易宕机
Redis就是一个用来作为数据库缓存的常见方案
缓存更新策略
定期生成
搜索引擎为例
实时生成
淘汰策略
FIFO(First In First Out) 先进先出
lRU(Least Recently Used) 淘汰最久未使用的
LFU(Least Frequently Used) 淘汰访问次数最少的
Ramdom 随机淘汰
Redis内置淘汰策略
缓存预热、缓存穿透、缓存雪崩、缓存击穿
缓存预热
缓存穿透
产生的原因可能有以下几种
解决方式
缓存雪崩
产生的原因可能有以下几种
为什么会出现大量的key同时过期?
如何解决
缓存击穿
如何解决
前言
缓存(cache)是计算机中的一个经典的概念,在很多场景中都会涉及到
核心思路就是把一些常用的数据放到触手可及(访问速度更快)的地方,方便读取
举个例子:
比如我去坐动车,那么我会选择将我的身份证放在口袋里,而不是我的背包中的某个夹层中
虽然我的口袋小,但是掏出来很快,并且在坐动车时身份证的使用还是比较频繁的~~
此时口袋就是背包的缓存
这里的速度快,是一种相对的快的概念~
通常情况下,OS对于硬件的访问速度是这样的:
CPU寄存器 > 内存 > 硬盘 > 网络
那么相对于网络,硬盘反倒是显得很快
而对于硬盘来说内存又更加的快~~
- 对于计算机硬件来说,往往越快的设备,价格越高昂,空间越小
- 即缓存虽然很快,但是空间往往是不足的,因此大部分时候,缓存只能存放一些热点数据
热点数据:频繁访问的数据
关于“二八定律”
即百分之 20 的数据,能够应对 百分之80 的访问场景
所以只需要将这少量的热点数据缓存起来,就能够应对百分之80的业务场景,从而在整体上有明显的性能提升
使用Redis作为缓存
在一个网站中经常会使用MySQL关系型数据库,来存储数据
关系型数据库虽然很强大,但是有一个很大的缺点,就是性能不高,即每一次查询的系统资源消耗高
为什么关系型数据库性能不高
- 数据库把数据存储在硬盘上,硬盘上的IO速度并不快,尤其是随机访问
- 如果查询不能命中索引,就需要进行表的遍历,会大大增加硬盘的IO次数
- 关系型数据库对于SQL的执行会做一系列的解析,校验,优化工作
- 如果是一些复杂的查询,比如联合查询,就需要进行笛卡尔积操作,效率更是低
- 事务处理和数据一致性:关系型数据库支持事务的原子性、一致性、隔离性和持久性(ACID)要求,这需要对数据进行更多的处理和管理,对性能产生一定的影响。
因此如果访问数据库的并发量高,那么数据库的压力很大的,很容易就宕机了~~
为什么并发量高了就容易宕机
服务器每处理一个请求,都是需要消耗一定的硬件资源,cpu、内存、硬盘、网络带宽....
一个服务器的硬件资源本身就是有限的。一个请求就会消耗一份资源,当资源耗尽。后续的请求没有资源可用,那么就无法正确的处理,更严重的还会导致服务器程序的代码出现崩溃
那么如何让数据库能够承受更大的并发量呢?
- 开源:引入更多机器,部署更多数据库实例,构成数据库集群
- 节流:引入缓存,使用其他方式保存经常访问的热点数据,从而降低直接访问数据库的请求数量
Redis就是一个用来作为数据库缓存的常见方案
Redis的访问速度比MySQL快很多,Redis能够接受的并发量更大
- Redis数据在内存中,访问速度远大于硬盘
- Redis只是简单的支持了key value的存储,不涉及复杂的查询
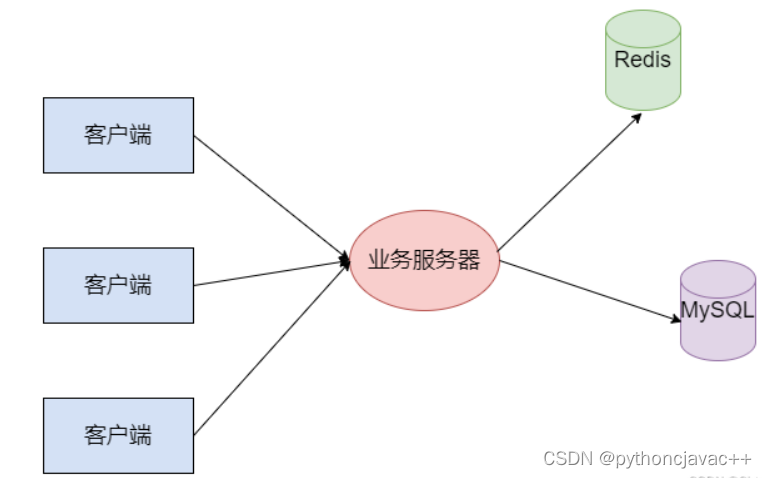
- 客户端访问业务服务器,发起查询请求
- 业务服务器先查询Redis,看看数据是否存在Redis
- 如果存在,直接返回
- 如果不存在,再查询MySQL
上述讨论了二八定侓,只需要在Redis中存放20%的热点数据,就能够保证日常80%的请求不用再去查询数据库了~
TIPS:缓存是用来加速"读" 操作,写操作还得老老实实的写数据库,并不能提高性能
缓存更新策略
定期生成
每隔一定的周期(一天,一周,一个月),对于数据的频次进行统计,挑选出访问频次最高的前N%的数据。
搜索引擎为例
用户在搜索引擎中输入一个"查询词",有些词是属于高频的(例如:30天速成C++,7天精通JAVA等)
此时搜索引擎的服务器就会把用户所搜索的词都通过日志的方式记录的明明白白,然后隔段时间就对该结果进行统计并得到一个"高频词表"
当然这种做法实时性低,对于突发情况应对的不是很好
比如春节时间大家最多的搜索可能是,春晚、高速免费时间段等
实时生成
先给缓存设定一个荣来给你上限(配置Redis中的 maxmemory 参数)
接下来的查询:
- 如果Redis查询到了,直接返回
- 如果Redis不存在,就从数据库查,把查到的结果同时也写入Redis
如果缓存满了,就出发淘汰策略,把一些不太热门的数据给淘汰掉。
淘汰策略
FIFO(First In First Out) 先进先出
把缓存中存在时间最久的 (也就是先来的数据) 淘汰掉.
lRU(Least Recently Used) 淘汰最久未使用的
记录每个key的最近一次的访问时间,把最近访问时间最老的key淘汰掉
LFU(Least Frequently Used) 淘汰访问次数最少的
记录每个key 最近一段时间的访问次数,把访问次数最少的淘汰掉
Ramdom 随机淘汰
从所有的 key 中抽取幸运⼉被随机淘汰掉
Redis内置淘汰策略
- volatile-lru 当内存不⾜以容纳新写⼊数据时,从设置了过期时间的key中使⽤LRU(最近最少使⽤)算法进⾏淘汰
- allkeys-lru 当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LRU(最近最少使⽤)算法进⾏淘汰.
- volatile-lfu 4.0版本新增,当内存不⾜以容纳新写⼊数据时,在过期的key中,使⽤LFU算法进⾏删除key.
- allkeys-lfu 4.0版本新增,当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LFU算法进⾏淘汰.
- volatile-random 当内存不⾜以容纳新写⼊数据时,从设置了过期时间的key中,随机淘汰数据
- allkeys-random 当内存不⾜以容纳新写⼊数据时,从所有key中随机淘汰数据.
- volatile-ttl 在设置了过期时间的key中,根据过期时间进⾏淘汰,越早过期的优先被淘汰.(相当于FIFO,只不过是局限于过期的 key)
- noeviction 默认策略,当内存不⾜以容纳新写⼊数据时,新写⼊操作会报错.
缓存预热、缓存穿透、缓存雪崩、缓存击穿
缓存预热
使⽤ Redis 作为 MySQL的缓存的时候, 当 Redis 刚刚启动,或者Redis⼤批 key失效之后,此时由于 Redis ⾃⾝相当于是空着的,没啥缓存数据,那么MySQL就可能直接被访问到,从⽽造成较⼤的压⼒.
此时就需要提前把热点数据准备好,直接写入到Redis中,使Redis可以尽早保护MySQL
缓存穿透
访问的 key 在 Redis 和 数据库中都不存在. 此时这样的 key 不会被放到缓存上,后续如果仍然在访问该 key, 依然会访问到数据库. 这就会导致数据库承担的请求太多,压⼒很⼤.
产生的原因可能有以下几种
- 业务设计不合理,缺少必要的参数校验环节,导致非法的key也被进行查询了
- 开发/运维的失误操作,不小心删除了某部分数据
- 被黑客攻击
解决方式
- 针对要查询的参数进行严格的合法性校验,例如如果要查询手机号,那么就要检验当前的key是否符合一个手机号码的格式
- 针对数据库上不存在的key,也存到Redis上,并将Value随便设置成一个'.',避免后续频繁访问数据库
- 使用布隆过滤器先判定key是否存在,再真正进行查询
缓存雪崩
短时间内大量的key在缓存上失效,导致数据库的压力倍增,甚至直接挂了
本来Redis就是MySQL的护盾,此时护盾失效了,MySQL的压力就会骤增
产生的原因可能有以下几种
-
Redis挂了
-
Redis上同时出现大量的key同时过期
为什么会出现大量的key同时过期?
可能是短时间呢设置了大量的Reids缓存,并且设置相同的过期时间
如何解决
- 部署高可用的Redis集群,并且完善监控报警体系
- 不给key设置过期时间 或者 设计过期时间的时候添加随机时间因子
缓存击穿
相当于缓存雪崩的特殊情况,即针对热点key过期了,导致大量的请求访问直接到MySQL上,甚至 导致数据库挂了
如何解决
- 基于统计的方式发现热点key,并设置永不过期
- 进行必要的服务降级,例如访问数据的时候使用分布式锁,限制同时请求数据的并发数