1、典型回答
在 Java 中,所有的基本类型都会对应一个包装类,如下所示:
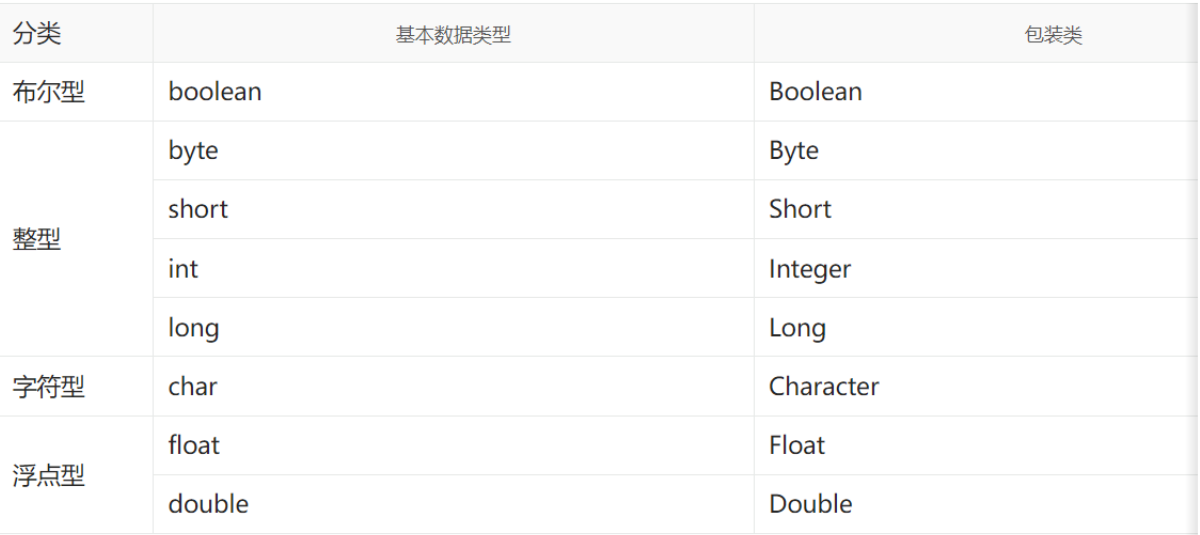
之所以要有包装类型的主要原因有以下几个:
- 面向对象要求:Java 是一门面向对象的编程语言,要求所有的数据都应该是对象。但是,基本数据类型(如 int、char、double等)并不是对象,它们没有成员方法和其他面向对象的特性。为了满足面向对象编程的要求,Java 引入了包装类,将基本数据类型封装成对象,使得它们也具有面向对象的特性。例如集合的操作只能是对象,而不能为基础数据类型
- 提供了更多的功能和方法:包装类提供了一些额外的方法和功能,例如执行数学运算、比较大小、转换数据类型 Integer.valueOf(n) 等方法
- 泛型要求:泛型(Generics)是 Java 中很重要的特性,它提供了类型安全和代码重用的功能。但是,泛型要求类型参数必须是对象类型,不能是基本数据类型。因此,如果想在泛型中使用基本数据类型,就需要使用对应的包装类
- 表示 null 值:包装类可以表示 null 值,而基本数据类型不能。这在某些场景下很有用,比如在接口传参中,如果使用包装类即使前端不传参也不会报错,而使用基本数据类型,如果前端忘记传参就会报错
2、全面剖析
包装类存在的意义是:面向对象编程的要求、提供了更多的功能和方法、泛型要求、以及可以用它来表示 null 值
包装类常用的场景有:
- 用于泛型数据存储
- 用于集合类数据存储
- 方法的参数传递
2.1、定义泛型
泛型类型定义不能为基本数据类型,否则编译期就会报错,如下代码所示:
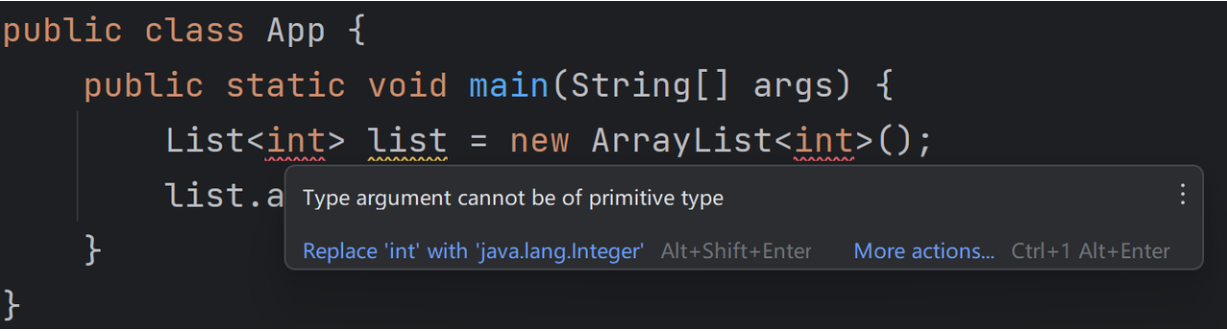
但使用包装类型则完全没有问题:

2.1、集合类的数据存储
集合类的操作必须是对象,而非基础数据类型,这点大家可能会有疑问,说不对呀,我平常 int 类型也可以直接添加到集合中,如下代码所示:
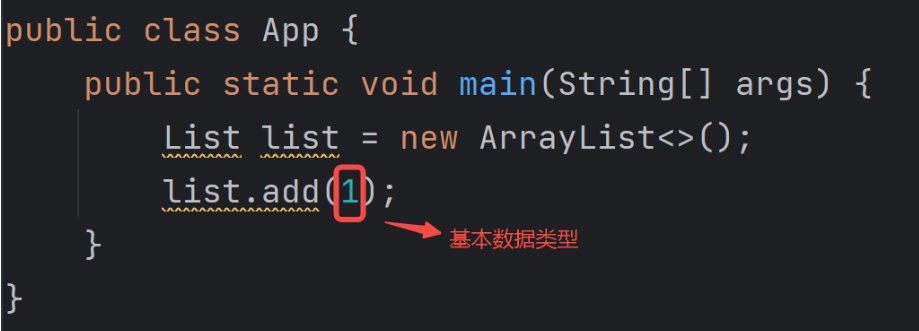
但你把上面的代码反编译一下就能看出“端倪”,以上代码反编译之后的代码如下:

也就是说,当你使用 int 基本数据类型时,编译器会帮你自动转换成包装类型,所以集合操作的底层还是对象,而非基础数据类型
2.3、方法参数传递
在接口传参中,一定要使用包装类,因为包装类的默认值是 null,所以在使用包装类接收参数时,即使前端没有传递任何参数,那么参数的值就是 null,但程序不会报错;而如果使用的是基本数据类型来接收参数,那么,如果前端忘记传递参数了,程序就会报错(状态码为 500 的内部错误),所以方法传参一定要使用包装类
3、知识扩展
3.1、装箱和拆箱
装箱(Boxing)和 拆箱(Unboxing)是 Java 语言中,用于基本数据类型和包装类之间互相转换的过程
装箱是指将基本数据类型转换为对应的包装类对象。Java编译器会自动将基本数据类型转换为对应的包装类对象,这称为自动装箱
例如,将 int 类型的值赋给 Integer 对象:

拆箱是指将包装类对象转换为对应的基本数据类型。同样,Java 编译器会自动将包装类对象转换为对应的基本数据类型,这称为自动拆箱
例如,将 Integer 对象赋给 int 类型的变量:

装箱和拆箱的过程在编译时由编译器自动完成,使得基本数据类型和包装类之间可以方便地进行转换。这样就可以在需要使用包装类的场景(如泛型、集合类、反射等)中传递和操作基本数据类型的值
注意事项
但需要注意的是,装箱和拆箱的过程中可能涉及到对象的创建和销毁,可能会引入额外的开销和性能消耗。因此,在性能要求较高的场景中,应尽量避免频繁的装箱和拆箱操作,以减少额外的开销
3.2、包装类缓存
在 Java 中,对于某些特定的包装类对象,JVM会对其进行缓存,以提高性能和节省内存空间,而这个机制就叫做包装类缓存,也叫做包装类的高速缓存
例如 Integer 的缓存,Integer 类内部实现了一个高速缓存,称为 Integer Cache。这个缓存用于缓存一定范围内的整数对象,以提高性能和减少内存消耗。这个特性在 Java5 及之后的版本中引入
Integer 类对于小整数值(默认范围为 -128 到 127)会在初始化时创建缓存,即预先创建这些整数对象并存储在一个数组中。当代码中需要创建一个该范围内的整数对象时,实际上是从缓存中获取已存在的对象,而不是每次都创建一个新的对象。这样做的好处是,对于常用的小整数值,不会产生大量的重复对象,从而节省了内存和提高了性能。
这个缓存的范围可以通过 JVM 参数进行调整,例如,可以通过设置 -XX:AutoBoxCacheMax=<Size> 来增加缓存的范围。
值得注意的是,对于超过缓存范围的整数值,每次都会创建一个新的 Integer 对象,而不会从缓存中获取。因此,使用整数时要注意是否处于缓存范围,避免在比较整数对象时产生不符合预期的结果
以下是一个简单 Integer 高速缓存的例子:
public class IntegercacheDemo{
public static void main(string[]args){
Integer a = 10; // 缓存范围内的整数,从缓存中获取
Integer b = 10; // 缓存范围内的整数,从缓存中获取
Integer c = 128; // 超出缓存范围,创建新的对象
Integer d = 128; // 超出缓存范围,创建新的对象
System.out.println("a == b:" + (a== b)); // 输出:a==b:true,因为a和b引用的是缓存中同一个对象
System.out.println("c == d:" + (c== d)); // 输出:c== d:false,因为c和d是两个独立的对象
}
}程序执行的结果:
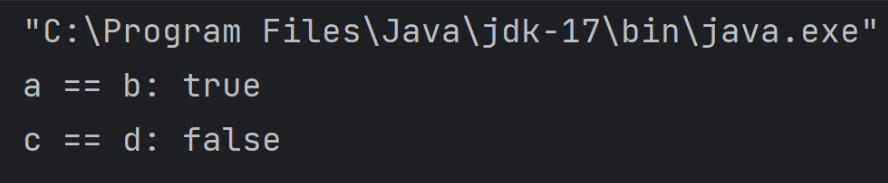
因为 a 和 b 使用的都是缓存,所以他们两个的引用地址是一样的;而 c 和 d 超出了 int 的缓存范围,所以都是新建的对象,那么他们的引用地址自然也就不同了