提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、Redis是什么?
- 二、Redis安装
- 三、Redis相关
- 数据类型
- 四、基础操作(使用了python连接redis)
- 1.字符串
- 2.键对应操作
- 3.哈希(hash)
- 结构
- 操作
- 4.集合
- 5.有序集合
- 6.列表
- 总结
前言
Redis是一个性能卓越、功能丰富的键值存储系统,适用于各种不同的应用场景,本文就介绍了Redis的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Redis是什么?
Redis (Remote Dictionary Server) 是一个开源的高性能、非关系型数据库管理系统,属于键值存储系统。它支持多种数据结构,包括字符串、哈希表、列表、集合、有序集合等,并提供了丰富的操作命令,可以满足各种不同的应用需求。
Redis具有以下特点:
-
内存存储:Redis是将所有数据存储在内存中,因此读写速度非常快。同时,Redis也可以将数据持久化到硬盘上,以保证数据的持久性。
-
高性能:Redis采用C语言编写,并且使用了自己开发的数据结构和算法,使得它在处理大量并发请求时表现出色,能够实现高性能的读写操作。
-
多种数据结构支持:Redis支持多种数据结构,包括字符串、哈希表、列表、集合、有序集合等。每种数据结构都有相应的操作命令,方便开发者进行数据的存储和操作。
-
发布订阅功能:Redis支持发布订阅模式,可以将消息发布给多个订阅者,实现消息的广播功能。
-
支持事务操作:Redis支持事务操作,可以将多个操作打包成一个事务进行执行,并且保证事务的原子性。
-
分布式存储:Redis支持数据的分布式存储,可以将数据分散存储在多个节点上,提高系统的整体性能和可扩展性。
总结起来,Redis是一个性能卓越、功能丰富的键值存储系统,适用于各种不同的应用场景,例如缓存、排行榜、实时统计等。它简单易用,具有高可用性、高性能和可扩展性,成为开发者们常用的数据存储解决方案之一。
二、Redis安装
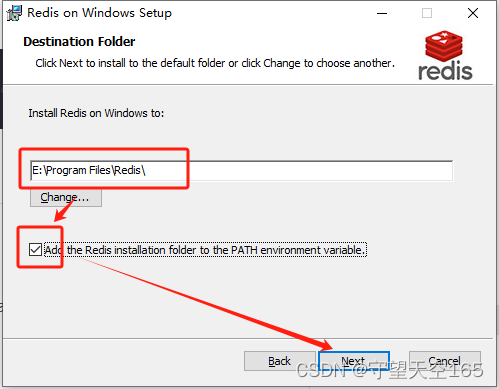
双击安装包,一直next下去,在下方页面可以更改安装地址和配置环境变量,安装地址更不更改看个人喜好,文件不大,可以不改(我这里更改到了E盘,因为本宫喜欢),千万不要忘了将添加环境变量的选项勾选上,否则就要自己配置环境变量了。
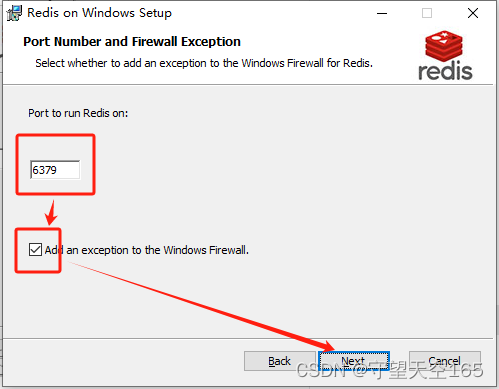
下方页面中6379是端口号,选项是在防火墙中添加一个通道供Redis使用。
- 扩展:
- MySQL端口号:3306
- MongoDB端口号:27017
- Redis端口号:6379
后面的默认就好。
安装后 win+r 打卡命令行终端输入redis-cli,出现下方界面表示安装成功。
三、Redis相关
Redis:是一个键值存储数据库,类似字典
-
内存数据库:
MySQL、MongoDB都是以文件的形式存储在磁盘里
Redis数据在内存中,操作内存的速度远远高于磁盘,并且Redis数据最终也可以存储在磁盘上 -
Redis服务器与客户端
启动服务器:redis-server 配置文件:redis.windows.conf
数据类型
-
字符串
-
哈希:存储键值对
-
列表:存储多个数据
-
集合:无序、不重复
-
有序集合:按照分数(权重)进行排序
-
数据库相关
默认使用db0(第一个数据库)
keys *:所有的键
四、基础操作(使用了python连接redis)
-
导入模块:import redis
-
构建连接:redis.StrictRedis()
-
关闭连接:client.close()
提示:下面的内容均是在python中运行的,与在终端中运行是不一样的
1.字符串
-
set(k, b):设置单个
-
get(k):获取单个
-
mset({字符串1:值, 字符串2:值, …}):添加多个字符串
例子:r = client.mset({“s3”: “s33”, “s4”: “s44”, “s5”: “s55”}) # 在s3中添加s33,在s4中添加s44,在s5中添加s55 -
mget(k,k,k,k):获取多个字符串中的元素
-
incr(字符串):加1,例如:在代码中s6从100变为101
-
incrby(字符串,增量):在原有字符串上增加
-
decr:减1
-
decrby:减 增量
-
setex(k,time,v):设置带有有效期的
-
setnx(k,v):不存在就插入,不会覆盖
-
append(k,v):在原始数据后面拼接
-
delete(k):删除指定元素,返回 1、0
1:删除成功
0:没有删除成功 -
strlen(k):获取指定键的值长度
# 导入模块
import redis
# 构建连接
client = redis.StrictRedis()
# 操作
# 数字类型 字符串
# 添加单个字符串
r = client.set("s2", "hello s2!!")
print(r) # True
# 获取单个元素
r = client.get("s2")
print(r, type(r)) # b'hello s2!!' <class 'bytes'>
# 添加多个字符串
# mset({字符串1:值, 字符串2:值, ...})
r = client.mset({"s3": "s33", "s4": "s44", "s5": "s55"})
# 在s3中添加s33,在s4中添加s44,在s5中添加s55
print(r) # True
# 获取多个字符串中的元素
r = client.mget(["s3", "s4", "s5"])
print(r) # [b's33', b's44', b's55']
r = client.set("s6", "100")
print(r) # True
# incr转换并加1
r = client.incr("s6")
print(r) # 101
# 增指定的量
r = client.incrby("s6", 10)
print(r) # 111
# decr转换并-1
r = client.decr("s6")
print(r) # 110
# decrby(字符串, 减量)
r = client.decrby("s6", 10)
print(r) # 100
# 设置带有有效期的
r = client.setex("s7", 10, "s777")
print(r) # True
# 删除指定元素
r = client.delete("s6")
print(r) # 1 ==》 删除成功
# append(k,v):在原始数据后面拼接,返回当前字符串的长度
r = client.append("s5", "77777")
print(r) # 8
# 获取指定键的值长度:strlen(k)
r = client.strlen("s5")
print(r) # 8
# 不存在就插入,不会覆盖
r = client.setnx("s44", "s4")
print(r) # True
# 释放连接
client.close()
2.键对应操作
-
keys():返回所有键
-
exists(k):查看键是否存在
-
type(k):查看键对应值的类型
-
expire(k,time):设置有效期
-
ttl(k):查看剩余时间
-
delete(k):删除键
# 导入模块
import redis
# 构建连接
client = redis.StrictRedis()
# 键相关操作
# 判断键是否存在,返回0、1
# 存在:1 ; 不存在:0
r = client.exists("s33")
print(r) # 0
# 设置有效期:expire(k,time),以秒为单位
r = client.expire("s3", 50)
print(r) # True
# 查看剩余时间
r = client.ttl("s3")
print(r) # 50
# 查看键对应值的类型
r = client.type("s3")
print(r) # b'string'
# 查看数据中所有的键
r = client.keys()
print(r) # [b'h2', b's44', b's4', b'set1', b'set5', ...
# 查看键对应的类型
r = client.type("s2")
print(r) # b'string'
# 释放连接
client.close()
3.哈希(hash)
结构
-
键(redis键)
-
字段(hash的键)
-
值(hash的值)
操作
-
hset(name,key,value):添加键值对
-
hget(name,key):获取对应的键
-
hmget(name,[key]):获取列表中字段对应的值
-
hmset(name,{}):添加多个键值对
-
hincrby(name,key,value):字段的值增加增量,返回增加后的值
-
hexists(name,key):判断字段是否存在
-
hgetall(name):所有字段与值
-
hkeys(name):所有字段
-
hvals(name):所有字段的值
-
hdel(name,key):删除字段,1:删除成功
-
hlen(name,key):返回字段长度
# 导入模块
import redis
# 构建连接
client = redis.StrictRedis()
# 哈希
print("***** 哈希 *****")
# 键(redis键)
# 字段(hash的键)
# 值(hash的值)
# 添加键值对:hset(name,key,value)
# 添加成功返回1
r = client.hset("h2", "k11", "v1111")
print(r) # 1
# 获取对应的键:hget(name,key)
r = client.hget("h2", "k1")
print(r) # b'v1'
#
# hmset要被废弃了,建议使用hset
# 添加键值对
r = client.hmset("h2", {"k2": "v2", "k3": "v3"})
print(r) # True
# 获取列表中字段对应的值:hmget(name,[key])
r = client.hmget("h2", ["k2", "k3", "k1", "k11"])
print(r) # [b'v2', b'v3', None, b'v1111']
r = client.hset("h2", "k4", "100")
print(r) # 1
# hincrby(name,key,value):将字段的值增加增量,返回增加后的值
# 正量
r = client.hincrby("h2", "k4", 100)
print(r) # 200
r = client.hget("h2", "k4")
print(r) # b'200'
# 负量
r = client.hincrby("h2", "k4", -100)
print(r) # 100
r = client.hget("h2", "k4")
print(r) # b'100'
# 判断字段是否存在
r = client.hexists("h2", "k4")
print(r) # True
# hdel(name,key):删除字段,1:删除成功
r = client.hdel("h2", "k4")
print(r) # 1
r = client.hexists("h2", "k4")
print(r) # False
# 释放连接
client.close()
4.集合
-
sadd(key,value,value,value):添加,需要指定键,返回成功插入的个数
例子:r = client.sadd(“set2”, 100, 200, 300, 300 ) -
smembers(key): 获取所有元素
-
sismember(key,value):判断value是否在集合中
-
scard(key):总个数
-
srem(key,value):移除指定元素,返回移除的个数
-
spop(key):随机删除,返回移除的元素
-
srandmember(key,个数):随机获取集合中的元素
-
sinter( [ key1,key2 ] ):交集,放入的是集合列表
-
sunion( [ key1,key2 ] ):并集,放入的是集合列表
-
sdiff( [ key1,key2 ] ):差集,放入的是集合列表
-
sinterstore(new_key, [ key1,key2 ] ):合并交集 (新集合),返回个数
-
sunionstore(new_key, [ key1,key2 ] ):合并并集 (新集合),返回个数
-
sdiffstore(new_key, [ key1,key2 ] ):合并差集 (新集合),返回个数
# 导入模块
import redis
# 构建连接
client = redis.StrictRedis()
# 集合
print("********* 集合 *********")
# 添加,需要指定键,返回成功插入的个数
r = client.sadd("set2", 100, 200, 300, 300, 100)
print(r) # 3
# 获取所有元素
r = client.smembers("set2")
print(r) # {b'100', b'300', b'200'}
# 判断value是否在集合中
r = client.sismember("set2", "100")
print(r) # 1
# 总个数
r = client.scard("set2")
print(r) # 3
# 移除指定元素,返回移除的个数
r = client.srem("set2", "200")
print(r) # 1
r = client.smembers("set2")
print(r) # {b'100', b'300'}
# 随机删除,返回移除的元素
r = client.sadd("set2", 450, 600, 780, 550, 450, 600)
print(r) # 4
r = client.spop("set2")
print(r) # b'450'
# 随机获取集合中的元素 2个
r = client.srandmember("set2", 2)
print(r) # [b'100', b'550']
# 第二个集合
r = client.sadd("set3", 400, 500, 450, 300)
print(r) # 4
# 交集
r = client.sinter(["set2", "set3"])
print(r) # {b'300'}
# 并集
r = client.sunion(["set2", "set3"])
print(r) # {b'500', b'600', b'100', b'300', b'450', b'400', b'550', b'780'}
# 差集
r = client.sdiff(["set2", "set3"])
print(r) # {b'100', b'550', b'600', b'780'}
# 合并交集,返回个数
r = client.sinterstore("set4", ["set2", "set3"])
print(r) # 个数 # 1
r = client.smembers("set4")
print(r) # {b'300'}
# 合并并集,返回个数
r = client.sunionstore("set5", ["set2", "set3"])
print(r) # 个数 # 8
r = client.smembers("set5")
print(r) # {b'500', b'600', b'100', b'300', b'450', b'400', b'550', b'780'}
# 合并差集,返回个数
r = client.sdiffstore("set4", ["set2", "set3"])
print(r) # 个数 # 4
r = client.smembers("set4")
print(r) # {b'100', b'550', b'600', b'780'}
# 释放连接
client.close()
5.有序集合
-
zadd(“集合”, {值: 权重}):添加带有权重的元素,返回个数
例子:r = client.zadd(“zset2”, {“v1”: 10, “v2”: 5 } ) -
zrem(集合, 值, 值, …):移除指定元素,返回移除的个数
例子:r = client.zrem(“zset2”, “v1”, “v2”) -
按照索引范围获取元素,withscores判断输出是否需要带权重
正序: zrange(集合, min索引, max索引, withscores=True)例子:r = client.zrange("zset2", 0, 5, withscores=True) 结果:[(b'v4', 20.0), (b'v3', 30.0), (b'v6', 40.0), (b'v5', 50.0)]逆序 :zrevrange(集合, min索引, max索引, withscores=True)
例子:r = client.zrevrange("zset2", 0, 5, withscores=True) 结果:[(b'v5', 50.0), (b'v6', 40.0), (b'v3', 30.0), (b'v4', 20.0)] -
按照权重范围获取元素
正序:zrangebyscore(集合, min权重, max权重, withscores=True)逆序:zrangebyscore(集合, max权重, min权重, withscores=True)
-
zcard(集合): 总个数
-
zcount(集合, min, max):权重在min到max之间元素的个数
例子:r = client.zcount(“zset2”, 10, 100) -
zscore(集合, value):获取value对应的权重
-
zincrby(集合, 增量, 值):增加权重,返回增加好的权重
例子:r = client.zincrby(“zset2”, 50, “v5”) # 向zset2中v5的权重增加50 结果:50
zinterstore(新集合, [集合1, 集合2, …]):合并交集,返回个数
# 导入模块
import redis
# 构建连接
client = redis.StrictRedis()
# 有序集合:通过分数(权重)实现有序
# 添加带有权重的元素:zadd("集合", {值: 权重}),返回个数
r = client.zadd("zset2", {"v1": 10, "v2": 5, "v3": 30, "v4": 20, "v5": 50, "v6": 40})
print(r) # 6
# 移除指定元素,返回移除的个数:zrem(集合, 值, 值, ....)
r = client.zrem("zset2", "v1", "v2")
print(r) # 2
# 按照索引范围获取元素(正序),withscores判断输出是否需要带权重
# zrange(集合, min索引, max索引, withscores=True)
r = client.zrange("zset2", 0, 5, withscores=True)
print(r) # [(b'v4', 20.0), (b'v3', 30.0), (b'v6', 40.0), (b'v5', 50.0)]
# 同上,只不过是逆序按照索引获取元素
r = client.zrevrange("zset2", 0, 5, withscores=True)
print(r) # [(b'v5', 50.0), (b'v6', 40.0), (b'v3', 30.0), (b'v4', 20.0)]
# 按照权重范围获取元素(正序):zrangebyscore(集合, min权重, max权重, withscores=True)
r = client.zrangebyscore("zset2", 0, 100, withscores=True)
print(r) # [(b'v4', 20.0), (b'v3', 30.0), (b'v6', 40.0), (b'v5', 50.0)]
# 逆序:zrangebyscore(集合, max权重, min权重, withscores=True)
r = client.zrevrangebyscore("zset2", 100, 0, withscores=True)
print(r) # [(b'v5', 50.0), (b'v6', 40.0), (b'v3', 30.0), (b'v4', 20.0)]
# 总个数
r = client.zcard("zset2")
print(r) # 4
# 权重在min到max之间元素的个数:zcount(集合, min, max)
r = client.zcount("zset2", 10, 100)
print(r) # 4
# 获取value对应的权重:zscore(集合, value)
r = client.zscore("zset2", "v5")
print(r) # 50.0
# 增加权重,返回增加好的权重:zincrby(集合, 增量, 值)
r = client.zincrby("zset2", 50, "v5") # 向zset2中v5的权重增加50
print(r) # 100.0
r = client.zadd("zset3", {"v5": 500, "v6": 400, "v7": 300, "v8": 40, "v9": 50})
print(r)
# 交集:zinterstore(新集合, [集合1, 集合2, ....]),返回个数
r = client.zinterstore("zset4", ["zset2", "zset3"])
print(r) # 2
# 释放连接
client.close()
6.列表
-
插入,返回当前列表的个数
在向当前列表的左边:lpush(列表, 值,值,…)例子:r = client.lpush("l2", 1, 2, 3, 4, 5)在向当前列表的右边插入:rpush(列表, 值,值,…)
例子:r = client.rpush("l2", 0, -1, -2, -3) -
末尾删除,返回删除的元素
左边删除:lpop(列表)
右边删除:rpop(列表) -
修改:lset(列表, 位置, 修改的值)
例子:r = client.lset(“l2”, 0, “30”) # 将l2中0的位置上的元素修改为30 -
插入元素,返回当前列表的个数:linsert(列表, “before/after”, 参考位置, 插入的值)
r = client.linsert("l2", "before", "0", "0.5") # l2中在0的前面插入0.5 r = client.linsert("l2", "after", "0", "-0.5") # l2中在0的后面插入-0.5 -
删除对应数量的值,返回删除的个数: lrem(“l2”, 数量, 值)
例子:r = client.lrem("l2", 2, "-30") # 在l2中删除2个-30 -
保留列表指定范围内的元素,删除其他元素:ltrim(列表, start, end)
r = client.ltrim(“l2”, 2, 4) -
获取指定范围的元素:lrange(“l2”, start位置, end位置)
r = client.lrange(“l2”, 0, 100) -
获取对应位置的元素:lindex(列表, 位置)
# 导入模块
import redis
# 构建连接
client = redis.StrictRedis()
# 列表
# 插入(在向当前列表的左边),返回当前列表的个数
# lpush(列表, 值,值,...)
r = client.lpush("l2", 1, 2, 3, 4, 5)
print(r) # 5
# 在向当前列表的右边插入
# rpush(列表, 值,值,...)
r = client.rpush("l2", 0, -1, -2, -3)
print(r) # 9
# 末尾删除,返回删除的元素
# 左边删除
# lpop(列表)
r = client.lpop("l2")
print(r) # b'5'
# 右边删除
# rpop(列表)
r = client.rpop("l2")
print(r) # b'-3'
# 修改:lset(列表, 位置, 修改的值)
r = client.lset("l2", 0, "30") # 将l2中0的位置上的元素修改为30
print(r) # True
# 插入元素,返回当前列表的个数
# linsert(列表, "before/after", "0"参考位置, 插入的值)
# l2中在0的前面插入0.5
r = client.linsert("l2", "before", "0", "0.5")
print(r) # 8
# l2中在0的后面插入-0.5
r = client.linsert("l2", "after", "0", "-0.5")
print(r) # 9
# 删除对应数量的值,返回删除的个数:lrem("l2", 数量, 值)
r = client.lrem("l2", 2, "-30") # 在l2中删除2个-30
print(r) # 2
# 保留列表指定范围内的元素,删除其他元素:ltrim(列表, start, end)
r = client.ltrim("l2", 2, 4)
print(r) # True
# 获取指定范围的元素:lrange("l2", start位置, end位置)
r = client.lrange("l2", 0, 100)
print(r) # [b'3', b'2', b'1']
# 获取对应位置的元素:lindex(列表, 位置)
r = client.lindex("l2", 5)
print(r) # None
# 释放连接
client.close()
总结
以上就是今天要讲的内容,本文介绍了redis的基础使用,而它具有快速的读写能力、灵活的数据模型和丰富的功能,愿每个人的心灵都能如同一座富饶的花园,种下智慧的种子,在岁月的浇灌下开出收获的芬芳。