目录
PaddleOCR 开源项目地址
一、数据集
1. 训练数据下载
2.数据集介绍
(1)PubTabNet数据集
(2) 好未来表格识别竞赛数据集
(3)WTW中文场景表格数据集
二、训练步骤
1.数据放置
2.环境配置
(1)PaddlePaddle框架安装
第一步:查看计算机平台版本
第二步、根据以下条件进行选择自动生成安装命令
(2)其他环境包安装
3.训练参数设置
4.启动训练
5.推理过程
三、踩坑记录
PaddleOCR 开源项目地址
PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices) (github.com)
一、数据集
1. 训练数据下载
PaddleOCR/doc/doc_ch/dataset/table_datasets.md at c27402bf1f012aeb54a98eb12ba98883eded502e · PaddlePaddle/PaddleOCR · GitHub

2.数据集介绍
(1)PubTabNet数据集
训练集合中包含50万张图像,验证集合中包含0.9万张图像 :https://github.com/ibm-aur-nlp/PubTabNet
(此次训练以 PubTabNet数据集为例)




数据格式如下所示:

{
'filename': PMC5755158_010_01.png, # 图像名
'split': ’train‘, # 图像属于训练集还是验证集
'imgid': 0, # 图像的index
'html': {
'structure': {'tokens': ['<thead>', '<tr>', '<td>', ...]}, # 表格的HTML字符串
'cells': [
{
'tokens': ['P', 'a', 'd', 'd', 'l', 'e', 'P', 'a', 'd', 'd', 'l', 'e'], # 表格中的单个文本
'bbox': [x0, y0, x1, y1] # 表格中的单个文本的坐标
}
]
}
}备注:PubTabNet_2.0.0.jsonl里面的label信息未将训练、验证数据集分开,如果有需要可以写脚本将其分开,或者训练过程中直接忽略掉读取错误的路径(图片读取文PaddleOCR-release-2.7/ppocr/data/pubtab_dataset.py)。
(2) 好未来表格识别竞赛数据集
识别竞赛数据集的训练集合中包含1.6万张图像。验证集未给出可训练的标注:https://ai.100tal.com/dataset
(3)WTW中文场景表格数据集
包含表格检测和表格数据两部分数据,数据集中同时包含扫描和拍照两张场景的图像:GitHub - wangwen-whu/WTW-Dataset: This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on table detection and table structure recognition.
二、训练步骤
1.数据放置
PaddleOCR-release-2.7/train_data/table/ 路径下(默认,可更改)
如果您的磁盘上已有数据集,只需创建软链接至数据集目录:
# linux and mac os
ln -sf <path/to/dataset> <path/to/paddle_ocr>/train_data/dataset
# windows
mklink /d <path/to/paddle_ocr>/train_data/dataset <path/to/dataset>2.环境配置
提示:可在python环境中进行安装,避免环境污染,创建命令conda create -n xxx_name python=3.9,激活conda activate xxx_name
(1)PaddlePaddle框架安装
第一步:查看计算机平台版本
在窗口输入查看命令,查看CUDA的版本
nvidia-smi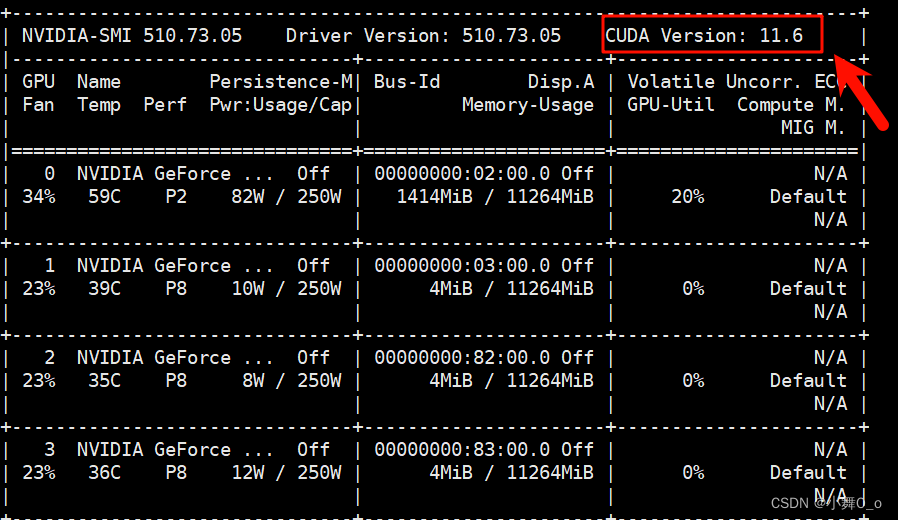
第二步、根据以下条件进行选择自动生成安装命令
快速安装路径:飞桨PaddlePaddle-源于产业实践的开源深度学习平台

(2)其他环境包安装
使用如下命令一键配置:
pip install -r requirements.txt3.训练参数设置
打开:PaddleOCR-release-2.7\configs\table\SLANet.yml
Global:
use_gpu: True #GPU是否使用
epoch_num: 100 #训练轮次
log_smooth_window: 20
print_batch_step: 20
save_model_dir: ./output/SLANet
save_epoch_step: 400
# evaluation is run every 1000 iterations after the 0th iteration
eval_batch_step: [0, 1000]
cal_metric_during_train: True
pretrained_model:
checkpoints:
save_inference_dir: ./output/SLANet/infer #保存路径
use_visualdl: False
infer_img: ppstructure/docs/table/table.jpg
# for data or label process
character_dict_path: ppocr/utils/dict/table_structure_dict.txt
character_type: en
max_text_length: &max_text_length 500
box_format: &box_format 'xyxy' # 'xywh', 'xyxy', 'xyxyxyxy'
infer_mode: False
use_sync_bn: True
save_res_path: 'output/infer'
d2s_train_image_shape: [3, -1, -1]
amp_custom_white_list: ['concat', 'elementwise_sub', 'set_value']
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
clip_norm: 5.0
lr:
name: Piecewise
learning_rate: 0.001
decay_epochs : [40, 50]
values : [0.001, 0.0001, 0.00005]
regularizer:
name: 'L2'
factor: 0.00000
Architecture:
model_type: table
algorithm: SLANet
Backbone:
name: PPLCNet
scale: 1.0
pretrained: true
use_ssld: true
Neck:
name: CSPPAN
out_channels: 96
Head:
name: SLAHead
hidden_size: 256
max_text_length: *max_text_length
loc_reg_num: &loc_reg_num 4
Loss:
name: SLALoss
structure_weight: 1.0
loc_weight: 2.0
loc_loss: smooth_l1
PostProcess:
name: TableLabelDecode
merge_no_span_structure: &merge_no_span_structure True
Metric:
name: TableMetric
main_indicator: acc
compute_bbox_metric: False
loc_reg_num: *loc_reg_num
box_format: *box_format
Train:
dataset:
name: PubTabDataSet
data_dir: train_data/table/pubtabnet/train/ #训练集路径
label_file_list: [train_data/table/pubtabnet/PubTabNet_2.0.0.jsonl] #标签文件路径
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- TableLabelEncode:
learn_empty_box: False
merge_no_span_structure: *merge_no_span_structure
replace_empty_cell_token: False
loc_reg_num: *loc_reg_num
max_text_length: *max_text_length
- TableBoxEncode:
in_box_format: *box_format
out_box_format: *box_format
- ResizeTableImage:
max_len: 488
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- PaddingTableImage:
size: [488, 488]
- ToCHWImage:
- KeepKeys:
keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
loader:
shuffle: True
batch_size_per_card: 16 # batch_size大小设置
drop_last: True
num_workers: 1
Eval:
dataset:
name: PubTabDataSet
data_dir: train_data/table/pubtabnet/val/ #训练集路径
label_file_list: [train_data/table/pubtabnet/PubTabNet_2.0.0.jsonl] #训练集路径标签文件路径
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- TableLabelEncode:
learn_empty_box: False
merge_no_span_structure: *merge_no_span_structure
replace_empty_cell_token: False
loc_reg_num: *loc_reg_num
max_text_length: *max_text_length
- TableBoxEncode:
in_box_format: *box_format
out_box_format: *box_format
- ResizeTableImage:
max_len: 488
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- PaddingTableImage:
size: [488, 488]
- ToCHWImage:
- KeepKeys:
keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
loader:
shuffle: False
drop_last: False
batch_size_per_card: 16 # batch_size大小设置
num_workers: 1
4.启动训练
#多卡训练,通过--gpus参数指定卡号
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/table/SLANet.yml服务器界面显示结果
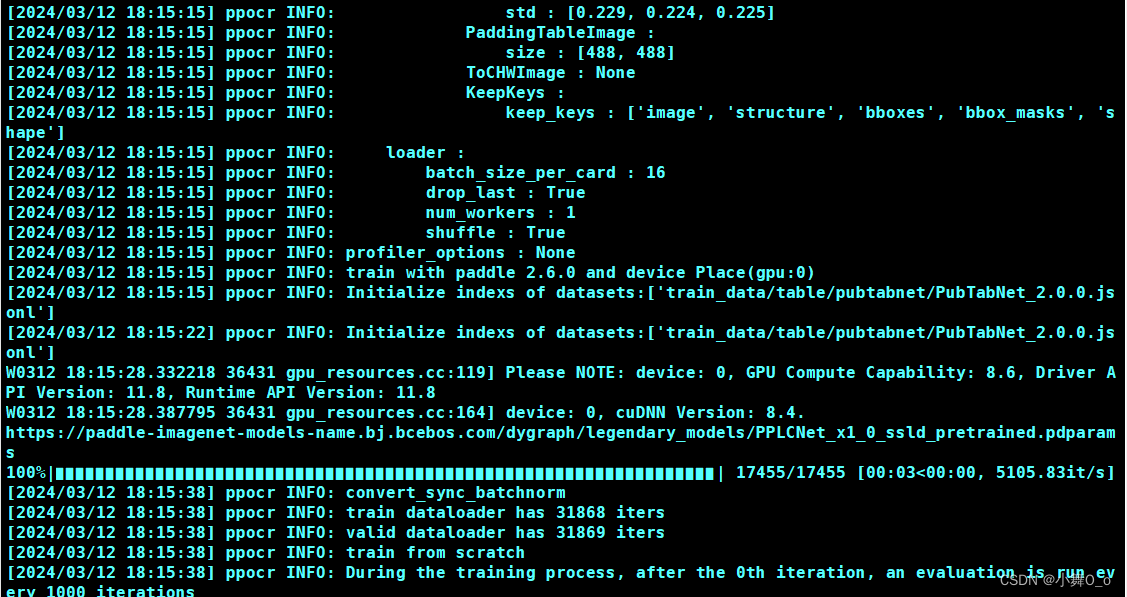
5.推理过程
# 预测表格图像
python3 tools/infer_table.py -c configs/table/SLANet.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=ppstructure/docs/table/table.jpg
推理结果保存至:PaddleOCR-release-2.7/output/infer/SLANet.json

三、踩坑记录
1.AttributeError: 'ParallelEnv' object has no attribute '_device_id'

解决方法:
paddle 2.6.0及以上版本中,应使用dist.get_world_size()代替dist.ParallelEnv().nranks,并且应使用dist.get_rank()代替dist.ParallelEnv().local_rank.
即定位到program.py的677行将内容更改成如下所示:

2.ImportError: libcudart.so.11.0: cannot open shared object file: No such file or directory

解决方法:
首先查看’ libcudart.so.11.0‘该文件是否存在:
【命令】 find 【路径】-name libcudart.so.11.0
例如: find /home/hadoop -name libcudart.so.11.0,结果显示:

选择结果中其中一个进行环境变量修改:
【命令】export LD_LIBRARY_PATH=/home/hadoop/xxx/data/lib:$LD_LIBRARY_PATH
【命令】source ~/.bashrc
重新运行Python,无错误显示即可
3.RuntimeError: (PreconditionNotMet) Cannot load cudnn shared library. Cannot invoke method cudnnGetVersion. [Hint: cudnn_dso_handle should not be null.] (at /paddle/paddle/phi/backends/dynload/cudnn.cc:64)
W0312 17:07:37.135784 19389 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver API Version: 11.8, Runtime API Version: 11.8
W0312 17:07:37.136477 19389 dynamic_loader.cc:314] The third-party dynamic library (libcudnn.so) that Paddle depends on is not configured correctly. (error code is /usr/local/cuda/lib64/libcudnn.so: cannot open shared object file: No such file or directory)
Suggestions:
1. Check if the third-party dynamic library (e.g. CUDA, CUDNN) is installed correctly and its version is matched with paddlepaddle you installed.
2. Configure third-party dynamic library environment variables as follows:
- Linux: set LD_LIBRARY_PATH by `export LD_LIBRARY_PATH=...`
- Windows: set PATH by `set PATH=XXX;
Traceback (most recent call last):
。。。。。。
packages/paddle/nn/initializer/initializer.py", line 40, in __call__
return self.forward(param, block)
File "/home/hadoop/anaconda3/envs/esrgan/lib/python3.9/site-packages/paddle/nn/initializer/kaiming.py", line 147, in forward
out_var = _C_ops.gaussian(
RuntimeError: (PreconditionNotMet) Cannot load cudnn shared library. Cannot invoke method cudnnGetVersion.
[Hint: cudnn_dso_handle should not be null.] (at /paddle/paddle/phi/backends/dynload/cudnn.cc:64)解决方法:
定位显示无法找到/usr/local/cuda/lib64/libcudnn.so文件

查找该文件的位置:
find -name libcudnn.so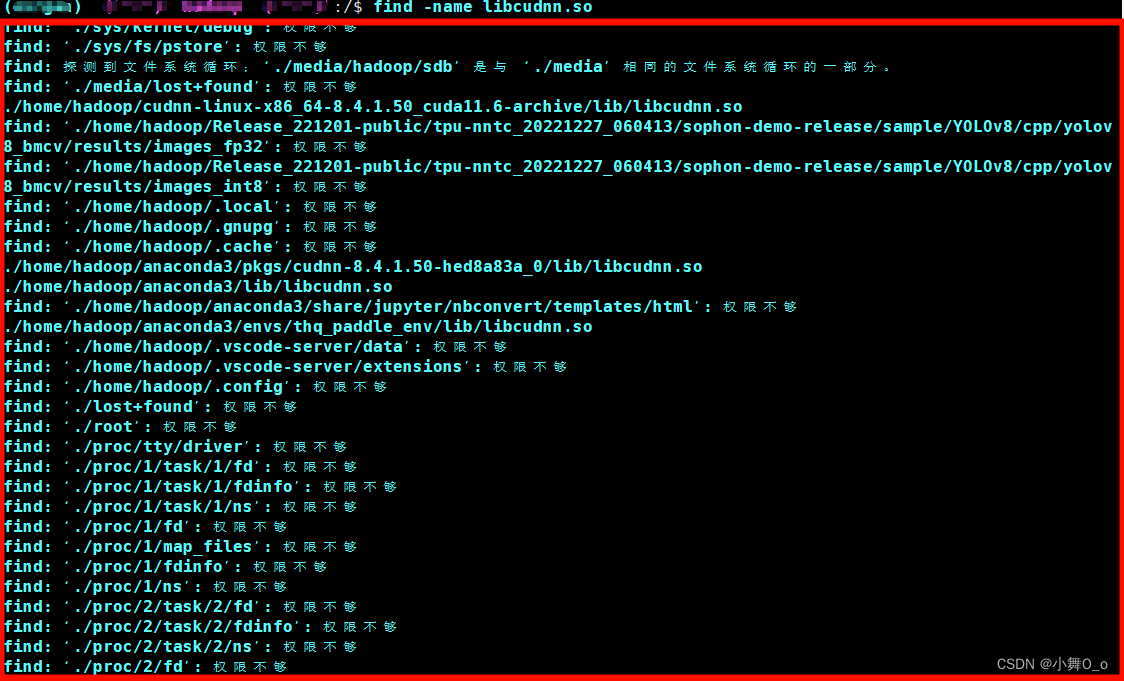
把缺失文件的库所在的lib路径,补充到LD_LIBRARY_PATH环境变量里面。找到该文件的位置,把库文件所在的路径(比如xxx/lib)加入LD_LIBRARY_PATH即可
export LD_LIBRARY_PATH=xxx/lib:$LD_LIBRARY_PATH
(上面方案为临时方案,每次在程序运行前设置环境变量。永久方案将环境变量添加到~/.bashrc文件,添加后需要关闭终端重新打开或者登录
echo "export LD_LIBRARY_PATH=xxx/lib">>~/.bashrc)
补充:常用的镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/simple/
上海交通大学:https://mirror.sjtu.edu.cn/pypi/web/simple/
豆瓣:http://pypi.douban.com/simple/
安装方式:
pip install <安装包> -i <镜像源>
例如: pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple/参考链接:解决paddlepaddle安装过程中遇到的ImportError: libcudart.so.10.2: cannot open shared object file: Nosuch file or-CSDN博客