目录
什么是Redis??
Redis有哪些使用场景?
Redis是单线程还是多线程?
为什么Redis是单线程速度还是很快??
Redis持久化
RDB机制:(Redis DataBase) [是redis中默认的持久化方式]
AOF机制:(Append Only File)
Redis和MySQL如何保持数据一致????
Redis事务
Redis与传统关系型数据库的区别:
Redis事务在Java中的运用:(Java代码中实现Redis的事务控制)
主从复制(Redis集群)
主从复制的作用??
redis哨兵机制
Key的过期删除策略
缓存穿透、缓存击穿、缓存雪崩
缓存穿透
缓存击穿
缓存雪崩
什么是Redis??
Redis是一款非关系型数据库,以键值对的形式存储在内存中,储存在内存中,读写的速度非常快,还支持多种数据类型,支持数据持久化
Redis有哪些使用场景?
1.缓存
访问量大的(秒杀、点赞)
修改少的(新闻类型、电商类型)
存储验证码(定时删除)
2.计数器(点赞)
3.排行榜(zset)
4.数据去重(set)
5.消息队列(list)
6.分布式锁(微服务)
Redis线程模型
Redis是单线程还是多线程?
6.0版本之前:只有一个线程处理事情(处理客户端的连接\读写功能)(线程安全)
6.0版本之后:引入了多线程
但这并不是说明Redis完全是多线程的
在网络请求过程中:多线程
在对兼职的读写时:单线程(依旧是线程安全的)
为什么Redis是单线程速度还是很快??
- Redis基于内存操作,运算为内存级别,故性能很高
- Redis底层是hash结构 ==> 时间复杂度为O(1),可以通过key(计算hash值)快速定位
- 单线程设计避免线程切换(防止切换线程开销),也不会导致死锁问题
Redis持久化
众所周知Redis是基于内存操作的,那么如果有一天突然断电了,那么Redis里的数据岂不是都没有了?基于这个问题,Redis推出了持久化的机制:
RDB机制:(Redis DataBase) [是redis中默认的持久化方式]
以快照的方式,将某一时刻Redis中的数据保存到一个.rdb文件中 
可以在redis.conf中修改触发条件:
save(同步机制):这是用来配置触发Redis的RDB持久化条件(即什么时候将内存中的数据持久化到硬盘中), 如:"save m n" 表示每m秒内,如果数据修改了n次或n次以上时,自动触发bgsave(存储)
save 60 2 :表示60秒内如果redis中的数据被修改了2次或以上,则进行快照
这时如果不需要持久化,将save所在的行全部注释,就不会进行持久化了
(注意:这里注释的时候需要在该行前面加'# ')
AOF机制:(Append Only File)
以日志的形式,将你进行的写操作(增、删、改)的命令记录下来
恢复时,逐行执行命令即可恢复数据
如果想要使用AOF机制,需要再配置文件中开启:
在redis.conf中找到appendonly no,并将其改为yes开启
appendfilename ==> 指定日志记录文件(的名字) 默认为 appendonly.aof
每次配置修改后,都需重启redis才会生效
同步机制: (默认:appendfsync everysec)
appendfsync always #每一次修改都会sync, 缺点:消耗性能
appendfsync everysec #每秒执行一次sync 缺点:如果1s内多次修改,可能会丢失数据
Redis和MySQL如何保持数据一致????
解决方式一:更新完MySQL后,立即去更新Redis
问题:万一更新Redis失败(e.g:Redis连接断开),会导致数据更新失败。
解决方式二:先删除Redis中的数据,然后更新MySql,有查询到来时Redis会从MySQL中查询
问题:删除Redis后,更新MySQL中的事务还没有提交,这时如果有新来的请求访问,查询出来的还是原来的数据。
解决方式三:延时双删机制:先删除Redis,再更新MySql,延迟几百毫秒之后再次删除Redis
解决了方案二中,MySQL提交事务之前,Redis查询数据后,以后访问过来还是原数据的问题
这时后方再有查询过来时,redis会从数据库中重新查询当前的新值。
Redis事务
Redis与传统关系型数据库的区别:
Redis事务中,同一个事物中的命令不会相互影响
不支持roll back(回滚)
不支持复杂的事务管理(嵌套事务、并发控制等)
优点: 高性能(基于内存的数据存储)
简单的操作命令: mutil(开启事务) set 1 set 2 exec(执行事务)
灵活的数据类型(Redis支持多种数据类型,如字符串、列表、集合、散列等)
Redis事务本质上是一组命令的集合,一个事务中所有命令都会序被列化,在事务执行过程中,会按照顺序执行。事务添加命令后,该命令不会立即执行,在执行exec命令时,才回执行此实物中的所有命令.
值得注意的是:与传统关系型数据库不同,Redis事务中不保证多条命令执行的原子性,即:Redis事务只负责将这几条命令打包放在一起,无所谓他们正确与否,即使其中有命令报错也不影响其他命令的执行结果。
Redis事务在Java中的运用:(Java代码中实现Redis的事务控制)
@Autowired
RedisTemplate redisTemplate;
public static void main(String[] args) {
redisTemplate.multi();//开启Redis事务
//命令一
//命令二
//命令三
redisTemplate.exec();//执行Redis事务
}主从复制(Redis集群)
主从复制,是指将一台Redis服务器的数据,复制到其他Redis服务器,前者称之为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能从主节点到从节点
一台Redis作为主机,其他redis服务作为从机,一主多从,这样即使其中一台宕机,其余还可正常运行,保证数据的完整性,写入命令时,发送命令到主机,主机执行后将自动备份到从机,进而达到读写分离,分担redis服务的压力。
(人话:主机可以进行增删改查,从机只有两个操作:从主机处获取数据,进行读操作)
主从复制的作用??
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用(集群)基石:除了上述作用以外,主从复制还是哨兵和陳群能够实施的基础,因此说主从复制是Redis高可用的基础。
redis哨兵机制
现在我们都知道了主从复制是为了分担redis服务的,如果其中有一台服务器宕机,其余还可正常运行,那么如果是主机宕机了,我们又该作何处理呢??
- 对主机和从机进行监控:哨兵系统能够监控Redis主机和从机的运行状态,包括是否正常运行、是否能够响应命令等。
- 向管理员发起通知:当某个节点出现问题时,哨兵可以通过API向管理员发送通知。
- 解决主机宕机问题:一旦主机宕机,哨兵机制会从剩余从机中选举一个当做主机,确保了系统的连续运行和数据的一致性
Key的过期删除策略
惰性删除:
当key过期后,标记为过期状态(字典,记录过期key),下次使用时再删除
缺:如果一个key长时间未被访问,即使它已经过期,也不会被删除,可能会导致内存的浪费。
定期删除:
在设定的时间节点,去扫描过期的key,删除过期key。
缺点:可能会在大量key同时过期时造成卡顿现象。
Redis操作时是两者结合的,具体是怎么操作的我在这里就不赘述了,如果有想深入了解的可以看大佬的:redis中key的过期键删除策略
缓存穿透、缓存击穿、缓存雪崩
前台请求时,数据查询的处理流程:
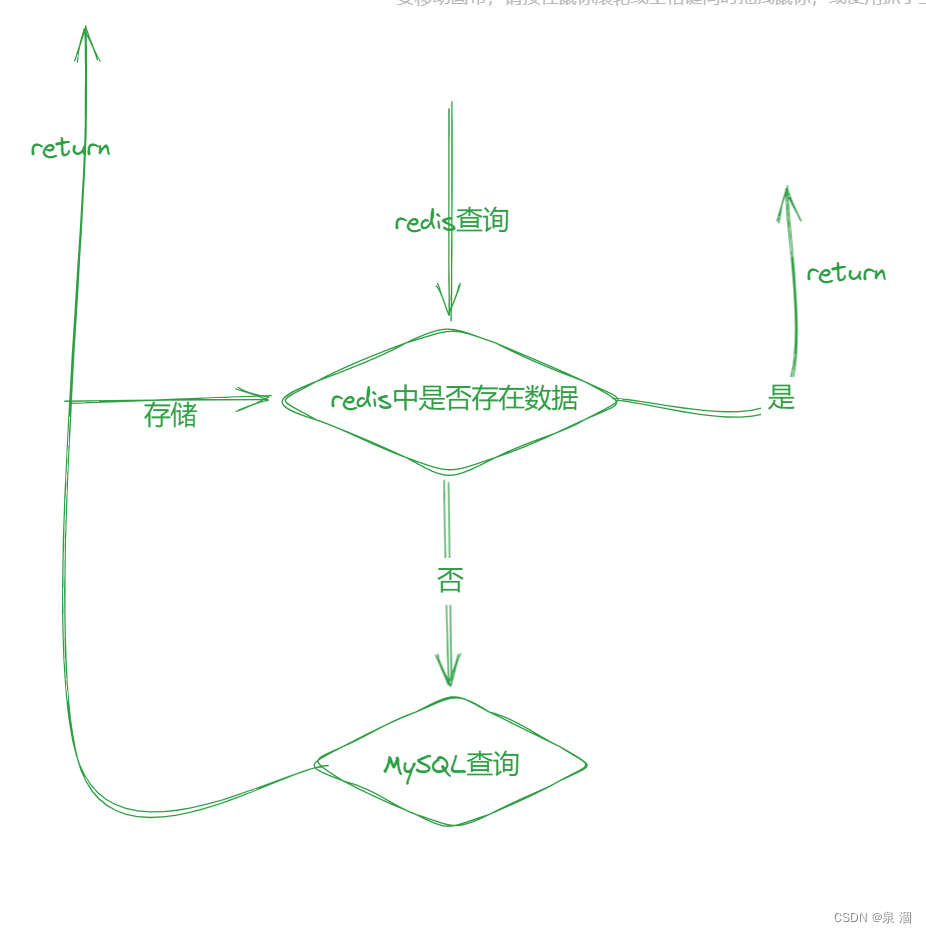
理解了数据查询时的处理流程,接下来让我们一同走进缓存高并发时常见的三大难题:
缓存穿透
key对应的数据在数据库中不存在,如果我们查询Redis时,该数据在Redis中不存在,那么该请求还是会去访问数据库,如果有大量的这种请求访问过来,有可能压垮数据库
解决方法:
1.添加参数验证
e.g: id肯定是integer类型,如果有人恶意访问 ?id='abc',这时肯定不可能查到该条数据
我们可以在后端添加一条验证 :if( id instanceof Integer) ,如果不符合条件,直接忽略此次请求或者返回return false;
2.设置key-null
e.g: 如果对方想要查找key为'abc'的数据,但是后端数据库中没有这条数据,可以在Redis中设置一个键值对:{ 'abc' , null } 这样,对方再次访问过来时,直接return null就行,同样不会造成缓存穿透
缓存击穿
key对应的数据在数据库中存在,但是在redis某一个时间节点恰好过期了,此时如果有大量的并发请求过来,这些请求发现缓存过期后,都会从数据库中加载该数据,这时候也有可能会压垮数据库.
解决方法:
1.灵活设置key过期时间
在设置key过期时间时,设置不要再访问量大的时候过期
2.加互斥锁
给该查询加一个互斥锁,这样去MySQL中查询时,可以确保同一时间只有一个请求去访问MySQL,其余请求只能等所释放了以后才能进
缓存雪崩
在高并发情况下,有大量的缓存失效(或者缓存层出现故障),造成大量请求到达数据库,导致数据库的调用量暴增,甚至可能导致数据库宕机。
解决办法:
1.避免缓存集体失效
设置随机过期时间,可有效避免大量key同时过期。
2.集成redis集群
将热点数据均匀分布再不同的Redis中,同样可以避免key同时失效的问题
3.设置定时任务
设置在缓存失效之前,重新设置过期时间。