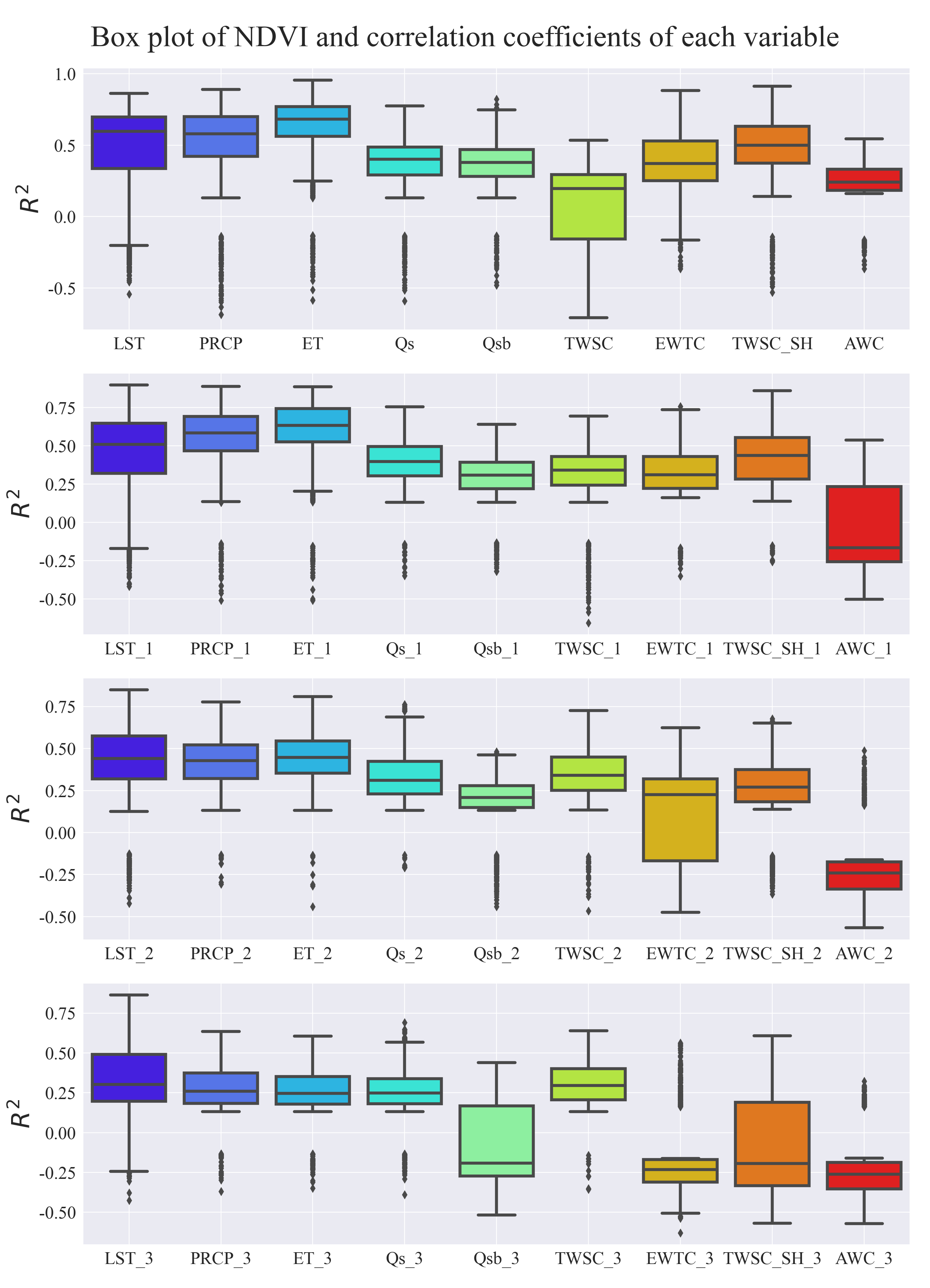
想在Python 代码中运行时下载模型,启动代理服务器客户端后
1. 检查能否科学上网
$ curl -x socks5h://127.0.0.1:1080 https://www.example.com
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
2. 用 Python 代码检验
test_proxy.py :
import requests
url1 = 'https://www.example.com'
url2 = 'https://huggingface.co/'
proxies = {
'http': 'socks5h://localhost:1080',
'https': 'socks5h://localhost:1080'
}
try:
response = requests.get(url1, proxies=proxies)
if response.status_code == 200:
print("成功连接到代理服务器并获取数据!")
print("响应内容:", response.text)
else:
print("连接到代理服务器失败。请检查代理设置和网络连接。")
except requests.exceptions.RequestException as e:
print("请求发生异常:", str(e))
输出结果:
成功连接到代理服务器并获取数据!
响应内容: <!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
Process finished with exit code 0
成功连接
3. 运行下载模型的代码
download_model.py
import os
import json
import requests
from uuid import uuid4
from tqdm import tqdm
proxies = {
'http': 'socks5h://localhost:1080',
'https': 'socks5h://localhost:1080'
}
#使用uuid4()函数生成一个唯一的会话ID,用于在请求的标头中加以标识
SESSIONID = uuid4().hex
VOCAB_FILE = "vocab.txt"
CONFIG_FILE = "config.json"
MODEL_FILE = "pytorch_model.bin"
BASE_URL = "https://huggingface.co/{}/resolve/main/{}"
headers = {'user-agent': 'transformers/4.38.2; python/3.11.8; \
session_id/{}; torch/2.2.1; tensorflow/2.15.0; \
file_type/model; framework/pytorch; from_auto_class/False'.format(SESSIONID)}
model_id = "distilbert-base-uncased-finetuned-sst-2-english"
# 创建模型对应的文件夹
model_dir = model_id.replace("/", "-")
print(model_dir)
if not os.path.exists(model_dir):
os.mkdir(model_dir)
# vocab 和 config 文件可以直接下载
# 使用requests.get()函数向Hugging Face的API发送GET请求来下载词典文件和配置文件
r = requests.get(BASE_URL.format(model_id, VOCAB_FILE), headers=headers,proxies=proxies)
r.encoding = "utf-8"
with open(os.path.join(model_dir, VOCAB_FILE), "w", encoding="utf-8") as f:
# print(r.text)
f.write(r.text)
print("{}词典文件下载完毕!".format(model_id))
r = requests.get(BASE_URL.format(model_id, CONFIG_FILE), headers=headers,proxies=proxies)
r.encoding = "utf-8"
with open(os.path.join(model_dir, CONFIG_FILE), "w", encoding="utf-8") as f:
# print(r.status_code)
# print(r.text)
json.dump(r.json(), f, indent="\t")
print("{}配置文件下载完毕!".format(model_id))
# 模型文件需要分两步进行
# Step1 获取模型下载的真实地址
r = requests.head(BASE_URL.format(model_id, MODEL_FILE), headers=headers,proxies=proxies)
r.raise_for_status()
if 300 <= r.status_code <= 399:
url_to_download = r.headers["Location"]
# Step2 请求真实地址下载模型
# stream=True 启用逐块下载模式,响应内容将被分成多个小块进行下载
r = requests.get(url_to_download, stream=True,headers=None,proxies=proxies)
r.raise_for_status()
# 这里的进度条是可选项,直接使用了transformers包中的代码
# headers.get()方法从响应头中获取"Content-Length"字段的值。"Content-Length"表示下载文件的总大小,以字节为单位。
content_length = r.headers.get("Content-Length")
total = int(content_length) if content_length is not None else None
"""
参数unit="B"表示进度条以字节为单位。
unit_scale=True将自动调整进度条的单位以便更好地显示,例如,以KB、MB或GB为单位。
total参数设置进度条的总大小。initial=0表示进度条的初始值为0。
desc="Downloading Model"是进度条的描述,用于显示在进度条前面"""
progress = tqdm(
unit="B",
unit_scale=True,
total=total,
initial=0,
desc="Downloading Model",
)
"""
使用iter_content()方法以指定的块大小(这里是1024字节)迭代下载的内容。
每次迭代,将一个块的内容存储在chunk变量中。
在每个块的迭代过程中,首先通过条件if chunk过滤掉空的块,以排除保持连接的新块。"""
with open(os.path.join(model_dir, MODEL_FILE), "wb") as temp_file:
for chunk in r.iter_content(chunk_size=1024):
if chunk: # filter out keep-alive new chunks
progress.update(len(chunk))
temp_file.write(chunk)
progress.close()
print("{}模型文件下载完毕!".format(model_id))
速度还是可以的:

如果想运行pipeline 代码:
text_classification = pipeline("text-classification")
会出现:
No model was supplied, defaulted to distilbert/distilbert-base-uncased-finetuned-sst-2-english and revision af0f99b (https://hf-mirror.com/distilbert/distilbert-base-uncased-finetuned-sst-2-english).
Using a pipeline without specifying a model name and revision in production is not recommended.
这时把上面改上面代码:
model_id = "distilbert-base-uncased-finetuned-sst-2-english"
4. 运行 pipeline 代码
pipeline.py
from transformers import pipeline
import urllib.request
print(urllib.request.getproxies())
text_classification = pipeline("text-classification")
result = text_classification("Hello, world!")
print(result)
结果报错:
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/wxf/PycharmProjects/llm/pipe.py", line 21, in <module>
text_classification = pipeline("text-classification")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wxf/lib/anaconda/envs/transformers/lib/python3.11/site-packages/transformers/pipelines/__init__.py", line 879, in pipeline
config = AutoConfig.from_pretrained(model, _from_pipeline=task, **hub_kwargs, **model_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wxf/lib/anaconda/envs/transformers/lib/python3.11/site-packages/transformers/models/auto/configuration_auto.py", line 1111, in from_pretrained
config_dict, unused_kwargs = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wxf/lib/anaconda/envs/transformers/lib/python3.11/site-packages/transformers/configuration_utils.py", line 633, in get_config_dict
config_dict, kwargs = cls._get_config_dict(pretrained_model_name_or_path, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wxf/lib/anaconda/envs/transformers/lib/python3.11/site-packages/transformers/configuration_utils.py", line 688, in _get_config_dict
resolved_config_file = cached_file(
^^^^^^^^^^^^
File "/home/wxf/lib/anaconda/envs/transformers/lib/python3.11/site-packages/transformers/utils/hub.py", line 441, in cached_file
raise EnvironmentError(
OSError: We couldn't connect to 'https://hf-mirror.com' to load this file, couldn't find it in the cached files and it looks like distilbert/distilbert-base-uncased-finetuned-sst-2-english is not the path to a directory containing a file named config.json.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
代码 /home/wxf/lib/anaconda/envs/transformers/lib/python3.11/site-packages/transformers/configuration_utils.py
改成:
resolved_config_file = cached_file(
pretrained_model_name_or_path,
configuration_file,
cache_dir=cache_dir,
force_download=force_download,
proxies={
'http': 'socks5h://localhost:1080',
'https': 'socks5h://localhost:1080'
},
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_commit_hash=commit_hash,
)
然后运行结果:
No model was supplied, defaulted to distilbert/distilbert-base-uncased-finetuned-sst-2-english and revision af0f99b (https://hf-mirror.com/distilbert/distilbert-base-uncased-finetuned-sst-2-english).
Using a pipeline without specifying a model name and revision in production is not recommended.
[{'label': 'POSITIVE', 'score': 0.9997164607048035}]
5. 参考
- huggingface transformers预训练模型如何下载至本地,并使用?
- 国内用户 HuggingFace 高速下载
- huggingface transformers预训练模型如何下载至本地,并使用?
- Huggingface的from pretrained的下载代理服务器方法设置