作者:来自 Elastic Kathleen DeRusso
本博客讨论了 ELSER 性能的令人兴奋的新增强功能,该增强功能即将在 Elasticsearch 的下一版本中推出!
标记(token)修剪背后的策略
我们已经详细讨论了 Elasticsearch 中的词汇和语义搜索以及使用向量字段的文本相似性搜索。 这些文章对向量搜索的工作原理提供了精彩、深入的解释。
我们过去还讨论过通过使用 ELSER v2 优化检索来降低检索成本。 虽然 Elasticsearch 限制为每个推理字段 512 个标记,但 ELSER 仍然可以为多术语查询生成大量唯一标记。 这会导致非常大的析取查询(disjunction query),并且将返回比单个关键字搜索更多的文档 - 事实上,具有大量结果查询的查询可能会匹配索引中的大多数或全部文档!

现在,让我们更详细地了解使用 ELSER v2 的示例。 使用 infer API,我们可以查看短语 “Is Pluto a planet?” 的预测值。
POST /_ml/trained_models/.elser_model_2_linux-x86_64/_infer
{
"docs":[{"text_field": "is Pluto a planet?"}]
}这将返回以下推理结果:
{
"inference_results": [
{
"predicted_value": {
"pluto": 3.014208,
"planet": 2.6253395,
"planets": 1.7399588,
"alien": 1.1358738,
"mars": 0.8806293,
"genus": 0.8014013,
"europa": 0.6215426,
"a": 0.5890018,
"asteroid": 0.5530223,
"neptune": 0.5525891,
"universe": 0.5023148,
"venus": 0.47205976,
"god": 0.37106854,
"galaxy": 0.36435634,
"discovered": 0.3450894,
"any": 0.3425274,
"jupiter": 0.3314228,
"planetary": 0.3290833,
"particle": 0.30925226,
"moon": 0.29885328,
"earth": 0.29008925,
"geography": 0.27968466,
"gravity": 0.26251012,
"astro": 0.2522782,
"biology": 0.2520054,
"aliens": 0.25142986,
"island": 0.25103575,
"species": 0.2500962,
"uninhabited": 0.23360424,
"orbit": 0.2327767,
"existence": 0.21717428,
"physics": 0.2001011,
"nuclear": 0.1603676,
"space": 0.15076339,
"asteroids": 0.14343098,
"astronomy": 0.10858688,
"ocean": 0.08870865,
"some": 0.065543786,
"science": 0.051665734,
"satellite": 0.042373143,
"ari": 0.024783766,
"list": 0.019822711,
"poly": 0.018234596,
"sphere": 0.01611787,
"dino": 0.006902895,
"rocky": 0.0062791444
}
}
]
}这些是将作为文本扩展搜索的输入发送的推理结果。 当我们运行文本扩展查询时,这些术语最终会在一个大型加权布尔查询中连接在一起,例如:
{
"query": {
"bool": {
"should": [
{
"match": {
"pluto": {
"query": "pluto",
"boost": 3.014208
}
}
},
{
"match": {
"planet": {
"query": "planet",
"boost": 2.6253395
}
}
},
...
{
"match": {
"planets": {
"query": "dino",
"boost": 0.006902895
}
}
},
{
"match": {
"planets": {
"query": "rocky",
"boost": 0.0062791444
}
}
}
]
}
}
}通过删除标记来加快速度
鉴于 ELSER 文本扩展产生大量标记,实现性能改进的最快方法是减少进入最终布尔查询的标记数量。 这减少了 Elasticsearch 在执行搜索时投入的总工作量。 我们可以通过识别文本扩展产生的非重要标记并将它们从最终查询中删除来实现这一点。
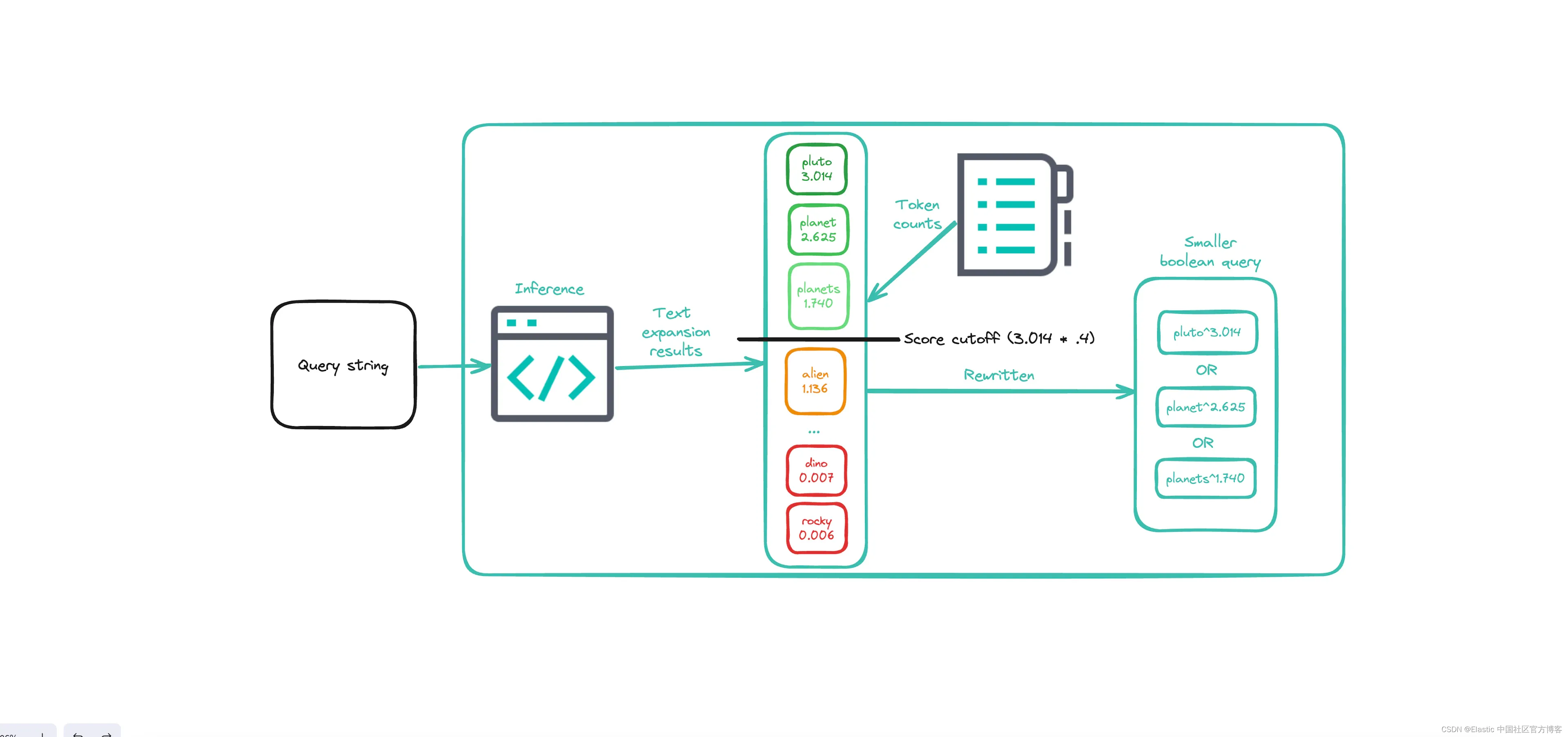
非重要令牌可以定义为满足以下两个条件的令牌:
- 权重/分数太低,以至于该标记可能与原始术语不太相关
- 该标记比大多数标记出现的频率要高得多,表明它是一个非常常见的单词,可能不会对整体搜索结果带来太大好处。
基于使用 ELSER v2 的内部实验,我们从一些默认规则开始识别不重要的标记:
- 频率:比该领域所有标记的平均标记频率高出 5 倍以上
- 得分:低于最佳得分标记的 40%
- 缺失:如果我们看到频率为 0 的文档,则意味着它根本不会出现,可以安全地修剪
如果你将文本扩展与 ELSER 以外的模型一起使用,则可能需要调整这些值才能返回最佳结果。
标记频率阈值和权重阈值都必须显示标记不重要,以便对标记进行修剪。 这可以让我们确保保留得分非常高的频繁标记或得分可能不那么高的非常罕见的标记。
性能改进
我们使用 MS Marco Passage Ranking 基准对这些变化进行基准测试。 通过此基准测试,我们观察到,使用上述默认值启用标记修剪可使第 99 个 pctile 延迟提高 3-4 倍!
相关性影响
一旦我们测量到了真正的性能改进,我们就想验证相关性仍然是合理的。 我们使用一个小数据集来对抗 MS Marco 通道排名数据集。 我们确实观察到修剪标记时对相关性的影响; 然而,当我们将修剪后的标记添加回重新评分块中时,相关性接近于原始的未修剪结果,而延迟仅略有增加。 重新评分会添加先前修剪的标记,仅针对从先前查询返回的文档查询修剪的标记。 然后它会更新分数,包括之前留下的维度。
使用包含 44 个查询的样本,并对 MS Marco Passage Ranking 数据集进行判断:
| Top K | Num Candidates | Avg rescored recall vs control | Control NDCG@K | Pruned NDCG@K | Rescored NDCG@K |
|---|---|---|---|---|---|
| 10 | 10 | 0.956 | 0.653 | 0.657 | 0.657 |
| 10 | 100 | 1 | 0.653 | 0.657 | 0.653 |
| 10 | 1000 | 1 | 0.653 | 0.657 | 0.653 |
| 100 | 100 | 0.953 | 0.51 | 0.372 | 0.514 |
| 100 | 1000 | 1 | 0.51 | 0.372 | 0.51 |
现在,这只是一个数据集 - 但即使在较小的规模上看到这一点也是令人鼓舞的!
如何使用
修剪配置将在我们的下一个版本中作为实验性功能推出。 这是一项可选的选择加入功能,因此如果你在不指定修剪的情况下执行文本扩展查询,则文本扩展查询的制定方式不会发生任何变化 - 并且性能也不会发生变化。
我们在文本扩展查询文档中提供了一些如何使用新修剪配置的示例。
下面是一个包含修剪配置和重新评分的文本扩展查询示例:
GET my-index/_search
{
"query":{
"text_expansion":{
"ml.tokens":{
"model_id":".elser_model_2",
"model_text":"Is pluto a planet?"
},
"pruning_config": {
"tokens_freq_ratio_threshold": 5,
"tokens_weight_threshold": 0.4,
"only_score_pruned_tokens": false
}
}
},
"rescore": {
"window_size": 100,
"query": {
"rescore_query": {
"text_expansion": {
"ml.tokens": {
"model_id": ".elser_model_2",
"model_text": "Is pluto a planet?"
},
"pruning_config": {
"tokens_freq_ratio_threshold": 5,
"tokens_weight_threshold": 0.4,
"only_score_pruned_tokens": false
}
}
}
}
}
}请注意,重新评分查询将 only_score_pruned_tokens 设置为 false,因此它仅将那些最初修剪的标记添加回重新评分算法中。
加权标记查询 - weighted tokens queries
我们还引入了新的加权标记查询
这种新查询类型有两个主要用例:
- 在查询时发送你自己的预先计算的推理,而不是使用推理 API
- 快速原型设计,因此你可以尝试更改(例如修剪配置!)
用法相同:
GET my-index/_search
{
"query":{
"weighted_tokens": {
"query_expansion_field": {
"tokens": {"pluto":3.014208,"planet":2.6253395,"planets":1.7399588,"alien":1.1358738,"mars":0.8806293,"genus":0.8014013,"europa":0.6215426,"a":0.5890018,"asteroid":0.5530223,"neptune":0.5525891,"universe":0.5023148,"venus":0.47205976,"god":0.37106854,"galaxy":0.36435634,"discovered":0.3450894,"any":0.3425274,"jupiter":0.3314228,"planetary":0.3290833,"particle":0.30925226,"moon":0.29885328,"earth":0.29008925,"geography":0.27968466,"gravity":0.26251012,"astro":0.2522782,"biology":0.2520054,"aliens":0.25142986,"island":0.25103575,"species":0.2500962,"uninhabited":0.23360424,"orbit":0.2327767,"existence":0.21717428,"physics":0.2001011,"nuclear":0.1603676,"space":0.15076339,"asteroids":0.14343098,"astronomy":0.10858688,"ocean":0.08870865,"some":0.065543786,"science":0.051665734,"satellite":0.042373143,"ari":0.024783766,"list":0.019822711,"poly":0.018234596,"sphere":0.01611787,"dino":0.006902895,"rocky":0.0062791444},
"pruning_config": {
"tokens_freq_ratio_threshold": 5,
"tokens_weight_threshold": 0.4,
"only_score_pruned_tokens": false
}
}
}
},
"rescore": {
"window_size": 100,
"query": {
"rescore_query": {
"weighted_tokens": {
"query_expansion_field": {
"tokens": {"pluto":3.014208,"planet":2.6253395,"planets":1.7399588,"alien":1.1358738,"mars":0.8806293,"genus":0.8014013,"europa":0.6215426,"a":0.5890018,"asteroid":0.5530223,"neptune":0.5525891,"universe":0.5023148,"venus":0.47205976,"god":0.37106854,"galaxy":0.36435634,"discovered":0.3450894,"any":0.3425274,"jupiter":0.3314228,"planetary":0.3290833,"particle":0.30925226,"moon":0.29885328,"earth":0.29008925,"geography":0.27968466,"gravity":0.26251012,"astro":0.2522782,"biology":0.2520054,"aliens":0.25142986,"island":0.25103575,"species":0.2500962,"uninhabited":0.23360424,"orbit":0.2327767,"existence":0.21717428,"physics":0.2001011,"nuclear":0.1603676,"space":0.15076339,"asteroids":0.14343098,"astronomy":0.10858688,"ocean":0.08870865,"some":0.065543786,"science":0.051665734,"satellite":0.042373143,"ari":0.024783766,"list":0.019822711,"poly":0.018234596,"sphere":0.01611787,"dino":0.006902895,"rocky":0.0062791444},
"pruning_config": {
"tokens_freq_ratio_threshold": 5,
"tokens_weight_threshold": 0.4,
"only_score_pruned_tokens": true
}
}
}
}
}
}
}此功能将在即将推出的 Elastic stack 版本中作为技术预览功能发布。 你可以先睹为快,使用我们 main 分支的最新版本,或者一旦发布,你就可以在云中试用! 请务必前往我们的讨论论坛并让我们知道你的想法。
原文:Improving text expansion performance using token pruning — Elastic Search Labs