文章目录
- 数据库和数据仓库的区别
- Hive安装配置
- Hive使用方式
- Hive日志配置
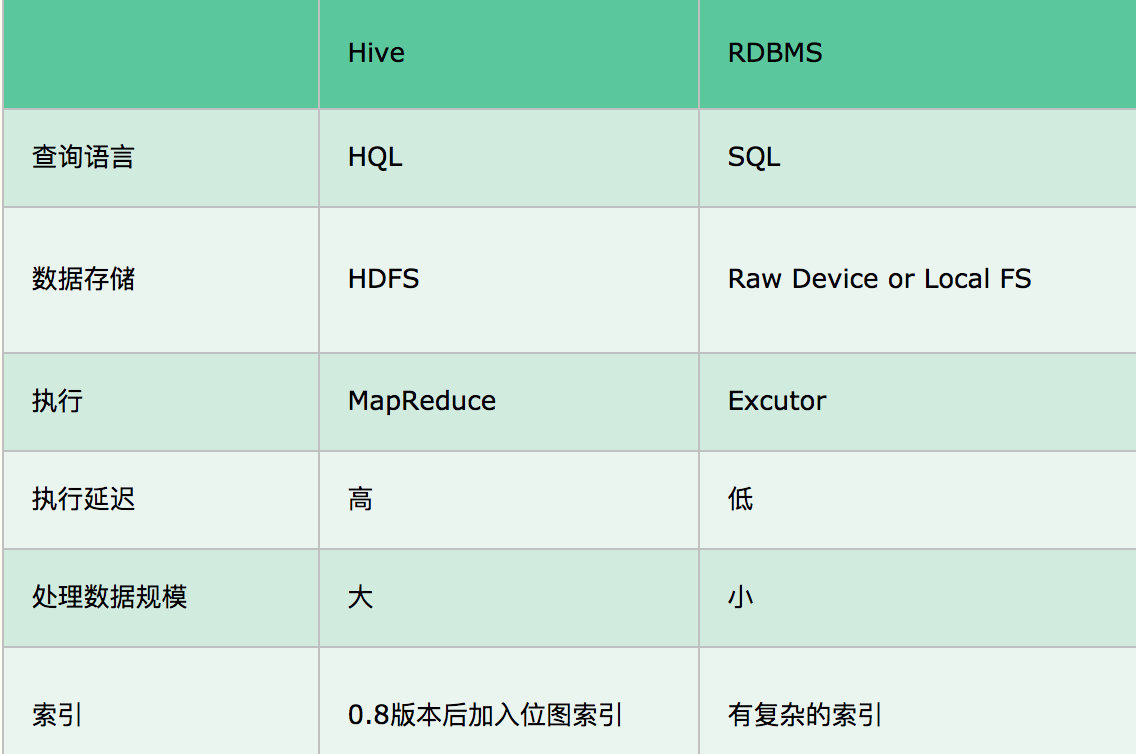
数据库和数据仓库的区别
- 数据库:传统的关系型数据库主要应用在基本的事务处理,比如交易,支持增删改查
- 数据仓库:主要做一些复杂的分析操作,侧重决策支持,相对于数据库而言,数据仓库分析的数据规模要大的多,只支持查询
- 本质区别是OLTP(On-Line-Transaction Processing)和OLAP(On-Line-Analytical Processing)的区别,OLTP称为联机事务处理,也是面向交易的处理系统,它是针对具体的业务在数据库联机的日常操作,通常对少数记录进行查询、修改,用户关心的是响应;时间,数据的安全性,完整性等问题;OLAP是分析性处理,称为联机分析处理,一般针对某些主题历史数据进行分析,支持管理决策
Hive安装配置
# 解压完之后
[root@hadoop04 conf]# mv hive-env.sh.template hive-env.sh
[root@hadoop04 conf]# mv hive-default.xml.template hive-site.xml
#修改配置
[root@hadoop04 conf]# vim hive-env.sh
export JAVA_HOME=/home/soft/jdk1.8
export HIVE_HOME=/home/soft/apache-hive-3.1.2
export HADOOP_HOME=/home/soft/hadoop-3.2.0
# 根据name修改对应配置
[root@hadoop04 conf]# vim hive-site.xml
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive_repo/scratchdir</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hive_repo/resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://ip:port/hive?serverTimezone=Asia/Shanghai</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
# 初始化数据仓库
[root@hadoop04 apache-hive-3.1.2]# bin/schematool -dbType mysql -initSchema
# 看到有下面那些表就算完成啦
Hive使用方式
命令行方式
# 连接hive
[root@hadoop04 apache-hive-3.1.2]# bin/hive
which: no hbase in (/home/soft/jdk1.8/bin:/home/soft/hadoop-3.2.0/bin:/home/soft/hadoop-3.2.0/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/soft/apache-hive-3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/soft/hadoop-3.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 505baa88-4bd1-4f00-9345-448ae17ab151
Logging initialized using configuration in jar:file:/home/soft/apache-hive-3.1.2/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Hive Session ID = dfffb77e-23d3-4c56-9457-32f30b5f4e3c
# 查询
hive> show tables;
OK
Time taken: 1.019 seconds
# 建表
hive> create table t1(id int,name string);
OK
Time taken: 1.875 seconds
hive> show tables;
OK
t1
Time taken: 0.388 seconds, Fetched: 1 row(s)
# 插入数据 会进行mapreduce
hive> insert into t1(id,name)values(1,"test");
Query ID = root_20240311140339_1e1450d1-2227-4b3d-bb10-e21f0016903b
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1710135432246_0001, Tracking URL = http://hadoop01:8088/proxy/application_1710135432246_0001/
Kill Command = /home/soft/hadoop-3.2.0/bin/mapred job -kill job_1710135432246_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2024-03-11 14:04:00,036 Stage-1 map = 0%, reduce = 0%
2024-03-11 14:04:08,605 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.66 sec
2024-03-11 14:04:16,949 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.69 sec
MapReduce Total cumulative CPU time: 4 seconds 690 msec
Ended Job = job_1710135432246_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop01:9000/user/hive/warehouse/t1/.hive-staging_hive_2024-03-11_14-03-39_724_266361142260875320-1/-ext-10000
Loading data to table default.t1
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.69 sec HDFS Read: 15158 HDFS Write: 236 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 690 msec
OK
Time taken: 42.328 seconds
hive> select * from t1;
OK
1 test
Time taken: 0.726 seconds, Fetched: 1 row(s)
hive> drop table t1;
OK
Time taken: 1.368 seconds
# 退出
hive> quit;
Hive日志配置
运行时日志
[root@hadoop04 conf]# mv hive-log4j2.properties.template hive-log4j2.properties
[root@hadoop04 conf]# vim hive-log4j2.properties
# list of properties
property.hive.log.level = INFO
property.hive.root.logger = DRFA
property.hive.log.dir = /home/hive_repo/log
property.hive.log.file = hive.log
property.hive.perflogger.log.level = INFO
任务执行日志
[root@hadoop04 conf]# mv hive-exec-log4j2.properties.template hive-exec-log4j2.properties
[root@hadoop04 conf]# vim hive-exec-log4j2.properties
status = INFO
name = HiveExecLog4j2
packages = org.apache.hadoop.hive.ql.log
# list of properties
property.hive.log.level = INFO
property.hive.root.logger = FA
property.hive.query.id = hadoop
property.hive.log.dir = /home/hive_repo/log
property.hive.log.file = ${sys:hive.query.id}.log
level = INFO
property.hive.root.logger = FA
property.hive.query.id = hadoop
property.hive.log.dir = /home/hive_repo/log
property.hive.log.file = ${sys:hive.query.id}.log