一、大部分元素没有id、name唯一标识,此时就需要通过xpath
from selenuim import webdriver
from selenuim.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('http://xxx')
time.sleep(3)
# 通过By.XPATH找到唯一页面元素后,先点击一下,全选所有内容后删除,再输入1234
driver.find_element(By.XPATH, "//*[@id=\"directorInputId\"]/input").click()
time.sleep(1)
pyautogui.hotkey("ctrl", "a")
pyautogui.hotkey("Backspace")
time.sleep(1)
driver.find_element(By.XPATH, "//*[@id=\"directorInputId\"]/input").send_keys("1234")1、找xpath的方法1:人工找相对路径
格式://类型[@属性='值'],后面加上/..表示找上一层的父节点,//表示找此节点下的所有
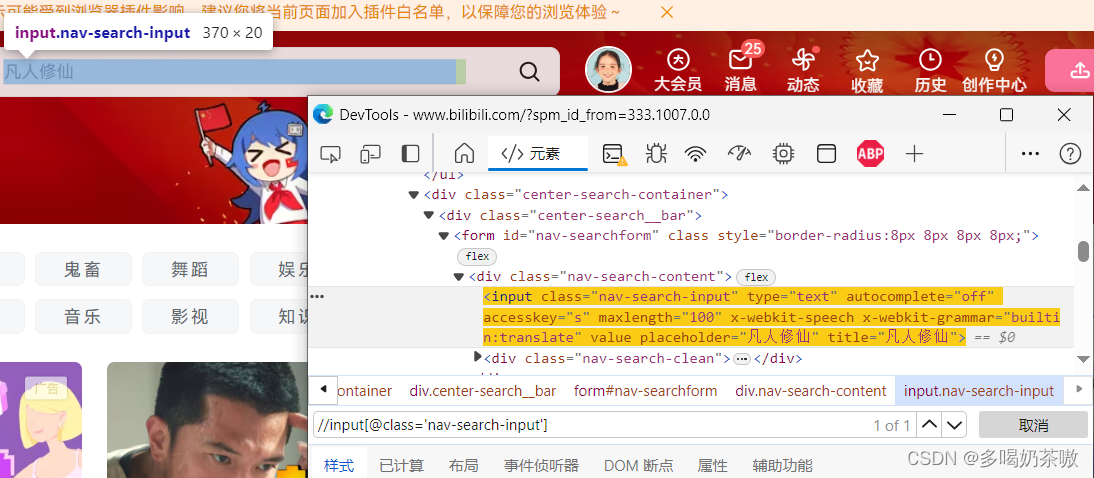
例1:找搜索框://input[@class='nav-search-input']
解释://input表示找所有的类型input,此时肯定有很多,@class表示找元素属性为class的,进一步缩小范围,@class='nav-search-input'表示元素属性值为:nav-search-input,此时就唯一了。如果想再稳一点,可以继续补充这么些://input[@class='nav-search-input'and@type='text']

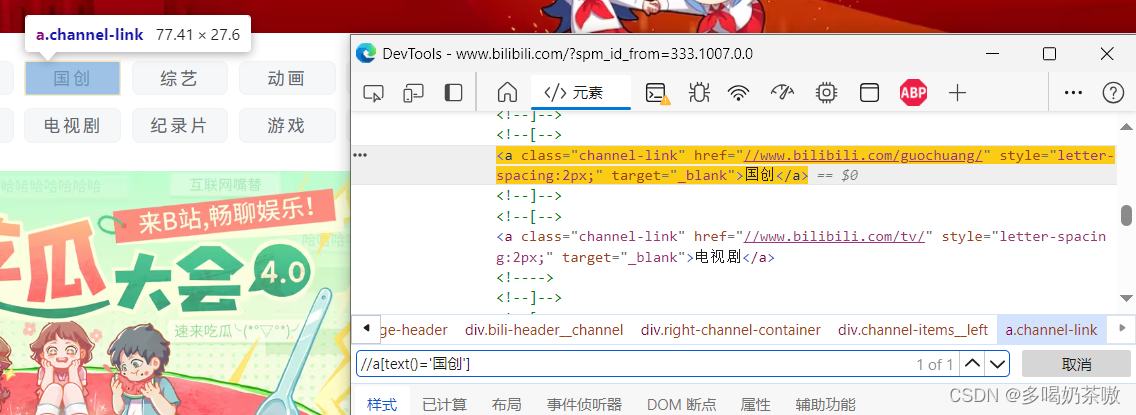
例2:找国创://a[text()='国创']
解释:由于"国创"两个字是孤零零的,这种情况就是text()类型,而不是属性(如果是属性就要写成@属性)
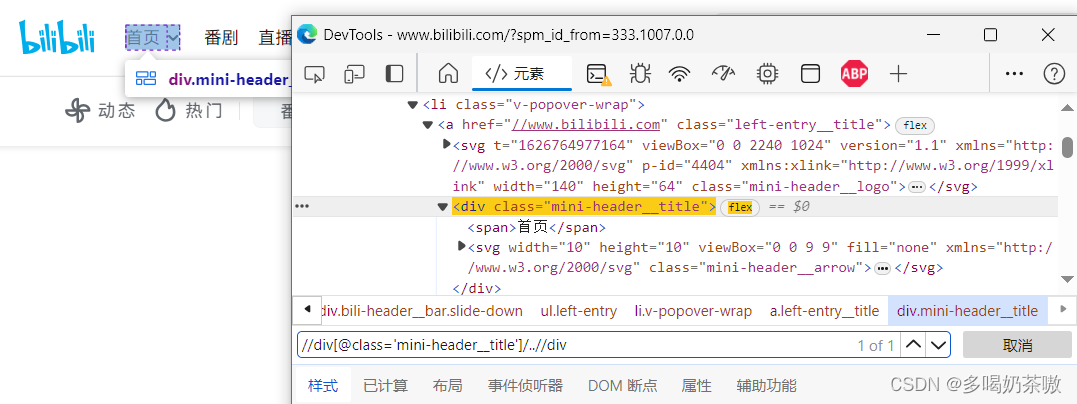
例3://div[@class='mini-header__title']/..
解释://div[@class='mini-header__title']表示找到首页按钮,后面跟上/..则表示找到此节点的父节点。那么如果再在后面追加//div,则表示寻找该父节点下所有类型为div节点,此时就已发现唯一,就不需要继续写[@属性='值']来缩小范围了

2、找xpath的方法2:使用SelectorsHub插件
直接在edge浏览器的拓展商店中搜索下载(安装后重启浏览器才会生效)
如果想在chrome中使用,可以在edge中下载后导出(下图:打包拓展),再去chrome中导入(下图:加载解压的拓展)