线程,协程,异步编程模型
1.线程编程模型
我们知道线程是 cpu 调度的基本单位。
如果是一个单核的cpu, 而且现在有3个线程需要执行。那么可能是 线程 1, 2, 3 通过 cpu分片, 轮流执行。
那么 如果不将 cpu 进行分片, 而是 线程 1,2,3 轮流执行,那么使用时间应该是和 cpu分片的时间完全是一样的。
并且只是切换了2次上下文。那么是不是这样执行的效率更高一些呢?多线程存在的意义又是什么呢?
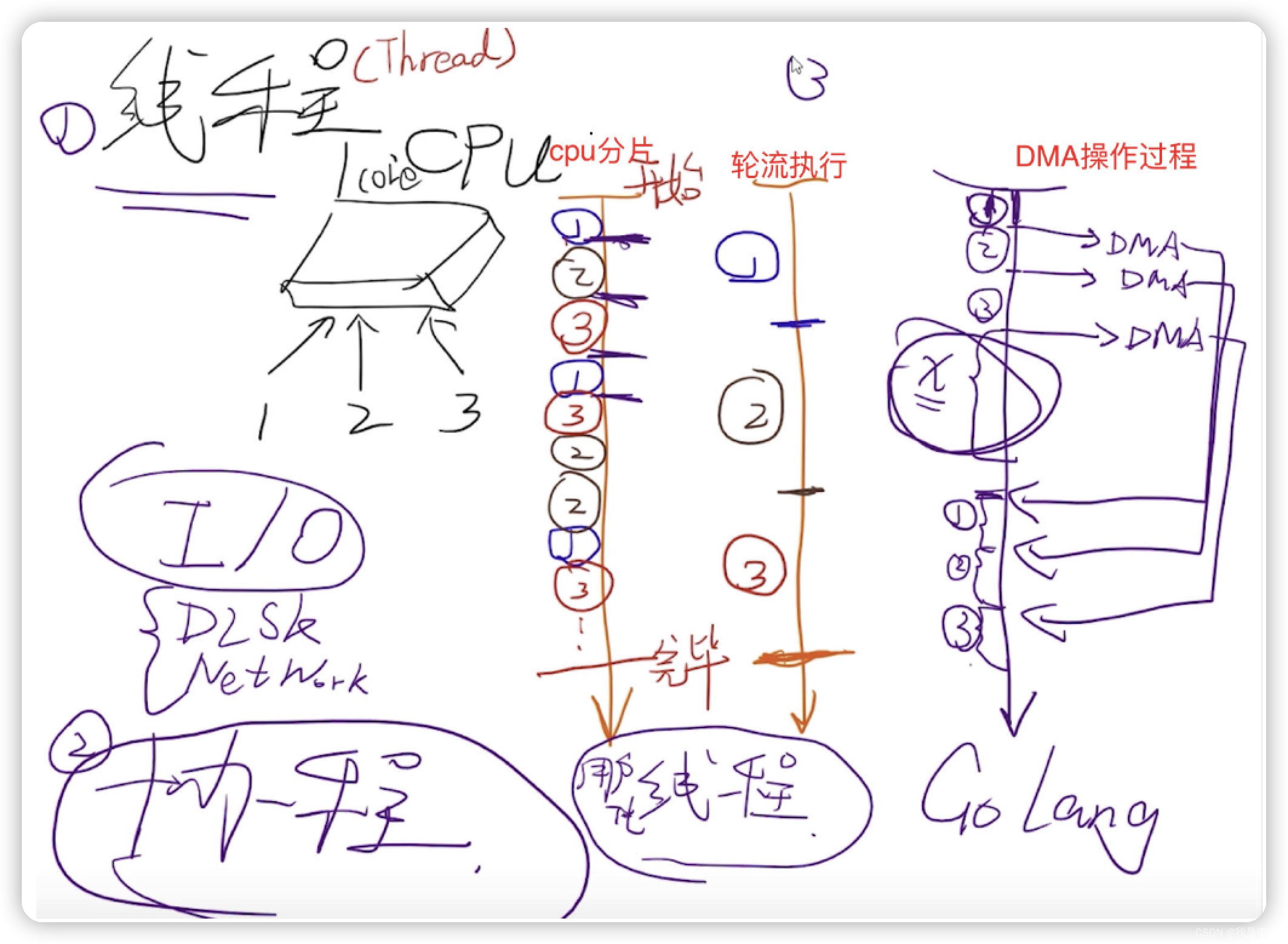
那么提到这个问题,不得不提的问题是 I/O。磁盘的读写,网络数据的传输,音视频的输入输出,都包含IO。我们在编程过程中,最重要的IO 就是磁盘IO和网络IO。IO 是非常消耗时间的,它比执行其它程序更加消耗时间。
那么看一下IO 执行的过程是什么样的。有cpu ,硬盘,内存,这个时候想要进行文件的读取。
首先最容易想到的就是:cpu 直接读取硬盘上的数据,然后将数据放到内存中。也就是文件读取以后,会将文件的内容放到内存中。在整个IO 读取过程中,cpu是全部被占用的。如果是以这种方式进行读取的话,那么必然会造成 cpu分片和不分片的所需要的时间都是一样的。
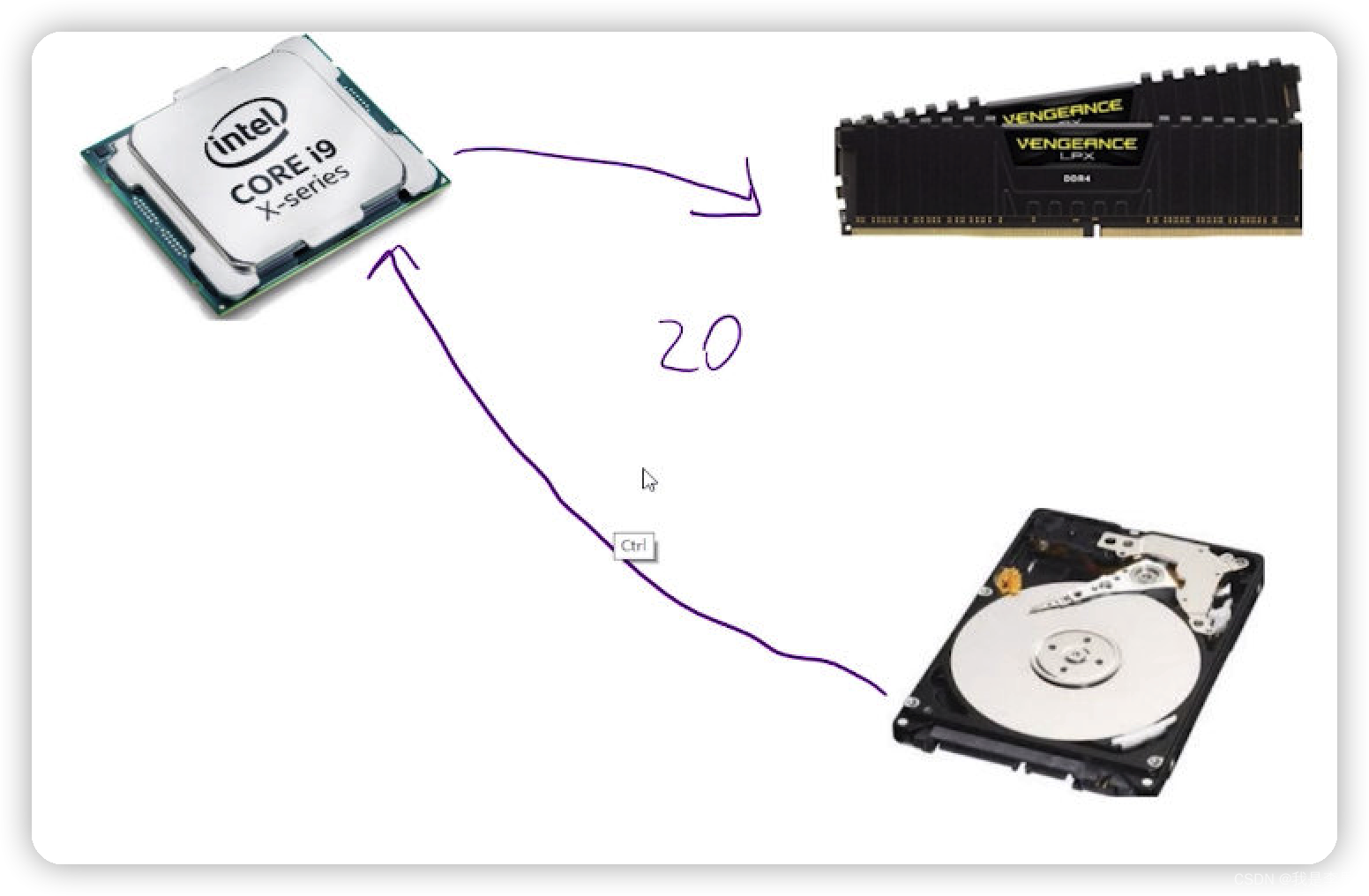
但是实际的IO不是这样的。在IO 执行过程中,有一个非常重要的概念是:DMA。direct memory access。
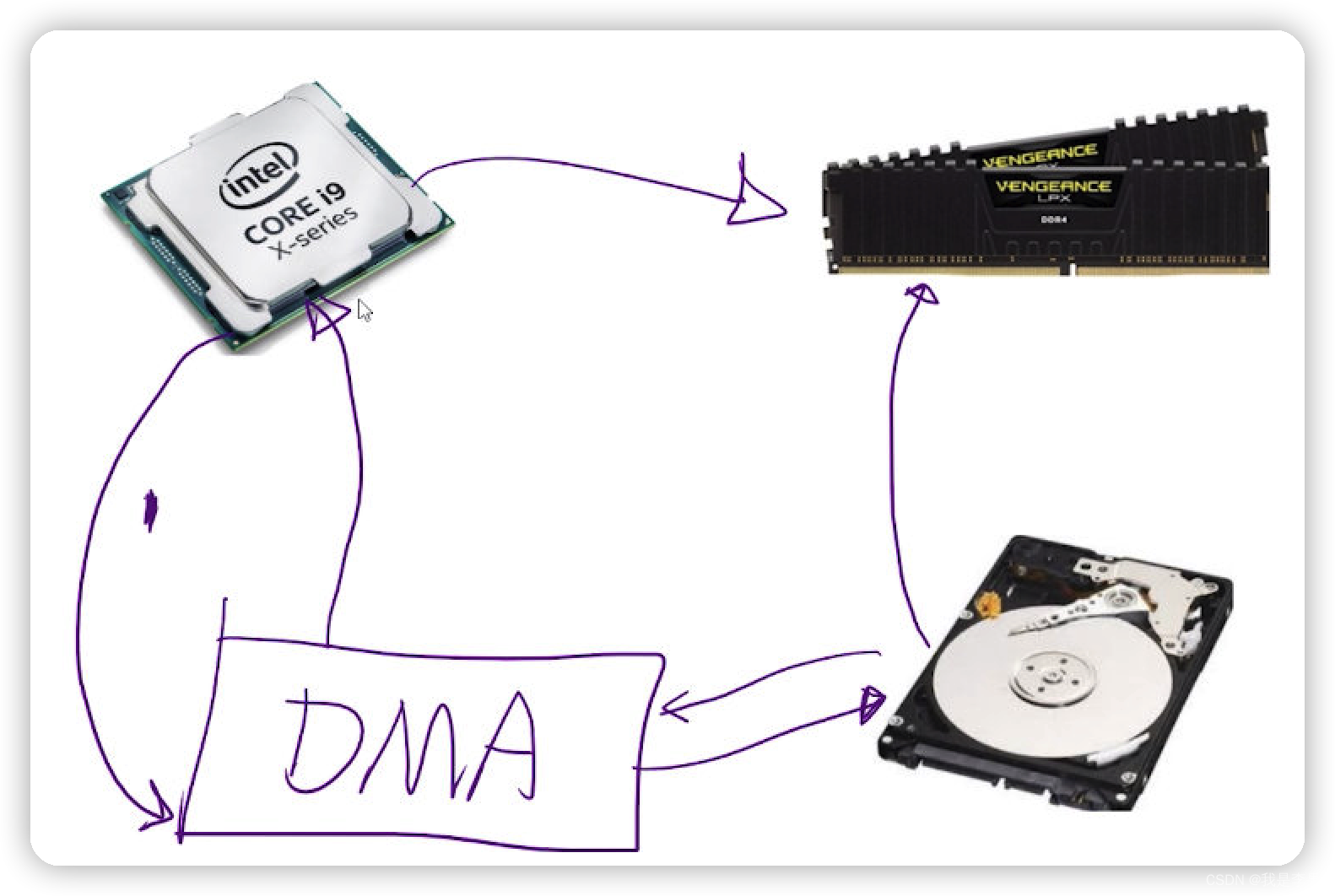
在文件读取过程中,cpu 并不是直接操作硬盘,而是通过对DMA直接下发指令,让DMA完成文件的读取。也就是第一步就是 : cpu 向 DMA下发指令,指令中包含磁盘信息和要读取的文件的位置。然后DMA 告知硬盘进行文件的读取。读取的过程是将文件的内容加载到内存中。最终在读取完毕以后,硬盘会给DMA一个反馈,读取完成。DMA 最终以中断的形式告知CPU ,文件读取完成。然后cpu再去内存中取这一块变量的值,最终就拿到了文件中的内容。
然后我们看整个的过程,cpu 向DMA 下发指令以后,cpu 就处于一个空闲的状态了。在当前状态下,cpu 可以去执行其它的线程。
那么再来回顾当前的过程,首先是线程1,如果发现是 读取文件,那么cpu就会发送 指令到 DMA, 进行文件的读取。此时 cpu 是空闲的。然后假设同时 cpu 被线程 2占用了,然后发现又是读取文件,那么这个时候又会发送指令到DMA 进行文件的读取。以此类推。那么假设这时候这3个线程都在进行文件的读取了,这时候cpu又可以腾出来去干其他的事情了。DMA在这段时间会进行文件的读取。读取完成,并且给了cpu一个中断,那么线程1,2,3 又会占用cpu的资源,继续执行。
那么很明显在DMA执行的过程中,是不占用cpu的,cpu这个时候又可以去做其他的事情了,也就是被其他的线程占用。另外,DMA 进行读取的时候,是可以复用的。因为cpu的线路是有多条的线路的。所以说DMA可以充分的利用这些线路。最终实现并行的读取这些文件。通过以上这些,我们就可以大大提高cpu的利用效率。
因此如果线程想要提高效率,是和IO是密切相关的。而我们的程序中,往往都含有IO。既然线程都已经有这么高的执行效率的,那么协程和异步分别是什么意思呢?
2. 协程编程模型
线程是操作系统级别的概念。在程序中,如果我们想要开辟多线程,那么我们需要调用系统底层的api,才能进行多线程的开辟。在线程开辟的过程中,会比较浪费cpu的时间。并且在线程运行过程中,会有用户态和内核态的切换。这个切换,会占用较长的时间。因而会有一部分时间浪费在cpu切换这个时间点上。所以就有了协程。
协程是编程语言级别的。我们可以像使用线程一样使用协程。但是协程并不是线程,并不会告诉操作系统开辟了线程。因而协程是全程处于用户态的。因而协程可以称作是用户自定义的线程。因而协程可以大量的开辟,并且不用担心内核态和用户态的切换。
在一台机器上,我们可以开辟的线程是有限的,在正常的机器上,开辟的几百或者上千的线程就已经达到上限了。如果是利用go 去开辟协程的话,那么就可以随随便便开辟几千万个协程了。
3. 异步编程模型
看了线程和协程,我们最后来看一下异步。异步的编程其实是非常简单的。例如我们上面说的DMA读取磁盘就是异步的。在一些编程语言,比如 Node.js中,默认就是以 异步的方式来进行编程的。node.js 是单线程的,却能够应对高并发。最重要的原因也是它是异步的操作模型。也就是在单线程中会有很多的回调函数。
总结
无论你是一个初级开发者还是高级开发者,线程,协程,异步 都应该是你日常开发过程中绕不开的一个话题,所以作为软件开发者的我们,真的很有必要详细地了解。
鸣谢
线程/协程/异步编程模型