文本摘要的常见问题和解决方法概述,以及使用Hugging Face Transformers库构建基于新浪微博数据集的文本摘要示例。
作 者丨程旭源
学习笔记
1 前言简介
文本摘要旨在将文本或文本集合转换为包含关键信息的简短文本。主流方法有两种类型,抽取式和生成式。常见问题:抽取式摘要的内容选择错误、语句连贯性差、灵活性差。生成式摘要受未登录词、词语重复等问题影响。
文本摘要的分类有很多,比如单文档多文档摘要、多语言摘要、论文生成(摘要、介绍、重点陈述等每个章节的生成)、医学报告生成、情感类摘要(观点、感受、评价等的摘要)、对话摘要等。主流解决方法主要是基于深度学习、强化学习、迁移学习等方法,有大量的相关论文可以解读和研究。
抽取式的代表方法有TextRank、BertSum[1],从原文中抽取出字词组合成新的摘要。TextRank仿照PageRank,句子作为节点,构造无向有权边,权值为句子相似度。
生成式摘要方法是有PGN[2]、GPT、BART[3]、BRIO[4]、GSum[5]、SimCLS[6]、CIT+SE[7]等。
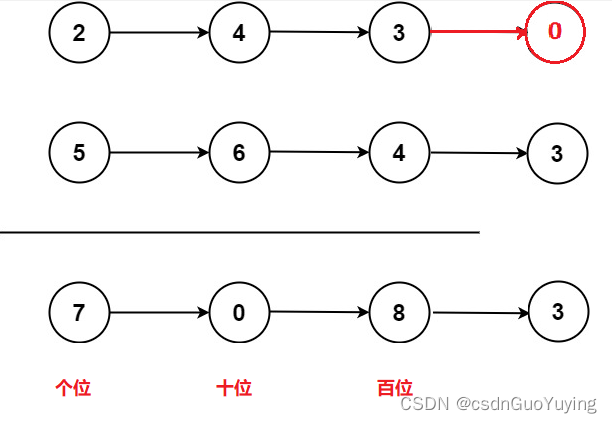
对于生成式摘要,不得不简单再提一下PGN模型:
Pointer Generator Network结构[2]
生成式存在的一个大问题是OOV未登录词,Google的PGN使用 copy mechanism和Coverage mechanism,能对于未遇见过的词直接复制用于生成部分,比如上面的“2-0”,同时避免了重复生成。
2 数据集
文本摘要的数据集有很多,这里使用的是Lcstsm[10]大规模中文短文本摘要语料库,取自于新浪微博,训练集共有240万条,为了快速得到结果和理解过程,可以自己设置采用数据的大小。比如训练集设置10万条。
3 模型选型
预训练模型选的是"csebuetnlp/mT5_multilingual_XLSum",是ACL-IJCNLP 2021的论文XL-Sum[8]中开源的模型,他们也是基于多语言T5模型 (mT5)在自己准备的44中语言的摘要数据集上做了fine-tune得到的模型。mT5[9]是按照与T5类似的方法进行训练的大规模多语言预训练模型。
如何加载模型?使用Hugging Face Transformers库可以两行代码即可加载。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_checkpoint = “csebuetnlp/mT5_multilingual_XLSum”
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
4 数据预处理
加载模型和tokenizer后对自定义文本分词:

mT5 模型采用的是基于 Unigram 切分的 SentencePiece 分词器,Unigram 对于处理多语言语料库特别有用。SentencePiece 可以在不知道重音、标点符号以及没有空格分隔字符(例如中文)的情况下对文本进行分词。
摘要任务的输入和标签都是文本,所以我们要做这几件事:
1、使用 as_target_tokenizer() 函数并行地对输入和标签进行分词,并标签序列中填充的 pad 字符设置为 -100 ,这样可以在计算交叉熵损失时忽略掉;
2、对标签进行移位操作,来准备 decoder_input_ids,有封装好的prepare_decoder_input_ids_from_labels函数。
3、将每一个 batch 中的数据都处理为模型可接受的输入格式:包含 ‘attention_mask’、‘input_ids’、‘labels’ 和 ‘decoder_input_ids’ 键的字典。
在编程的时候,可以打印出一个 batch 的数据看看:

5 模型训练和评测
因为Transformers包已经帮我们封装好了模型、损失函数等内容,我们只需调用并定义好训练循环即可:
def train_loop(dataloader, model, optimizer, lr_scheduler, epoch, total_loss):
progress_bar = tqdm(range(len(dataloader)))
progress_bar.set_description(f'loss: {0:>7f}')
finish_batch_num = (epoch-1) * len(dataloader)
model.train()
for batch, batch_data in enumerate(dataloader, start=1):
batch_data = batch_data.to(device)
outputs = model(**batch_data)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
total_loss += loss.item()
progress_bar.set_description(f'loss: {total_loss/(finish_batch_num + batch):>7f}')
progress_bar.update(1)
return total_loss
训练的过程中,不断的优化模型权重参数,那么如何评估模型的性能、如何确保模型往更好的方向优化呢?用什么评估指标呢?
我们定义一个测试循环负责评估模型的性能,指标就使用ROUGE(Recall-Oriented Understudy for Gisting Evaluation),它可以度量两个词语序列之间的词语重合率。
ROUGE 值的召回率,表示被参考摘要 reference summary有多大程度上被生成摘要 generated summary覆盖,精确率则表示生成摘要中有多少词语与被参考摘要相关。
那么,如果我们只比较词语,召回率是:
Recall = 重叠词数/被参考摘要总词数
Precision=重叠词数/生成摘要的总词数
已经有rouge的Python包[11],使用pip安装即可
pip install rouge

rouge库官方示例,“f” stands for f1_score, “p” stands for precision, “r” stands for recall.
ROUGE-1 度量 uni-grams 的重合情况,ROUGE-2 度量 bi-grams 的重合情况,而 ROUGE-L 则通过在生成摘要和参考摘要中寻找最长公共子串来度量最长的单词匹配序列。
另外要注意的是,rouge 库默认使用空格进行分词,中文需要按字切分,也可以使用分词器分词后再计算。

Transformers对解码过程也进行了封装,我们只需要调用 generate() 函数就可以自动地逐个生成预测 token。
例如我们使用马来亚大学的介绍生成一个摘要:“马来亚大学是马来西亚历史最悠久的高等教育学府。“

所以,在测试过程中,我们通过generate() 函数获取预测结果,然后将预测结果和正确标签都处理为 rouge 库接受的格式,最后计算各项的ROUGE值即可:
def test_loop(dataloader, model, tokenizer):
preds, labels = [], []
rouge = Rouge()
model.eval()
with torch.no_grad():
for batch_data in tqdm(dataloader):
batch_data = batch_data.to(device)
# 获取预测结果
generated_tokens = model.generate(batch_data["input_ids"],
attention_mask=batch_data["attention_mask"],
max_length=max_target_length,
num_beams=beam_search_size,
no_repeat_ngram_size=no_repeat_ngram_size,
).cpu().numpy()
if isinstance(generated_tokens, tuple):
generated_tokens = generated_tokens[0]
decoded_preds = tokenizer.batch_decode(generated_tokens,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
label_tokens = batch_data["labels"].cpu().numpy()
# 将标签序列中的 -100 替换为 pad token ID 以便于分词器解码
label_tokens = np.where(label_tokens != -100, label_tokens, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(label_tokens,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
# 处理为 rouge 库接受的文本列表格式
preds += [' '.join(pred.strip()) for pred in decoded_preds]
labels += [' '.join(label.strip()) for label in decoded_labels]
# rouge 库计算各项 ROUGE 值
scores = rouge.get_scores(hyps=preds, refs=labels, avg=True)
result = {key: value['f'] * 100 for key, value in scores.items()}
result['avg'] = np.mean(list(result.values()))
return result
6 模型保存
优化器我们选使用AdamW,并且通过 get_scheduler()函数定义学习率调度器。
在每一个epoch中,调用上面定义的train_loop和test_loop,模型在验证集上的rouge分数用来调整超参数和选出最好的模型,最后使用最好的模型跑测一下测试集来评估最终的性能。
""" Train the model """
total_steps = len(train_dataloader) * num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], "weight_decay": weight_decay},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0}
]
warmup_steps = int(total_steps * warmup_proportion)
optimizer = AdamW(
optimizer_grouped_parameters,
lr=learning_rate,
betas=(adam_beta1, adam_beta2),
eps=adam_epsilon
)
lr_scheduler = get_scheduler(
'linear',
optimizer,
num_warmup_steps=warmup_steps,
num_training_steps=total_steps
)
# Train!
logger.info("***** Running training *****")
logger.info(f"Num examples - {len(train_data)}")
logger.info(f"Num Epochs - {num_train_epochs}")
logger.info(f"Total optimization steps - {total_steps}")
total_loss = 0.
best_avg_rouge = 0.
for epoch in range(num_train_epochs):
print(f"Epoch {epoch+1}/{num_train_epochs}\n" + 30 * "-")
total_loss = train_loop(train_dataloader, model, optimizer, lr_scheduler, epoch, total_loss)
dev_rouges = test_loop(dev_dataloader, model, tokenizer)
logger.info(f"Dev Rouge1: {dev_rouges['rouge-1']:>0.2f} Rouge2: {dev_rouges['rouge-2']:>0.2f} RougeL: {dev_rouges['rouge-l']:>0.2f}")
rouge_avg = dev_rouges['avg']
if rouge_avg > best_avg_rouge:
best_avg_rouge = rouge_avg
logger.info(f'saving new weights to {output_dir}...\n')
save_weight = f'epoch_{epoch+1}_rouge_{rouge_avg:0.4f}_weights.bin'
torch.save(model.state_dict(), os.path.join(output_dir, save_weight))
logger.info("Done!")
7 总结
文本摘要和文本生成是自然语言处理中非常重要和常见的任务,本文使用生成式方法做文本摘要,文本生成还可以应用于其他场景下,比如给定一个句子,生成多个与其相似、语义相同的句子,这里也Mark一下,后面再写一篇相关文章。
文本摘要还存在很多问题,有待研究者们进一步探索,比如:长程依赖、新颖性、暴露偏差、评估和损失不匹配、缺乏概括性、虚假事实、不连贯等,此外,还有摘要任务特定的问题,比如:如何确定关键信息,而不仅仅是简单地句子压缩。每个问题的解决或方法优化都能发表论文,相关的论文有太多了。后续可以抽关键的解决方案聊聊。
代码近期整理后上传Github,链接见文末留言处。




![[ 数据结构 ] 平衡二叉树(AVL)--------左旋、右旋、双旋](https://img-blog.csdnimg.cn/img_convert/9d6a1ec489b692b74db72fc6abb0109d.png)