文章目录
- 一、网络功能概述
- 二、SDN基本概念
- 三、路由算法与路由协议概述
- 四、IP数据报格式
- 五、IP数据报分片
- 六、IPv4地址
- 七、网络地址转换NAT
- 八、子网划分和子网掩码
- 九、无分类编址CIDR
- 十、ARP协议
- 十一、DHCP协议
- 十二、ICMP协议
- 十三、IPv6
- 十四、RIP协议与距离向量算法
- 十五、OSPF协议与链路状态算法
- 十六、BGP协议
- 十七、IP组播
- 十八、移动IP
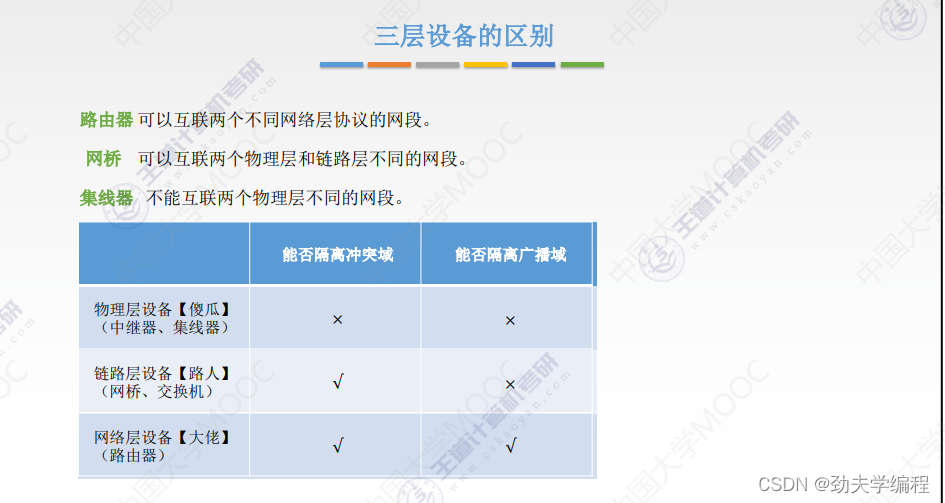
- 十九、网络层设备
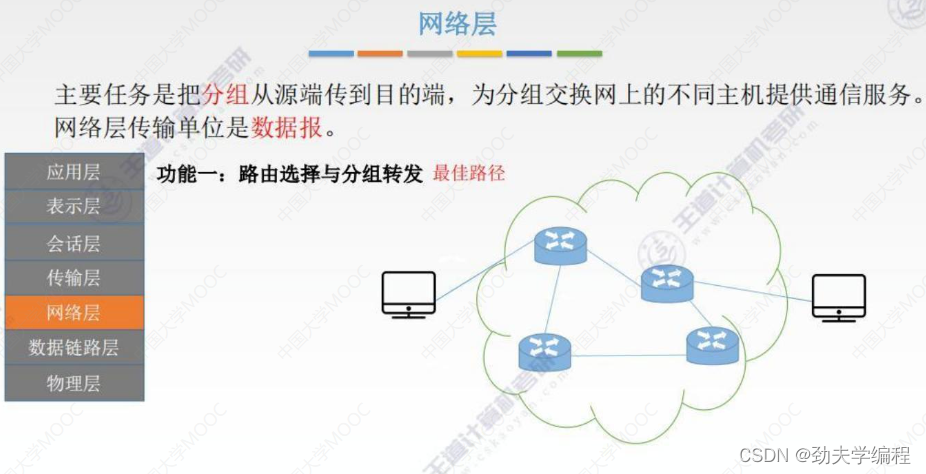
一、网络功能概述
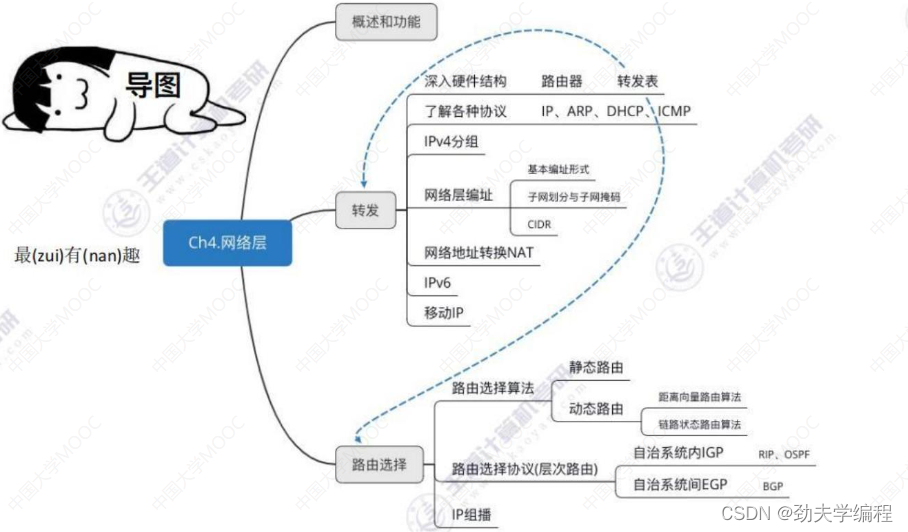
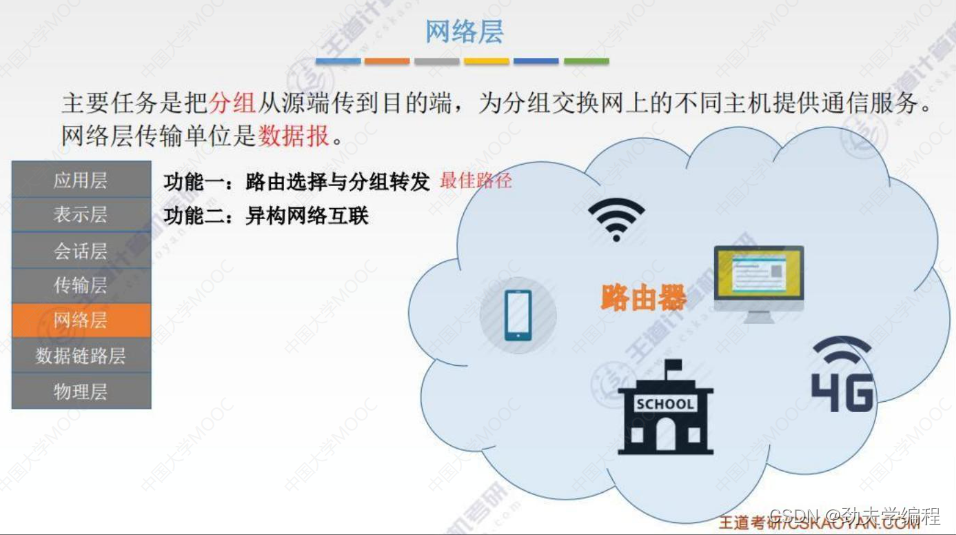

二、SDN基本概念
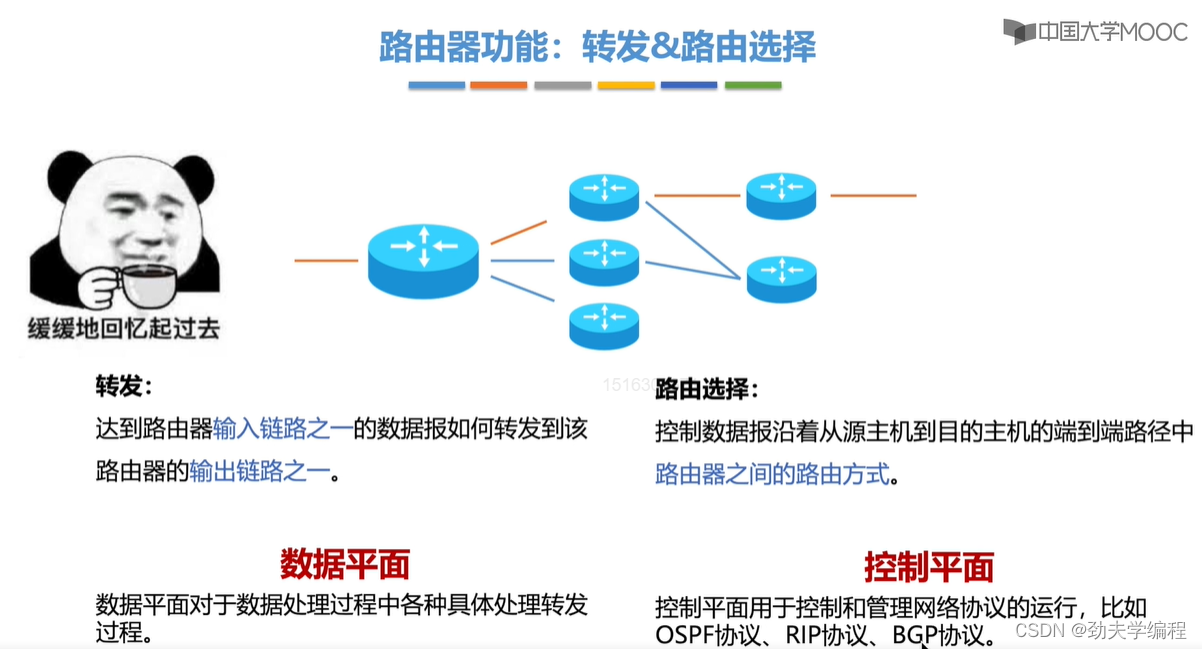
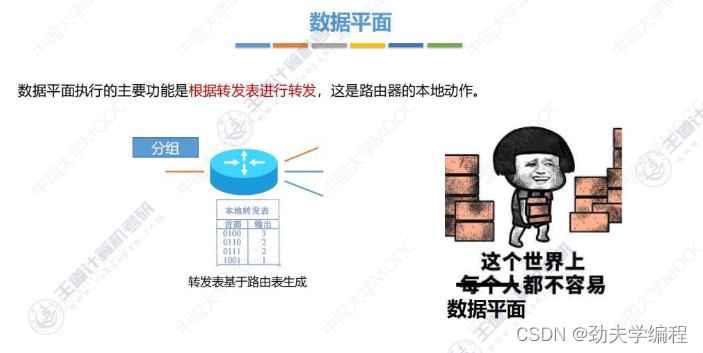


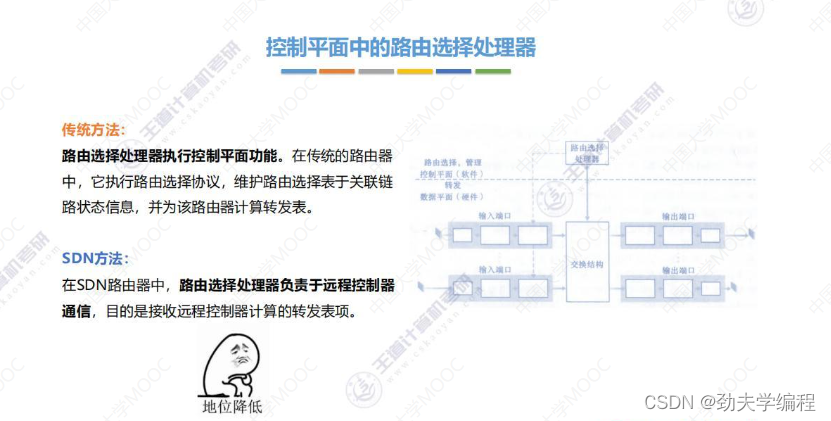



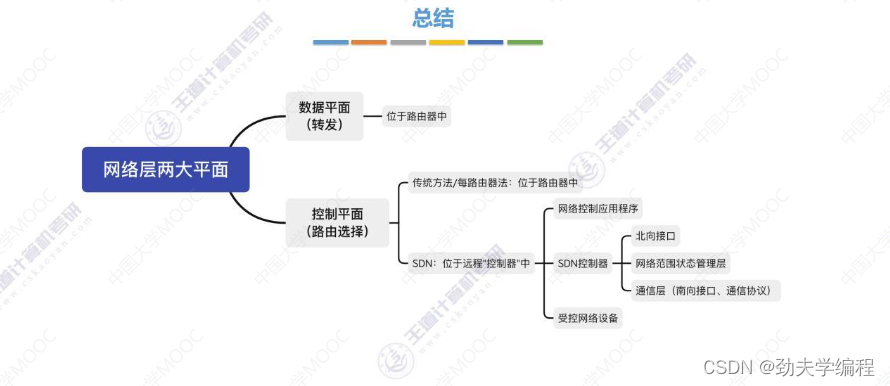
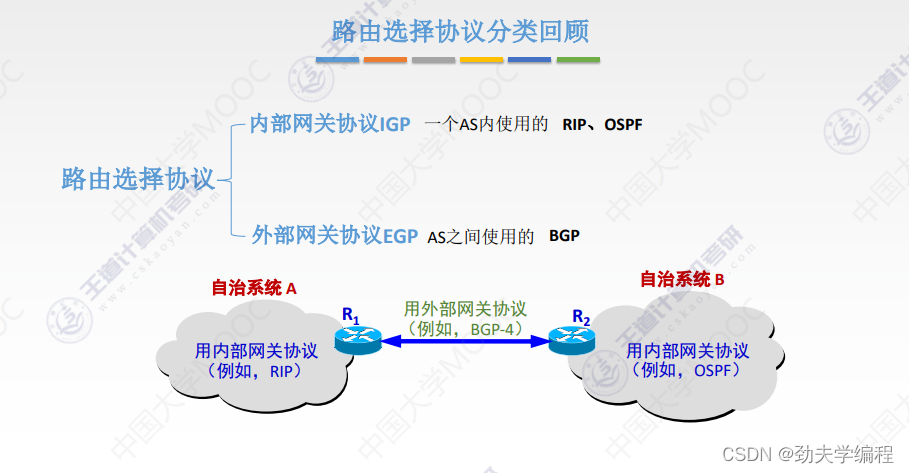
三、路由算法与路由协议概述



四、IP数据报格式
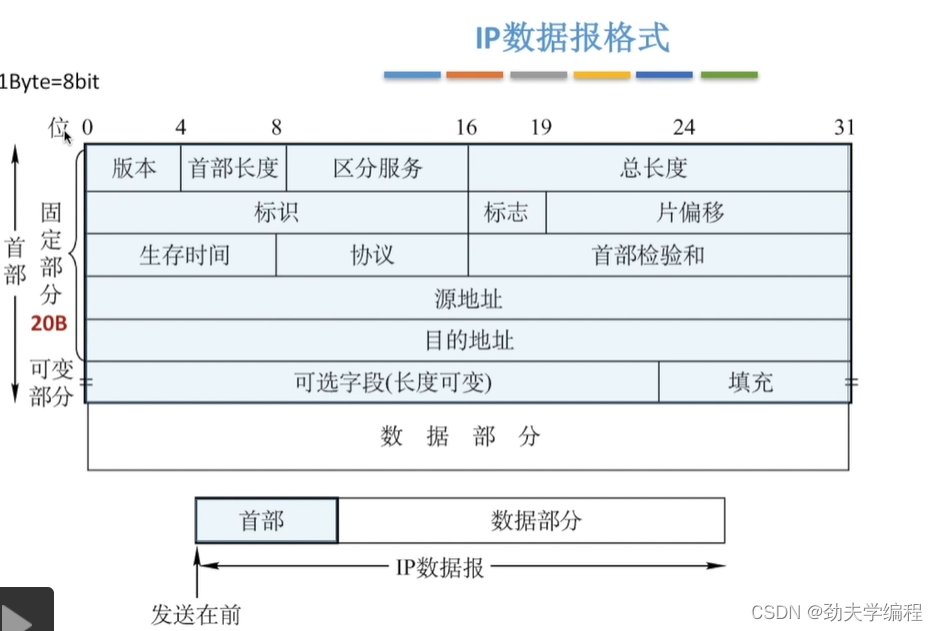
对于IP数据报,分成了两部分,一个是首部和数据部分。
数据部分就是运输层的传送单元,有TCP段也有UDP段。这个首部也可以称之为IP数据报的头部,需要注意的是,在网络层这一章的IP数据报和分组不用做太细的区分。但我们要清楚它们仍有一定的区别,对于一个IP数据报如果过大,我们会给它进行一个分片,分片下来的小单位就是网络层的传输单元“分组”
我们发送数据的时候是从首部开始,然后逐个比特再去发送。这个首部我们又给它细分成了两个部分,第一部分是固定部分,第二部分叫可变部分。固定部分必须要有,可变部分不一定需要。

下面我们看一下具体的首部有哪些字段。
固定部分长度固定是20字节,1字节=8比特(1比特就是1位),所以我们这里用位来对首部进行划分。
版本:
版本字段是0-4,也就是版本字段占4位。它是指使用ip协议版本的是ipv4还是ipv6。
首部长度:
首部长度占4位,也就是0000-1111,可以表示16个数,而首部长度的单位是4字节,也就是说如果首部长度的数据是1111,那么就是15*4=60字节的首部长度。
首部长度可以是0000吗?这个是不行的,因为固定部分是20字节,我们用20字节除4字节单位长度,20/4=5,所以首部长度的数据最少要是5开始,对应二进制是0101
填充:
而当我们ip分组的首部长度不是4字节的整数倍时,就没办法用首部长度表示了,所以我们会有这样一个填充字段。
填充字段的意义就是把整个首部填充成4字节的整数倍,这样首部长度才能对应的表示出来
这样,后面的数据部分就会从4字节的整数倍开始。
我们常用的首部是20字节,也就是只有固定部分,没有可变部分,首部长度的比特序列也就是0101,也就是5
区分服务:
区分服务是只期望获得哪种类型的服务,比如我现在手里有一个数据报,想把它优先发出去,那我们就可以用区分服务来强调优先级。实际应用中很少用区分服务。
总长度:
是指首部长度+数据部分,也就是整个ip数据报的长度。这里需要和首部长度做一个区分。
首部长度的单位是1B
总长度占16位,也就是可以用16位二进制数表示,那么总长度最大值216-1,也就是65535,再乘以1字节(一个单位),也就是65535B,这是ip数据报长度的上限。但是实际生活中是不会达到这个上限的,因为如果长度过大我们还需要对它进行分片来满足这个数据链路层的一个MTU(最大数据传输单元的要求)
标识、标志、片偏移
后面讲ip数据报分片着重讲,这里先跳过
生存时间
生存时间(TTL),time to live,它表示ip分组的保质期,也就是ip分组在网络中的一个寿命,它每经过一个路由器,它的生存时间就会减一。如果最后这个生存时间变成0了,这个数据报就会丢弃掉。
至于为什么要设置生存时间,是为了防止无法交付的数据报无限制的在网络中兜圈子。
举个例子:
我们某个主机要发送一个分组,而发送过程要经过大大小小的网络再到达目的主机。
假设现在3个路由器R1 R2 R3
分组首先从R1转发到R2,再到R3,后面可能又到R1了,这样其实就很消耗网络资源了。

协议:
协议是指数据部分所用的协议,也就是我们运输层传下来的报文段是什么样的协议。
具体来说有如下协议,它们分别对应一定的字段值。我们着重记忆TCP和UDP两协议

我们简单记忆一下:
TCP是面向连接的,所以它非常”6“
UDP是不面向连接的,对于不面向连接的传输,数据比较容易被遗弃。因为如果不建立连接,那么这个链路是不可靠的。因此这个数据经常会发生丢包的现象,也就是被遗弃掉了。遗弃就是”17“。
首部检验和:
它占的位数是16位,顾名思义就是检验首部的字段,为什么用”和“呢,这个是因为检验首部使用的方法是二进制求和。
需要注意,首部检验和只检验首部,它不检验数据部分。之所以要有首部检验和,是因为我们在数据传输过程中,数据报每经过一个路由器,路由器都需要重新计算一下首部检验和。因为一些字段,比如生存时间、标志、片偏移都可能发生变化。所以我们要通过检验和来检验一些发生变化后数据报有没有出错。如果出错就把数据报丢弃掉,如果没错就继续传输。
源地址、目的地址:
它们的长度都是32位,也就是我们现在常用的ipv4,ipv4对应的ip地址长度就是32位。
可选字段:
可选字段长度是可变的,它的范围是0-40B,是用来支持排错、测量的。
填充字段:
这个是为了实现补全的功能,是为了让ip数据报长度是4字节的整数倍。
五、IP数据报分片
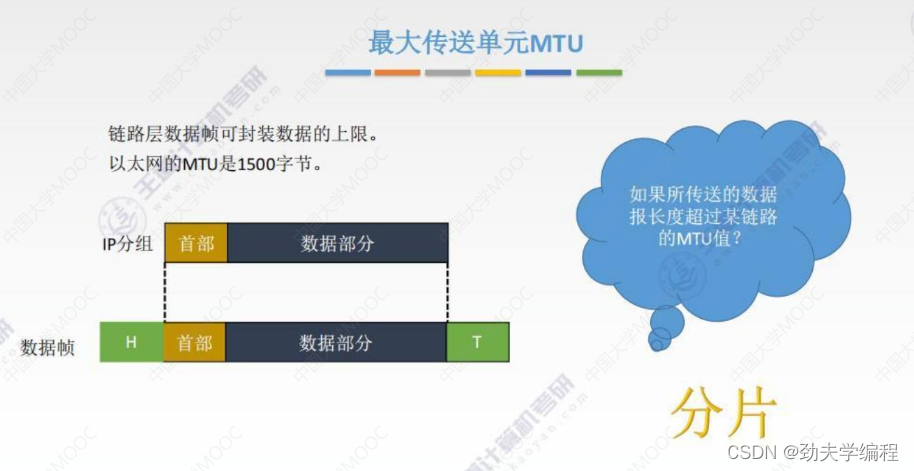
在链路层上,每一个数据帧都有一个可封装数据的上限,这个上限就叫做最大传送单元mtu
对于以太网来说,mtu就是1500字节。
ip分组(也称之为ip数据报),它分为首部和数据部分

ip数据报经过封装成为链路层的数据帧,封装过程就是在分组前面加头,分组后面加尾

中间部分是ip分组,这个数据部分有一个最大要求,这个最大要求就是mtu不能超过这个上限值,以太网中数据帧的数据部分最大就是1500字节。
如果我们要传送的数据报长度超过了链路的mtu怎么办?
我们的解决办法就是分片(这种分片的解决办法前提是这个ip分组同意)
有些ip分组不愿意分片,但是不分片就无法往下传递了,于是就会返回一个icmp的差错报文,这个icmp后面再详细讲。
我们下面来学一下分片的方法。
分片就需要结合ip数据报首部中的”标识、标志、片偏移“来理解。
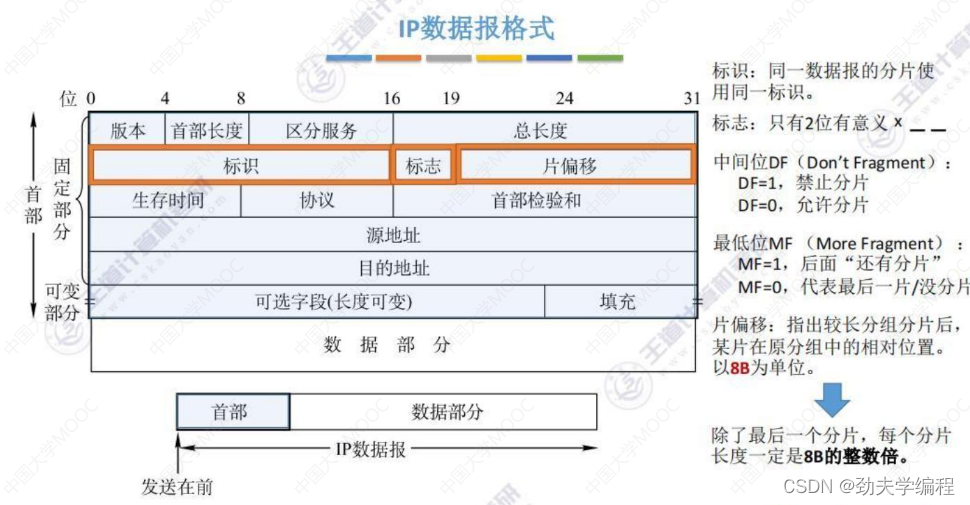
标识:
标识是指同一数据报的分片,只要是同一数据报的分片,它都会使用相同的标识,也就是说一个原始的数据报,如果它的长度超过了mtu,那么它就需要进行分片,每分的一小片它都和原来的数据报使用同一个标识。
标志:
标志字段占3位,但是只有2位是有意义的,
中间的位DF=1表示不允许分片,DF=0表示允许分片
最后一位MF=1表示后面还有分片,MF=0表示后面没有分片了。

片偏移:
这个字段是告诉我们这个分片是在原先分组哪个位置上。
这个字段共占13位,以8B为单位。
如果一个分片的片偏移数据为1,那么这个分组在原先分组中相对位置就是1*8B
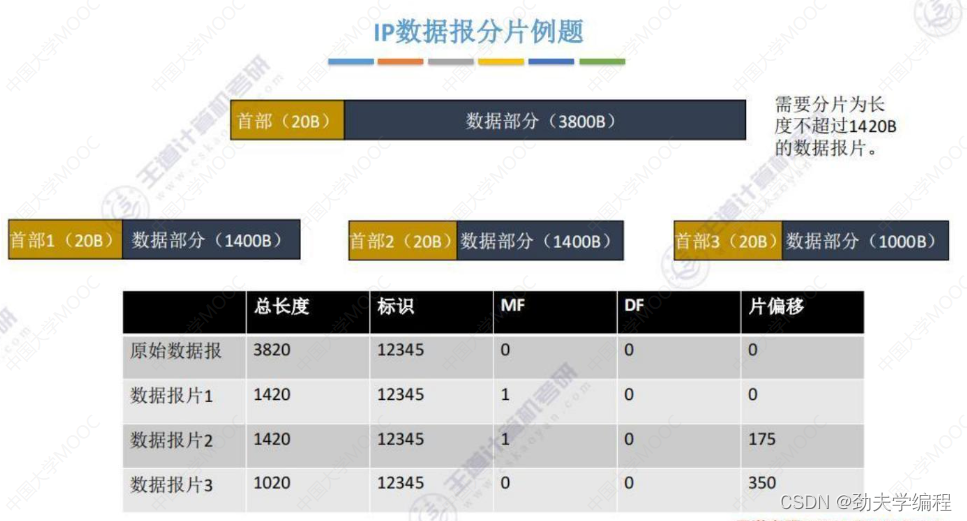
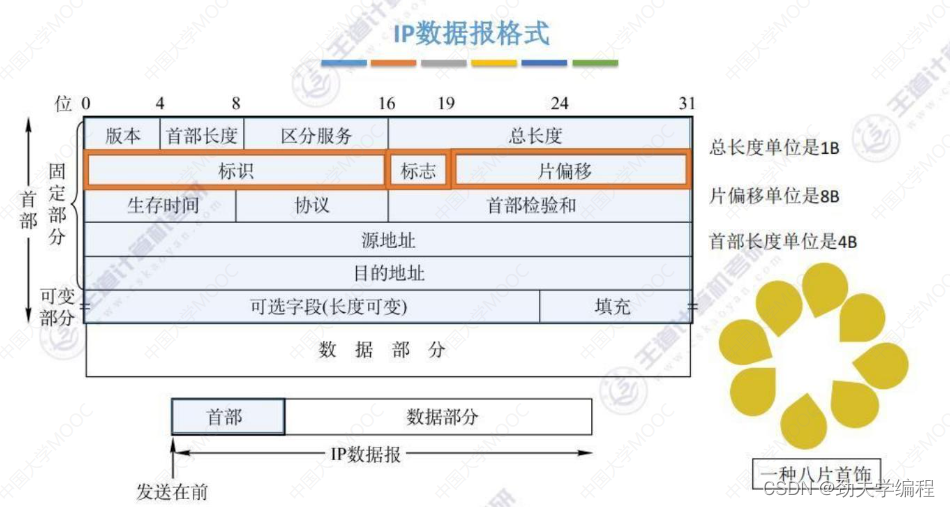
简单记忆单位:1总8片首4
六、IPv4地址
整个大的互联网,也就是因特网是非常单一的网络。ip地址其实就是在给这个网络中的每一台主机或者每一个主机的接口,以及路由器的接口都赋予一个标识符,使之能够标识这个主机的接口以及路由器的接口。这样我我们根据ip地址就可以很容易的在因特网中进行寻址了。
而由于世界上的设备非常的多,如果每一个设备都有一个属于自己的ip地址,我们怎么分配呢?

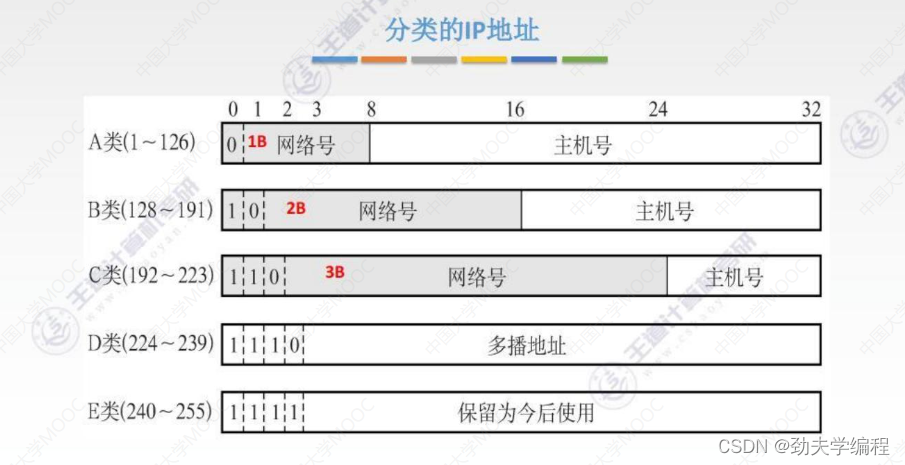
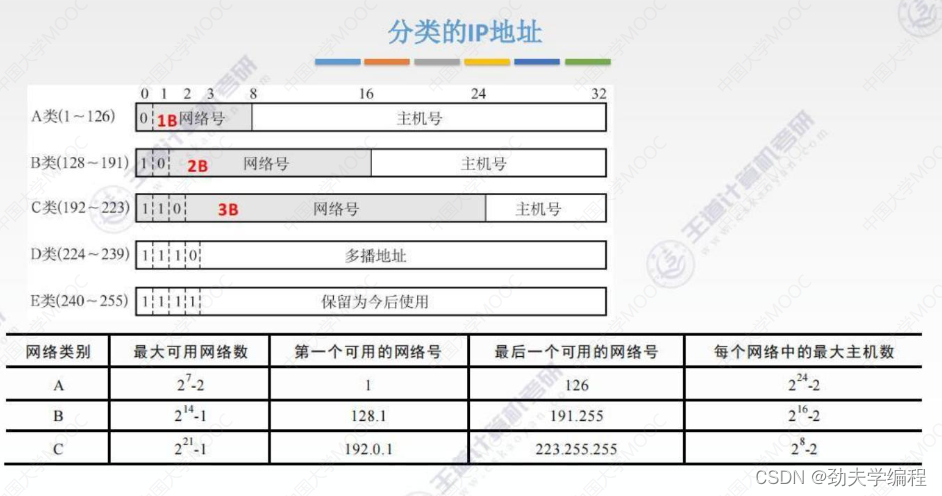
分类的IP地址:
第一阶段:分类的ip地址就是把一个很大的ip地址空间进行一个划分,分成几类。
子网的划分:
第二阶段:随着时代的发展,我们所需分配的地址变多了,这个分类的ip地址其实已经不太能满足人们的应用了,所以对于ip地址的改进就出现了子网的划分。
构成超网:
第三阶段:就是构成超网,也就是CIDR技术,这是目前比较新的技术,是一种无分类的编址方法。
子网划分和构成超网我们后面会详细解释,这里先学习分类的ip地址

身份证可以唯一标识一个人,ip地址也可以唯一标识一个主机或者路由器。
IP地址前8位是网络号,后24位是主机号,这种32位机器是可以识别的。
但是为了方便人们操作,我们写成了点分十进制,我们把每一个字节(8位)写成十进制数,中间用点分割开就可以了。我们做题中也是用的点分十进制。
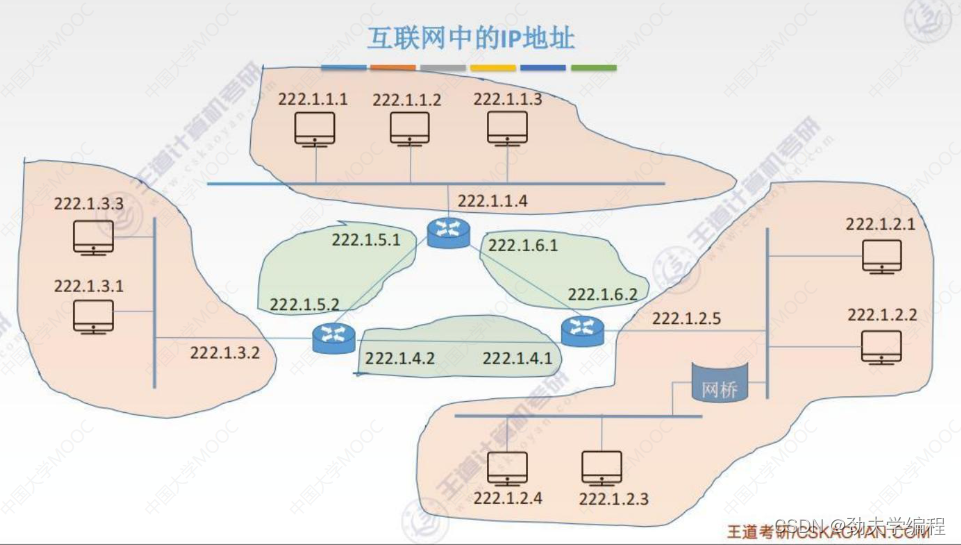
上图中总共有6个网络,但只有2种类型的网络。
上图粉色部分是一种网络,它们都是路由器的一个接口连接的主机以及链路层设备(网桥)所构成的局域网,所以都叫做一个网络。
比如最左边的一个网络,我们可以用222.1.3.0表示,主机号全0,剩下网络号不变这就标识着这样一整个局域网。,我们这里称之为LAN1。
最右边一个网络,它有一个网桥,网桥是不能够分割广播域的,所以用网桥(链路层设备)连接起来的网段仍然是一个局域网,而且也只能有一个网络号,所以这个LAN3所对应的网络号就是222.1.2.0,只要是属于LAN3范围的主机和设备,它们的ip地址网络号都是222.1.2,剩下的主机号位置各部相同。
再来看剩下的几个路由器,每个路由器都有三个端口(看路由器出去几条线)
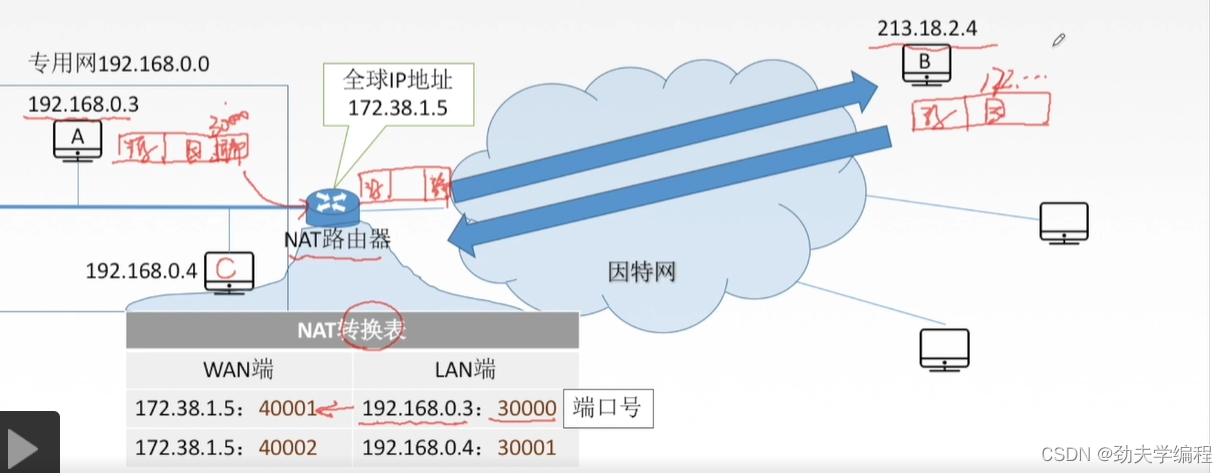
七、网络地址转换NAT
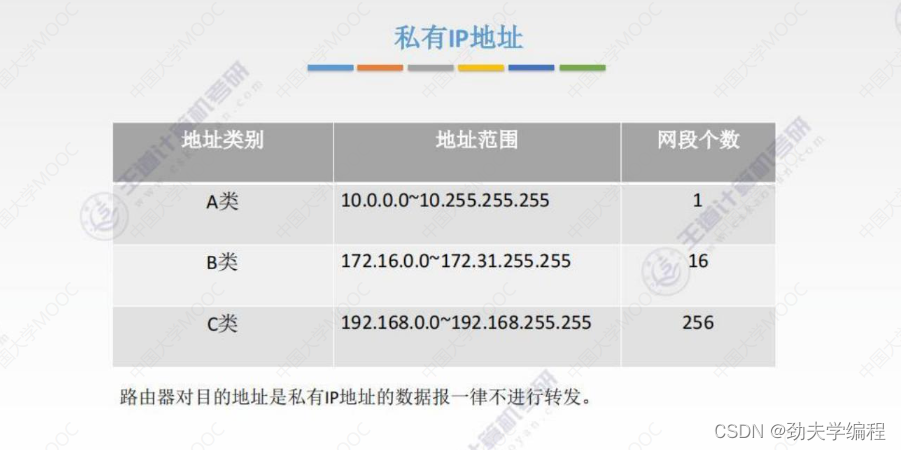
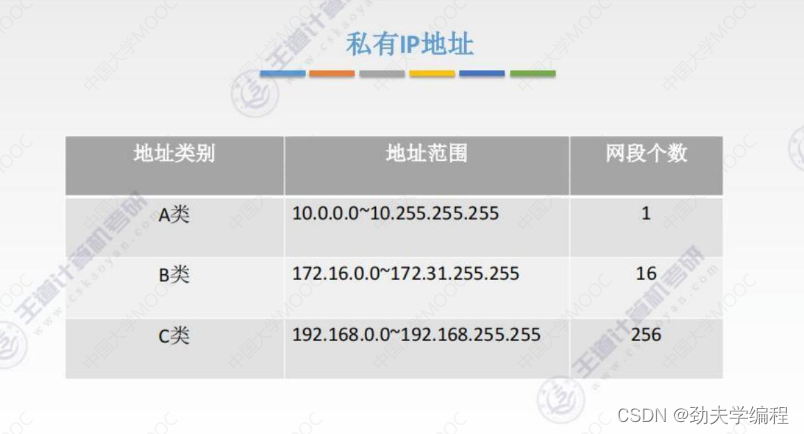
路由器对私有IP地址不会进行转发,也就是说私有IP地址在外网/因特网中是无效的。
那这种私有IP地址能否和外网中的主机进行通信呢?这个是可以的,也就是我们本节要讲的网络地址转换NAT技术。
NAT技术也很简单,只需要在专用网和因特网之间的路由器上装一个NAT的软件,然后这个路由器就会变成NAT路由器
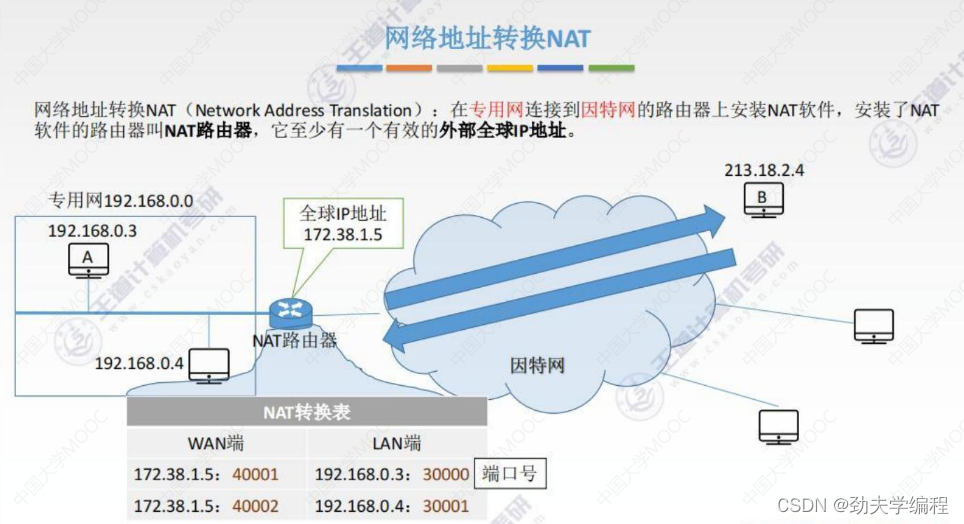
这种路由器至少有一个有效的外部全球IP地址(也可以有多个)
所有使用本地地址的主机在和外界进行通信的时候都需要经历这样一个NAT路由器的地址转换,就可以实现和外部主机的通信。
专用网内的主机要把自己的数据发出去,就需要用路由器上的全球IP地址做一个伪装
外网的其他主机要给这个专用网上的主机发送数据,目的地址也是填的路由器的地址。然后路由器再把数据分发给具体的主机。
这个网络地址转换的实现的一个关键就是NAT路由器,它有一个NAT的转换表。
这个转化表主要分为两列:广域网端、局域网端(外网端、本地网端)
每份信息都包含两个部分,一个是我们常用的点分十进制的ip地址,另一个就是端口号
比如172.38.1.5:40001,这个172.38.1.5是ip地址,40001是端口号
ps:端口号是传输层会学到的,它可以唯一标识主机中的某一个具体进程
下面来看一下A给B发送信息具体流程:
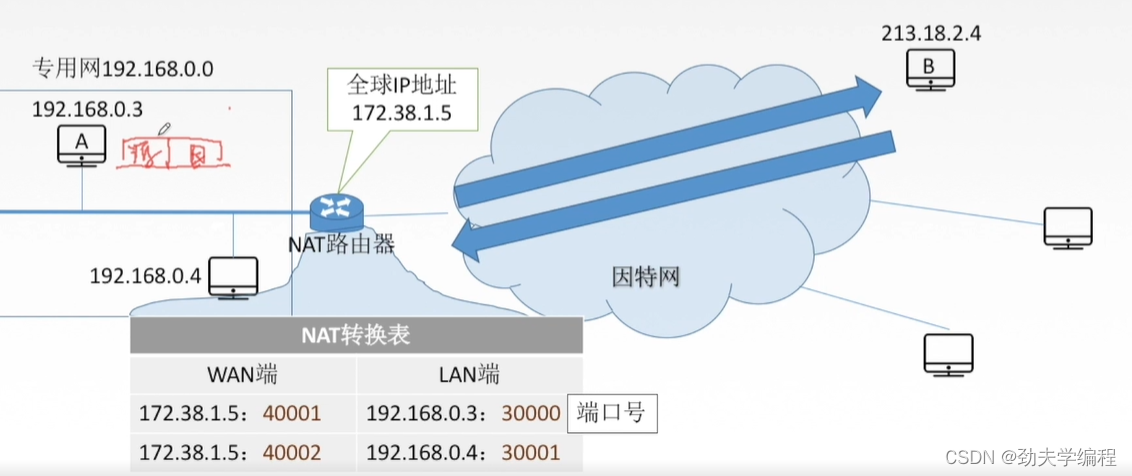
A在网络层这里会封装上源IP地址和目的IP地址

到了传输层会进一步封装加上端口号,假设我们设它的端口号是30000
这个数据报到了NAT路由器(本地网的代表)就需要实现了一个网络地址转换了
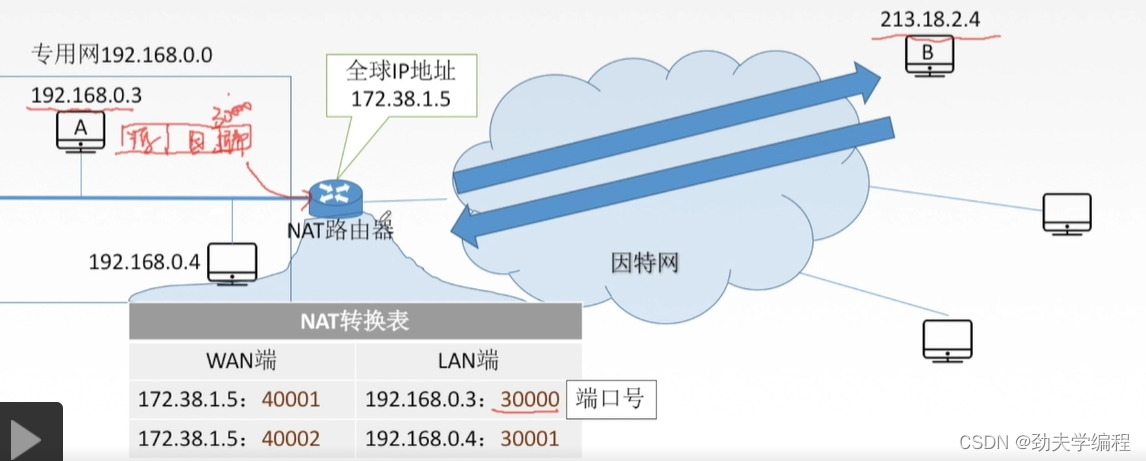
怎么进行转换?其实就是把源ip地址和端口号两个字段替换一下,替换就按照转化表中对应外网中所用的ip地址。也就是把源ip替换成路由器的ip地址,端口号替换成40001

转换后的数据报就可以在因特网中被路由器及主机识别与转发
这样的数据报到了B端,B端也可以正确接收。
再看一个例子,B主机要给C主机发送数据,它会先准备好一个数据报,贴上源地址和目的地址。源地址就是B主机的IP地址,目的地址就是NAT路由器的地址(本例中是172.38.1.5)
然后再到传输层上封装上端口号,假设我们这里端口号是40002
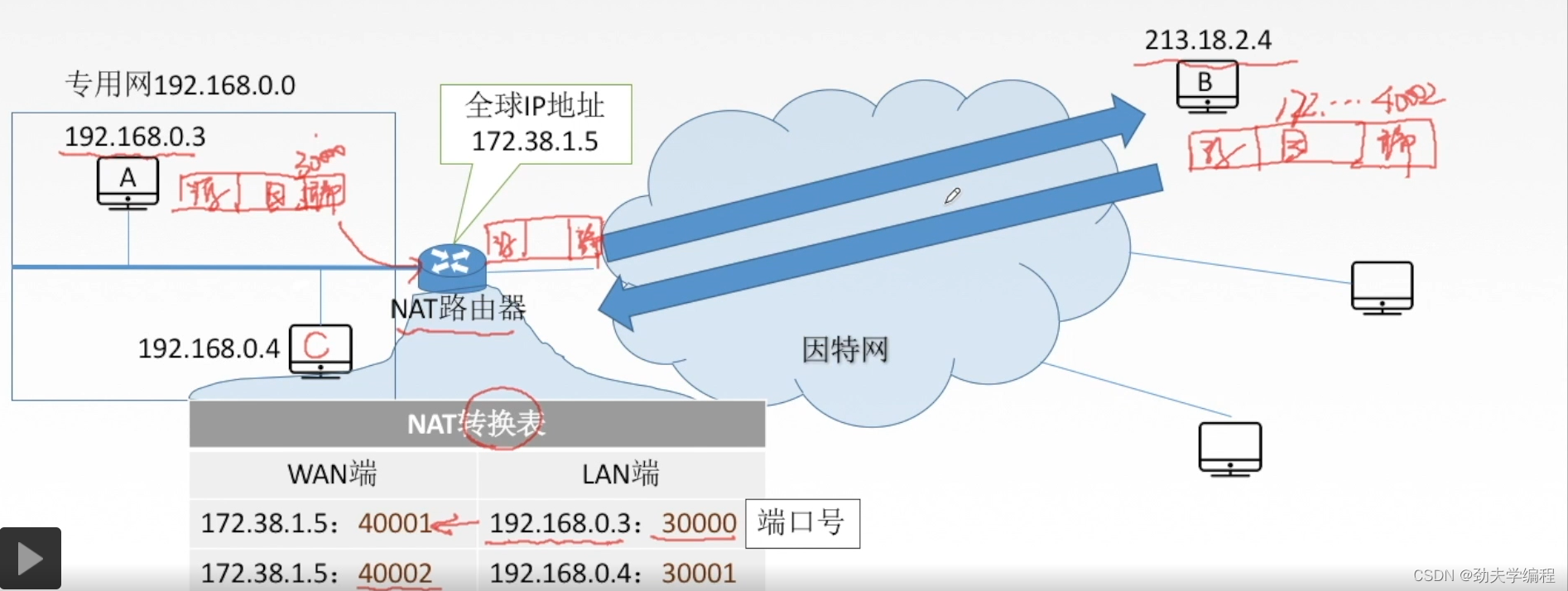
这种数据报就可以在网络上转发了,现在它经过因特网传到了NAT路由器,那这个NAT路由器就要把这个数据报查看一下,再把地址转换一下才能分发给本地网络的某台主机。
根据转发表中的178.38.1.5:40002它知道要转发给本地的192.168.0.4:30001

转换后的数据报就可以传给本地网的C主机了。
八、子网划分和子网掩码

分类IP地址有如下的缺点:
1.IP地址空间的利用率有时很低
比如A类地址,A类地址网络号占1个字节,主机号占3个字节。A类中的每一个网络,可以分配的主机个数至少有1000w个,然而有的网络会对连接在网络上的计算机数目有一定的限制,那根本是不可能达到1000w个这么多的。这样就造成了资源的浪费。
2.两级IP地址不够灵活
比如说有个单位他可能需要在一个新的地点马上开通一个新的网络,但是在申请一个新的IP地址之前,他需要跟这个ISP(因特网服务供应商)申请一系列的IP地址,这样操作就不够灵活了。
那有没有办法可以随时随地的灵活的增加我们单位的网络,而不是事先去找ISP去申请一些新的网络号。这个方法就是我们本节要讲的子网划分。
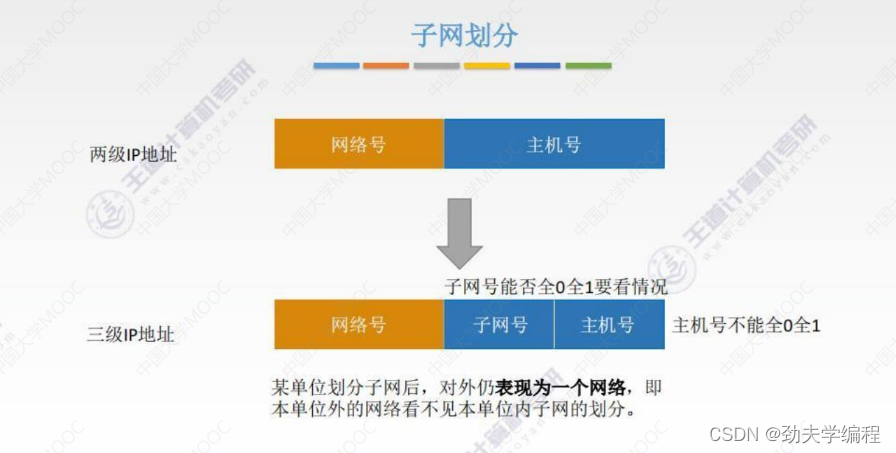
子网划分就是把原先的主机号较高部分拿出来作为子网号,剩下的部分再作为一个主机号。
子网划分的规则,比如要不要划分子网、怎么划分子网都是可以自己决定的。
需要注意的是,如果划分了子网后,对外仍然会表现成一个网络,而表现的网络号是原先的网络号。简言之,本单位外的网络是看不见子网的。
子网号可以一位也没有(除了网络号,全是主机号),子网号最多是留两位给主机号。
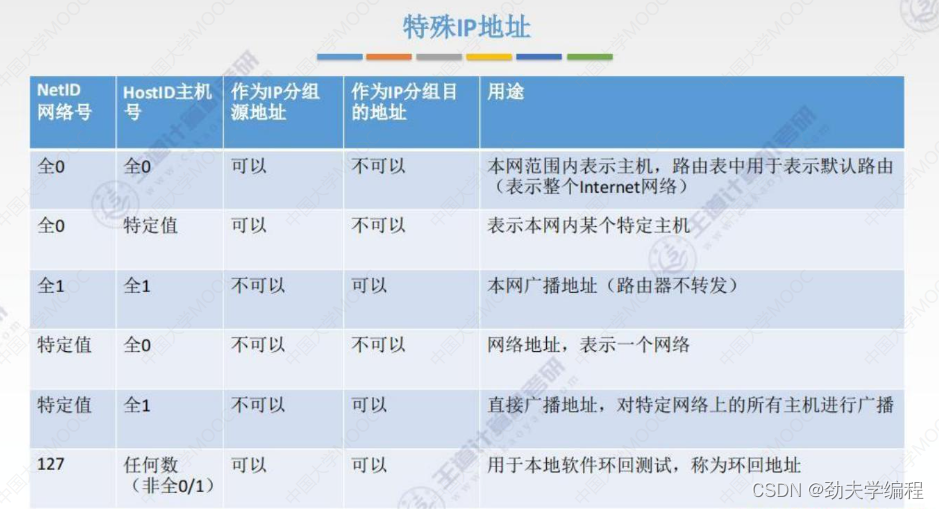
IP地址必须是有意义的,一定要分配给主机的某个接口或者路由器的某个接口。因为如果主机号只剩下1位了,1位要么是0要么是1。而我们之前讲过全0或全1这种特殊的IP地址是不能被指派的。
ps:全0是指本网络,全1是广播分组。
下面看子网划分的具体例子:
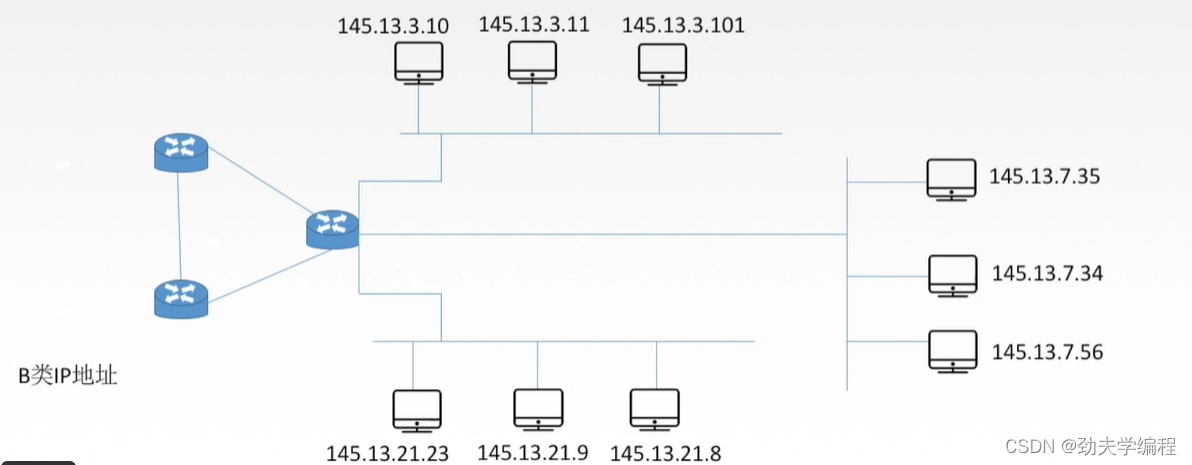
现在某单位申请到了B类IP地址。
上图的路由器相当于是单位的保卫处,任何一个想要进入这个单位的数据报/IP分组都需要经过这个路由器才能够进入到这个单位的各个主机中。
现假设路由器连接的网络地址是145.13.0.0
也就是说所有能到达上图这样一个网络的分组都会经过这个路由器,再转发到这个单位的各个主机中。也就是说,只要有一个数据报它的目的地址是145.13.xx.xx,只要是这样的数据报,它都会经过这个路由器。
而进入单位中后,可以看到下图这个单位是划分了三个子网。我们这里假定子网号占8位,主机号也占8位。即使划分了子网,这个路由器所连接的网络,对外展示的仍然是一个网络。因为外面不知道这个单位内部进行了怎么样的子网划分,只知道是145.13.0.0这样一个网络。
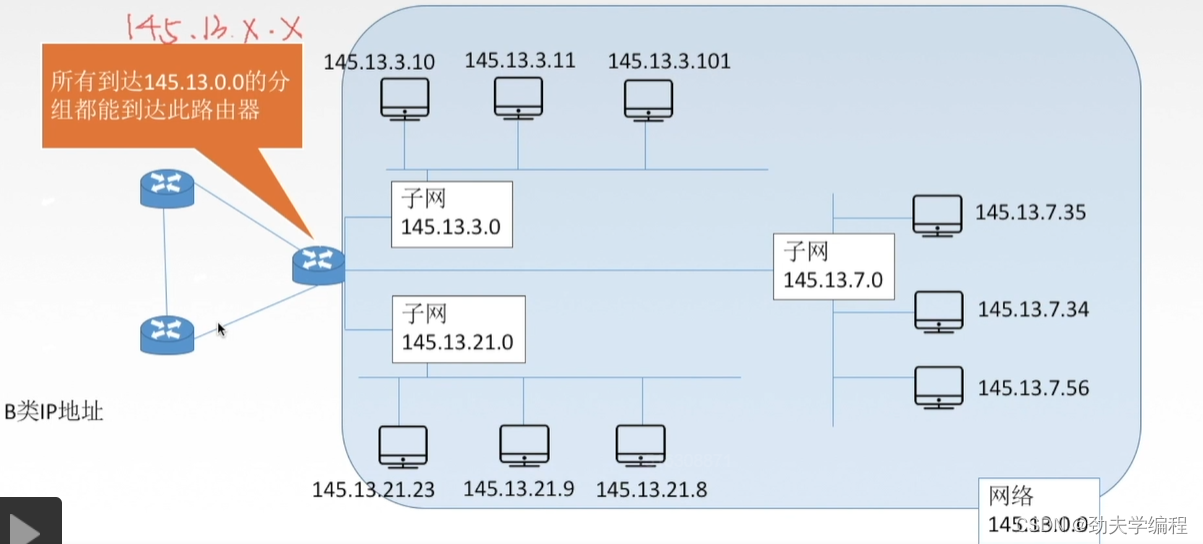
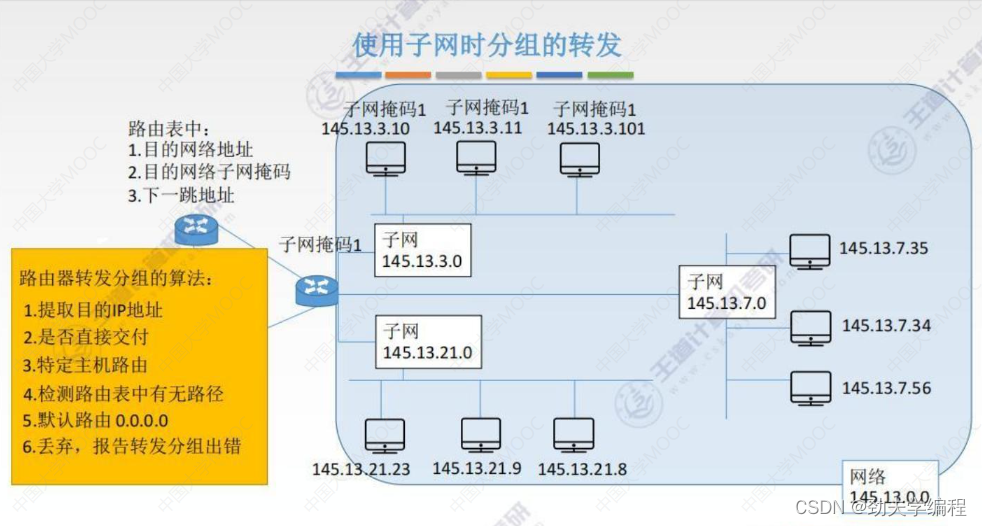
现在假定有一个数据报,它的目的IP地址是145.13.3.10,也就是它想发给下图红色圈圈出来的主机。

但它作为外部世界过来的IP分组,它只知道我应该传给这个路由器,但是怎么传给接下来的主机呢?这就涉及子网掩码了。
首先是刚才那个数据报,表示成二级IP地址是下图这样。橙色表示网络号,蓝色表示主机号。
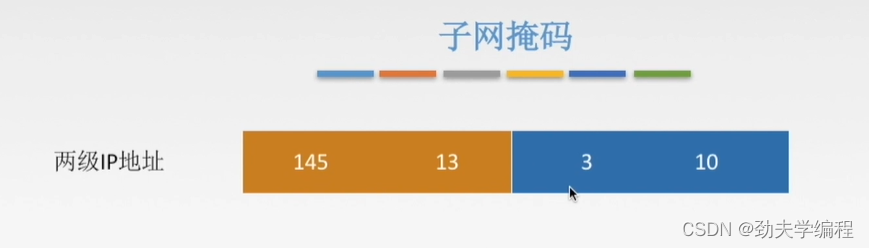
二级IP地址会有一个它对应的子网掩码,可以看到这个子网掩码还是很简单的,网络号就是全1,主机号就是全0。用点分十进制表示就是子网掩码255.255.0.0,也就是说子网掩码是由一系列连续的1和0构成的。
1的个数取决于网络号的个数,网络号有多少位,1就有多少位。剩下的主机号自然对应的就是0的位数。
如果要使得一个外部世界的IP分组进入都本单位的一个子网的某一台主机内,就需要那个路由器实现一个识别的功能。它需要从收到的IP分组中提取这个目的IP地址,进而根据这个目的IP地址判断应该发给本单位的哪一个子网,然后再发送给那个子网。
因此就会把这个分组再写成一个三级IP地址的形式,这里就要把子网号提出来了。
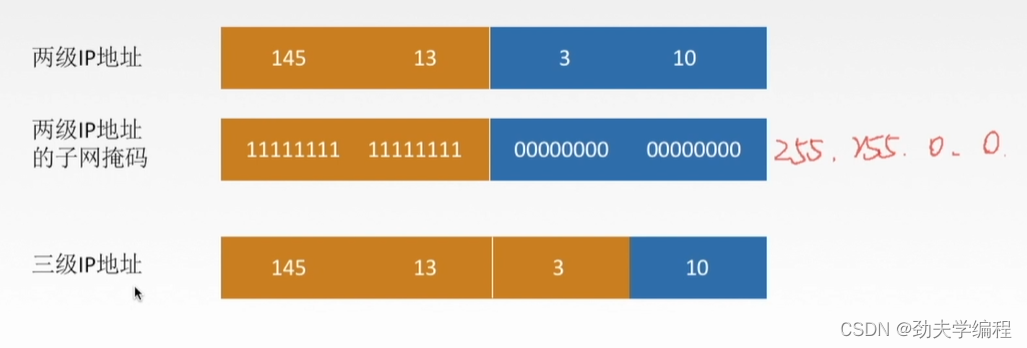
这个三级IP地址它的子网掩码,就是算上了子网号,剩下的主机位数才是对应全0的位数

不管是二级还是三级IP地址,你就记住主机全0,其他部分都是1
那知道了子网掩码怎么知道数据报是要分给哪个子网?这里就需要进行一个与的运算,用子网掩码与IP地址逐位相与,就得到了子网网络地址。
按上图的例子,也就是把145.13.3.10和三级IP地址的子网掩码相与。
ps:与运算:全1为1,遇0为0,其实就是&&这个
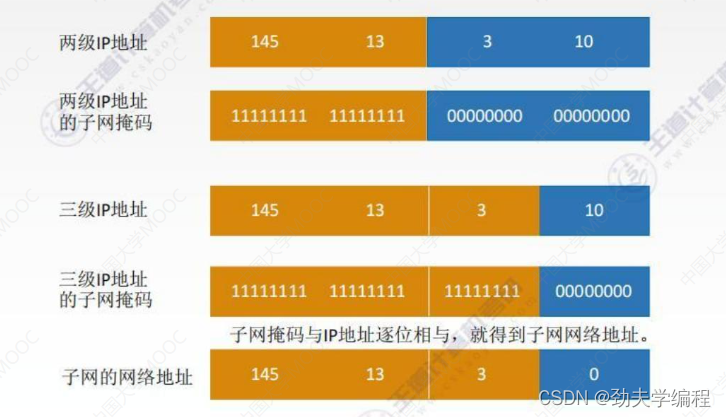
相与后就得到了所需的子网网络地址。
下面看一下具体的例题:

现在已知主机IP地址,也知道它所配置的子网掩码,怎么知道网络地址?
这个很简单,只需要用IP地址和子网掩码相与。
这个相与的过程并不需要把所有的位都写出来,我们只需要看子网掩码的第三个地方。因为前面都是1,相与出来肯定还是原先的141.14。而子网掩码的最后一个全是0,相与出来肯定全是0,所以只需要看第三位怎么样即可。


72对应的二进制数是 01001000
192对应的二进制是是 11000000
相与结果 01000000
相与结果对应的十进制就是64
因此我们对应的网络地址就是141.14.64.0
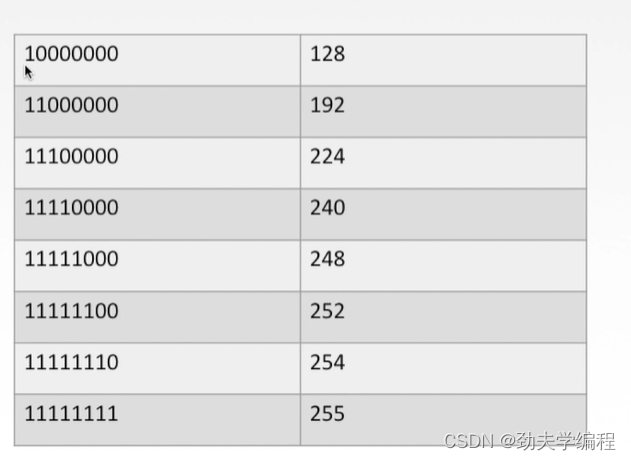
下面是二进制和十进制一些常见的对应,大家可以简单记一下

广播分组就是广播地址,它提示我们目的地址一定是一个广播地址。广播地址的特点就是主机号全1。这样我们就可以排除A选项。下面我们进行详细判断,首先子网掩码的第三个自字节是252,它对应的二进制数是1111 1100。我们根据子网掩码就可以判断出来,前面22位都是1(255.255.252前面一共是8+8+6个1还有2个0),然后剩下的10位是主机号
主机号全0,剩下的全1。已经知道全1的有22位,那剩下的32-22=10是主机号的位数。
上图中IP地址的第三个字节77对应二进制0100 1101,如果我们是需要向该主机所在子网内发送一个广播分组,那就需要看这个IP地址中子网号的部分,我们根据这个子网掩码知道了子网号是占6位(B类网络的网络号是16位,这里网络号是22位,说明有6位子网)
所以我们取77二进制数的前6位,0100 11,然后子网号后面都是主机号了
还原一下是0100 1100(后面补的两位0是属于后面主机号的0),转换成十进制是76
也就是180.80.76,这个就是这个主机所在的子网号
而我们所需的目的地址,也就是题目中要的广播分组,那就是把主机号全改成1即可
是22位网络号,也就是该子网的网络号不变,把后面的全改成1


也就是变成了180.80.79.255
九、无分类编址CIDR

1992年的时候B类地址很快就分配完毕了,因为B类地址是用2字节作为网络号,2字节作为主机号。相对A类和C类,B类这种居中的划分方式是性价比最高的。
除此之外,路由表当中的这个表项,它是在急剧增长的。因为网络的普及,越来越多的设备加入到互联网中,所以每一个路由表里面的项目从原来的几千个增长到后面的几万个。对于一个很庞大的路由表来说,这是很难维护的。
于是人们就发明出一种无分类的编址形式,CIDR就是在子网这个概念的启发之下,把整个网络号和子网号合并在一起,称之为网络前缀,再次回到了二级IP地址的形式。虽然看起来似乎回到了起点,但是它和之前的网络号、主机号是不一样的。这个网络前缀的位数是可变长的。所以它可以很灵活的调整网络号的长度,自然就调整了主机号的长度,所以CIDR这种形式现在也被广泛的使用起来了。

那当我们又回到了这种IP地址,如何表示它的网络前缀呢?只需要在IP地址后加一个斜杠/,比如128.14.32.0/20
对于网络前缀都相同的,我们会给它起一个名字叫做CIDR地址块

取20位作为前缀,那我们就把前20位进行一个标粗,那剩下的12位就是主机号。
那我们就可以根据这样一个地址形式来判断它所在的CIDR地址块里面,最小地址和最大地址分别是什么,其实也就是把剩下的主机号换成全0或者全1

这个地址块就是128.14.32.0/20,也就是主机号全0表示本网络,这个网络就是CIDR地址块。
我们也可以称之为/20地址块
虽然无分类编址消除了划分子网的概念,但它还是会沿用子网的一些名词,这里有一个地址掩码的概念,也可以称之为CIDR里面的子网掩码。它和之前学过的子网掩码一样,都是由m个1在后面接上n个0表示。1所在的位就是网络号所在的位置,剩下的0表示的是主机号的位置。
对于/20地址块其实就是下图这样一种子网掩码的表示形式,也就是网络前缀有多少位,子网掩码的1就有多少位。

来看一个例题加深一下理解:

对于上面这个地址,我们可以看到,它用的是无分类编址的表示形式
/27表示有27位网络前缀,也就是说网络号占27位,主机号占32-27=5位
问题1:这个地址块包含多少个ip地址?
答:25个
问题2:地址块的最小/最大地址?
答:最小地址就是令主机号全0,最大地址就是令主机号全1
因为这里网络号占27位,那192.199.170.82的前3个数都可以不看
就看82,转换成二进制是01010010
前3位还是网络号,后面5位是主机号
把主机号全换成0或者1即为所求。

问题3:CIDR地址块是多少?
答:也就是把主机号全0表示本网络,其实就是问题2求的最小地址。
问题4:这个地址所在的CIDR地址块,它的子网掩码或者地址掩码是多少?
答:即网络号27位全1,剩下5位主机号全1,这就是子网掩码。
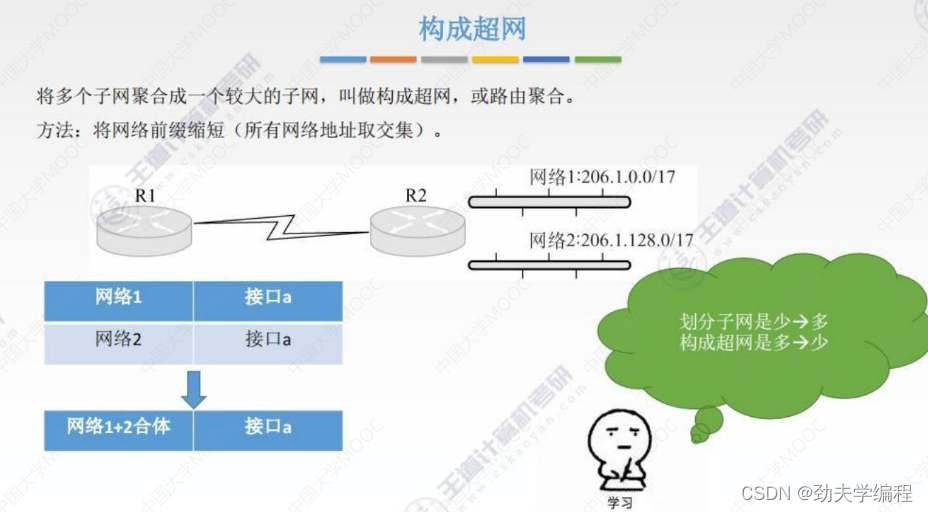
构成超网,这是指将多个子网聚合成一个较大的子网,叫构成超网(也可以称为路由聚合、地址聚合)
上图有一个路由器r1和r2相连,r2有多个端口。其中一个端口连着网络1,另一个连着网络2。
那么r1这个路由器就要维护一个路由表,这个路由表里面所包含的主要信息就是包括目的网络,以及要传到这个目的网络要走哪个接口。
我们r1到r2和r2到r1都是走一条路,它们就都会记录一个接口a。
如果后面连的网络增加,下面的路由表也会继续往下进行填充,如果这个路由表的表项疯狂增长的话,其实路由器是不好维护的。
因此,我们在CIDR这里会提供一个路由聚合的方式。具体的方法就是把网络前缀缩短以达到下图这样的效果。
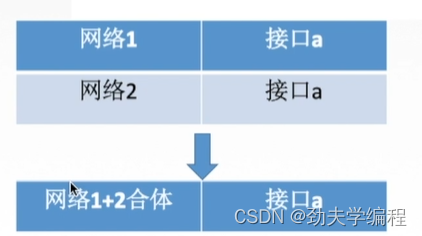
最后这个r1的路由表就可以把相同接口的合并到一起形成一个新的网络。这个网络如何来求,其实就是将所有网络的地址取交集。
首先这个网络的网络前缀都相同,都占了17位。那这两个网络的前两个字节肯定是相同的
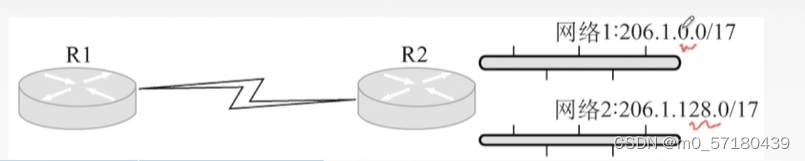
所以这里我们只需要看最关键的第三个字节,一个是0,一个是128
0转换成二进制就是 0000 0000
128转换成二进制就是1000 0000
如何求合体后的聚合网络?只需要将这两个网络的网络地址取交集,那这两个网络的前16位都是一样的,但是17位就不一样了。那我们只能取前16位做它们的合体网络
也就是206.1.0.0/16
我们求的是网络地址,网络地址是网络号前16位不变,令后面主机号全0。
下面是构成超网的一个例题:

某路由表中有转发接口相同的四条路由表项,也就是说对于这四条路,他们在这个路由器里面都会走相同的一个转发接口,因此就可以把这四个路由进行聚合,其目的网络地址分别就是上面问题中几个。现在要我们求聚合后的目的网络地址。
首先把四个网络地址写下来,可以发现它们都是21位的网络前缀,也就是除了前面这两个字节,第三个字节又占用了5位作为网络号。剩下的32-21=11位作为主机号。

记下来我们就把关键的第三个字节形成二进制

可以看到,第三个字节前3位是一样的,后面就不同了。所以我们取交集就取到第三字节的第3位即可。

所以我们的前缀位数=8+8+3=19位,所以排除BD选项
而四个地址合并之后,19位后的应该是主机号全0,
也就是聚合后的目的网络地址第三个字节是001 00000 转换成十进制是32
所以答案选C

来看一个例题:

我们只需要用一个目的地址,和这几个网络的掩码按位相与,然后看是否匹配。如果匹配成功,再来看所有成功的这些目的网络里面,谁的网络前缀最长,就选那个路由器。
ps:图中全0的目的网络是默认路由,也可以称之为默认网关,什么时候可以用到它?就是在所有的路由表的目的网络中没有任何一个目的网络是和我这个分组的地址相匹配,那这个时候就需要走默认路由。默认路由接下来会交付给另一个路由器进行同样的一个过程。
下面我们来详细算一下:
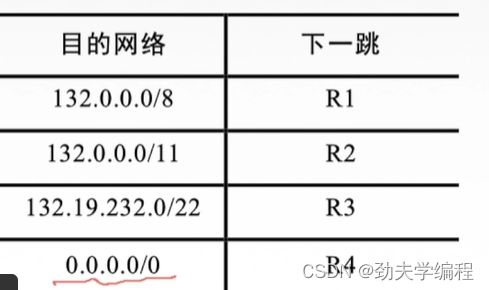
进入R0的分组的目的地址132.19.237.5
对于132.0.0.0/8这个目的网络,它的子网掩码是前8位为1,后24位为0
然后子网掩码和这个目的地址按位相与,根据这样一个子网掩码的形式,我们可以直接得到他们两的匹配结果是132.0.0.0/8,这个是匹配的
再看132.0.0.0/11,它作为网络前缀,子网掩码是前11位1,后21位0
然后子网掩码和这个目的地址按位相与,
子网掩码第二个字节是 1110 0000
目的地址第二个字节19转换成二进制是0001 0011
相与结果是 0000 0000转换成十进制是0
所以第二个字节还是132.0.0.0/11,也是匹配成功的
接下来看第三个目的网络132.19.232.0/22,它的网络前缀是22位,所以它的子网掩码前22位是1,后面的32-22=10位是0
也就是第一二个字节全1,第三个字节前6位是1,后2位是0
子网掩码第三个字节是 1111 1100
目的地址第三个字节237转换成二进制是1110 1101
相与结果是 1110 1100转换成十进制是236
匹配结果就是132.19.236.0/22,这个匹配结果和目的网络是不匹配的。
综上我们是在132.0.0.0/8和132.0.0.0/11两个匹配结果中选一个,而我们是符合最长前缀匹配规则,所以我们选择132.0.0.0/11
十、ARP协议
发送数据的时候需要经历一个对数据的封装和解封装的过程,但是具体封装什么内容则需要根据我们不同层次的一个协议规定。
比如说我们在网络层要加头,在链路层要加头加尾。
这两个头里面最重要的就是加了ip地址和mac地址。也就是逻辑地址和物理地址。
本节主要是把发送过程的一些具体细节讲清楚。
现在1号主机要发送数据,它发送数据就需要对数据进行封装,就需要经历五层结构。在应用层,如果主机1要发送数据给主机3(主机1和主机3在一个网段内)
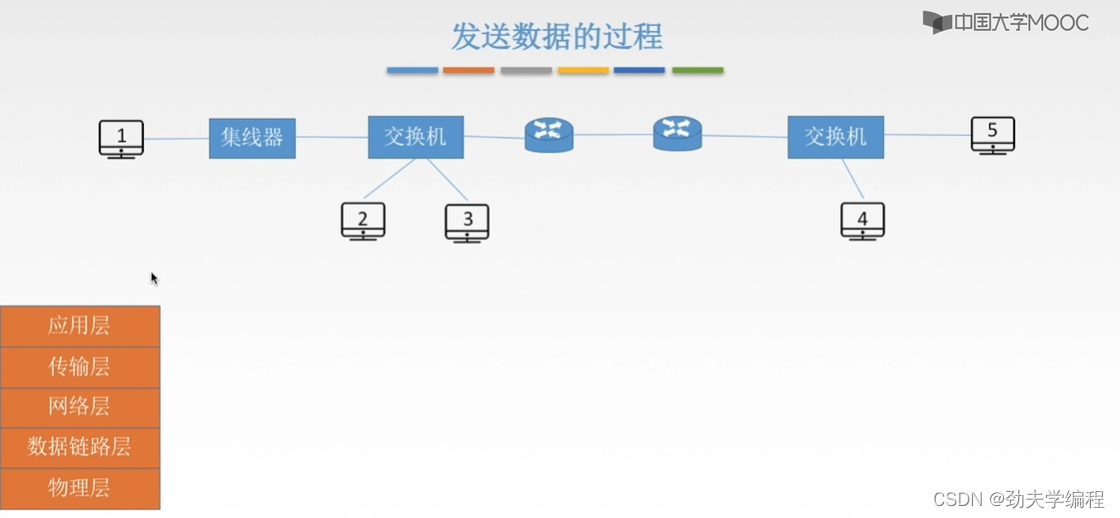
在传输层,就会把一个大报文分段,形成报文段,也就是传输层的传输单元。
这里是否需要分段需要根据应用层数据大小决定。
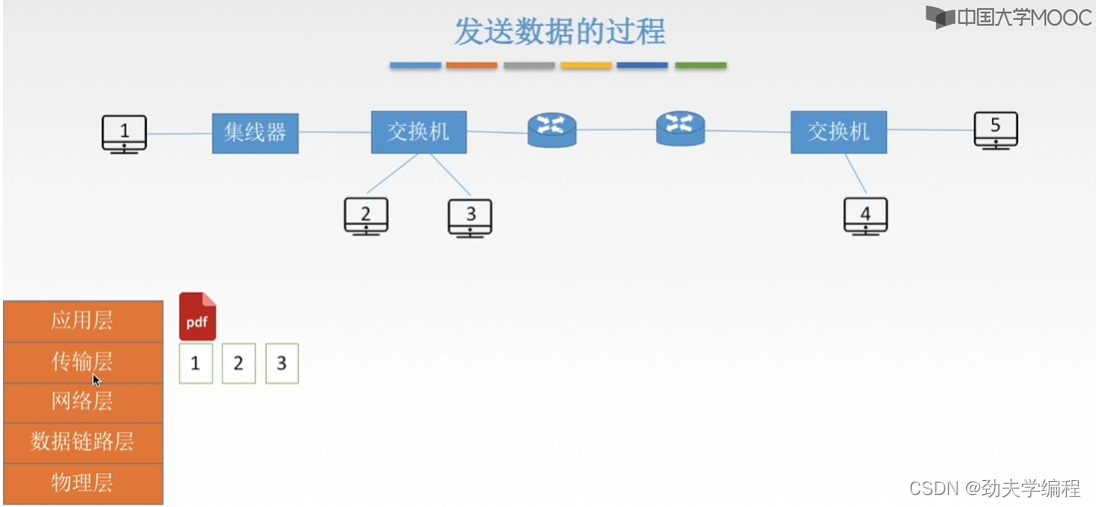
接下来到网络层,网络层就拿其中一个报文段来看,比如这里选择了1号报文段
会对1号报文段进行封装,加上ip地址,一个是源主机ip地址,另一个是目的主机ip地址。
这里的ip1是源主机填入的,ip3是怎么获得的呢?这个是传输层讲的内容,根据dns,我们可以把ip3填入。网络层就实现了这样一个封装,也就是从报文段形成了一个ip数据报(也可称为分组,分组通常是指我们数据报分片后的结果)。
至于为什么要分片,因为我们要传输的链路,它的链路层协议要求的最大传输单元有一个MTU,要根据这个MTU来决定我们要不要在网络层进行分片。假设这里就不分片了,就构成一个IP数据报。
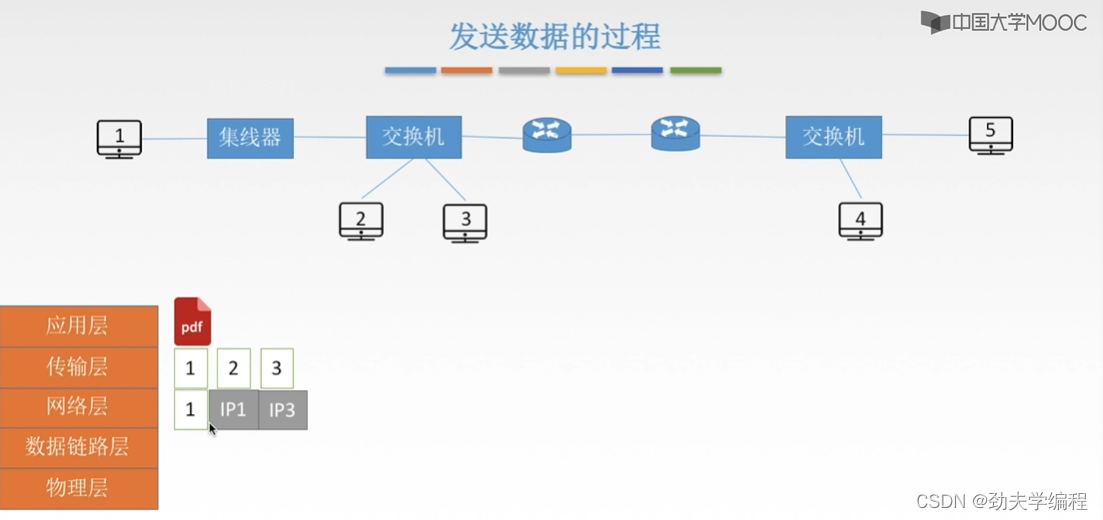
接下来到链路层封装,这里的封装就是加上mac地址,这个mac地址除了源mac地址,也就是mac1之外,还需要加入一个目的mac地址。也就是这个3号主机的mac地址。
但我们现在是不知道mac3的,怎么把mac3填入?这就涉及本节所讲的ARP协议

首先对于每一个主机以及每一个路由器,它都有这样一个ARP高速缓存,你可以想象成一个小的仓库,这个仓库里存的是ip地址和mac地址的映射。也就是某个ip地址它对应的mac地址应该是什么。
当然,这个高速缓存所存的所有的表项都是一个局域网内部的。
比如说2号主机ip地址和mac地址映射,3号主机ip地址和mac地址映射,以及左边这个路由器的左边的端口ip地址和mac地址的映射。
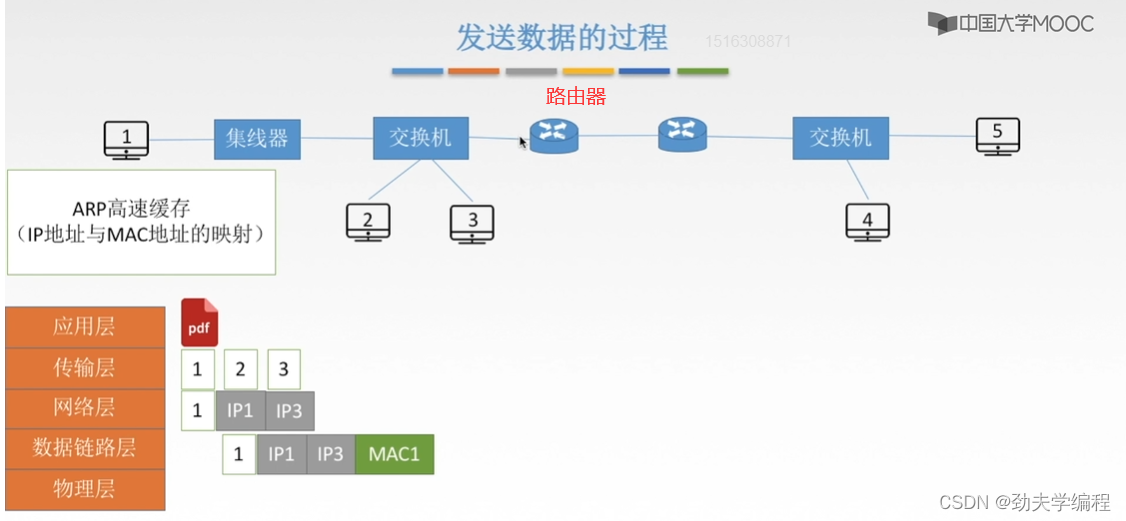
假设我们现在查询自己的这个仓库,发现1号主机的高速缓存中有一个表项,上面写着3号主机的ip地址及对应的mac地址,那我们就可以很容易的把3号的mac地址填入,然后实现一个封装(加头加尾),这里的尾部通常是FCS帧检验序列。
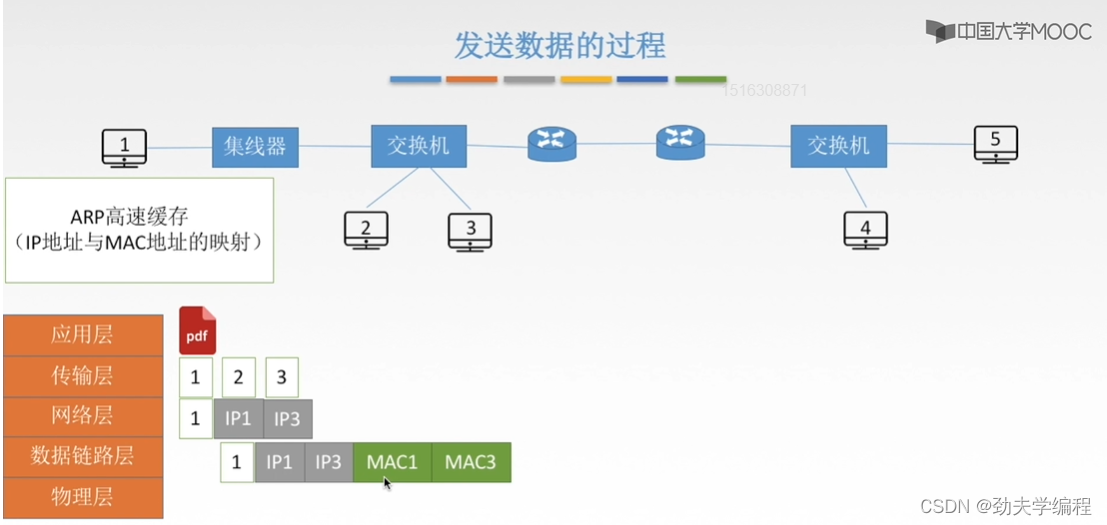
但是假如这个ARP高速缓存中并没有发现3号主机的ip地址及它的这个mac地址的映射,那我们就没办法一下子填上mac3
我们还是要使用这个ARP协议,首先是广播一个ARP分组请求,也就是这个一号主机,它要发送的这样一个数据帧,数据帧的主要部分如下:
第一个部分是它自己的ip地址,第二个是它要查询的mac地址对应的主机ip地址,第三个是它字节的mac地址,第四个则是目的物理地址。
这里的物理目的地址填的是全F,也就是全1,代表这个局域网内一个有广播效果的帧。也就是这个分组从1号主机发出来之后,经过集线器,再到交换机这里,交换机发现是广播分组则会把这个分组从交换机的所有端口转发出去。
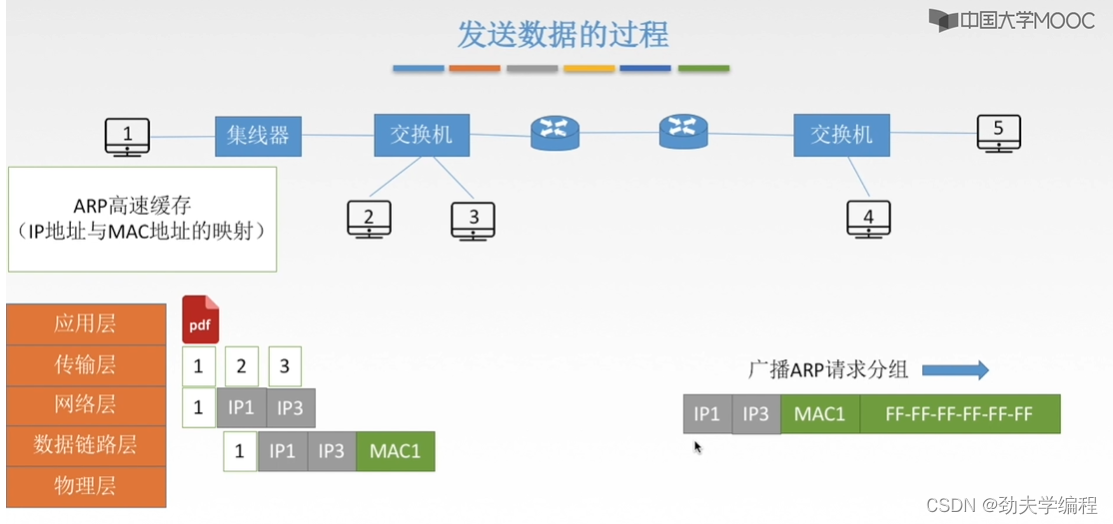
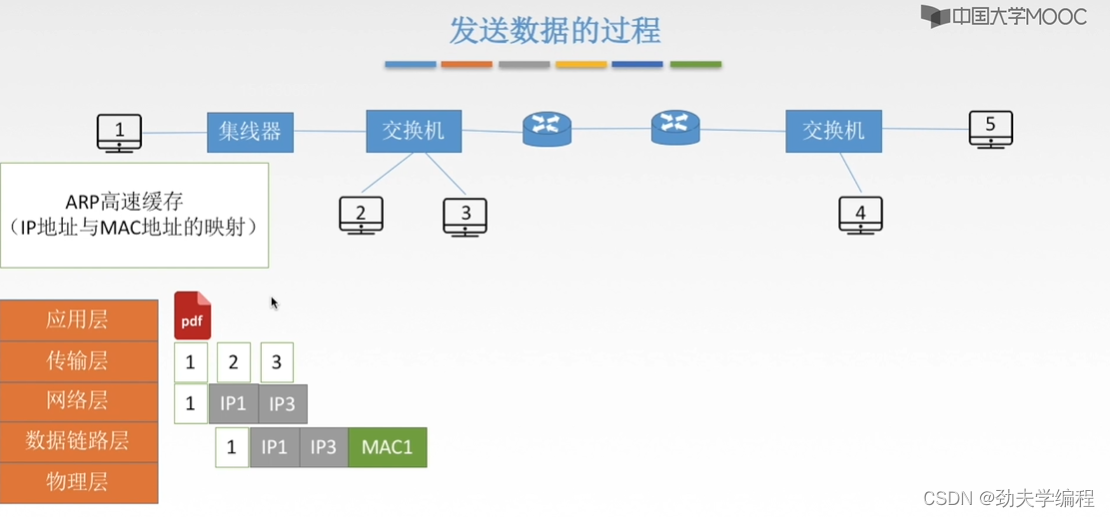
经过交换机转发,连在交换机上的所有主机都会收到,但是只有3号才会响应(因为ARP请求分组第二个参数是IP3)。
然后3号主机会返回一个响应分组,这个分组是只从3号到1号,而不会转发给其他端口。这个响应分组包括ip地址和物理地址,它会告诉1号主机3号主机的ip地址和对应的mac地址是多少。也就是把这个映射返回给1号主机。
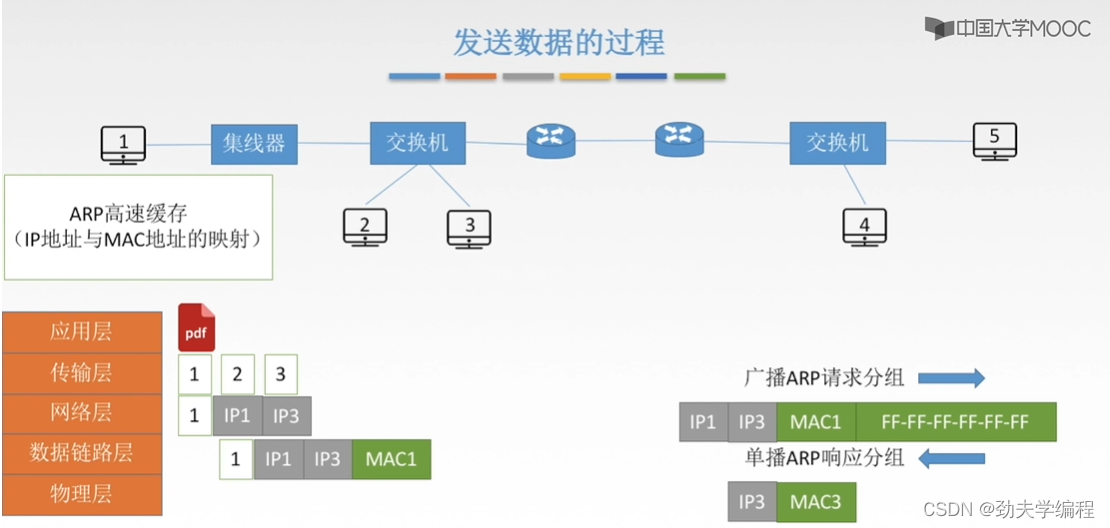
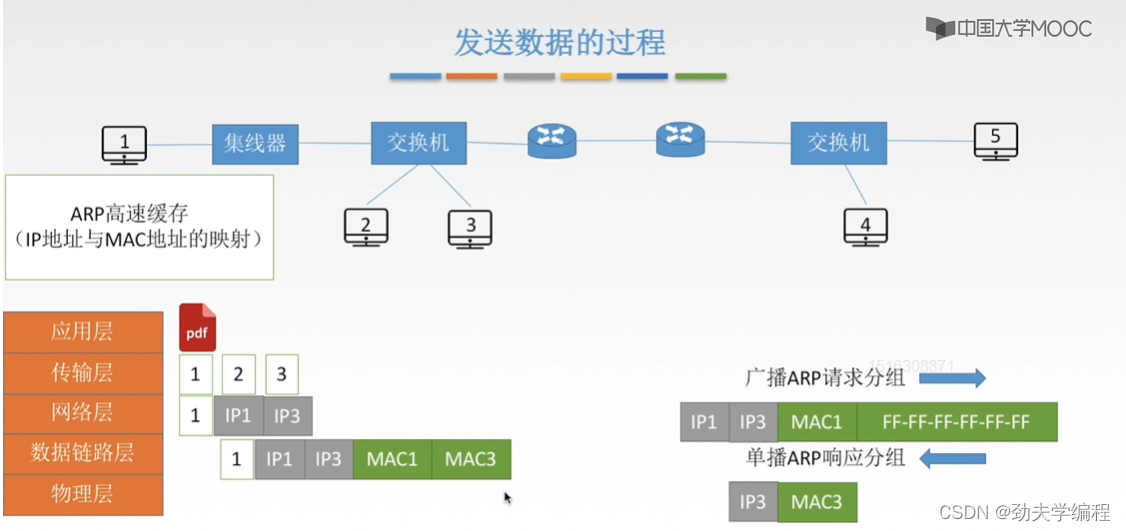
后面1号主机收到这个响应分组就知道了mac3应该填多少
下面就是封装,加一个帧检验序列,加上FCS之后就构成了一个传输单元,也就是一个数据帧,然后就可以放物理层上传输了。
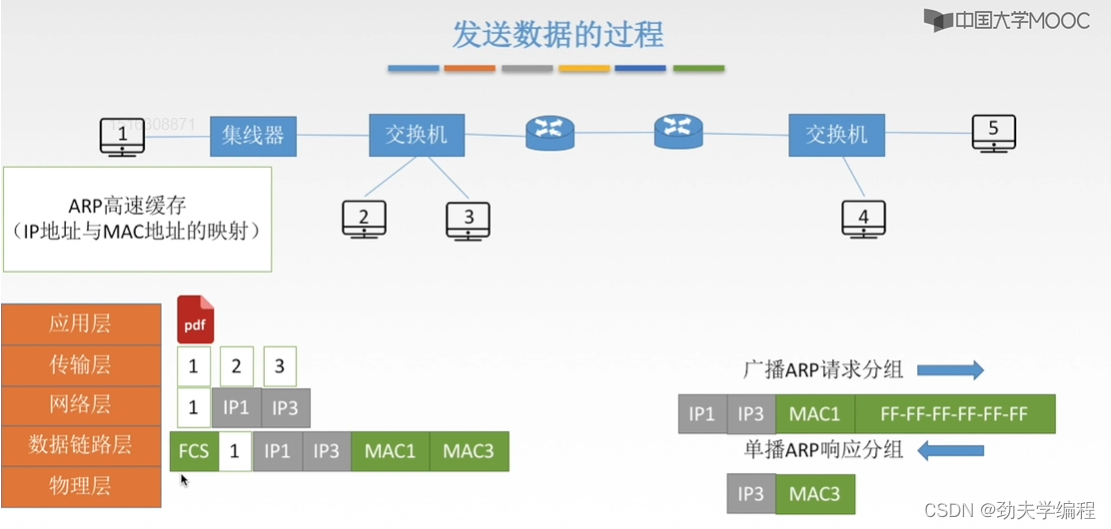
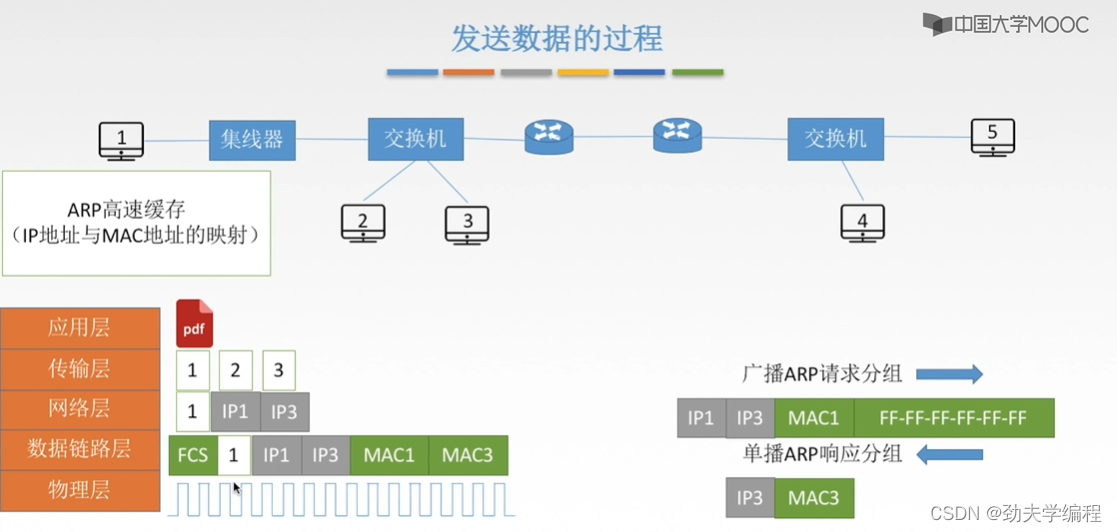
因此,这样一个文件(或者这个主机要发送的数据)就经过网络层封装ip地址,到链路层封装mac地址,然后再形成比特流的形式(或者信号的形式)在链路上传输。
上述情况是针对源主机和目的主机是在一个网络内的,如果不在一个网络内怎么办?
答案还是使用ARP协议,只不过mac地址获取方式和前面也有所差别了。
比如现在1号主机要和5号主机进行通信。
主机1要发送文件,先是经过传输层分成报文段,再到网络层对每一个报文段进行封装加上ip地址,源ip地址是ip1,目的ip地址是ip5
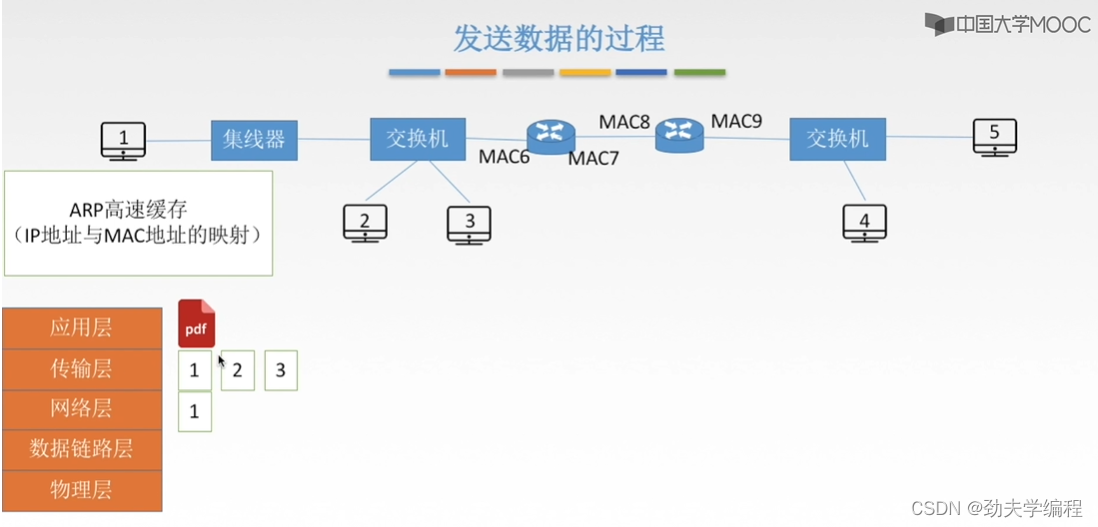
接下来到链路层封装,首先要装上原来的物理地址mac1,mac1就是自己的这个主机的mac地址,然后还应装目的主机的mac地址。
我们还是要先看一下,在ARP高速缓存中有没有ip5以及它的mac地址
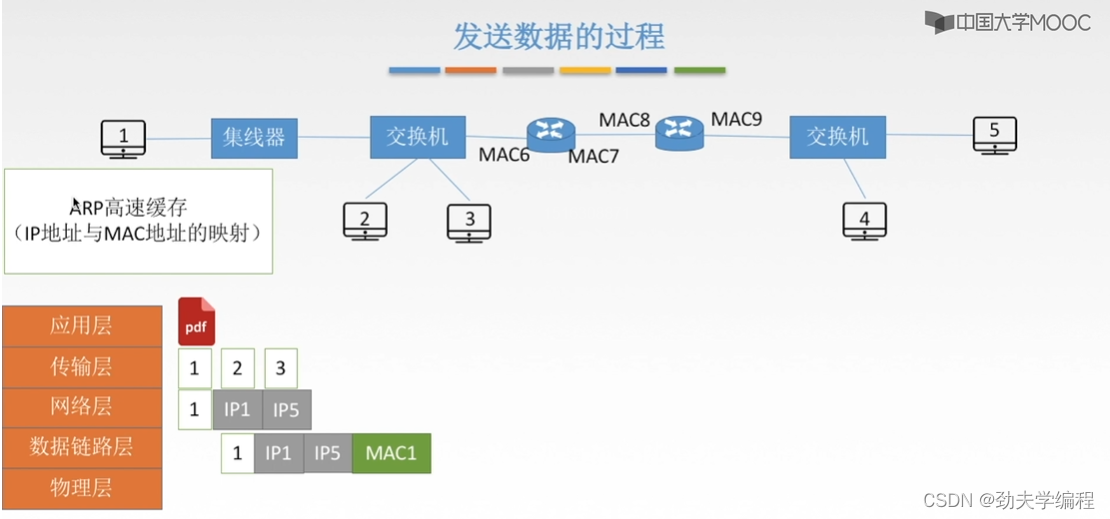
但5号主机的ip地址和mac地址肯定是没有的,因为我们知道ARP高速缓存,它内部存储的都是这一个局域网内的ip地址和mac地址映射,他肯定查不到这个5号主机的。
那1号主机就会先用自己的子网掩码和这个目的ip地址相与一下,看是不是在字节的这个网段内,后面发现不在一个网段内就需要查询默认网关的mac地址
ps:这个默认网关其实就是左边这个路由器,也就是左边这个网段和外界沟通的路由器。这个路由器是局域网连入因特网的关口,所以我们叫它网关,每一个主机都知道字节的默认网关是谁。
因此,这个1号主机发现自己的目的主机不是和自己在一个网段,它寄希望默认网关。所以这里的目的地址会填上默认网关的地址。下一跳就是默认网关。
假设我们左边这个路由器左边端口是mac6
怎么得到这个mac6?还是先发送一个ARP请求,分组依旧是广播的形式。
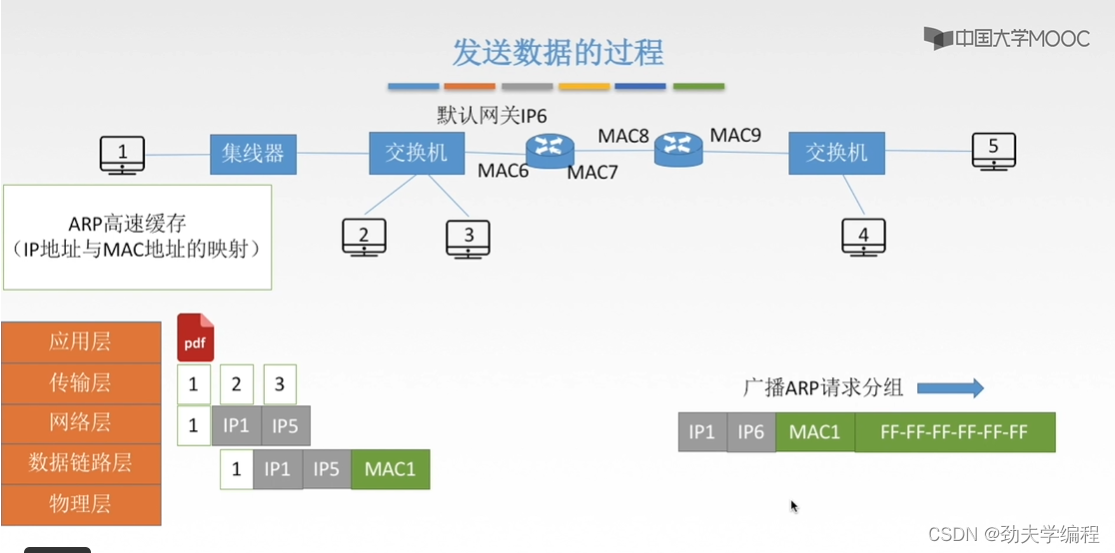
所有的设备接受到这个分组之后,只有左边这个路由器会响应这样一个请求。
然后返回一个ARP响应分组
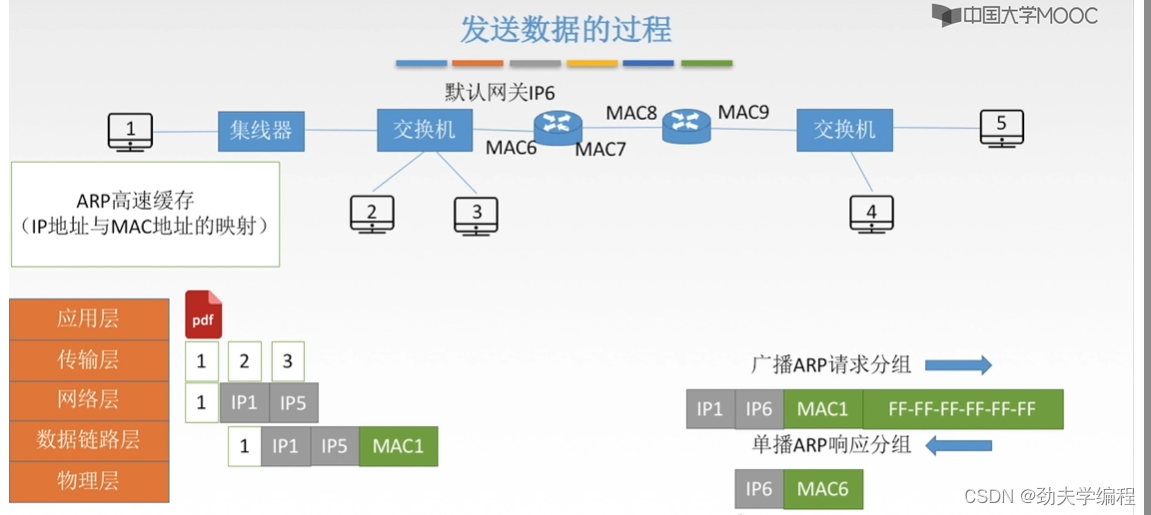
然后1号主机收到mac6,进行封装加上尾部帧检验序列FCS,然后就可以放到物理层上传输了。
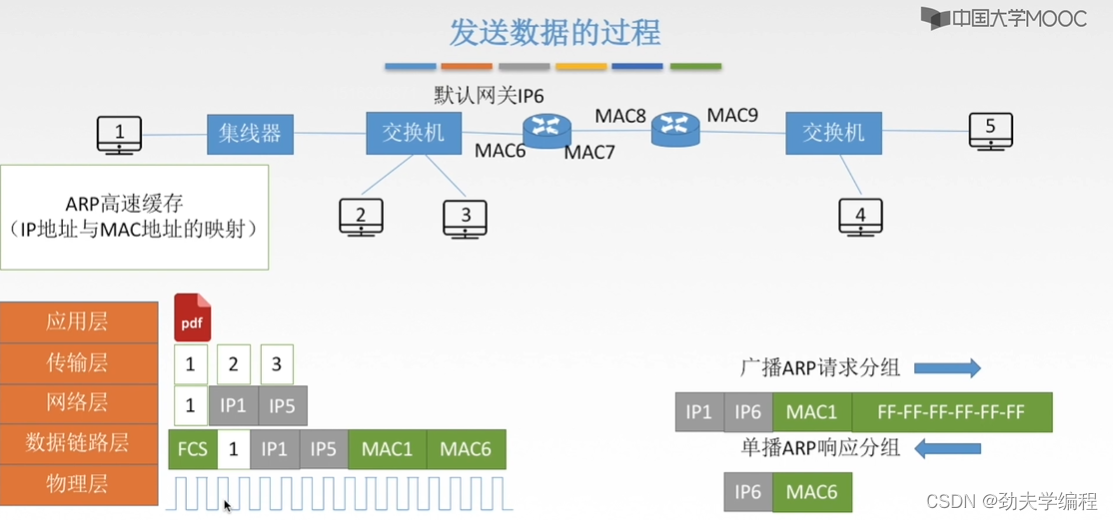
然后假设这个数据在链路上传输到了路由器这里,然后路由器会对这个数据进行一个解封装和封装。解封装就是最高到网络层,因为路由器是一个三层设备,解到网络层后再封装加ip地址,ip1和ip5是不变,但是物理地址要变了,因为这里数据到了一个新的网络内。源mac地址和目的mac地址应该由连路由器的mac7到下一个路由器的mac8
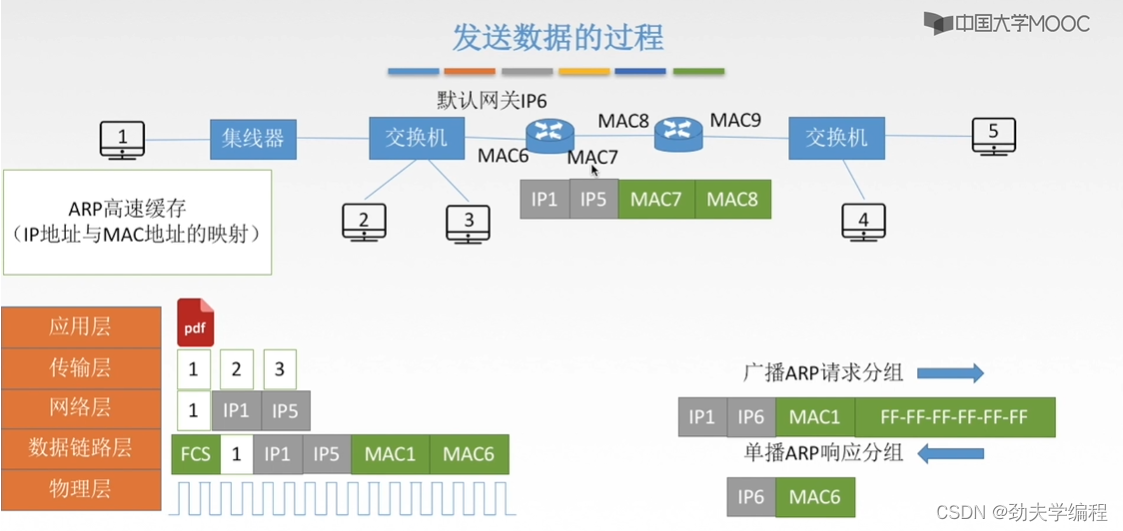
然后过程和前面类似,两个ip地址至始至终都不变,只变mac地址。
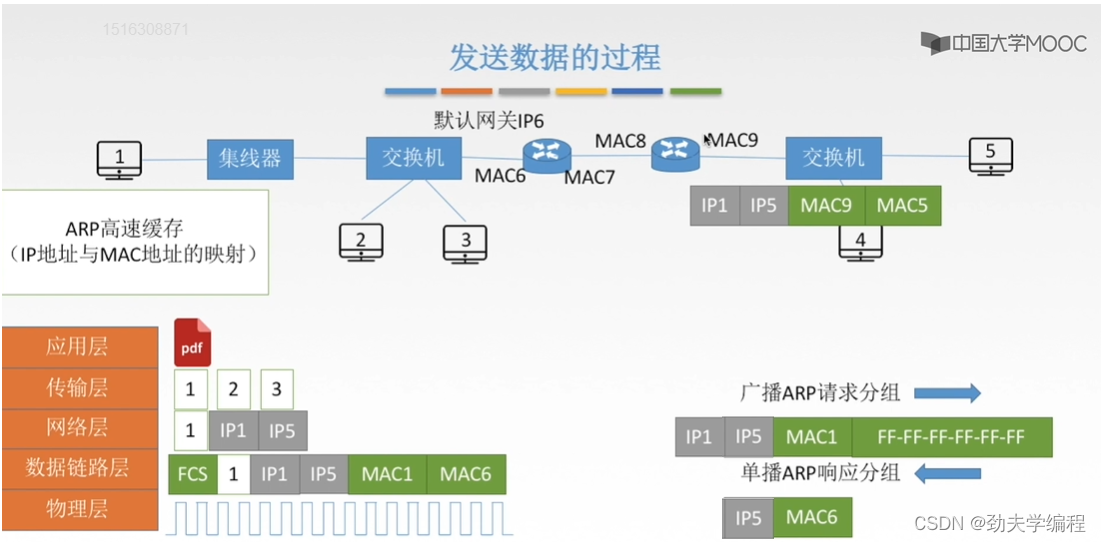
这里mac5获取方法还是和以前一样,这个路由器向它网络内所有主机发送一个广播的ARP请求分组,然后如果有对应的主机,那就会回复一个单播ARP响应分组。然后就知道了mac5。


十一、DHCP协议
我们主机在通信的时候一定要具备一个ip地址,那主机如何获得ip地址呢?
主要有两种方法,静态配置和动态配置。
静态配置:
主要配置ip地址、子网掩码、默认网关
默认网关其实是算作这样一个局域网内所有主机和外界交流的关口,通常是指一个路由器的一个接口的ip地址。

动态配置:

每个教室它都可能是一个网段,对于每一个网段内,其实都会有几台DHCP服务器、交换机、主机。。。
因为我们在教学楼里面我们的手机和电脑,这种不是长时间固定在一个位置的。所以我们就需要给这种移动设备动态的分配一个ip地址,这个就是DHCP服务器分配的。
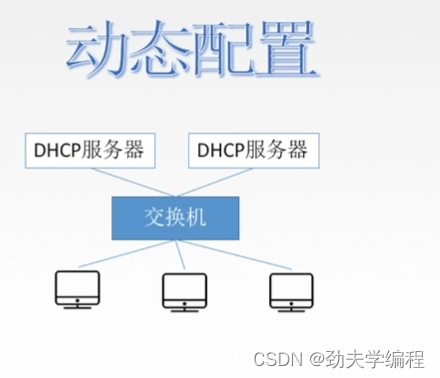
如果某台主机离开了作用范围,刚才给它分配的ip地址就会收回了。

十二、ICMP协议
ICMP协议是在网络层和传输层之间的协议,所以这个ICMP协议是起到一个桥梁的作用,它的作用就是为了更有效的转发ip数据报和提高交付成功的机会。
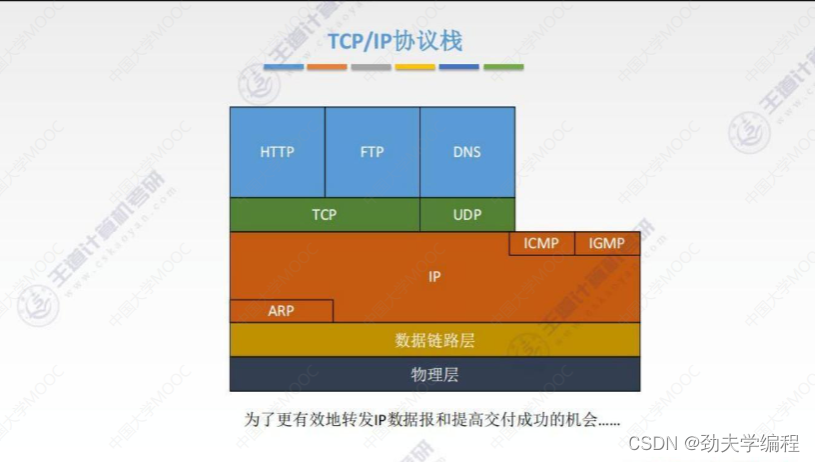
通信的过程中,总会有一些分组会出错。对于出错的分组,我们在网络层的处理就是把它丢弃掉,丢弃完之后还需要发送一个ICMP差错报告报文。

下面我们来看一些ICMP报文的一个结构:
ICMP报文是装在IP数据报的数据部分,ICMP协议是网络层的协议,它作为数据部分再加上IP数据报的首部就形成了一个数据报,就可以发出去了。
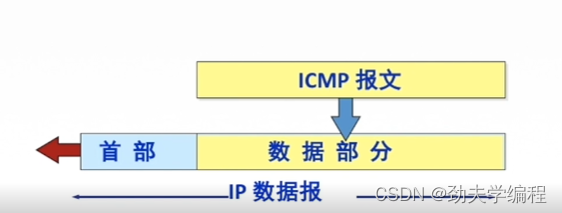
ICMP报文具体如下:
首先是1个字节的类型、1一个字节的代码、2个字节的校验和
然后4字节是取决于ICMP报文的类型
再往下是数据部分,它的长度也是取决与ICMP报文的类型。

ICMP报文主要有两种类型:



ps:组播是一点到多点,广播是一点到所有点,注意区分。


十三、IPv6

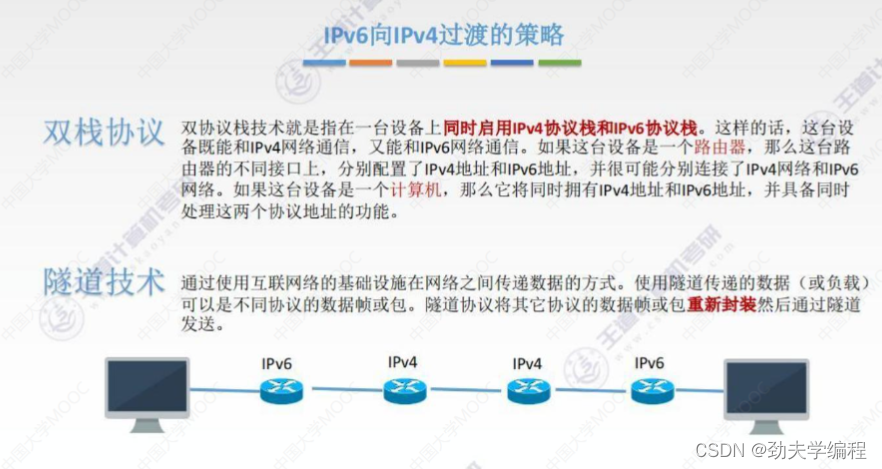
随着时代的发展IPv4的地址很快就被耗尽了,尽管后面出了CIDR和NAT技术,但是也治标不治本。
于是就出现了新的方法,也就是IPv6,这个可以根本上解决地址耗尽的问题。因为IPv6是从地址的位数上来扩充长度的,该方法是解决地址耗尽的根本方法。
举个例子,我在上海买个房子,这房子非常小,md为了尽可能利用空间只能在墙上放一些小格子然后在小格子里面填满东西。这就类似CIDR和NAT技术,它只是在原来地址长度的基础上,对地址进一步划分。而IPv6这种方法就像是我直接买了个超大号的别墅,再也不用拘束了!
另外,由于IPv4它首部除了固定部分之外还有一定可变部分,并且那固定部分(20字节)占的字段多了,所以也需要改进一下首部格式,使得这个字段变得少一些。这样还能加快路由器的处理效率。
简言之:需要改进首部格式来实现一个快速处理和转发数据报的功能,另外就是要支持QoS
ps:QoS就是服务质量
下面看一下IPv6数据报的格式:

IPv6数据报包括两个部分:一个是基本首部,另一个是有效载荷
有效载荷又包括两部分:一个是选项部分,它里面是各种扩展的首部;另一个就是数据部分。就相当于我们把IPv4中的可变部分挪到了这个有效载荷中。
所以这里IPv6的基本首部就是固定的40字节,这些扩展首部其实就是对于这个数据报有一些新的要求,比如说这个数据报要增加某些功能,就放到这个扩展首部中来实现。
所以IPv6这种数据报格式,因为它有了扩展首部的部分,所以使得原来的IPv4首部中一些不必要的部分就可以先不用了,如果需要用的话,就直接把它放到扩展首部中就可以了。
下面是IPV6数据报的格式,基本首部占固定40字节,有效载荷是不固定的(它包括可扩展首部和数据部分)

扩展首部是可有可无的,根据我们的数据报的具体要求,看他要不要提供其他服务,如果需要就在扩展首部这里填充。
版本:
这个和IPv4数据报的版本是一样的,都是指明了这个协议的版本
IPv6协议版本字段就是6
优先级:
这个其实就是在区分数据报的类别,以及声明这个数据报的优先级,是否要对这个数据报进行优先处理,就是要看这个优先级怎么规定。
流标签:
“流”是指互联网络上从特点源点到特定终点的一系列数据报,所有属于同一个流的数据报都有同样的流标签。
就比如A主机要给B主机发送一系列的数据报,这一系列的数据报都像是一组的数据报,所以我们就可以称之为一个流的。一个流中的所有数据报,它们的流标签都是一样的。
这有点类似我们IPv4中的标识位,IPv4中的标识位是指对这个数据报分片之后,每一个数据报它的所有分片都具有同一个标识位。
有效载荷长度:
顾名思义就是有效载荷部分长度有多少位。
这里要和IPv4区分,IPv4标识长度有两个字段,一个叫做首部长度字段,另一个叫做总长度字段。首部长度字段是指首部的大小,总长度则是首部+数据部分大小。
这里的有效载荷长度是指扩展首部加数据部分大小。
下一个首部:
下一个首部标识的是下一个扩展首部或者上层的协议首部
假如我们现在有一个数据报,这个数据报除了基本首部40字节之外,它还有3个扩展首部(假设为扩展首部1、扩展首部2、扩展首部3),然后就是数据部分。
对于这3个扩展首部,它们都有一个字段,也就是下一个首部字段。
基本首部也有下一个首部字段,基本首部的下一个首部字段就是扩展首部1,
扩展首部1的下一个首部字段就是扩展首部2
。。。
扩展首部3的下一个首部字段就是数据部分。
跳数限制:
跳数限制相当于IPv4中的TTL,也就是生存时间。
如果跳数限制变成了0,路由器就会把这个数据报丢弃,并且会返回一个icmp差错报告报文。
源地址和目的地址:
IPv6源地址和目的地址位数都是128位,在IPv4中,它的源地址和目的地址都是32位。可见,IPv6在地址上进行了非常大的扩充,基本上地球上每个沙子都能分配到ip地址。(只能说一句nb)

红色和粗体部分要记住,其他的了解即可。
我们知道IPv6的地址非常多,一共128位16个字节,如果还用点分十进制那这个地址就会非常长了。所以我们这里有一个新的表达形式:
一般形式:冒号十六进制记法

每4位我们用一个16进制数表示,每4个16进制数为1组,一共8组。
压缩形式:
就是遇到前面有0的时候,把多余的0删了就行(保证每组最少一个数字)


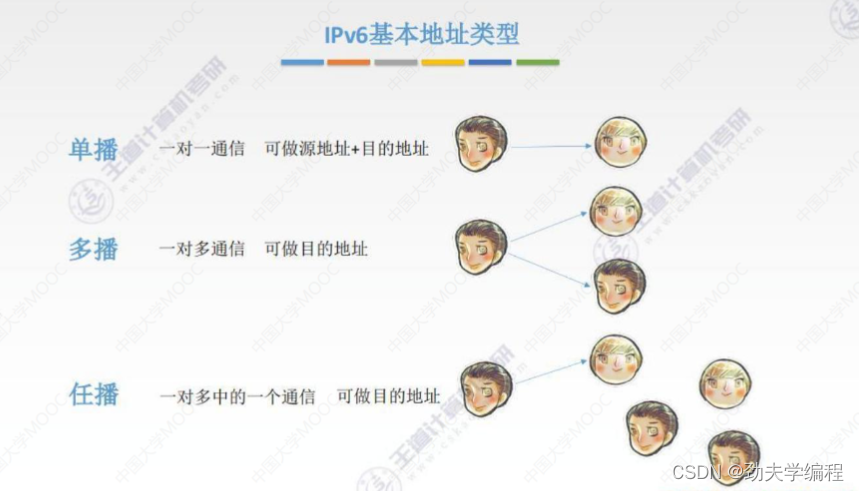
任播是IPv6独有的一种地址,它的实质还是1对1,但表现形式是1对多的一个通信。所以它也只能做目的地址
举个例子:
假设某台主机的ip数据报中封装的目的地址是一个任播地址,它就会给这个任播组内的一台主机发送数据报,这一台主机通常是离他最近的那台。
十四、RIP协议与距离向量算法
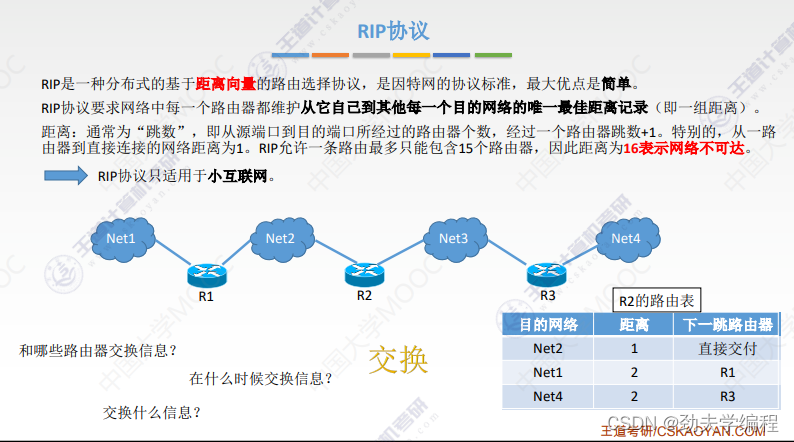
在比较小的网络中通常是使用RIP协议。
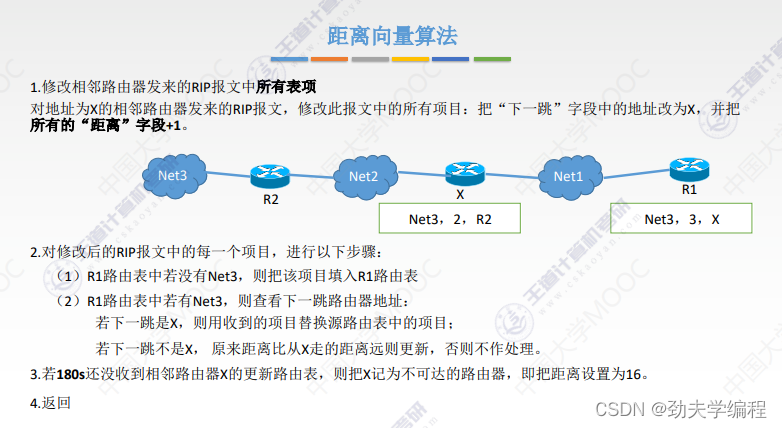
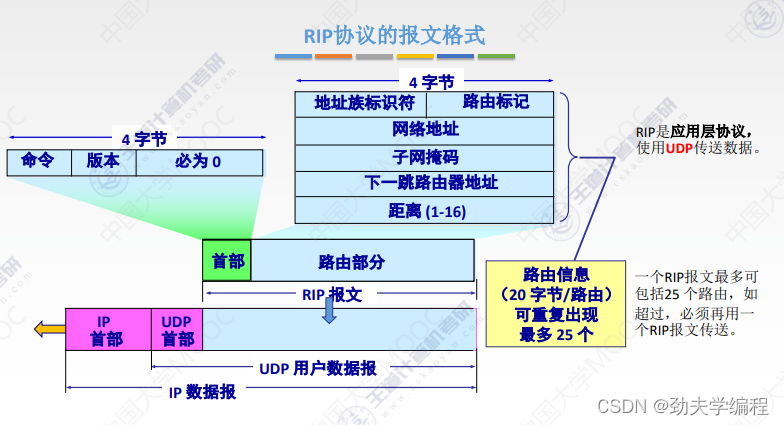
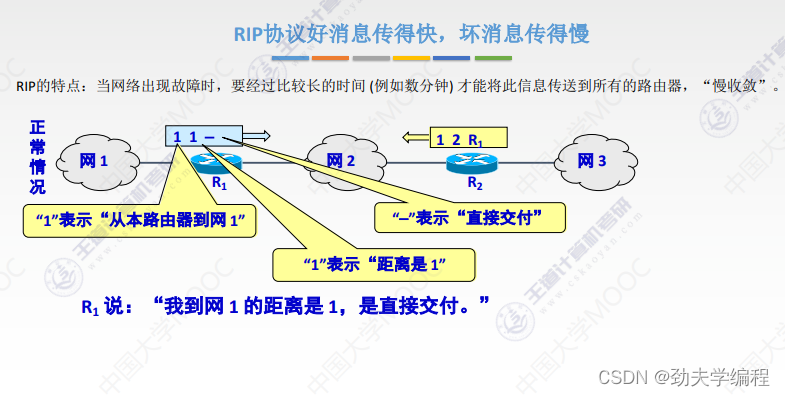
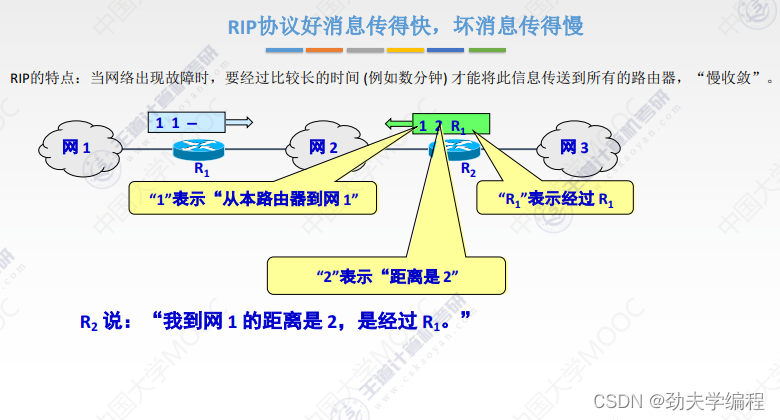
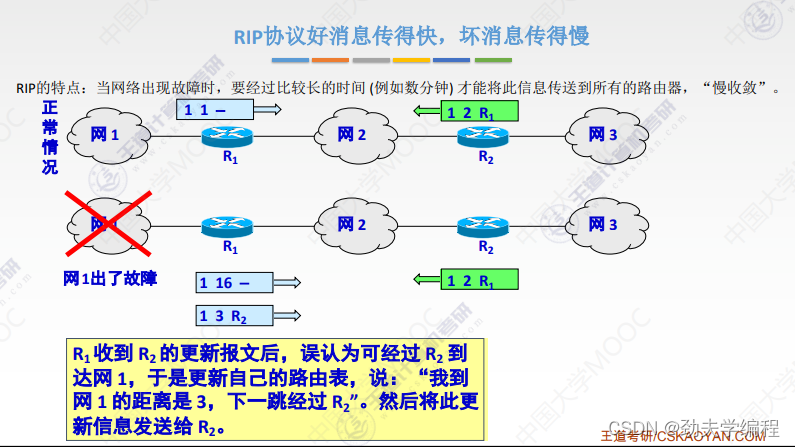
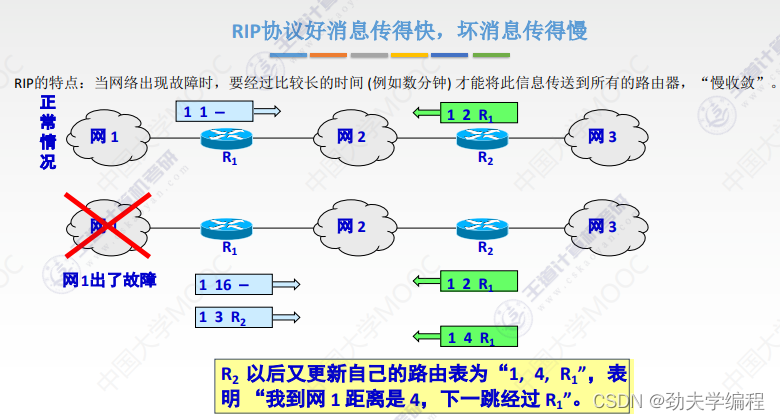
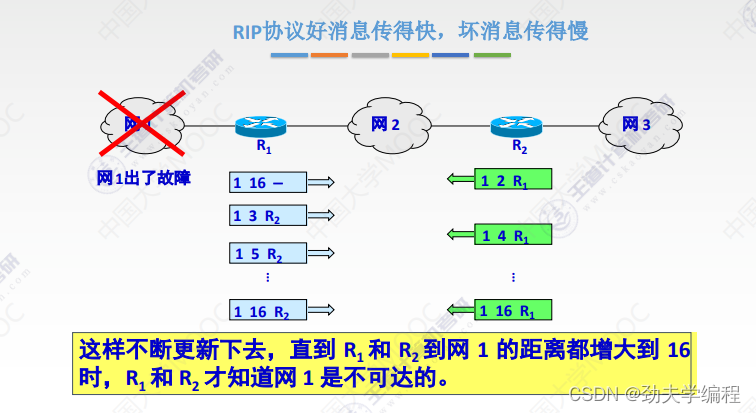
RIP协议它要求网络中每一个路由器都维护从他自己到其他每一个目的网络的唯一最佳距离记录。
每个路由器都有一个路由表,这个路由表里的表项其实就是他自己到其他的目的网络的距离记录。这个有一个要求,距离不是任意距离,而是最佳距离,也就是最短路由(经过路由器跳数最短的)。这样的路径选择方式就是最佳距离,所以称之为距离向量,就是因为它维护的是一个路由表,路由表有很多的表项,很多表项组在一起就像是一组距离。

路由器的路由表主要有3列:目的网络、距离、下一跳路由器
根据这个路由表,就可以说明这个路由器它到某一个目的网络最短距离,以及要走这样的距离下一跳应该交给哪个路由器。
这里有一个直接交付,直接交付是指这个路由器和目的网络是直接相连的。
如果是间接相连,就需要先交给其他路由器了。




十五、OSPF协议与链路状态算法


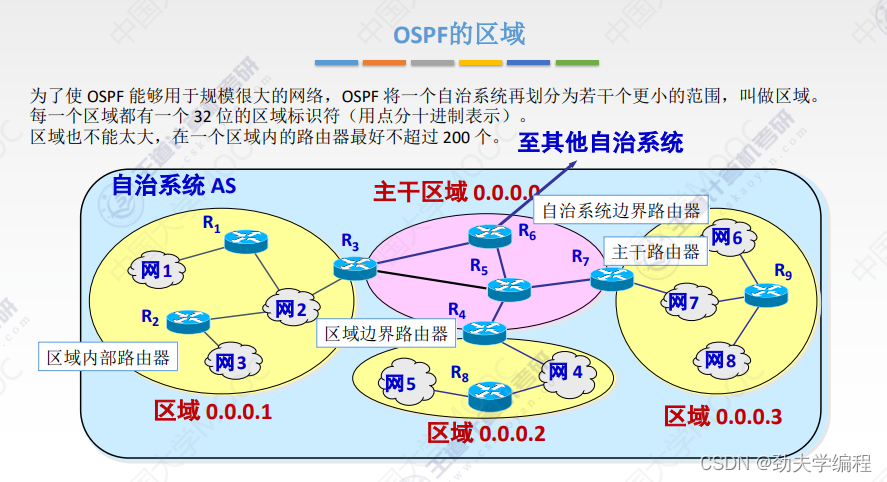
自治系统划分区域之后,他分为了两个主要的区域,一个叫主干区,另一个就是普通的区域。
主干区的标识符规定是全0的,它的作用是来连通其他的下层区域。
关于区域划分这块,还需要掌握几个非常重要的路由:
主干区域中的路由又称位主干路由器,包括R5、R6,也包括R3、R4、R7
因为R3、R4、R7在连接两个区域的边缘上,它既可以叫做主干路由器,也可以叫做区域边界路由器。
第三种路由器叫做自治系统边界路由器,因为在主干路由器中,有一个路由器它需要连接到其他的自治系统AS中,所以这个路由器叫做自治系统边界路由器。
第四种路由器是区域内部路由器,就是在普通的下层区域内部的所有路由器都是区域内部路由器。
采用这种分层次划分区域的办法,虽然使得交换信息的种类增多了,同时也使得OSPF协议更加复杂。但是这样做可以使每个区域内部交换路由信息的通信量大大的减少。因而OSPF协议就可以使用于规模较大的自治系统了。

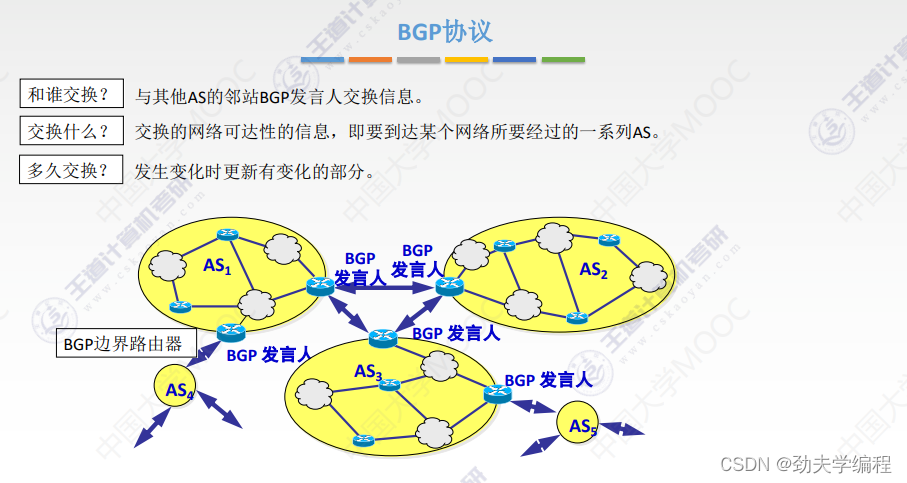
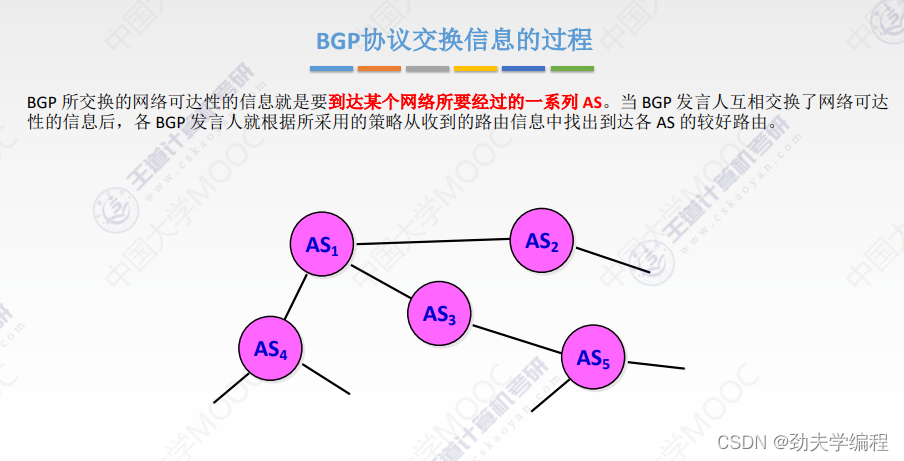
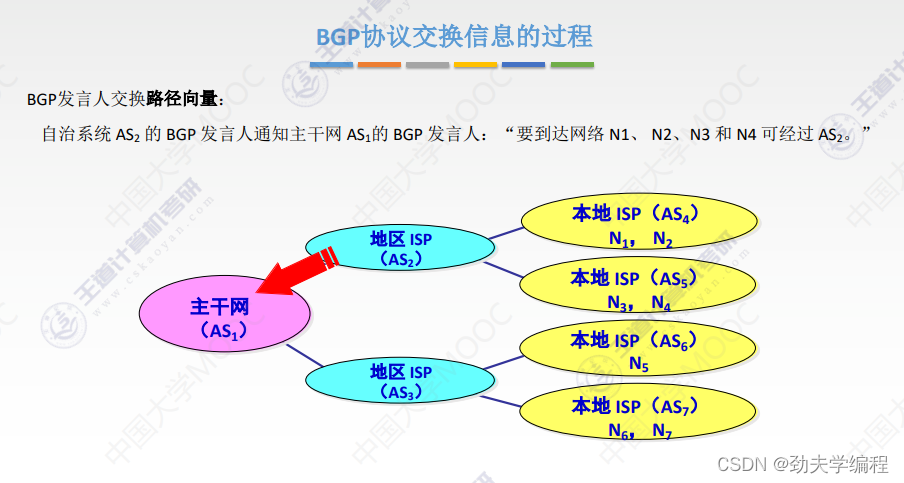
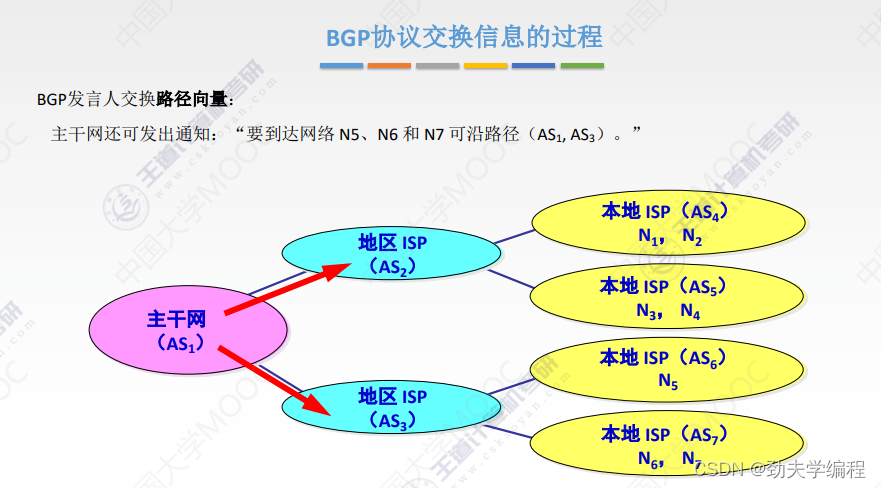
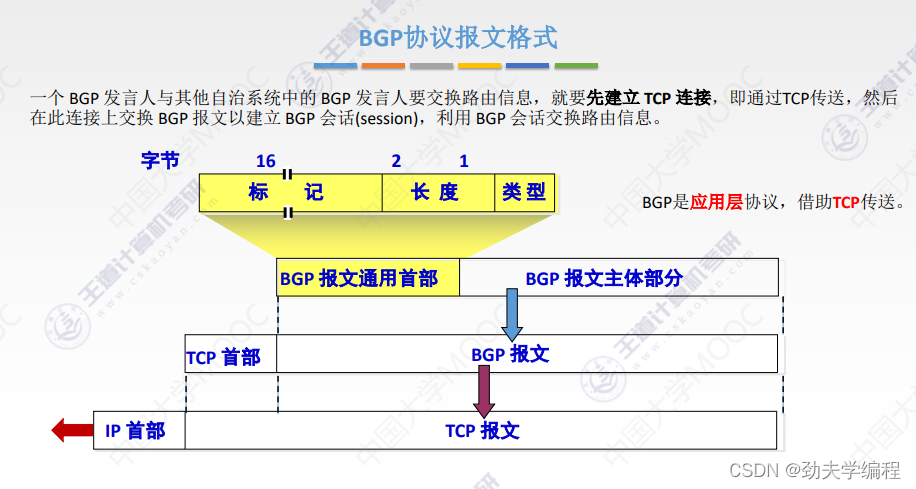
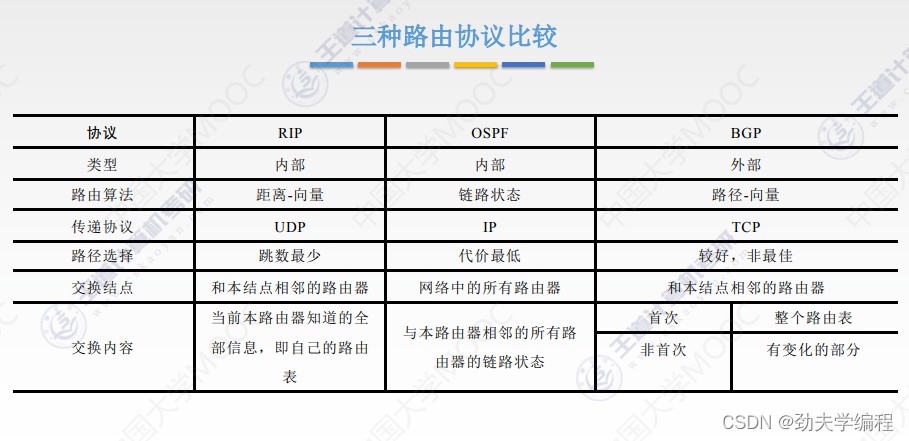
十六、BGP协议


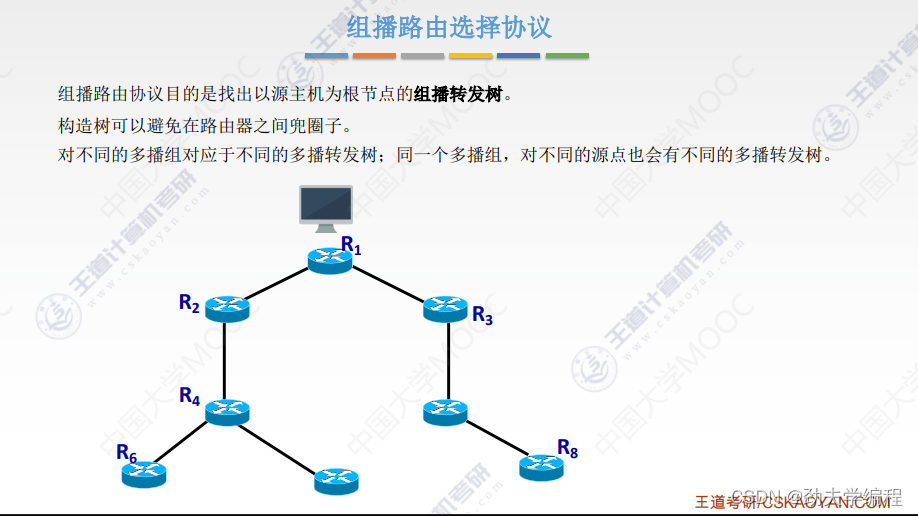
十七、IP组播
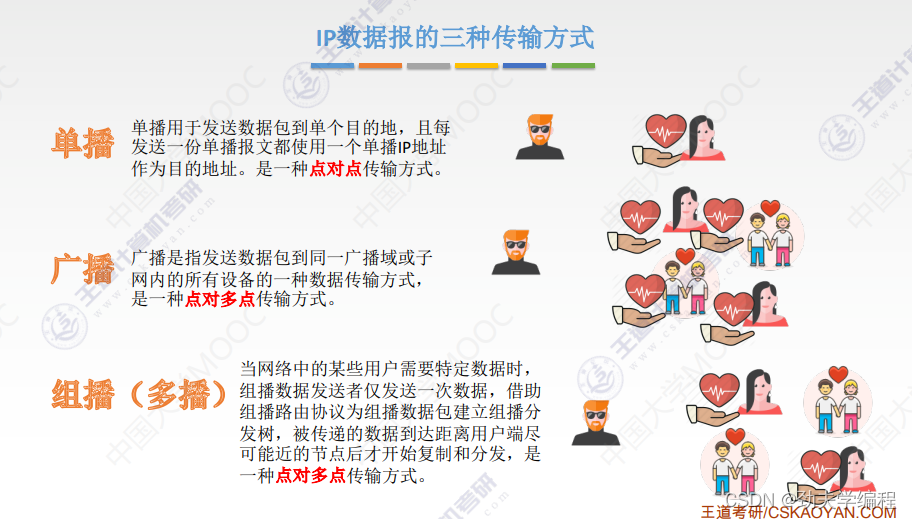
广播会给整个局域网的所有主机发送数据报,不管对方主机想不想要这个
就像一个男的不分青红皂白给所有女的表白,不管对方有没有男朋友。
组播也是发给很多的主机,但是相比广播不同的是,组播只会给有相同需求的主机发送一个数据报。而且它并不会在发送端就复制,它会直到要到下一个路由器才会把数据报进行一个复制,然后分发给这个网络中的组播组的主机。
组播就像一个男的向多个女生表白,但是他只找没有男朋友的女生。
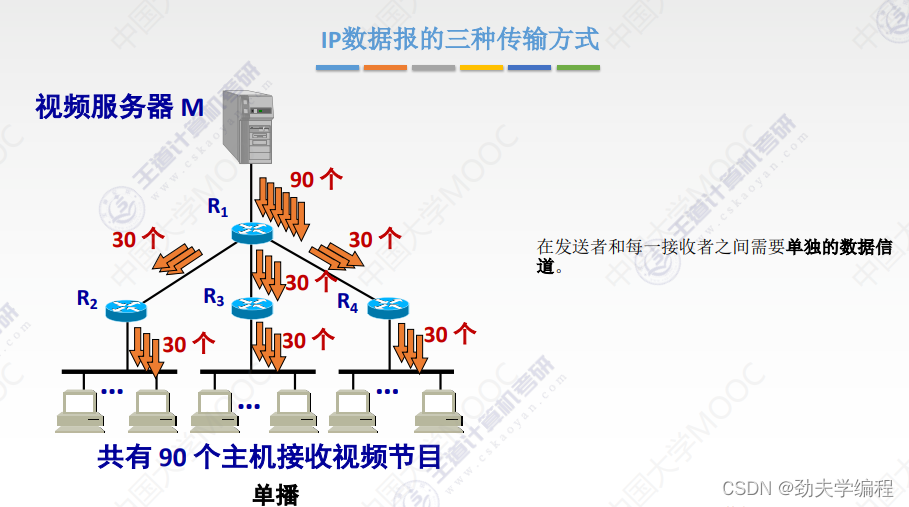
单播的方式,每一个待接收的主机都要和发送站点建立一个单播之间的连接。因此在原站点这里,它就需要根据有多少个人要接收我的数据,他就复制多少份。比如现在有90个主机要接收数据,它就需要复制90份IP数据报然后再分发到各个主机中。
可以看到,在实际传输时,占用的带宽和资源是很多的。就是因为在发送者和每一个接收者之间都需要单独的数据信道。
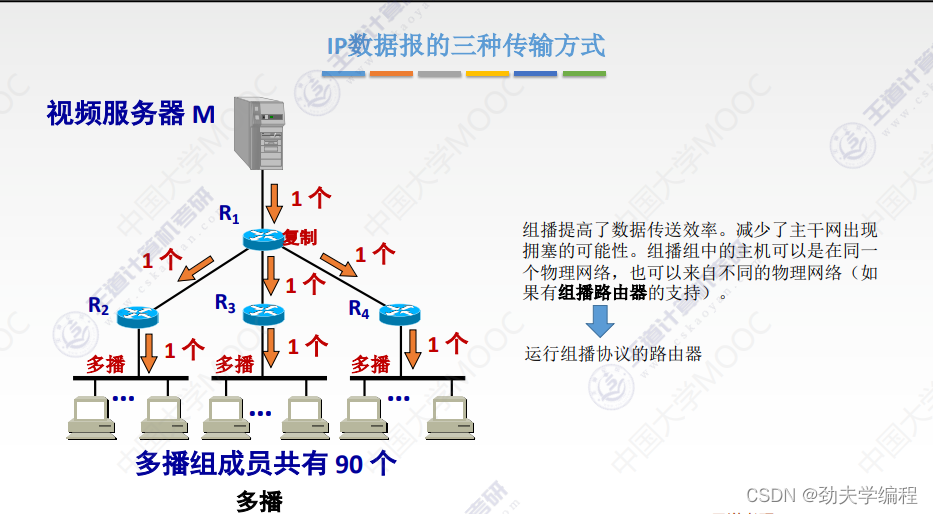
组播可以提高数据传输速率,减少主干网中出现拥塞的可能性。也就是这个源站点(发送方),它不需要事先复制很多份数据报,就一份数据报传输过去,到路由器的时候再复制几份(具体复制几份取决于路由器下面有几条链路)。复制之后每一个链路上还是只有一个数据报,这个局域网中的主机,只要还是属于这同一个组播组的,就可以收到这样一个组播的数据报。
组播组中的主机,可以是在同一个物理网络中,也可以在一个局域网内。当然也可以在不同的物理网络中,这个时候就需要有组播路由器的支持。组播路由器是指可以运行组播协议的路由器,这一类路由器既可以运行组播协议,也可以运行单播协议。
比如下图中红色圈的主机,它们也可以是同一个组播组,这样如果要发送数据给这个组播组的数据报就要走R2、R3、R4的路由器,再分发给这个组播组当中的成员主机。
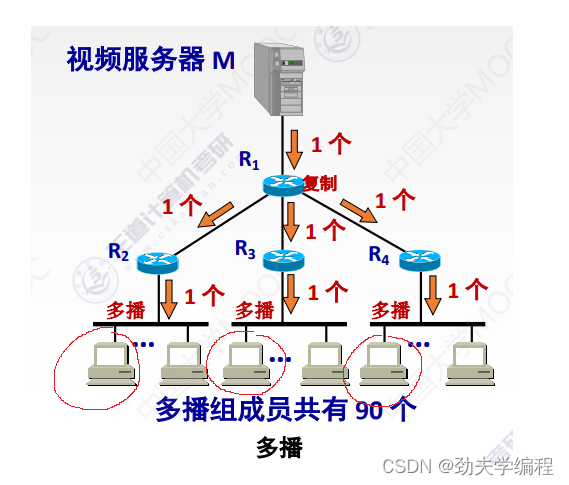
现在就有一个问题,在发送的时候怎么找到对应的主机呢?或者我们怎么知道某些主机是不是一个组播组的呢?这就涉及下面要讲的IP组播地址了。

我们知道因特网在进行通信的时候,每一个主机都需要有一个全球唯一的IP地址,如果某个主机现在想要接收某个特定的多播组的分组。怎么才能使这个多播数据报传送到这个主机中呢?
显然,这个组播数据报,它的目的地址一定不能写这个主机他自己的IP地址,因为如果这样写的话只能发给这个主机,其他的同属一个组播组中的主机是收不到这个数据报的,因此就需要有一个新的地址,比如这个主机中再产生一个新地址来接收这个组播的数据报。
当然,其他属于这个组播组中的主机就可以有这样一个IP组播地址,然后接收到发送给它们所在的组播组的数据报。
因此,IP组播地址就是让原设备能够将分组发送给一组设备。属于同一个多播组(组播组)当中的设备都会被分配一个组播组的IP地址,也就是很多主机他们都会有一个组播地址,如果他们是一个组播组的话,那他们的组播地址是一样的。
但是,这个组播地址并不是任何一个主机生来就有的,如果这个主机要实现接收组播数据报的功能,比如说我现在要看直播,或者我要加入一些视频会议,那我这个手机就有一个组播IP地址了。
组播地址只能作为分组的目标地址
举个例子,现在我们看直播,某个主播是被多人看的。相当于组播是源站,它把这个信息通过组播的方式发给这些主机,因为这些主机他是属于一个组播组的。但是反过来就不可以了,如果你一个人同时看多个直播,那画面一定是很混乱的。
IP组播的一个典型过程如下图所示,我们可以看到,图主要是分成了两个部分。
一个是因特网范围内的组播,另一个是硬件组播
这其实就是对IP组播的进行一个分类,一种是只能在本局域网内进行的硬件组播;另一种是因特网范围内,也就是还没有进入到局域网的这个范围的因特网范围内组播。
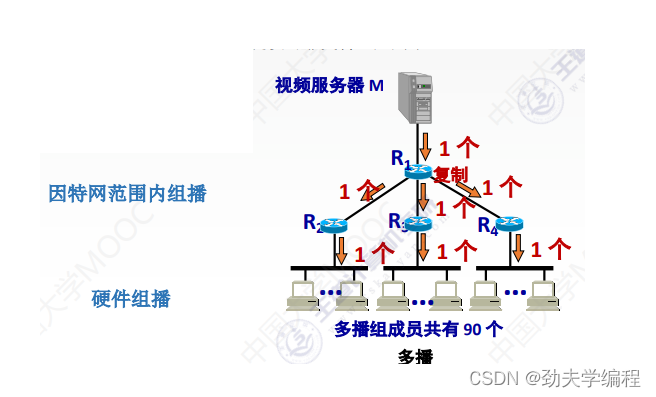
硬件组播是很简单也很重要的,因为现在大部分主机都是通过连在局域网,然后再连入因特网,下面就来看一下关于硬件组播的相关问题。
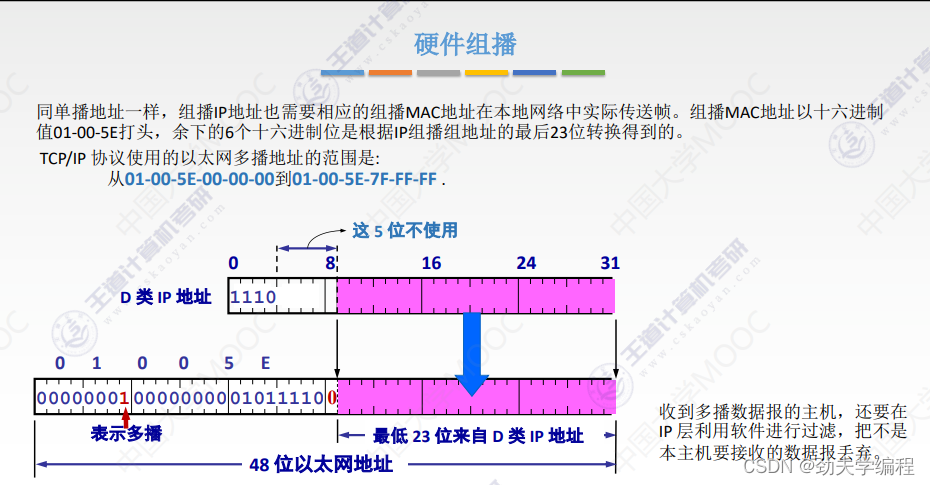
硬件组播其实就是在局域网范围内,对于一个组播的数据报,我们应该怎么样给这些主机,或者给哪些主机。
这里就可以结合我们前面学的单播。比如说现在发了一个单播数据报,它进入局域网后应该交付给哪个主机?那就要看这个主机的MAC地址了。
同样,在硬件组播这里,也是要根据MAC地址来找到可以接收组播数据报的主机。
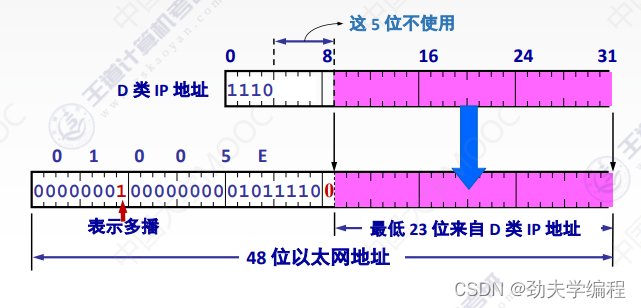
在组播这里也有一种MAC地址的标识,就是01-00-5E,只要这个MAC地址是这个打头的,它一定是一个组播MAC地址。那就要做好准备,要发给这个局域网中的一部分主机了,具体发给哪些主机,要看剩下部分。
把01-00-5E转换成16位,前面都是固定的这些,用它们表示多播。后面1位0是最高位也是固定好的(正数的意思)
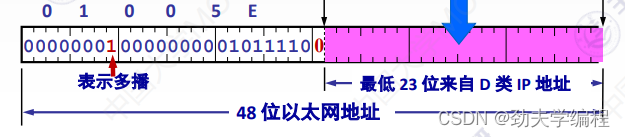
那么最低位就剩下了23位,这23位其实也就决定了这样一个局域网内它的多播地址范围。也就是全0到全1

而最低的23位需要和他的ip地址有一个映射关系。
ps:MAC地址要和ip地址有一个映射关系来决定是不是同属一个多播组
因为我们知道,一个D类IP地址标识的是一个组播组,因此,我们就把这个IP地址映射成MAC地址。那就变成了一个MAC地址可以映射一个组播组。需要注意的是,在这个D类IP地址中,有5位是不固定的(25=32种可能)
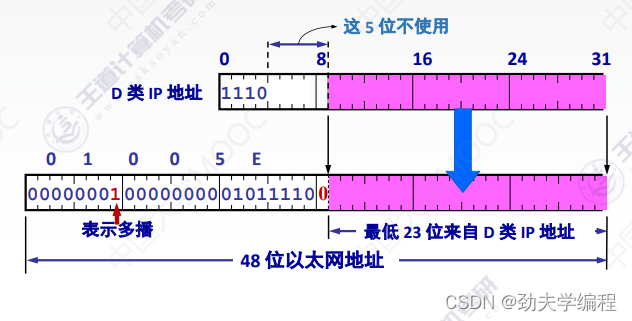
假如我们现在有两个D类IP地址,如下图所示:
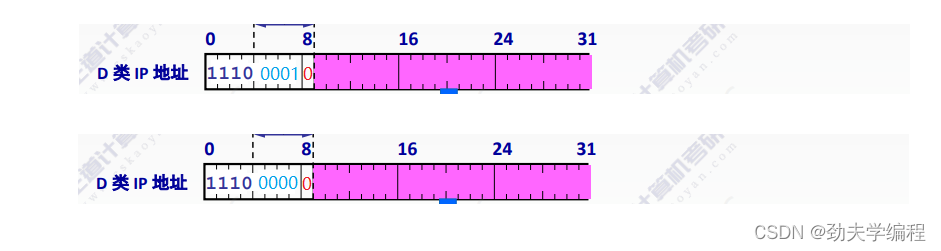
可以看到它们不固定的5位是不一样的,但是后面23位一样。
其实这两个主机应该是属于不同的组播组,因为他们的IP地址不一样,但是我们看映射到MAC地址这里,因为在组播中IP地址和MAC地址的映射只在最后的23位,前面都是固定好的,所以虽然这两个地址前面不一样,但是它们映射到mac地址上也是一样的。
那这两个不同的IP地址到最后居然是映射成了同一个mac地址,那到一个局域网内,明明是两个组播组的,现在居然并成一个组播组了。这就出现严重问题了,需要解决这个问题。
解决办法就是需要进行过滤,对于收到多播数据报的主机,还要在ip层利用软件进行过滤,把不是本主机要收到的数据报丢弃了。这就是为了解决那5位不一样,但剩下23位一样的问题。
关于硬件组播这里,可能会考察IP地址和MAC地址进行一个映射,比如说给你一个IP地址,让你来映射成他的组播的MAC地址。
那我们先要看清选项,前面一定是01-00-5E,然后把IP地址后23位写到MAC地址的后23位。然后转换成16进制,每4位一个数,那么就是最后的组播mac地址。
接下来来看另一个重点IGMP协议和组播路由选择协议
刚才我们讲了IP组播的两种类型,一个是在本局域网内进行硬件多播,另一个则是在因特网的范围内进行多播。这两个协议就是在因特网的范围内要使用的协议。
IGMP协议:

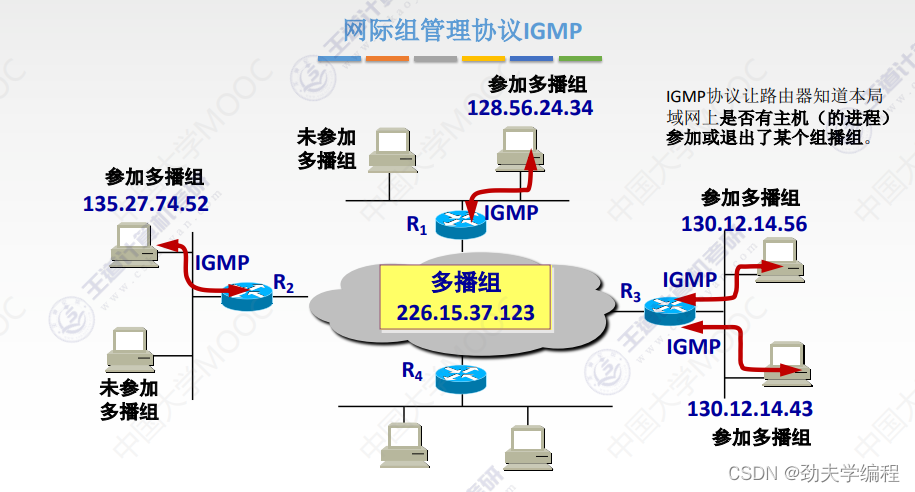
它是在一个路由器内部所使用的协议,它就是要让连在一个局域网上的组播路由器知道他所连的局域网上面是不是还有主机参加/退出了某个组播组。
简言之,一个组播路由器通过IGMP协议,就可以知道他所连的局域网中是不是还有可以接收组播数据报的主机了。


组播路由选择协议:
既然是路由选择,那很容易就知道他是在路由器之间进行一个路径选择的问题。
而且如果只有IGMP协议,是不足以完成组播的一整个流程的。连接在局域网上的组播路由器还必须要和其他的路由器,因特网上的其他路由器进行一个协同的合作,进行一个信息的交换,才能够把这个组播的数据报用最小的代价来传送给组播组当中的全部成员。

十八、移动IP




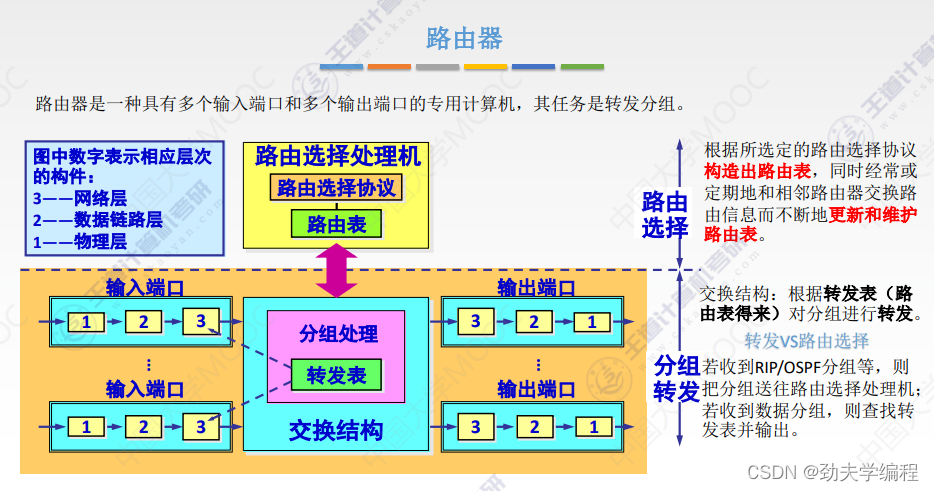
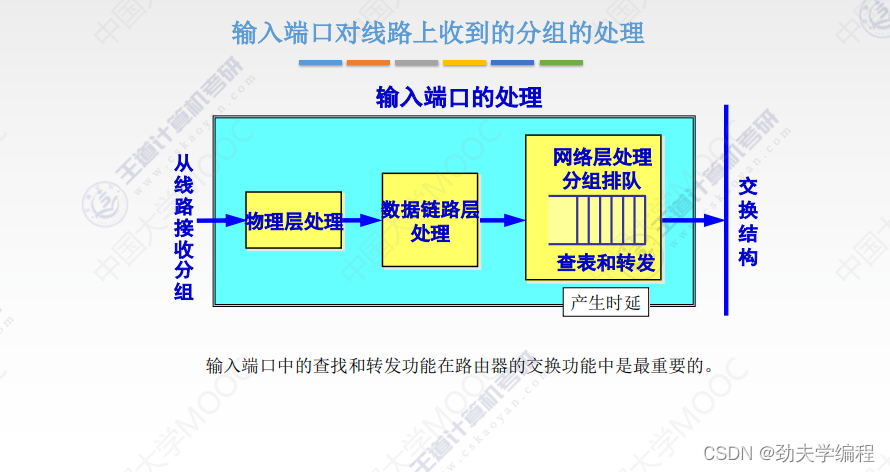
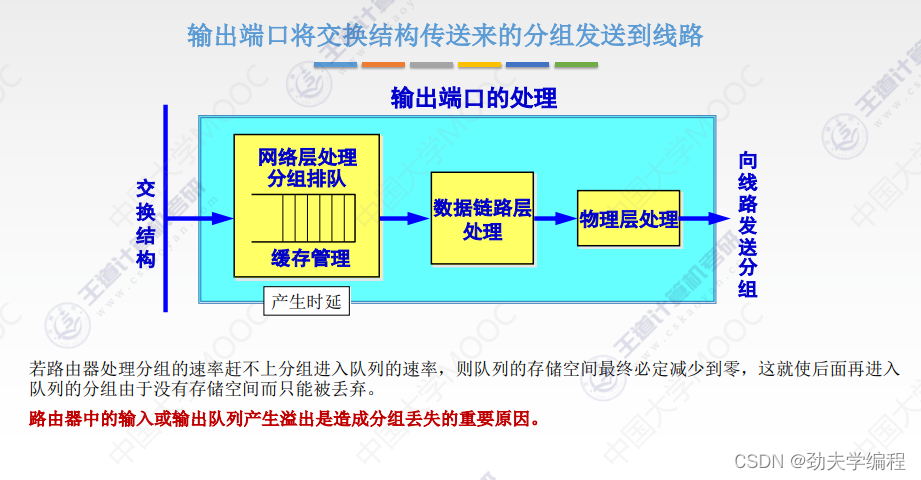
十九、网络层设备


![中间件 | Redis - [基本信息]](https://img-blog.csdnimg.cn/direct/2bdb86e2378943fa8036bbbc8ecd00fe.png)