可以参考我改的项目,不过目前推理结果不对,还在修复:
https://github.com/lindsayshuo/yolov8-cls-tensorrtx
先看代码
class DFL(nn.Module):
"""
Integral module of Distribution Focal Loss (DFL).
Proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
"""
def __init__(self, c1=16):
"""Initialize a convolutional layer with a given number of input channels."""
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
"""Applies a transformer layer on input tensor 'x' and returns a tensor."""
b, c, a = x.shape # batch, channels, anchors
print("self.conv.weight.data[:] is : ",self.conv.weight.data[:])
print("self.conv.weight.data[:] shape is : ",self.conv.weight.data[:].shape)
print("x is : ",x)
print("x.shape is : ",x.shape)
print("x.view(b,4,self.c1,a) is : ",x.view(b,4,self.c1,a))
print("x.view(b,4,self.c1,a).shape is : ",x.view(b,4,self.c1,a).shape)
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
这个类 DFL 是一个神经网络模块,继承自 nn.Module,是在PyTorch框架中定义自定义神经网络层的标准方式。这个 DFL 类实现了分布焦点损失(Distribution Focal Loss, DFL),这是在论文 “Generalized Focal Loss” 中提出的一个概念。下面是对这段代码的详细解释:
1、class DFL(nn.Module):定义了一个名为 DFL 的类,它继承自 nn.Module,使其成为一个PyTorch的网络层。
2、def init(self, c1=16):DFL 类的初始化方法。接收一个参数 c1,默认值是 16,代表输入通道的数量。
3、super().init():调用父类 nn.Module 的初始化函数,这是在定义PyTorch模型时的标准做法。
4、self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False):定义了一个卷积层,该层有 c1 个输入通道,1个输出通道,卷积核大小1x1,没有偏置项,且不需要梯度更新(即在训练过程中不会更新这个卷积层的权重)。
5、x = torch.arange(c1, dtype=torch.float):创建一个大小为 c1 的一维张量,这个张量包含了从0到 c1-1 的连续整数。
6、self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1)):初始化卷积层的权重。x 被转换成形状为 (1, c1, 1, 1) 的四维张量,并作为卷积层权重的值。
7、self.c1 = c1:存储输入通道数目的属性。
8、def forward(self, x):定义了模块的前向传播方法,其中 x 是输入张量。
9、b, c, a = x.shape:获取输入张量 x 的形状,假设其是三维的,其中 b 是批处理大小,c 是通道数量,a 是锚点数量(注:锚点通常用于目标检测任务中)。
10、这段代码中还包含了一些打印语句,用于输出卷积层的权重和输入张量的形状等调试信息。
11、return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a):这是前向传播的关键操作。输入张量 x 首先被重塑为 (b, 4, self.c1, a),这里假定 c 是 4*self.c1。然后 transpose(2, 1) 交换了通道和锚点的维度。softmax(1) 在第二个维度上(即原来的 self.c1 维度、现在的通道维度)应用softmax函数。最后,应用卷积操作并将结果重塑为 (b, 4, a)。
综上所述,DFL 类使用了卷积核对输入张量进行变换,旨在学习一种分布式的表示,其在目标检测等任务中可能用于学习预测概率分布。这种方法可能有利于模型更好地理解目标的不确定性。
以下是调试输出:
Ultralytics YOLOv8.1.8 🚀 Python-3.11.5 torch-2.0.0+cu118 CUDA:0 (NVIDIA GeForce RTX 3060 Laptop GPU, 6144MiB)
self.conv.weight.data[:] is : tensor([[[[ 0.]],
[[ 1.]],
[[ 2.]],
[[ 3.]],
[[ 4.]],
[[ 5.]],
[[ 6.]],
[[ 7.]],
[[ 8.]],
[[ 9.]],
[[10.]],
[[11.]],
[[12.]],
[[13.]],
[[14.]],
[[15.]]]], device='cuda:0')
self.conv.weight.data[:] shape is : torch.Size([1, 16, 1, 1])
x is : tensor([[[ 7.9609, 3.9328, 1.2542, ..., 7.9261, 3.7103, 6.1628],
[ 7.8865, 8.2141, 3.6136, ..., 7.7927, 7.2668, 5.9885],
[ 2.1200, 8.2323, 7.2977, ..., 3.5018, 7.1541, 3.2515],
...,
[-1.6378, -2.2544, -2.0439, ..., -1.8033, -1.7783, -1.4680],
[-1.9045, -2.5544, -2.3420, ..., -2.0054, -1.9784, -1.6110],
[-1.1409, -2.4363, -2.1418, ..., -1.7273, -1.7041, -1.6811]]], device='cuda:0')
x.shape is : torch.Size([1, 64, 21])
x.view(b,4,self.c1,a) is : tensor([[[[ 7.9609, 3.9328, 1.2542, ..., 7.9261, 3.7103, 6.1628],
[ 7.8865, 8.2141, 3.6136, ..., 7.7927, 7.2668, 5.9885],
[ 2.1200, 8.2323, 7.2977, ..., 3.5018, 7.1541, 3.2515],
...,
[-1.3957, -2.2859, -2.3732, ..., -1.6756, -1.7059, -1.4575],
[-1.6145, -2.3682, -2.4476, ..., -1.7892, -1.7984, -1.5309],
[-0.8706, -1.7938, -1.8388, ..., -1.6522, -1.6732, -1.5332]],
[[ 8.3572, 9.8892, 9.1272, ..., 4.1972, 4.2291, 6.8087],
[ 8.2836, 9.8511, 9.0978, ..., 7.4077, 7.2967, 6.6090],
[ 2.7911, 2.6250, 2.3740, ..., 7.2771, 7.1356, 3.5323],
...,
[-1.6353, -2.0540, -1.9561, ..., -0.9167, -1.0320, -1.4185],
[-1.8191, -2.3518, -2.2370, ..., -1.1207, -1.2171, -1.5694],
[-1.1255, -2.2479, -2.0955, ..., -0.5296, -0.6821, -1.8163]],
[[-0.2927, 0.9935, 4.8185, ..., 4.0401, 8.2405, 5.8280],
[ 1.8495, 4.0922, 8.9220, ..., 7.8240, 8.1252, 5.9634],
[ 3.7216, 8.0900, 8.7783, ..., 7.6322, 3.4239, 3.9682],
...,
[-1.7413, -2.0473, -2.3148, ..., -1.7863, -1.6267, -1.3612],
[-1.9912, -2.2312, -2.4779, ..., -1.9319, -1.7893, -1.5738],
[-1.3506, -1.7374, -1.8736, ..., -1.7203, -1.5202, -1.5913]],
[[ 0.9126, 0.7135, 0.5577, ..., 8.0598, 8.0426, 6.3850],
[ 2.6471, 2.7828, 2.6682, ..., 7.9502, 7.9280, 6.1044],
[ 3.7130, 4.0446, 3.8203, ..., 3.9169, 4.0009, 3.2179],
...,
[-1.6378, -2.2544, -2.0439, ..., -1.8033, -1.7783, -1.4680],
[-1.9045, -2.5544, -2.3420, ..., -2.0054, -1.9784, -1.6110],
[-1.1409, -2.4363, -2.1418, ..., -1.7273, -1.7041, -1.6811]]]], device='cuda:0')
x.view(b,4,self.c1,a).shape is : torch.Size([1, 4, 16, 21])
在PyTorch框架中,x.view() 函数是非常常用来改变张量(Tensor)形状的方法。当使用x.view()时,你需要提供一个维度的新形状,而这个新形状必须要与原始张量包含的元素数量相匹配。换句话说,使用view可以在不改变数据内容的前提下,改变数据的形状。
这是 x.view() 方法的基本用法:
x.view(dim1, dim2, dim3, ...)
其中,dim1, dim2, dim3, … 是新的形状,每一个维度都是一个整数,代表了在该维度上的大小。可以使用 -1 来让PyTorch自动计算该维度的大小,但一次只能用在一个维度上。
请看以下代码中的 forward 方法里的 x.view() 的使用:
b, c, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
在这个例子中,x 是输入张量,其形状为 (b, c, a),其中 b 是批次大小(batch size),c 是通道数(channels),a 是锚点数量(anchors)。这里的 c 应该等于 4*self.c1,这样才能通过 view 进行重塑。
x.view(b, 4, self.c1, a) 的意思是将 x 的形状由 (b, c, a) 改变为 (b, 4, self.c1, a)。此时,第二维度变成了 4,第三维度变成了 self.c1,而第四维度是 a。调用 view 后,张量的总元素数不变,但将这些元素按照新的形状重新排列。
在这个转换之后,x 经过了 .transpose(2, 1),它会交换第二维和第三维。transpose(2, 1) 的结果是张量的形状变成了 (b, self.c1, 4, a)。
最后,.softmax(1) 在第二维上应用了softmax函数,它会计算该维度上的概率分布。然后经过自定义的1x1卷积核处理,并返回形状为 (b, 4, a) 的结果。
通过这种方式,x.view() 使得张量可以在不同神经网络操作中适应所需的形状,在保持数据元素不变的同时改变其结构。
tensorrt里面的dfl如下:
nvinfer1::IShuffleLayer* DFL(nvinfer1::INetworkDefinition* network, std::map<std::string, nvinfer1::Weights> weightMap,
nvinfer1::ITensor& input, int ch, int grid, int k, int s, int p, std::string lname){
nvinfer1::IShuffleLayer* shuffle1 = network->addShuffle(input);
shuffle1->setReshapeDimensions(nvinfer1::Dims3{4, 16, grid});
shuffle1->setSecondTranspose(nvinfer1::Permutation{1, 0, 2});
nvinfer1::ISoftMaxLayer* softmax = network->addSoftMax(*shuffle1->getOutput(0));
nvinfer1::Weights bias_empty{nvinfer1::DataType::kFLOAT, nullptr, 0};
nvinfer1::IConvolutionLayer* conv = network->addConvolutionNd(*softmax->getOutput(0), 1, nvinfer1::DimsHW{1, 1}, weightMap[lname], bias_empty);
conv->setStrideNd(nvinfer1::DimsHW{s, s});
conv->setPaddingNd(nvinfer1::DimsHW{p, p});
nvinfer1::IShuffleLayer* shuffle2 = network->addShuffle(*conv->getOutput(0));
shuffle2->setReshapeDimensions(nvinfer1::Dims2{4, grid});
return shuffle2;
}
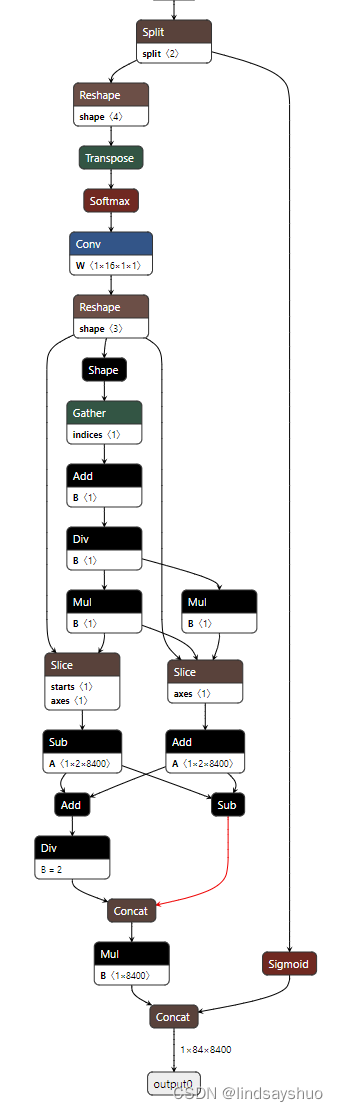
下面放出DFL的onnx图:

tensorrtx里面处理的detect的代码为:
nvinfer1::IShuffleLayer* shuffle22_0 = network->addShuffle(*cat22_0->getOutput(0));
shuffle22_0->setReshapeDimensions(nvinfer1::Dims2{64 + kNumClass, (kInputH / 8) * (kInputW / 8)});
nvinfer1::ISliceLayer* split22_0_0 = network->addSlice(*shuffle22_0->getOutput(0), nvinfer1::Dims2{0, 0}, nvinfer1::Dims2{64, (kInputH / 8) * (kInputW / 8)}, nvinfer1::Dims2{1, 1});
nvinfer1::ISliceLayer* split22_0_1 = network->addSlice(*shuffle22_0->getOutput(0), nvinfer1::Dims2{64, 0}, nvinfer1::Dims2{kNumClass, (kInputH / 8) * (kInputW / 8)}, nvinfer1::Dims2{1, 1});
nvinfer1::IShuffleLayer* dfl22_0 = DFL(network, weightMap, *split22_0_0->getOutput(0), 4, (kInputH / 8) * (kInputW / 8), 1, 1, 0, "model.22.dfl.conv.weight");
nvinfer1::ITensor* inputTensor22_dfl_0[] = {dfl22_0->getOutput(0), split22_0_1->getOutput(0)};
nvinfer1::IConcatenationLayer* cat22_dfl_0 = network->addConcatenation(inputTensor22_dfl_0, 2);
nvinfer1::IShuffleLayer* shuffle22_1 = network->addShuffle(*cat22_1->getOutput(0));
shuffle22_1->setReshapeDimensions(nvinfer1::Dims2{64 + kNumClass, (kInputH / 16) * (kInputW / 16)});
nvinfer1::ISliceLayer* split22_1_0 = network->addSlice(*shuffle22_1->getOutput(0), nvinfer1::Dims2{0, 0}, nvinfer1::Dims2{64, (kInputH / 16) * (kInputW / 16)}, nvinfer1::Dims2{1, 1});
nvinfer1::ISliceLayer* split22_1_1 = network->addSlice(*shuffle22_1->getOutput(0), nvinfer1::Dims2{64, 0}, nvinfer1::Dims2{kNumClass, (kInputH / 16) * (kInputW / 16)}, nvinfer1::Dims2{1, 1});
nvinfer1::IShuffleLayer* dfl22_1 = DFL(network, weightMap, *split22_1_0->getOutput(0), 4, (kInputH / 16) * (kInputW / 16), 1, 1, 0, "model.22.dfl.conv.weight");
nvinfer1::ITensor* inputTensor22_dfl_1[] = {dfl22_1->getOutput(0), split22_1_1->getOutput(0)};
nvinfer1::IConcatenationLayer* cat22_dfl_1 = network->addConcatenation(inputTensor22_dfl_1, 2);
nvinfer1::IShuffleLayer* shuffle22_2 = network->addShuffle(*cat22_2->getOutput(0));
shuffle22_2->setReshapeDimensions(nvinfer1::Dims2{64 + kNumClass, (kInputH / 32) * (kInputW / 32)});
nvinfer1::ISliceLayer* split22_2_0 = network->addSlice(*shuffle22_2->getOutput(0), nvinfer1::Dims2{0, 0}, nvinfer1::Dims2{64, (kInputH / 32) * (kInputW / 32)}, nvinfer1::Dims2{1, 1});
nvinfer1::ISliceLayer* split22_2_1 = network->addSlice(*shuffle22_2->getOutput(0), nvinfer1::Dims2{64, 0}, nvinfer1::Dims2{kNumClass, (kInputH / 32) * (kInputW / 32)}, nvinfer1::Dims2{1, 1});
nvinfer1::IShuffleLayer* dfl22_2 = DFL(network, weightMap, *split22_2_0->getOutput(0), 4, (kInputH / 32) * (kInputW / 32), 1, 1, 0, "model.22.dfl.conv.weight");
nvinfer1::ITensor* inputTensor22_dfl_2[] = {dfl22_2->getOutput(0), split22_2_1->getOutput(0)};
nvinfer1::IConcatenationLayer* cat22_dfl_2 = network->addConcatenation(inputTensor22_dfl_2, 2);
nvinfer1::IPluginV2Layer* yolo = addYoLoLayer(network, std::vector<nvinfer1::IConcatenationLayer *>{cat22_dfl_0, cat22_dfl_1, cat22_dfl_2});
yolo->getOutput(0)->setName(kOutputTensorName);
network->markOutput(*yolo->getOutput(0));
tensorrtx里面的处理手段是将三个output分别经过dfl等一系列处理,再拼回去,再看onnx图: