INDEX
- §1 常规用法
- §2 QPS
- §3 pipeline
§1 常规用法
分布式锁
最常见用法,需要注意分布式锁的redis需要单点
分布式事务
分布式事务中,核心的技术难点其实是分布式事务这个事本身作为数据的持久化
- 2PC,比如 seata 的 AT 模式下,将 undo 数据作为分布式事务数据进行了持久化
- TCC 模式中,将事务锁作为分布式事务数据进行了持久化
- 可靠性消息中,事务消息(transztionalMessage)即分布式事务消息的持久化
- 独立消息服务中,要发一个什么样的消息这个信息作为分布式事务数据进行持久化
而 redis,本身也可以作为分布式事务数据的持久化容器,这是因为大部分分布式事务的处理过程中,最终分布式事务数据是要被物理删除的
分布式 ID
比如雪花算法的实现
简易消息队列
并发量较低、业务模型比较简单的分布式系统中可用
其他
计数器、排行榜、统计、开关标记集
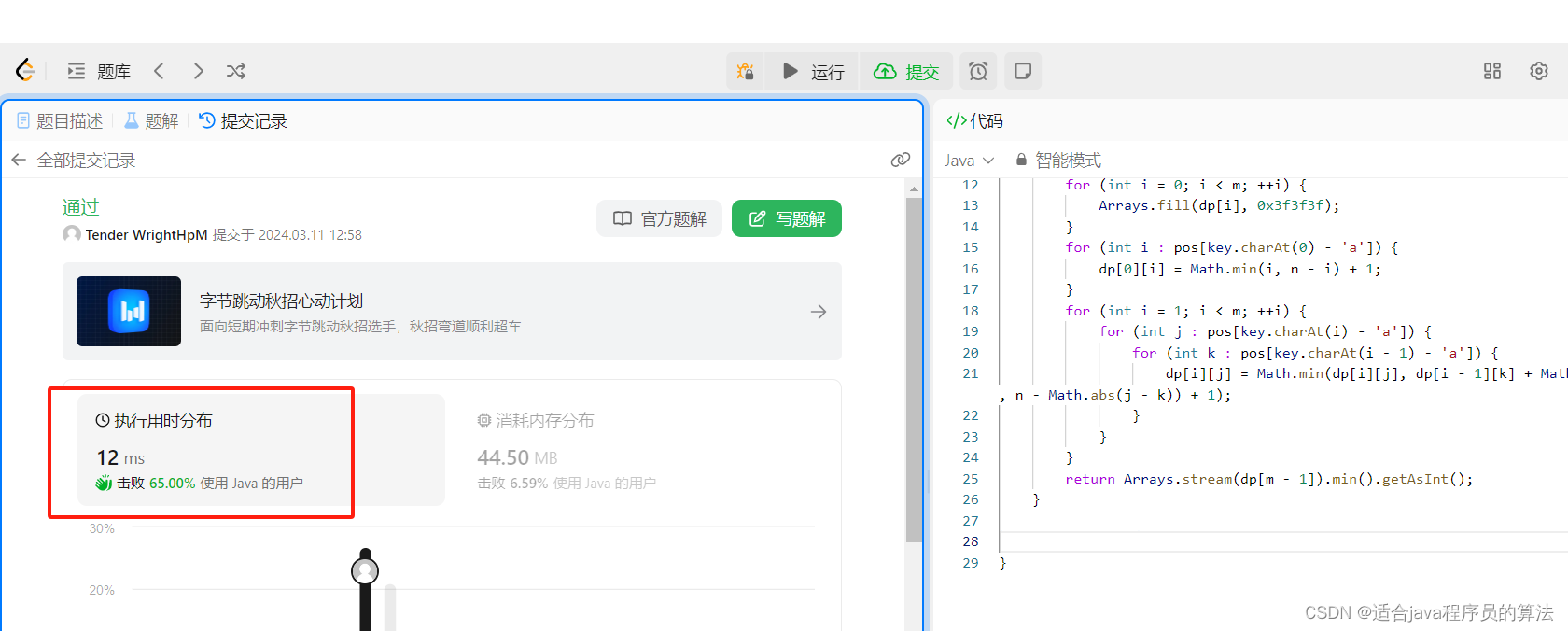
§2 QPS
10W+
§3 pipeline
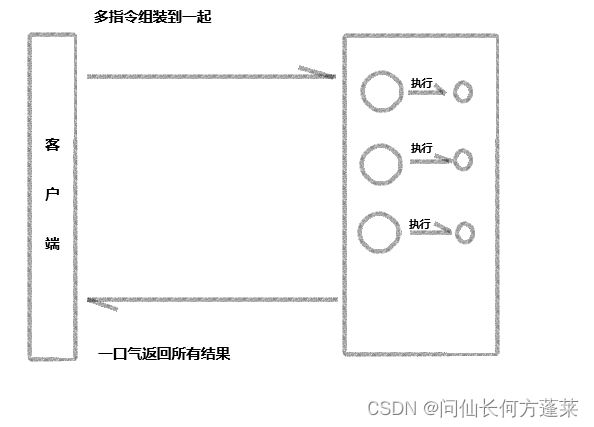
pipeline 简单的说就是指令打包
一个 redis 的指令(其实不限于 redis)可以分为 4 个阶段
- 发出
- 排队
- 执行
- 返回
其中,1/4阶段都设计网络传输(即 RTT ,往返时间)。有可能,往返时间远高于指令的排队+执行时间,于是造成了相对显著的性能浪费
pipeline 可以批量发送指令给 redis-server
应用 & 最佳实践
通常使用 redis api 中提供的 pipeline
Jedis jedis;
Pipeline p = jedis.pipelined();
p.set(key1,value1);
p.set(key2,value2);
p.set(key3,value3);
pipelined.sync();
通常,使用 pipeline 时,建议每次 pipeline 中报文总大小不超过 1460 字节,否则可能导致 http 拆包,也会造成性能损耗
集群 vs pipeline
pipeline 需要打包一批指令一口气提交到 redis-server 处理
在集群背景下,这一批指令很可能不在同一个集群节点上,redis 官方 API 如 jedis 等没有对这中操作进行支持(其实无论如何,都已经不能按 pipeline 初衷去使用了)
假设支持(比如头铁自研),需要注意死锁问题
假设 redis 有 ABC,pipeline 中指令的 key 分别对应 3 台机器
则只有 pipeline 同时持有 3个节点的连接时,才能正确提交
但可能获取到 AB 连接后,C 节点连接被全部占用,于是等待 C
而这两个等待的 AB 连接又禁止了其他指令使用,最终导致死锁
综上:集群中,不要用