DDP的分布式训练方法采用数据并行方式,相当于通过增大数据的batch来加快训练。但对于大模型(LLM)来说,DDP已经不适用了。因为LLMs的模型本身太大,一块GPU都放不下怎么可能去复制从而实现数据并行呢。所以LLM的训练采用模型并行的方式来训练。
FairScale 是一个用于高性能和大规模训练的 PyTorch 扩展库。该库扩展了基本的 PyTorch 功能,同时添加了新的 SOTA 扩展技术。FairScale 以可组合模块和易于使用的 API 的形式提供最新的分布式训练技术。这些 API 是研究人员工具箱的基本组成部分,因为他们试图用有限的资源扩展模型。(来源官网)
本次熟悉一下其常用的设置。
目录
一、预先准备
二、使用 PIPELINE PARALLEL 进行模型分片
1、官网的教程
2、实际应用举例
3、模型分片后,数据前向传播流程分析
总结
一、预先准备
随便准备一个模型作为例子。以下面模型为例(可以运行),简单的分类任务。
import torch
import torch.nn as nn
import random
import torchvision.datasets as data
import torchvision.transforms as transforms
import torch.optim as optim
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32, kernel_size=4,stride=2, padding=1),
nn.ReLU(),
nn.MaxPool2d((2,2),1),
nn.Conv2d(in_channels=32,out_channels=64, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.MaxPool2d((2,2),1),
nn.Conv2d(64, 128, 2, 2,1),
nn.ReLU(),
nn.MaxPool2d((2,2),1)
)
#
self.classifier = nn.Sequential(
nn.Linear(3*3*128,4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096,2048),
nn.ReLU(),
nn.Linear(2048,1024),
nn.ReLU()
)
self.last_layer_input = nn.Sequential(nn.Linear(1024,10),
nn.Softmax())
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
x = self.last_layer_input(x)
return x
if __name__ == '__main__':
batchSize = 50
nepoch = 45
print("Random Seed: 88")
random.seed(88)
torch.manual_seed(88)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
dataset = data.CIFAR10(root='/root/data/zjx/Datasets/cifar10', # 这个路径自己改
train=True,
transform=transforms.Compose([transforms.ToTensor()]),
download=True
)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batchSize,
shuffle=True)
Model = Classifier().to(device)
Cross_entropy = nn.BCELoss().to(device)
Optimizer = optim.Adam(Model.parameters(), lr=0.00001)
for epoch in range(nepoch):
for i, (data, label) in enumerate(dataloader, 0):
data = data.to(device)
label_onehot = torch.zeros((data.shape[0], 10)).to(device)
label_onehot[torch.arange(data.shape[0]), label] = 1
output = Model(data)
loss = Cross_entropy(output, label_onehot)
print('{}/{}: Loss is {}'.format(i, epoch, loss.data))
Model.zero_grad()
loss.backward()
Optimizer.step()二、使用 PIPELINE PARALLEL 进行模型分片
1、官网的教程
官网的示例看这里,主要关键点包括切片的语法设置,以及设备对齐。
模型切片的要求格式
import fairscale
import torch
import torch.nn as nn
model = nn.Sequential(
torch.nn.Linear(10, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 5)
)
model = fairscale.nn.Pipe(model, balance=[2, 1])可以看到要求必须 torch.nn.Sequential 格式。上述前两层放到cuda:0, 后一层放到cuda:1上。但是这里有个问题。如果我们自定义的模型不全是nn.Sequential的格式,那么它还能这样实现吗?
以 一中预准备的模型为例,它并不全是nn.Sequential的格式,而是分成了三个部分,前向传播过程中有一步拉直操作。(当然,一中例子也可以转换成全是nn.Sequntial的格式,拉直可以用nn.Flatten()来实现)这样的话使用这个设置还可以吗?来试一下
Model = Classifier().to(device)
# 在上面语句的下面添加
Model = fairscale.nn.Pipe(Model, balance=[6, 6, 6])
# 运行报错
TypeError: module must be nn.Sequential to be partitioned显然,这样不行。报出错误:必须是nn.Sequential类型的。这样行不通,必须另想办法。
2、实际应用举例
当整个模型不是连续的nn.Sequential类型时,而是分成几部分单独定义时,我们可以把每部分分别分片放到不同的GPU上。这个过程可以在模型定义的时候在其内部实现。
以一中模型为例,将 模型中的 self.features 分片,放到三块GPU上。
self.features = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32, kernel_size=4,stride=2, padding=1),
nn.ReLU(),
nn.MaxPool2d((2,2),1),
nn.Conv2d(in_channels=32,out_channels=64, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.MaxPool2d((2,2),1),
nn.Conv2d(64, 128, 2, 2,1),
nn.ReLU(),
nn.MaxPool2d((2,2),1)
)
# 在上面语句的下面添加
self.features = fairscale.nn.Pipe(self.features, balance=[3, 3, 3])注意 ,我这里是根据我实际情况划分的,我采用的是三块GPU,一共9层,三等分了,你们按实际自行改动。下面的实例也是都用的三块GPU的基础上进行的
这样简单的设置,来执行一下看看行不行得通。
# 运行报错
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0! (when checking argument for argument weight in method wrapper__cudnn_convolution)
报错了。因为官网中还有另一个关键的设备对其没有设置。所以,必须在整个过程中进行一下设备对齐,才能顺利运行。
首先,在定义模型时先不把模型放到 cuda上, 而是在模型内部去实现这一步。
# 将
Model = Classifier().to(device)
# 改为
Model = Classifier()然后
self.features = fairscale.nn.Pipe(self.features, balance=[3, 3, 3])
# 在上面语句的下面添加
self.device = self.features.devices[0]
self.classifier = nn.Sequential(
nn.Linear(3*3*128,4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096,2048),
nn.ReLU(),
nn.Linear(2048,1024),
nn.ReLU()
)
# 在上面的语句下面添加
self.classifier.to(self.device)self.last_layer_input = nn.Sequential(nn.Linear(1024, 10),
nn.Softmax())
# 在上面的语句下面添加
self.last_layer_input.to(self.device)x = torch.flatten(x, 1)
# 在上面语句的下面添加
x = x.to(self.device)这样就可以运行了。我们来看一下不同GPU显存占用的变化
模型未分片,只用一个GPU时
(base) root@3eaab89e2baa:~/data# nvidia-smi
Sat Mar 9 04:15:26 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:04:00.0 Off | N/A |
| 22% 33C P2 71W / 250W | 1522MiB / 11264MiB | 31% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce ... On | 00000000:05:00.0 Off | N/A |
| 22% 27C P8 3W / 250W | 3MiB / 11264MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA GeForce ... On | 00000000:09:00.0 Off | N/A |
| 22% 32C P8 2W / 250W | 3MiB / 11264MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 28350 C 1519MiB |
+-----------------------------------------------------------------------------+模型分片时的情况
(base) root@3eaab89e2baa:~/data# nvidia-smi
Sat Mar 9 04:17:00 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:04:00.0 Off | N/A |
| 22% 34C P2 66W / 250W | 1546MiB / 11264MiB | 22% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce ... On | 00000000:05:00.0 Off | N/A |
| 22% 30C P2 52W / 250W | 1210MiB / 11264MiB | 3% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA GeForce ... On | 00000000:09:00.0 Off | N/A |
| 22% 35C P2 47W / 250W | 1190MiB / 11264MiB | 2% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 29306 C 1543MiB |
| 1 N/A N/A 29306 C 1207MiB |
| 2 N/A N/A 29306 C 1187MiB |
+-----------------------------------------------------------------------------+可以看到其中的区别。未分片时只有一个GPU内存被占用,分片时三个GPU显存被占用。至于占用的大小并不是1+1=2的关系,因为其中不仅仅只是模型的参数被划分,在训练过程中还有其它参数的内存占用,比如中间过程生成的特征参数,计算保留的梯度参数等等。这里自行体会。
3、模型分片后,数据前向传播流程分析
debug,发现

模型被分片后,其被分到了三个设备上,具体的体现就是图中的devices包含三个cuda:1,2,3。
在对其设备时,数据被放到了 cuda:0 上。所以,在送入 self.features 这个被分片的模型之前,数据的状态如下

当数据在分片的模型 self.features 前向流程走完后,发现

其在 cuda:2 设备上进行了输出。!!所以整个流程如下图所示
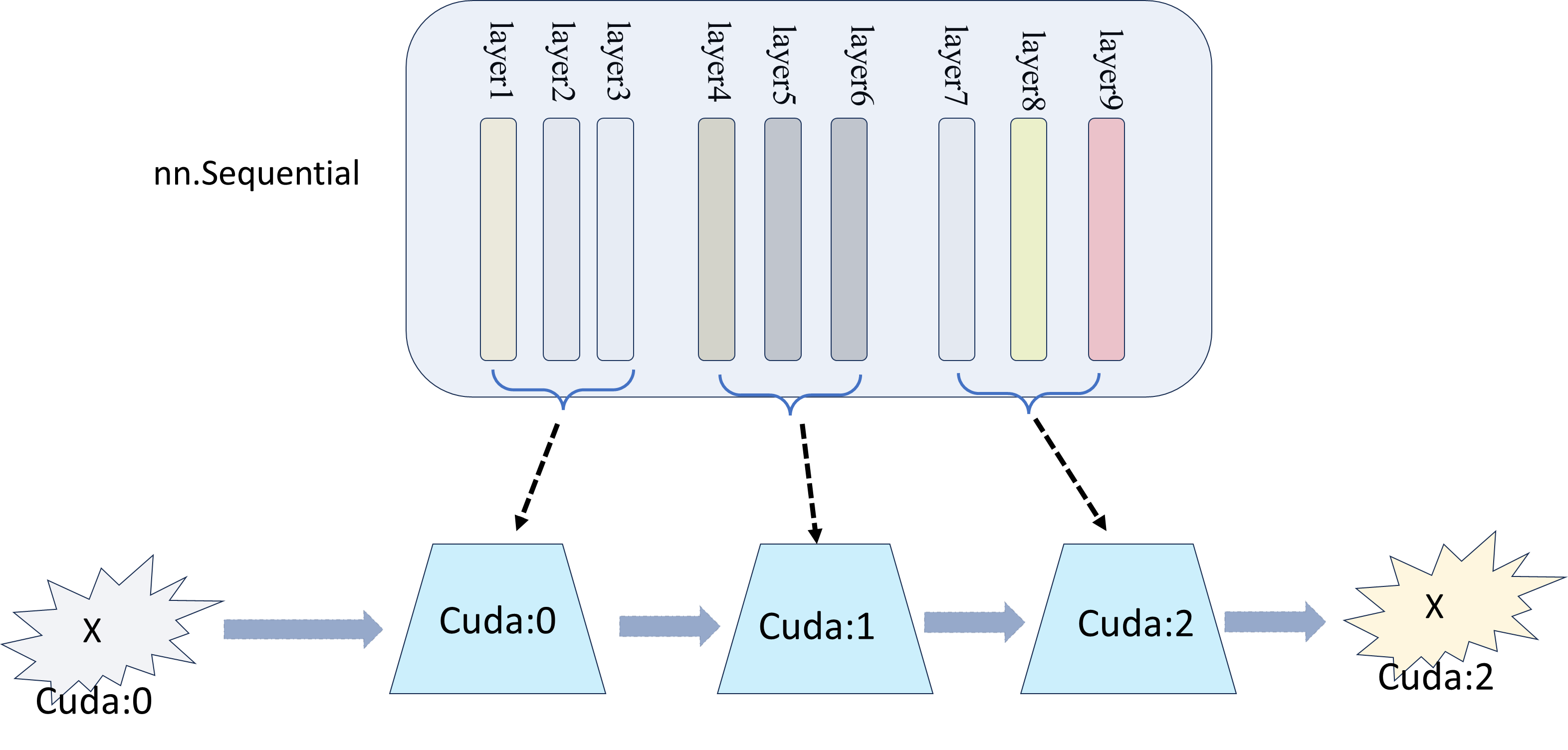
因此,模型分片的时候必须要对齐设备,所以,2中的例子才会有那老些的对齐设备步骤。
至此,整个过程以及需要注意的事项已经有了大概的了解,有了一定的视野。接下来,我们将会把一中的例子中的 self.classifier在之前的基础上也进行模型分片。有了上面的视图,这实现起来经不会太难。
具体地,在之前地基础上进行修改
self.classifier = nn.Sequential(
nn.Linear(3*3*128,4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096,2048),
nn.ReLU(),
nn.Linear(2048,1024),
nn.ReLU()
)
# 在上面的语句下面添加
self.classifier = fairscale.nn.Pipe(self.classifier, balance=[2, 3, 2])# 注释掉下面语句
# self.classifier.to(self.device)注释掉是为了对齐进行模型分片后 ,模型会放到不同的设备上,如果再放到cuda:0上造成矛盾,从而出错。记住,模型分片后的设备cuda是个list,被放到了好几个cuda上。
x = self.classifier(x)
# 在上面的语句下面添加
x = x.to(self.device)对齐设备,从之前的图中看到,x回在cuda:2上输出,所以必须把它放到cuda:0上才能进行下一步
查看GPU显存占用情况
(base) root@3eaab89e2baa:~/data# nvidia-smi
Sat Mar 9 04:49:19 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:04:00.0 Off | N/A |
| 22% 34C P2 57W / 250W | 1326MiB / 11264MiB | 11% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce ... On | 00000000:05:00.0 Off | N/A |
| 22% 31C P2 58W / 250W | 1420MiB / 11264MiB | 13% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA GeForce ... On | 00000000:09:00.0 Off | N/A |
| 22% 36C P2 49W / 250W | 1250MiB / 11264MiB | 5% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 13027 C 1323MiB |
| 1 N/A N/A 13027 C 1417MiB |
| 2 N/A N/A 13027 C 1247MiB |
+-----------------------------------------------------------------------------+明显比之前的大了。
总结
到这里,通过一步步的简单的实践对模型的分片有了一定的了解。知道了怎么去实现模型分片。接下来会继续探索其中的奥秘, 望诸君共勉!嘿嘿嘿