在云服务中,缓存是极其重要的一点。所谓缓存,其实是一个高速数据存储层。当缓存存在后,日后再次请求该数据就会直接访问缓存,提升数据访问的速度。但是缓存存储的数据通常是短暂性的,这就需要经常对缓存进行更新。而我们操作缓存和数据库,分为读操作和写操作。
读操作的详细流程为,请求数据,如缓存中存在数据则直接读取并返回,如不存在则从数据库中读取,成功之后将数据放到缓存中。
写操作则又分为以下 4 种:
-
先更新缓存,再更新数据库
-
先更新数据库,再更新缓存
-
先删除缓存,再更新数据库
-
先更新数据库,再删除缓存
一些一致性要求不高的数据,如点赞数等,可以先更新缓存,然后再定时同步到数据库。而在其它情况下,我们通常会等数据库操作成功,再操作缓存。
下面主要介绍更新数据库成功后,更新缓存和删除缓存这两个操作的区别和改进方案。
先更新数据库,再删除缓存
先更新数据库,再删除缓存,这种模式也叫 cache aside,是目前比较流行的处理缓存数据库一致性的方法。
它的优点是:
-
出现数据不一致的概率极低,实现简单
-
由于不更新缓存,而是删除缓存,在并发写写情况下,不会出现数据不一致的情况
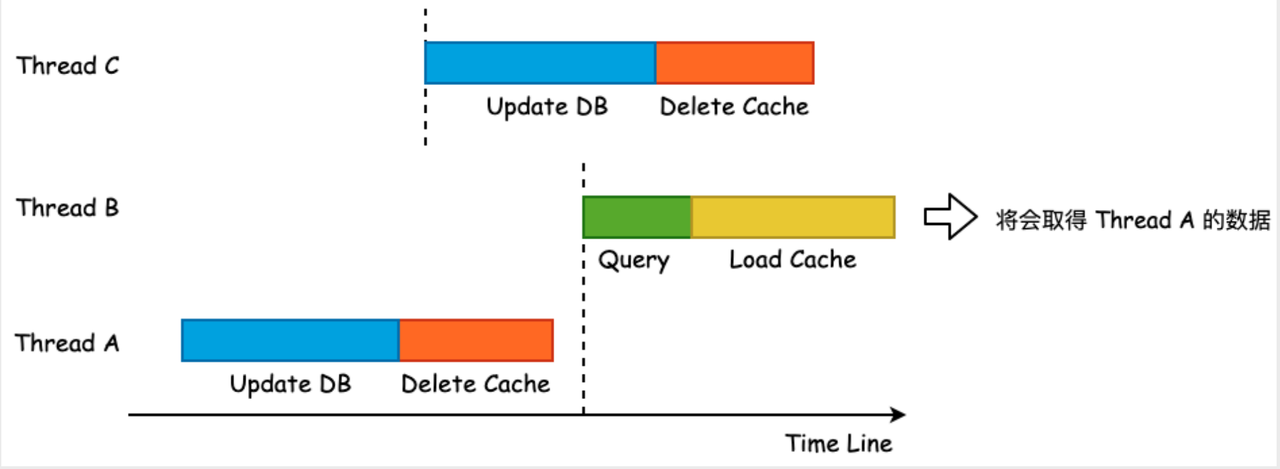
出现数据不一致的情况出现在并发读写的场景下,详情可见下图:
这种情况发生的概率比较低,必须要在某⼀时间区间同时存在两个或多个写⼊和多个读取,所以大部分业务都容忍了这种小概率的不一致。
虽然发生的概率较低,但还是有一些方案可以让影响降到更低。
优化方案
第一种方案为:采用较短的过期时间来减少影响。这种方法有两个缺点:
-
删除后,读请求会 miss
-
如果缓存不一致,不一致的时间取决于过期时间设置
第二种方案则是采用延迟双删的策略,比如:1分钟以后删除缓存。这种做法也存在两个缺点:
-
删除缓存之前的时间里可能会有不一致
-
删除后,读请求会 miss
第三种方案为双更新策略,思路与延迟双删策略差不多。不同的点是,此方案不删除缓存而是更新缓存,所以读请求就不会发生 miss。但是另一个缺点还是存在。
先更新数据库,再更新缓存
相比先更新数据库再删除缓存的操作,先更新数据库再更新缓存的操作可以避免用户请求直接打到数据库,进而导致缓存穿透的问题。
此方案是更新缓存,我们需要关注并发读写和并发写写两个场景下导致的数据不一致。
先来看看并发读写的情况,步骤如下图所示:
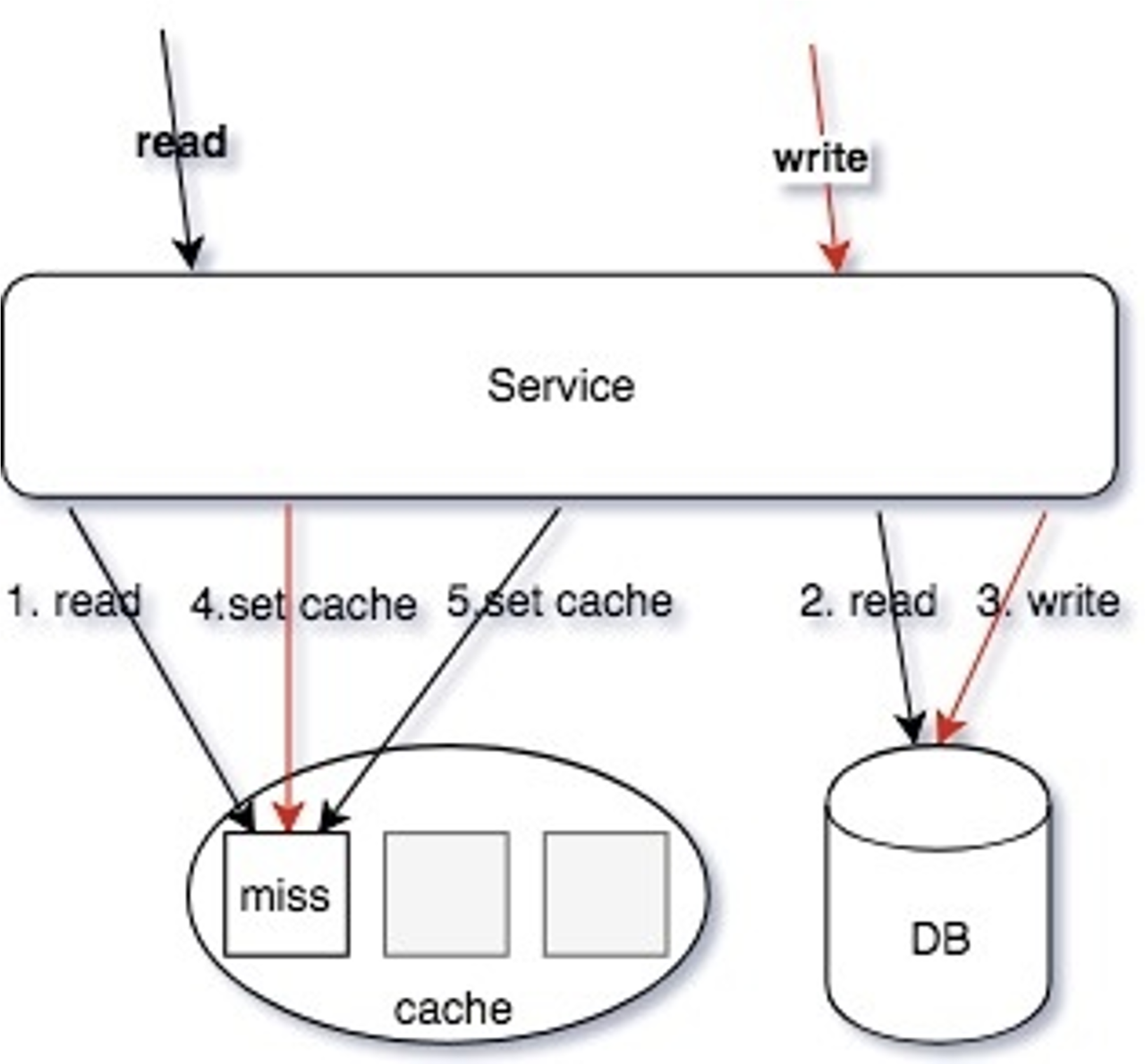
可以看到由于 4 和 5 操作步骤都设置了缓存,如果步骤4发生在步骤5之前,那么会出现旧值覆盖新值的情况,也就是缓存不一致的情况。这种情况只需要修改一下步骤5,便可解决。
优化方案
可以通过在第五步不要 set cache,改用 add cache,redis 中使用 setnx 命令来进行优化。修改后步骤示意图如下:
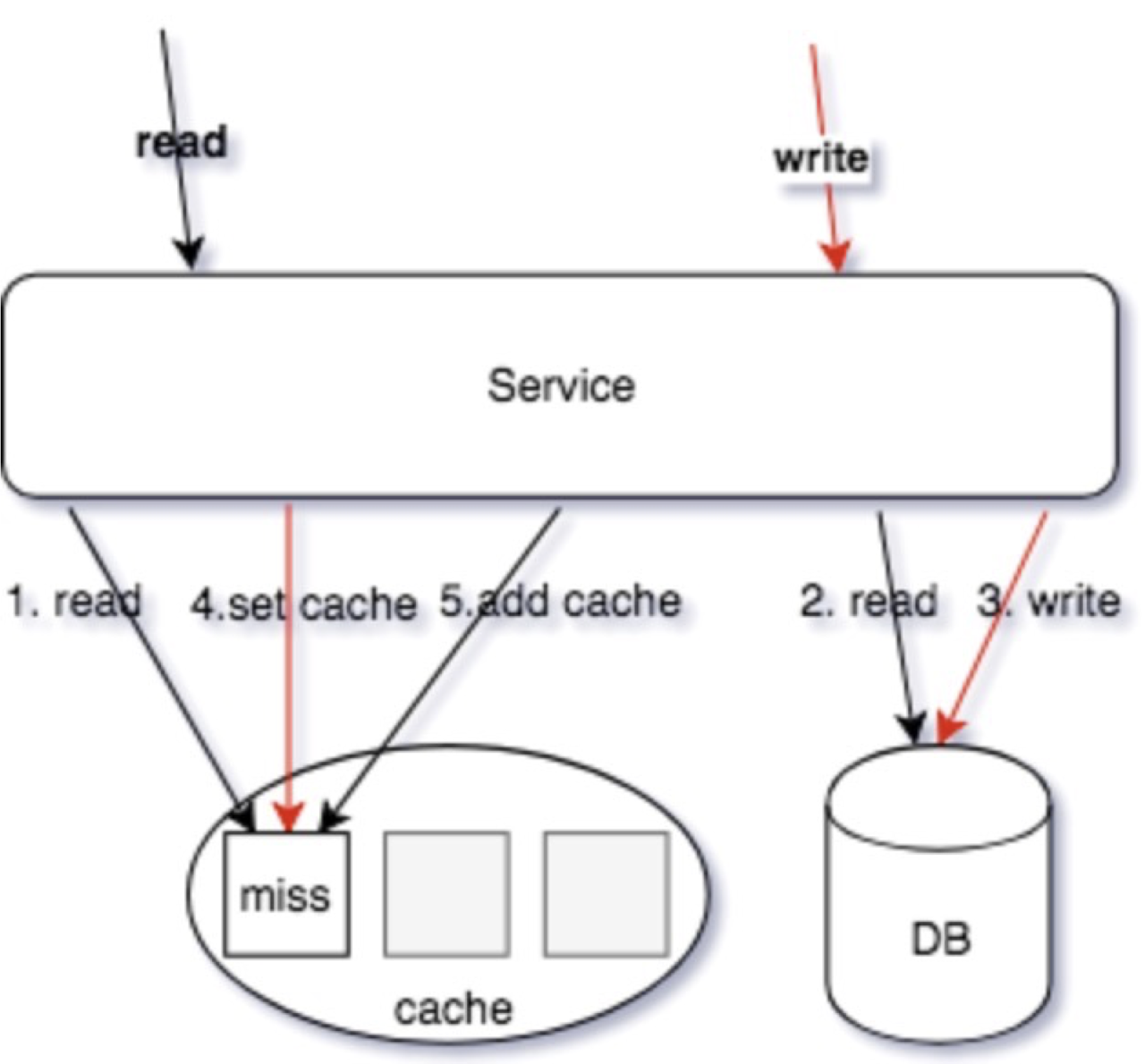
解决完了并发读写场景导致的数据不一致,再来看看并发写写情况导致的数据不一致问题。
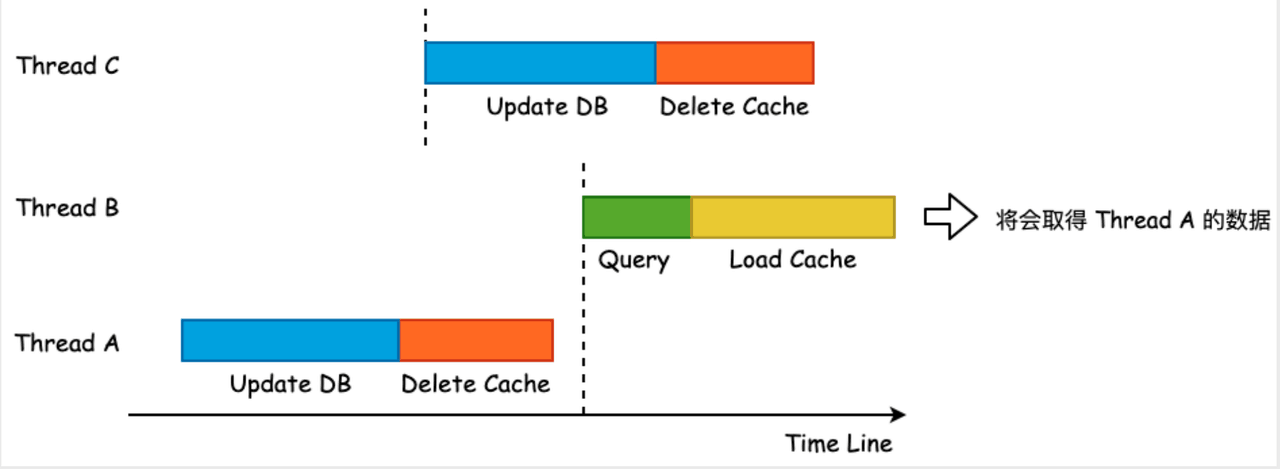
出现不一致的情况如下图所示,Thread A 比 Thread B 先更新完 DB,但是 Thread B 却先更新完缓存,这就导致缓存会被 Thread A 的旧值所覆盖。

这种情况也是有方法可以优化的,下面介绍两个主流方法:
-
使用分布式锁
-
使用版本号
使用分布式锁
要解决并发读写的问题,第一个思路就是消灭并发写。而使用分布式锁,让写操作排队执行,理论上就可以解决并发写的问题,但现在并没有可靠的分布式锁实现方案。
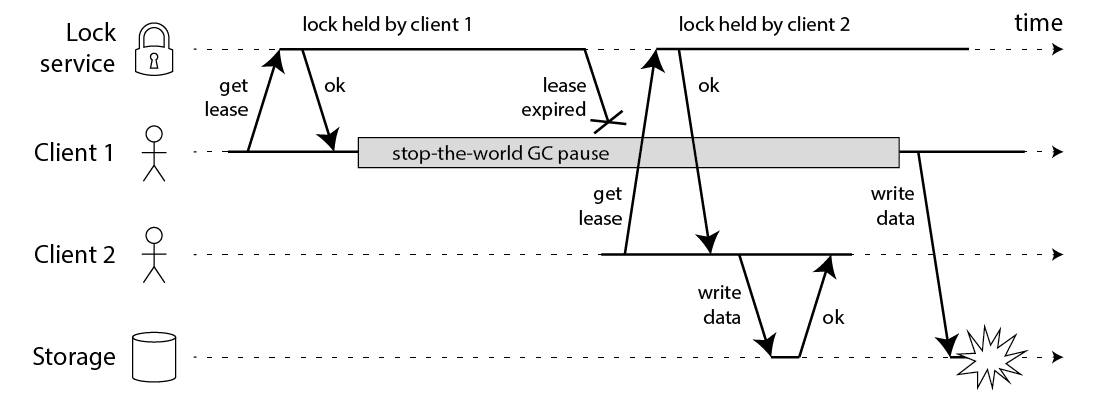
不管是基于 Zookeeper,etcd 还是 redis 实现分布式锁,为了防止程序挂掉而锁不能释放,我们都会给锁设置租约/过期时间,想象一种场景:如果进程卡顿几分钟(虽然概率较低),导致锁失效,而其它线程获取到锁,此时就又出现了并发读写的场景了,还是有可能会造成数据不一致。
使用版本号
并发写导致的数据不一致,是因为低版本覆盖了高版本。那么我们可以想办法不让这种情况发生,一种可行的方案是引入版本号,如果写入的数据低于现版本号,则放弃覆盖。
缺点:
-
应用层维护版本的代价很大,大规模落地很难
-
需修改数据模型,添加版本
-
每次需要修改,让版本自增
不管是更新缓存还是删除缓存,优化以后都将出现数据不一致的概率降到最低了。但是有没有一种办法既简单,又不会出现数据不一致的场景呢。下面就介绍一下 Rockscache。
Rockscache
简介
Rockscache 也是一种保持缓存一致性的方法,它采用的缓存管理策略是:更新数据库后,将缓存标记为删除。主要通过以下两个方法来实现:
-
Fetch 函数实现了前面的查询缓存
-
TagAsDeleted 函数实现了标记删除的逻辑
在运行时只要读数据时调用 Fetch,并且确保更新数据库之后调用 TagAsDeleted,就能够确保缓存最终一致。这一策略有 4 个特点:
-
不需要引入版本,几乎可以适用于所有缓存场景
-
架构上与"更新 DB 后删除缓存”一样,无额外负担
-
性能高:变化只是将原来的 GET/SET/DELETE,替换为 Lua 脚本
-
强一致方案的性能也很高,与普通的防缓存击穿方案一样
在 Rockscache 策略中,缓存中的数据是包含几个字段的 hash:
-
value:数据本身
-
lockUtil:数据锁定到期时间,当某个进程查询缓存无数据,那么先锁定缓存一小段时间,然后查询 DB,然后更新缓存
-
owner:数据锁定者 uuid
证明
因为 Rockscache 方案并不更新缓存,所以只要确保并发读写数据一致性即可。下面来看看 Rockscache 是怎么解决数据不一致的问题,先回忆一遍 cache aside 模式导致的数据不一致的原因。
结合 cache aside 模式出现数据不一致的场景,来讲讲 Rockscache 是怎么解决的。
我们要解决的核心问题是,防止旧值写入到缓存中。Rockscache 的解决方案是这样的:
-
查询请求,如果缓存中读不到数据,还要做一个操作:锁定缓存,为key设置一个uuid(代码示例:https://github.com/dtm-labs/rockscache/blob/main/client.go#L191)
-
写请求在删除缓存的时候,需要把锁删了(代码示例:https://github.com/dtm-labs/rockscache/blob/main/client.go#L96)
-
读请求在设置缓存的时候,通过uuid比对,发现上锁的不是自己,说明有写请求把数据更新了,则放弃修改缓存(代码示例:https://github.com/dtm-labs/rockscache/blob/main/client.go#L160)
至此我们已经完成了 rockscache 策略下的缓存更新。不过和其他缓存更新策略一样,我们都默认操作数据库成功后,操作缓存肯定成功。但是这是不对的,在实际操作过程即便操作数据库成功,也可能出现缓存操作失败的情况,因此可以通过以下 3 种方式来保证缓存更新成功:
-
本地消息表
-
监听 binlog
-
dtm 的二阶段消息
除了缓存更新,Rockscache 还有以下两种功能:
-
防止缓存击穿
-
防止防止穿透和缓存雪崩
这都是非常实用的功能,推荐大家实际使用操作试试看。
参考资料
-
https://dtm.pub/app/cache.html
-
https://smartkeyerror.oss-cn-shenzhen.aliyuncs.com/Psyduck/redis/%E7%BC%93%E5%AD%98%E6%9B%B4%E6%96%B0%E7%9A%84%E7%AD%96%E7%95%A5.pdf