文章目录
- 前言
- ExecutionGraph中的主要抽象概念
- 源码核心代码入口
- 源码核心流程:
前言
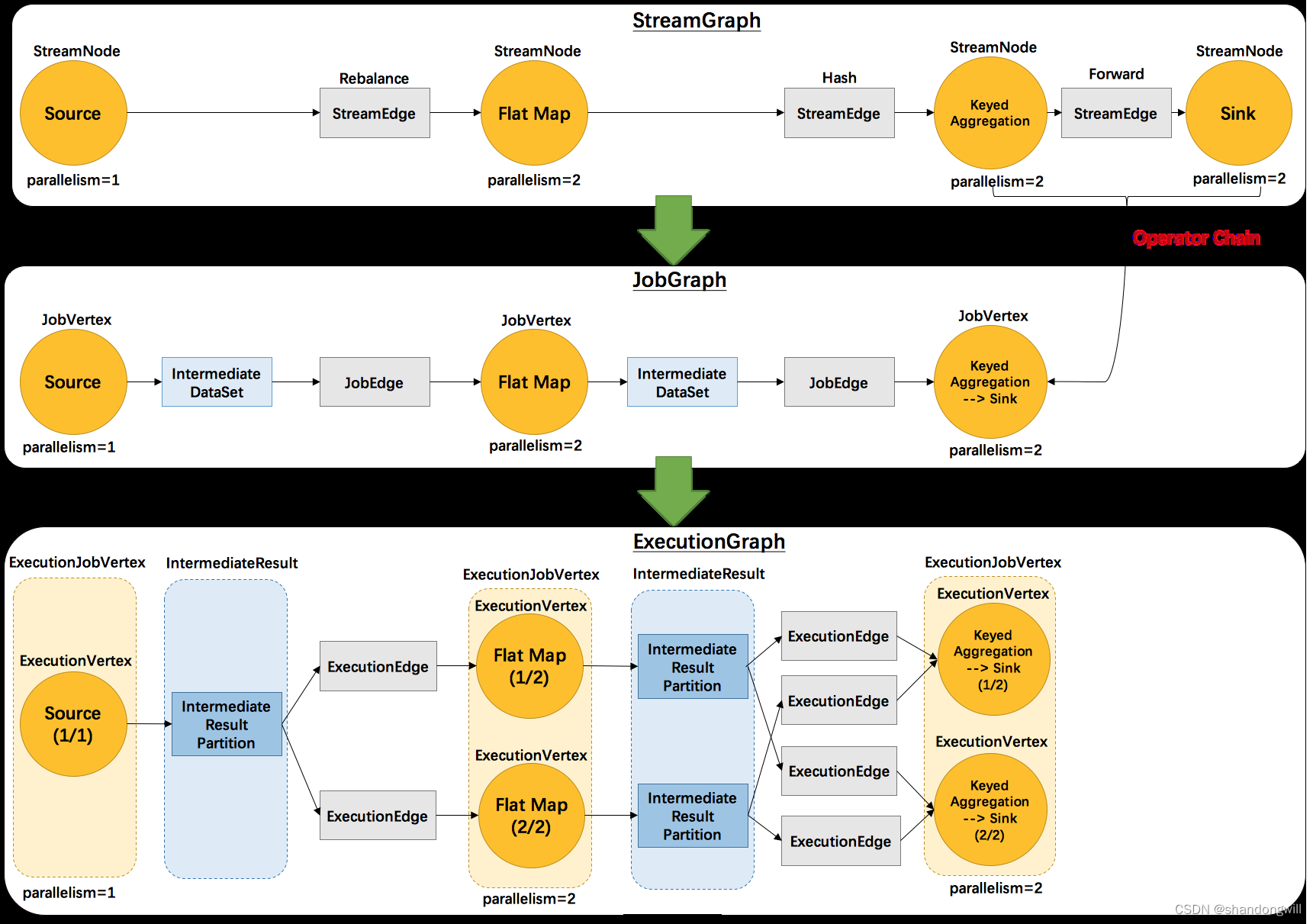
在JobGraph构建过程中分析了JobGraph的构建过程,本文分析ExecutionGraph的构建过程。JobManager(JobMaster) 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph是JobGraph 的并行化版本,是调度层最核心的数据结构。
ExecutionGraph中的主要抽象概念
1、ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有
和并发度一样多的 ExecutionVertex。
2、ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输
出是IntermediateResultPartition。
3、IntermediateResult:和JobGraph中的IntermediateDataSet一一对应。一个
IntermediateResult包含多个IntermediateResultPartition,其个数等于该operator的并发度。
4、IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是
ExecutionVertex,consumer是若干个ExecutionEdge。
5、ExecutionEdge:表示ExecutionVertex的输入,source是IntermediateResultPartition,
target是ExecutionVertex。source和target都只能是一个。
6、Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下
ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过
ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过
ExecutionAttemptID 来确定消息接受者。
源码核心代码入口
ExecutionGraph executioinGraph = SchedulerBase.createAndRestoreExecutionGraph(
completedCheckpointStore,
checkpointsCleaner,
checkpointIdCounter,
initializationTimestamp,
mainThreadExecutor,
jobStatusListener,
vertexParallelismStore);
在 SchedulerBase 这个类的内部,有两个成员变量:一个是 JobGraph,一个是 ExecutioinGraph
在创建 SchedulerBase 的子类:DefaultScheduler 的实例对象的时候,会在 SchedulerBase 的构造
方法中去生成 ExecutionGraph。
源码核心流程:
DefaultExecutionGraphFactory.createAndRestoreExecutionGraph()
ExecutionGraph newExecutionGraph = createExecutionGraph(...)
DefaultExecutionGraphBuilder.buildGraph(jobGraph, ....)
// 创建 ExecutionGraph 对象
executionGraph = (prior != null) ? prior : new ExecutionGraph(...)
// 生成 JobGraph 的 JSON 表达形式
executionGraph.setJsonPlan(JsonPlanGenerator.generatePlan(jobGraph));
// 重点,从 JobGraph 构建 ExecutionGraph
executionGraph.attachJobGraph(sortedTopology);
// 遍历 JobVertex 执行并行化生成 ExecutioinVertex
for(JobVertex jobVertex : topologiallySorted) {
// 每一个 JobVertex 对应到一个 ExecutionJobVertex
ExecutionJobVertex ejv = new ExecutionJobVertex(jobGraph,
jobVertex);
ejv.connectToPredecessors(this.intermediateResults);
List<JobEdge> inputs = jobVertex.getInputs();
for(int num = 0; num < inputs.size(); num++) {
JobEdge edge = inputs.get(num);
IntermediateResult ires =intermediateDataSets.get(edgeID);
this.inputs.add(ires);
// 根据并行度来设置 ExecutionVertex
for(int i = 0; i < parallelism; i++) {
ExecutionVertex ev = taskVertices[i];
ev.connectSource(num, ires, edge,consumerIndex);
}
}
}
DefaultExecutionGraphBuilder 详细代码如下:
public class DefaultExecutionGraphBuilder {
public static DefaultExecutionGraph buildGraph(
JobGraph jobGraph,
Configuration jobManagerConfig,
ScheduledExecutorService futureExecutor,
Executor ioExecutor) {
final String jobName = jobGraph.getName();
final JobID jobId = jobGraph.getJobID();
final JobInformation jobInformation = new JobInformation(... );
// create a new execution graph, if none exists so far
final DefaultExecutionGraph executionGraph;
executionGraph = new DefaultExecutionGraph( ....);
// set the basic properties
executionGraph.setJsonPlan(JsonPlanGenerator.generatePlan(jobGraph));
// initialize the vertices that have a master initialization hook
// file output formats create directories here, input formats create splits
for (JobVertex vertex : jobGraph.getVertices()) {
String executableClass = vertex.getInvokableClassName();
vertex.initializeOnMaster(
new SimpleInitializeOnMasterContext(
classLoader,
vertexParallelismStore
.getParallelismInfo(vertex.getID())
.getParallelism()));
}
// topologically sort the job vertices and attach the graph to the existing one
List<JobVertex> sortedTopology = jobGraph.getVerticesSortedTopologicallyFromSources();
executionGraph.attachJobGraph(sortedTopology);
// configure the state checkpointing
if (isDynamicGraph) {
// dynamic graph does not support checkpointing so we skip it
log.warn("Skip setting up checkpointing for a job with dynamic graph.");
} else if (isCheckpointingEnabled(jobGraph)) {
JobCheckpointingSettings snapshotSettings = jobGraph.getCheckpointingSettings();
// load the state backend from the application settings
final StateBackend applicationConfiguredBackend;
final SerializedValue<StateBackend> serializedAppConfigured =
snapshotSettings.getDefaultStateBackend();
if (serializedAppConfigured == null) {
applicationConfiguredBackend = null;
} else {
try {
applicationConfiguredBackend =
serializedAppConfigured.deserializeValue(classLoader);
} catch (IOException | ClassNotFoundException e) {
throw new JobExecutionException(
jobId, "Could not deserialize application-defined state backend.", e);
}
}
final StateBackend rootBackend =
StateBackendLoader.fromApplicationOrConfigOrDefault(
applicationConfiguredBackend,
snapshotSettings.isChangelogStateBackendEnabled(),
jobManagerConfig,
classLoader,
log);
// load the checkpoint storage from the application settings
final CheckpointStorage applicationConfiguredStorage;
final SerializedValue<CheckpointStorage> serializedAppConfiguredStorage =
snapshotSettings.getDefaultCheckpointStorage();
if (serializedAppConfiguredStorage == null) {
applicationConfiguredStorage = null;
} else {
applicationConfiguredStorage = serializedAppConfiguredStorage.deserializeValue(classLoader);
final CheckpointStorage rootStorage;
try {
rootStorage =
CheckpointStorageLoader.load(
applicationConfiguredStorage,
null,
rootBackend,
jobManagerConfig,
classLoader,
log);
} catch (IllegalConfigurationException | DynamicCodeLoadingException e) {
throw new JobExecutionException(
jobId, "Could not instantiate configured checkpoint storage", e);
}
// instantiate the user-defined checkpoint hooks
final SerializedValue<MasterTriggerRestoreHook.Factory[]> serializedHooks =
snapshotSettings.getMasterHooks();
final List<MasterTriggerRestoreHook<?>> hooks;
if (serializedHooks == null) {
hooks = Collections.emptyList();
} else {
final MasterTriggerRestoreHook.Factory[] hookFactories;
try {
hookFactories = serializedHooks.deserializeValue(classLoader);
} catch (IOException | ClassNotFoundException e) {
throw new JobExecutionException(
jobId, "Could not instantiate user-defined checkpoint hooks", e);
}
final Thread thread = Thread.currentThread();
final ClassLoader originalClassLoader = thread.getContextClassLoader();
thread.setContextClassLoader(classLoader);
try {
hooks = new ArrayList<>(hookFactories.length);
for (MasterTriggerRestoreHook.Factory factory : hookFactories) {
hooks.add(MasterHooks.wrapHook(factory.create(), classLoader));
}
} finally {
thread.setContextClassLoader(originalClassLoader);
}
}
final CheckpointCoordinatorConfiguration chkConfig =
snapshotSettings.getCheckpointCoordinatorConfiguration();
String changelogStorage = jobManagerConfig.getString(STATE_CHANGE_LOG_STORAGE);
executionGraph.enableCheckpointing(
chkConfig,
hooks,
checkpointIdCounter,
completedCheckpointStore,
rootBackend,
rootStorage,
checkpointStatsTrackerFactory.get(),
checkpointsCleaner,
jobManagerConfig.getString(STATE_CHANGE_LOG_STORAGE));
}
return executionGraph;
}
}