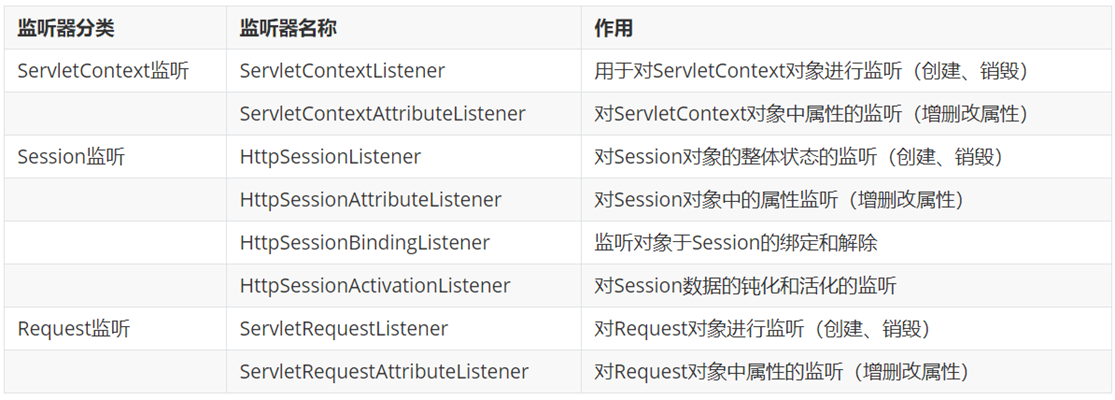
TensorFlow和PyTorch是两个最受欢迎的开源深度学习框架,这两个框架都为构建和训练深度学习模型提供了广泛的功能,并已被研发社区广泛采用。但是作为用户,我们一直想知道哪种框架最适合我们自己特定项目,所以在本文与其他文章的特性的对比不同,我们将以实际应用出发,从性能、可伸缩性和其他高级特性方面比较TensorFlow和PyTorch。

性能
在选择深度学习框架时,一个关键的考虑因素是你构建和训练的模型的性能。
TensorFlow和PyTorch都进行了性能优化,这两个框架都提供了大量的工具和技术来提高模型的速度。
就原始性能而言,TensorFlow比PyTorch更好一些。这两个框架之间的一个关键区别是使用静态计算图而不是动态计算图。在TensorFlow中,在模型训练之前,计算图是静态构造的。这使得TensorFlow可以通过分析图并应用各种优化技术来更有效地优化图的性能。
而PyTorch使用动态计算图,这意味着图是在训练模型时动态构建的。虽然这可能更灵活,更容易使用,但在某些情况下也可能效率较低。
但是记住这一点很重要
TensorFlow和PyTorch之间的性能差异相非常小,这是因为这两个框架都对性能进行了优化,并提供了许多工具和方法来提高模型的速度,在很多情况下根本发现不了他们的区别。
除了使用静态与动态计算图之外,还有许多其他因素会影响模型的性能。这些因素包括硬件和软件环境的选择、模型的复杂性以及数据集的大小。通过考虑这些因素并根据需要应用优化技术,可以使用TensorFlow或PyTorch构建和训练高性能模型。
除了原始性能,TensorFlow和PyTorch都提供了大量的工具和方法来提高模型的速度:
TensorFlow提供了多种优化方法,可以极大地提高模型的性能,例如自动混合精度和XLA。
XLA(加速线性代数):TensorFlow包括一个称为XLA的即时(JIT)编译器,它可以通过应用多种优化技术来优化模型的性能,包括常数折叠、代数简化和循环融合。要启用XLA,可以使用tf.config.optimizer.set_jit函数。
TFX (TensorFlow Extended): TFX是一套用于构建和部署机器学习管道的库和工具,包括用于数据处理、模型训练和模型服务的工具。TFX可以通过自动化所涉及的许多步骤,更有效地构建和部署机器学习模型。
tf.function函数装饰器可以将TensorFlow函数编译成一个图,这可能比强制执行函数更快,可以利用TensorFlow的优化技术来提高模型的性能。
PyTorch通过使用torch.autograd 和torch.jit等提供了优化模型的方法,它提高模型的有效性
torch.autograd.profiler:通过跟踪 PyTorch 模型的各种元素使用的时间和内存量,可以帮助找到瓶颈和代码中需要改进的地方。
torch.nn.DataParallel:torch.nn.DataParallel 类可跨多个设备(例如 GPU)并行训练 PyTorch 模型。 通过使用 DataParallel,可以利用多个设备来增加模型的推理效率。
torch.jit:使用即时 (JIT) 编译器优化 PyTorch 模型。 torch.jit 将模型编译成静态计算图,与动态图相比可以更有效地进行优化。
静态与动态计算图定义的编码示例:
如前所述,TensorFlow在原始性能方面比PyTorch略有优势,这是由于它的静态计算图。
下面是一个在TensorFlow中构建前馈神经网络的简单例子:
importtensorflowastf
# Define the model
model=tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(64,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Fit the model
model.fit(x_train, y_train, epochs=5)
下面是在PyTorch中实现和训练的相同模型:
importtorch
importtorch.nnasnn
importtorch.optimasoptim
# Define the model
classNet(nn.Module):
def__init__(self):
super(Net, self).__init__()
self.fc1=nn.Linear(64, 64)
self.fc2=nn.Linear(64, 64)
self.fc3=nn.Linear(64, 10)
defforward(self, x):
x=self.fc1(x)
x=self.fc2(x)
x=self.fc3(x)
returnx
# Create the model instance
model=Net()
# Define the loss function and optimizer
criterion=nn.CrossEntropyLoss()
optimizer=optim.Adam(model.parameters())
# Training loop
forepochinrange(5):
# Forward pass
output=model(x_train)
loss=criterion(output, y_train)
# Backward pass and optimization step
optimizer.zero_grad()
loss.backward()
optimizer.step()
这两个例子都展示了如何构建和训练一个简单的前馈神经网络,虽然方法不同但是他们的性能基本却相同。对于性能的对比,目前来说两个框架基本相同,差异可以忽略不计。
可伸缩性
在选择深度学习框架时,另一个重要考虑因素是可伸缩性。随着模型的复杂性和规模的增长,需要一个能够处理不断增长的计算需求的框架。
这两个框架都提供了扩展模型的策略,但它们处理问题的方式略有不同。
TensorFlow在设计时考虑了可伸缩性,并提供了许多用于分布式训练和部署的工具。
例如,TensorFlow 的 tf. distribute API 可以轻松地跨多个设备和服务器分发训练,而 TensorFlow Serving 可以将经过训练的模型部署到生产环境。
PyTorch也提供用于分布式培训和部署的工具,但重点更多地放在研究和开发上,而不是生产环境。
PyTorch 的 torch.nn.DataParallel 和 torch.nn.parallel.DistributedDataParallel 类可以跨多个设备并行训练,而 PyTorch Lightning 库(非官方)为分布式训练和部署提供了一个高级接口。
TensorFlow
- tf.distribute.Strategy:tf.distribute.Strategy API 可跨多个设备和机器并行训练 TensorFlow 模型。 有许多不同的策略可用,包括 tf.distribute.MirroredStrategy,它支持在单台机器上的多个 GPU 上进行训练,以及 tf.distribute.experimental.MultiWorkerMirroredStrategy,它在具有多个 GPU 的多台机器上提供训练。
- tf.data.Dataset:可以为训练构建了高效且高度并行化的数据管道。 通过使用 tf.data.Dataset,可以轻松地并行加载和预处理大型数据集,这可以模型扩展到更大的数据集。
- tf.keras.layers.Normalization:tf.keras.layers.Normalization 层实时规范化输入数据,这可能有助于提高模型的性能。 应用归一化可以减少大输入值的影响,这可以帮助模型更快地收敛并获得更好的性能。
- tf.data.Dataset.interleave:通过对数据并行应用函数,再次并行处理输入数据。 这对于数据预处理等任务非常有用,在这些任务中您需要对数据应用大量转换。
Pytorch
- torch.nn.parallel.DistributedDataParallel:torch.nn.parallel.DistributedDataParallel 类在多个设备和机器上并行训练 PyTorch 模型。 但是需要使用torch.nn.parallel.DistributedDataParallel.init_process_group 设置分布式训练环境。
- torch.utils.data.DataLoader:创建一个数据迭代器,用于并行处理数据的加载和预处理。
- torch.utils.data.distributed.DistributedSampler:类似于 torch.utils.data.DistributedSampler,但设计用于与 DistributedDataParallel 类一起使用。 通过使用 DistributedSampler,可以确保在使用DistributedDataParallel 进行训练时,每个设备都会收到平衡的数据样本。
通过利用这些函数和类,可以将 TensorFlow 和 PyTorch 模型扩展到更大的数据集和更强大的硬件,构建更准确、更强大的模型。
下面介绍了提高可伸缩性的两种不同方法。
TensorFlow的第一个例子使用了tf.distribute. mirrredstrategy:
importtensorflowastf
# Define the model
model=tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(64,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Define the distribution strategy
strategy=tf.distribute.MirroredStrategy()
# Load the dataset
dataset=tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(64)
# Define the training loop
withstrategy.scope():
forepochinrange(5):
forx_batch, y_batchindataset:
model.fit(x_batch, y_batch)
在PyTorch使用 torch.nn.DataParallel :
importtorch
importtorch.nnasnn
importtorch.optimasoptim
# Define the model
classNet(nn.Module):
def__init__(self):
super(Net, self).__init__()
self.fc1=nn.Linear(64, 64)
self.fc2=nn.Linear(64, 64)
self.fc3=nn.Linear(64, 10)
defforward(self, x):
x=self.fc1(x)
x=self.fc2(x)
x=self.fc3(x)
returnx
# Create the model instance and wrap it in DataParallel
model=nn.DataParallel(Net())
# Define the loss function and optimizer
criterion=nn.CrossEntropyLoss()
optimizer=optim.Adam(model.parameters())
# Training loop
forepochinrange(5):
# Forward pass
output=model(x_train)
loss=criterion(output, y_train)
# Backward pass and optimization step
optimizer.zero_grad()
loss.backward()
optimizer.step()
这两个例子都展示了如何在多个设备上并行训练,但TensorFlow对于分布式训练的支持要比Pytorch更好一些。
高级的特性
除了性能和可伸缩性之外,这两个框架还提供了许多项目相关的高级特性。
例如,TensorFlow拥有强大的工具和库生态系统,包括用于可视化的TensorBoard和用于模型部署和服务的TensorFlow Extended。
PyTorch也多个高级特性,一般都会命名为 torchXXX,比如torchvision,torchaudio等等
我们以TensorBoard为例介绍两个库的使用,虽然TensorBoard是TensorFlow的一部分,但是Pytorch也通过代码部分兼容了数据部分的发送,也就是说使用Pytorch也可以往TensorBoard写入数据,然后通过TensorBoard进行查看。
TensorFlow 在训练时使用TensorBoard的callback可以自动写入。
importtensorflowastf
# Define the model
model=tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(64,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Define a TensorBoard callback
tensorboard_callback=tf.keras.callbacks.TensorBoard(log_dir='logs')
# Fit the model
model.fit(x_train, y_train, epochs=5, callbacks=[tensorboard_callback])
Pytorch需要自行代码写入:
importnumpyasnp
fromtorch.utils.tensorboardimportSummaryWriter
writer=SummaryWriter(comment='test_tensorboard')
forxinrange(100):
writer.add_scalar('y=2x', x*2, x)
writer.add_scalar('y=pow(2, x)', 2**x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x*np.sin(x),
"xcosx": x*np.cos(x),
"arctanx": np.arctan(x)}, x)
writer.close()
在高级特性中我觉得最主要的就是TensorFlow 中引入了Keras,这样只需要几行代码就可以完成完整的模型训练
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
而Pytorch还要手动进行损失计算,反向传播
output=model(x_train)
loss=criterion(output, y_train)
# Backward pass and optimization step
optimizer.zero_grad()
loss.backward()
optimizer.step()
虽然这样灵活性很高,但是应该有一个像Keras这样的通用方法(TensorFlow 也可以手动指定计算过程,并不是没有),所以在这一部分中我觉得TensorFlow要比Pytorch好很多。
当然也有一些第三方的库来简化Pytorch的训练过程比如PyTorch Lightning、TorchHandle等但是终究不是官方的库。
最后总结
最适合你的深度学习框架将取决于你的具体需求和要求
TensorFlow 和 PyTorch 都提供了广泛的功能和高级特性,并且这两个框架都已被研发社区广泛采用。 作为高级用户,我的个人建议是深入学习一个库,另外一个库代码基本上是类似的,基础到了基本上做到能看懂就可以了,比如
classDNNModel(nn.Module):
def__init__(self):
super(DNNModel, self).__init__()
self.fc1=nn.Linear(2,4)
self.fc2=nn.Linear(4,8)
self.fc3=nn.Linear(8,1)
# 正向传播
defforward(self,x):
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
y=nn.Sigmoid()(self.fc3(x))
returny
################
classDNNModel(models.Model):
def__init__(self):
super(DNNModel, self).__init__()
defbuild(self,input_shape):
self.dense1=layers.Dense(4,activation="relu",name="dense1")
self.dense2=layers.Dense(8,activation="relu",name="dense2")
self.dense3=layers.Dense(1,activation="sigmoid",name="dense3")
super(DNNModel,self).build(input_shape)
# 正向传播
@tf.function(input_signature=[tf.TensorSpec(shape= [None,2], dtype=tf.float32)])
defcall(self,x):
x=self.dense1(x)
x=self.dense2(x)
y=self.dense3(x)
returny
看看上面代码的两个类它们的区别并不大,对吧。
下面是google trends的趋势对比,我们可以看到明显的区别
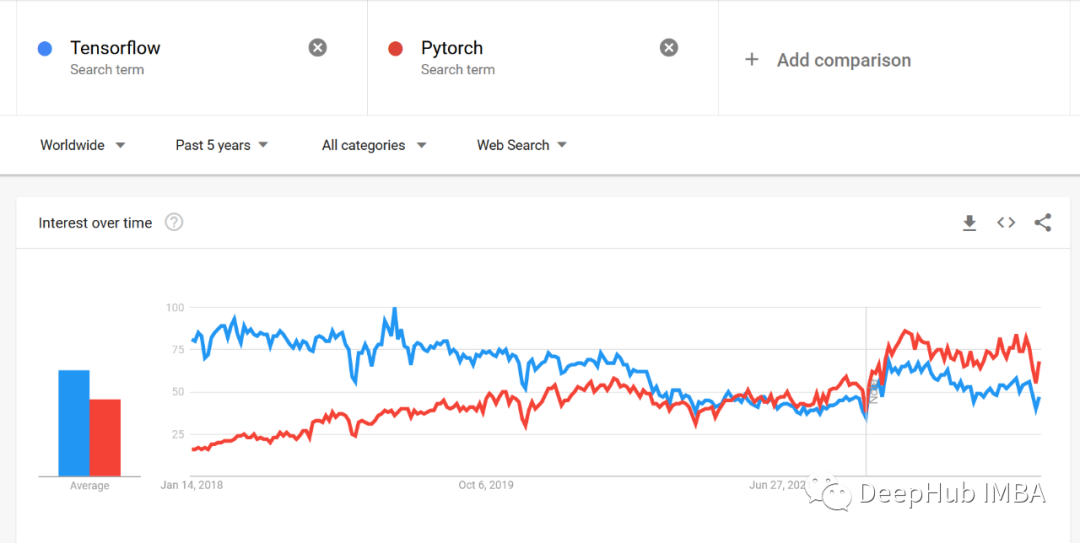
该学那个自己看吧
https://avoid.overfit.cn/post/786849900e314953a64565e5feb5076e
作者:Jan Marcel Kezmann