什么是缓存
缓存就是数据交换的缓冲区,是存储数据的临时地方,一般读写性能较高。在以前CPU需要将内存或磁盘中读到数据放寄存器才可以做运算,正是因此计算机运算的能力受到限制。为了解决,人们在CPU中设计了缓存,将一些经常需要读写的数据放入缓存中,这样在进行高速运算时就不需要频繁的进行磁盘或者内存的I/O。
所以,衡量CPU好坏的一项重要指标——缓存的大小
在浏览器中也不例外,也会将经常浏览的信息添加到缓存里
缓存的作用与代价
缓存的作用不必多说,提高了读写的效率,降低响应的时间,减少了数据库与磁盘的i/o自然会降低后端的负载。
但是与此同时会带来数据一致性的问题:
如果请求命中缓存,直接去访问缓存,另一个对数据修改的接口被执行导致数据库里的信息被修改。这样一来在最开始从数据库里读到并放入缓存的信息与之后就产生了不一致,另外缓存穿透、缓存雪崩也有可能随之发生,显然这就直接地提升了代码维护的成本。
缓存工作模型
为接口添加缓存可以减少查询数据库的次数,减少了磁盘I/O自然会使接口性能提升。
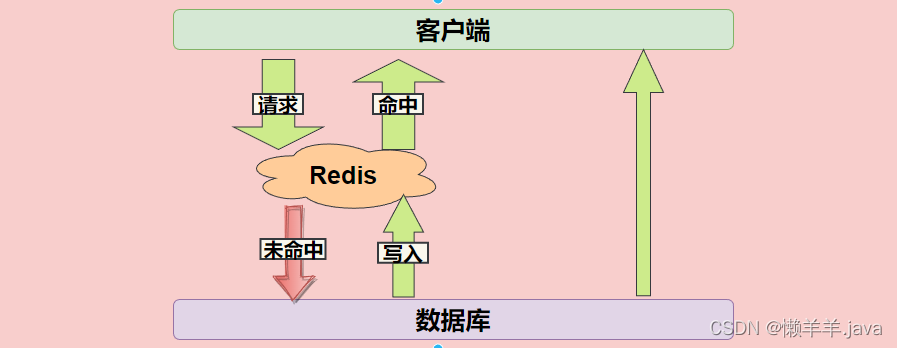
缓存就相当于在数据库和客户端之间添加了一层中间层,当客户端的请求命中缓存就会直接从缓存中获得信息,当请求未命中缓存(经常是在第一次访问的情况)就会去查询数据库,并将数据库的信息返回给客户端,与此同时,将从库中查到的信息添加到缓存中。
这样一看,客户端与数据库的交互明显减少了!自然而然效率就提升了。
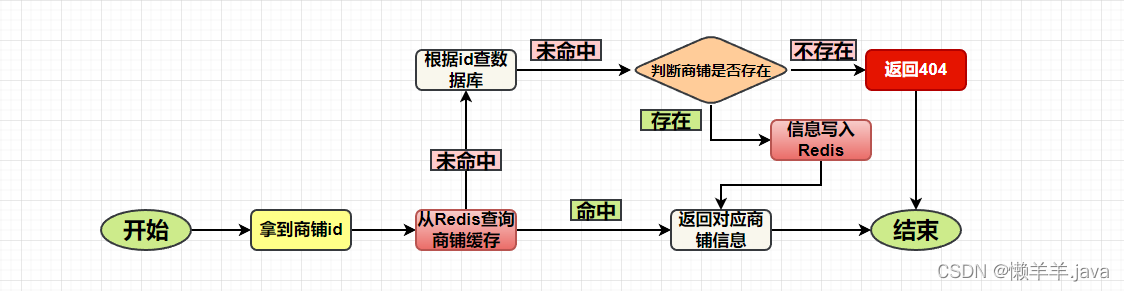
为查询接口添加缓存
为一个频繁使用的商铺查询接口添加缓存:
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
/**
* 添加查询商铺缓存
* @param id
* @return
*/
@Override
public Result queryById(Long id) {
String key=CACHE_SHOP_KEY+id;
String shopJson = stringRedisTemplate.opsForValue().get(key); //JSON格式
if (StrUtil.isBlank(shopJson)){
//存在则直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
//不存在则先查数据库
Shop shopById = getById(id);
//数据库里查不到说明没有
if (shopById==null){
return Result.fail("暂无该商铺信息");
}
//把查到的放到缓存里
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shopById));
//返回给前端
return Result.ok(shopById);
}
}
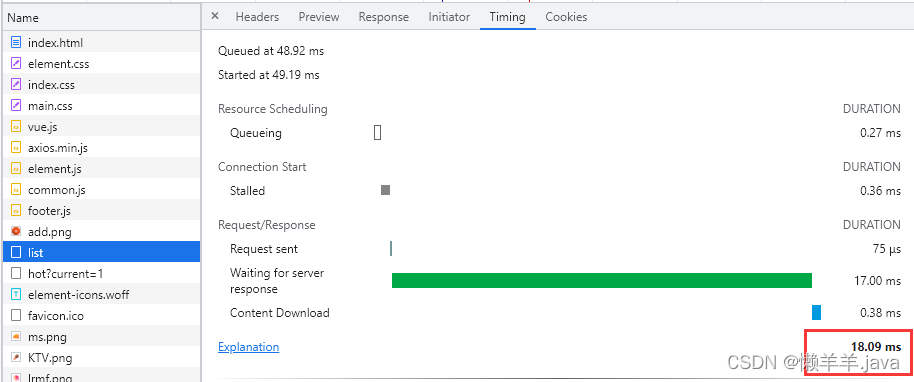
直观的感受一下,同一个接口查询缓存与查询数据库的性能差距:
查询数据库时 1.16s
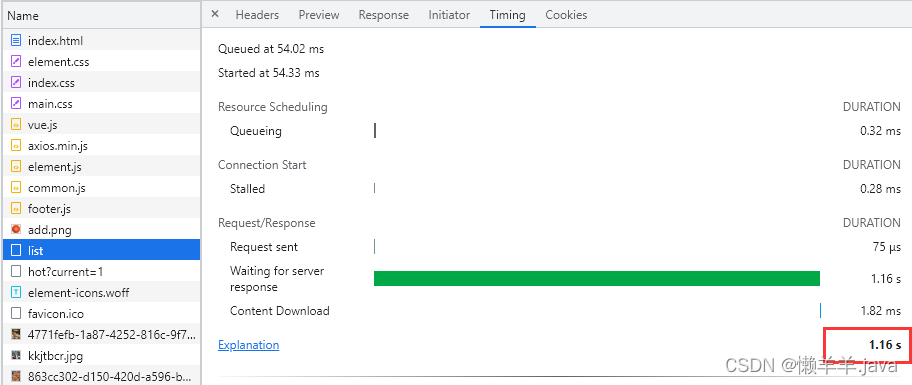
查询缓存时 18.09ms