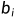文章目录
- 1、DPDK 原理
- 1.1、用户态驱动 IO
- 1.2、内存池管理
- 2、DPDK 启动设置
- 3、DPDK:UDP 协议栈
- 3.1、代码实现
- 3.2、设置静态 arp
- 4、DPDK:KNI
- 4.1、代码实现
- 4.2、程序测试
文章参考<零声教育>的C/C++linux服务期高级架构系统教程学习: 服务器高级架构体系
云技术的出现代表着网络功能虚拟化(NFV)共享硬件成为趋势,NFV的定义是通过标准的服务器、标准交换机实现各种传统的或新的网络功能。越来越多的网络设备基础架构开始逐步向基于通用处理器平台的方向发展。NFV 使得网络在变得更加可控制和成本更低的同时,也需要支持大规模用户或应用程序的性能需求,以及具备对大规模数据的处理能力。
传统的基于内核的报文处理方式通过中断将报文分发至内核,当服务器处理大规模报文时会产生频繁的中断,造成大量的性能开销。当内核协议栈处理报文完毕后,还涉及到将报文一次拷贝到用户层的操作。以上问题成为服务器处理大规模报文的阻碍。
高性能网络报文处理框架的理念是服务器上软件的方式进行优化,利用CPU多核对网络负载处理、依靠软件的方式旁路内核、通过轮询屏蔽中断,在用户态处理网络报文和业务。目前运行在用户态的高性能网络报文处理框架中,Intel 的 DPDK (数据平面开发套件,Data Plane Development Kit) 最早开源投入商用,应用也最为广泛,除此以外还有 wind、Netmap、PF_Ring、NBA、Snap 等一系列高性能报文处理框架。
DPDK 技术采用数据层与控制层分离的设计,在用户空间处理数据包、管理内存、调度处理器,而内核仅负责部分控制指令的处理。
1、DPDK 原理
DPDK 舍弃了内核中断,提供全用户态的驱动,拥有高效的内存管理机制,报文直接通过直接内存存取(DMA, direct memory access)传输到用户态处理,减少内存拷贝次数。
DPDK 旁路原理

左边:传统方式,数据从网卡 -> 驱动 -> 协议栈 -> socket 接口 -> 业务
右边:DPDK 方式,基于 UIO 旁路数据。数据从网卡 -> DPDK轮询模式-> DPDK基础库 -> 业务
DPDK 特点
- UIO:用户态驱动 IO,将报文拷贝到用户空间
- hugepage:巨页,通过大内存页提高内存使用效率。
- cpu affinity:将线程绑定到 cpu 上,这样在线程执行过程中,就不会被随意调度,一方面减少了线程间的频繁切换带来的开销,另一方面避免了 CPU 缓存的局部失效性,增加了 CPU 缓存的命中率。
- zero copy:减少数据拷贝次数
1.1、用户态驱动 IO
为减少中断开销,DPDK 抛弃了传统的内核中断,采用轮询模式驱动 (poll mode driver, PMD) 的方式直接操作网卡的接收和发送队列,将报文直接拷贝到用户空间,不再经过内核协议栈。
DPDK 的用户态 IO(user space I/O, UIO)驱动技术为 PMD 提供了支持。其主要功能是拦截中断,并重设中断回调行为,从而绕过内核协议栈的后续处理流程。
UIO 技术使得内核空间与用户空间的内存交互不用进行拷贝,而是只做控制权转移,减少了报文的拷贝过程。即具有零拷贝,无系统调用的好处,同步处理也减少了上下文切换带来的 cache miss。从而中断与拷贝中节省的资源和时延,有效地运行在报文处理流程中,提高了报文的处理、转发效率。
UIO 设备的实现机制其实是对用户空间暴露文件接口,比如当注册一个 UIO 设备 uioX,就会出现文件 /dev/uioX,对该文件的读写就是对设备内存的读写。除此之外,对设备的控制还可以通过 /sys/class/uio 下的各个文件的读写来完成。

1.2、内存池管理
Linux 使用 4kB 大小的分页来管理内存,而 DPDK 使用 2MB 或 1GB 的巨页来管理内存,一个页表缓存 TLB 表项可以指向更大的内存区域,从而减少了 TLB miss。
DPDK 对网络报文的内存操作对象是 Mbuf,Mbuf 存储在内存池 Mempool 中。内存池中的内存从巨页中提前分配,并且同时预先分配好指定大小的 Mbuf 对象。内存池采用双环形缓冲区来管理网络报文的生命处理周期,当一个网络报文被网卡接收后,DPDK 在 Mbuf 的环形缓冲中创建一个 Mbuf 对象。对网络报文的所有操作都集中在 Mbuf 对象中,仅在必要时对实际网络报文进行访问。也就是说,内核空间和用户空间的内存交互不进行拷贝,只做控制权转移。
2、DPDK 启动设置
环境监测
# 1、查询网卡信息,并检查是否能 ping 通
# 2、查看系统是否支持多队列网卡
cat /proc/interrupts | grep eth0
dpdk 启动设置
# 1、设置 dpdk 环境变量
export RTE_SDK=/home/king/share/dpdk/dpdk-stable-19.08.2
export RTE_TARGET=x86_64-native-linux-gcc
# 2、执行usertools的启动设置
./usertools/dpdk-setup.sh
# 选择 43,Insert IGB UIO module,选择网卡为 vmxnet3 会加载此模块
# 选择 44,Insert VFIO module,选择网卡为 e1000 会加载此模块
# 选择 45,Insert KNI module,写回内核
# 选择 46,Setup hugepage,512
# 选择 47,Setup hugepage,512
# 选择 49,绑定 igb_uio 模块
# 1、先宕掉 eth0 网卡
sudo ifconfig eth0 down
# 2、绑定 pci

3、DPDK:UDP 协议栈
这里实现一个简单的 udp 协议栈,对网卡传递来的 udp 数据包做 echo 处理。
3.1、代码实现
dpdk 环境初始化
int main(int argc, char *argv[]) {
// 1、eal 初始化
if (rte_eal_init(argc, argv) < 0) {
rte_exit(EXIT_FAILURE, "Error\n");
}
// 2、创建 mbuf 内存池
// 内存池分配 MBUF_NUMBER 个 mbuf,mbuf 大小默认固定为 2048(data_room_size指定),牺牲内存空间提高吞吐量
struct rte_mempool *mbuf_pool = rte_pktmbuf_pool_create("mbufpool", MBUF_NUMBER, 0, 0, RTE_MBUF_DEFAULT_BUF_SIZE, rte_socket_id());
if (!mbuf_pool) {
rte_exit(EXIT_FAILURE, "mbuf Error\n");
}
// 3、配置网卡设备
// 设置接收和发送队列数量
uint16_t nb_rx_queues = 1;
uint16_t nb_tx_queues = 1;
// 创建网卡配置文件
const struct rte_eth_conf port_conf_default = {
.rxmode = {.max_rx_pkt_len = RTE_ETHER_MAX_LEN }
};
// 配置网卡设备
rte_eth_dev_configure(gDpdkPortId, nb_rx_queues, nb_tx_queues, &port_conf_default);
// 创建网卡接收队列
rte_eth_rx_queue_setup(gDpdkPortId, 0, 128, rte_eth_dev_socket_id(gDpdkPortId), NULL, mbuf_pool);
// 创建网卡发送队列
rte_eth_tx_queue_setup(gDpdkPortId, 0, 1024, rte_eth_dev_socket_id(gDpdkPortId), NULL);
// 启动网卡设备
rte_eth_dev_start(gDpdkPortId);
...
}
封装 udp 数据包
static struct rte_mbuf *alloc_udp_pkt(struct rte_mempool *pool, uint8_t *data, uint16_t length) {
// 内存池分配一块固定大小的 mbuf,2048
struct rte_mbuf *mbuf = rte_pktmbuf_alloc(pool);
if (!mbuf) {
rte_exit(EXIT_FAILURE, "rte_pktmbuf_alloc error\n");
}
// mbuf 包的长度:udp 包的长度 + ip 首部 + 以太网帧首部
mbuf->pkt_len = length + sizeof(struct rte_ipv4_hdr) + sizeof(struct rte_ether_hdr);
// mbuf 包的数据长度
mbuf->data_len = length + sizeof(struct rte_ipv4_hdr) + sizeof(struct rte_ether_hdr);
uint8_t *msg = rte_pktmbuf_mtod(mbuf, uint8_t*);
// ether_hdr
struct rte_ether_hdr *eth = (struct rte_ether_hdr *)msg;
rte_memcpy(eth->s_addr.addr_bytes, gSrcMac, RTE_ETHER_ADDR_LEN);
rte_memcpy(eth->d_addr.addr_bytes, gDstMac, RTE_ETHER_ADDR_LEN);
eth->ether_type = htons(RTE_ETHER_TYPE_IPV4);
// iphdr
struct rte_ipv4_hdr *ip = (struct rte_ipv4_hdr *)(msg + sizeof(struct rte_ether_hdr));
ip->version_ihl = 0x45;
ip->type_of_service = 0;
ip->total_length = htons(length + sizeof(struct rte_ipv4_hdr));
ip->packet_id = 0;
ip->fragment_offset = 0;
ip->time_to_live = 64;
ip->next_proto_id = IPPROTO_UDP;
ip->src_addr = gSrcIp;
ip->dst_addr = gDstIp;
ip->hdr_checksum = 0;
ip->hdr_checksum = rte_ipv4_cksum(ip);
// udphdr
struct rte_udp_hdr *udp = (struct rte_udp_hdr *)(msg + sizeof(struct rte_ether_hdr) + sizeof(struct rte_ipv4_hdr));
udp->src_port = gSrcPort;
udp->dst_port = gDstPort;
udp->dgram_len = htons(length);
rte_memcpy((uint8_t*)(udp+1), data, length-sizeof(struct rte_udp_hdr));
udp->dgram_cksum = 0;
udp->dgram_cksum = rte_ipv4_udptcp_cksum(ip, udp);
return mbuf;
}
从以太网 uio 网卡接收 udp 数据包,并转发回去。dpdk 的接收发送数据操作 burst 是内存操作,不存在 io 的阻塞问题。
int main(int argc, char *argv[]) {
...
// 业务逻辑:echo udp 数据包
while (1) {
unsigned num_recvd = 0;
unsigned i = 0;
// 逻辑 2:从以太网网卡读取数据,若是 udp 数据,则执行 echo 操作
// 使用 mbuf 操作
struct rte_mbuf *mbufs[MBUF_SIZE];
// 从网卡接收队列接收数据:直接操作内存
num_recvd = rte_eth_rx_burst(gDpdkPortId, 0, mbufs, MBUF_SIZE);
if (num_recvd > MBUF_SIZE) {
rte_exit(EXIT_FAILURE, "rte_eth_rx_burst Error\n");
}
for (i = 0; i < num_recvd; i++) {
// 取出以太网帧头(返回 mbuf 结构体)
struct rte_ether_hdr *ehdr = rte_pktmbuf_mtod(mbufs[i], struct rte_ether_hdr *);
// 非 ip 数据包,丢弃处理
if (ehdr->ether_type != rte_cpu_to_be_16(RTE_ETHER_TYPE_IPV4)) {
continue;
}
// 取出 ip 首部(返回 mbuf 结构体偏移位置)
struct rte_ipv4_hdr *iphdr = rte_pktmbuf_mtod_offset(mbufs[i], struct rte_ipv4_hdr *, sizeof(struct rte_ether_hdr));
if (iphdr->next_proto_id == IPPROTO_UDP) {
// 返回 udp 首部(iphdr + 1,偏移一个 ip 首部,即返回 udp 首部)
struct rte_udp_hdr* udphdr = (struct rte_udp_hdr*)(iphdr + 1);
// 返回 udp 包的长度,避免长度为 0
uint16_t length = ntohs(udphdr->dgram_len);
*((char*) udphdr + length) = '\0';
// 打印数据包的源 ip 和目的 ip
struct in_addr addr;
addr.s_addr = iphdr->src_addr;
printf("src: %s:%d, ", inet_ntoa(addr), ntohs(udphdr->src_port));
addr.s_addr = iphdr->dst_addr;
printf("dst: %s:%d, %s\n", inet_ntoa(addr), ntohs(udphdr->dst_port), (char *)(udphdr + 1));
// 转发 udp 数据包,实现 echo
rte_memcpy(gSrcMac, ehdr->d_addr.addr_bytes, RTE_ETHER_ADDR_LEN);
rte_memcpy(gDstMac, ehdr->s_addr.addr_bytes, RTE_ETHER_ADDR_LEN);
rte_memcpy(&gSrcIp, &iphdr->dst_addr, sizeof(uint32_t));
rte_memcpy(&gDstIp, &iphdr->src_addr, sizeof(uint32_t));
rte_memcpy(&gSrcPort, &udphdr->dst_port, sizeof(uint16_t));
rte_memcpy(&gDstPort, &udphdr->src_port, sizeof(uint16_t));
// 封装 udp 数据包,udphdr+1 返回 udp 数据包的数据
struct rte_mbuf *mbuf = alloc_udp_pkt(mbuf_pool, (uint8_t*)(udphdr + 1), length);
// 发送 mbuf 数据
rte_eth_tx_burst(gDpdkPortId, 0, &mbuf, 1);
}
}
}
}
在测试 udp echo 时,由于自定义的协议栈没有实现 arp 协议的处理方法,需要对网卡设置静态 arp,才能进行 echo 测试。
3.2、设置静态 arp
# 以管理员的身份运行cmd
# 1、寻找要绑定主机的 ip 和 mac
arp -a
# 2、查看要进行 arp 绑定的网卡 idx 编号
netsh i i show in
# 3、arp 绑定:netsh -c i i add neighbors idx IP MAC
netsh -c i i add neighbors 10 192.168.0.104 00-0c-29-18-ef-9d
# arp 解除绑定:netsh -c i i delete neighbors idx
netsh -c i i delete neighbors 10
查看要进行 arp 绑定的网卡编号的方法如下:

若代码中实现 KNI,则无需配置静态 arp。
4、DPDK:KNI
在 udp 协议栈的基础上实现功能,其他类型数据包通过 KNI(内核网卡接口,Kernel NIC Interface)交给内核协议栈进行处理,并将内核协议栈处理后的结果返回给以太网网卡,发送出去。

这里存在两条数据流向
- 从以太网网卡读取数据,若是 udp 数据,则执行 echo 操作;否则,转发到内核协议栈处理
- 从内核协议栈读取数据,转发到以太网网卡接口,发送数据
4.1、代码实现
// 网卡配置接口
static int g_config_network_if(uint16_t port_id, uint8_t if_up) {
if (!rte_eth_dev_is_valid_port(port_id)) {
return -EINVAL;
}
int ret = 0;
if (if_up) {
rte_eth_dev_stop(port_id);
ret = rte_eth_dev_start(port_id);
}
else {
rte_eth_dev_stop(port_id);
}
if (ret < 0) {
printf("Failed to start port : %d\n", port_id);
}
return 0;
}
int main(int argc, char *argv[]) {
...
// 初始化 kni
if (rte_kni_init(gDpdkPortId) == -1) {
rte_exit(EXIT_FAILURE, "kni init failed\n");
}
// 定义 kni 配置
struct rte_kni_conf conf;
memset(&conf, 0, sizeof(conf));
// 定义 kni 网卡名字,通过 ifconfig -a 命令查看
snprintf(conf.name, RTE_KNI_NAMESIZE, "vEth%d", gDpdkPortId);
conf.group_id = gDpdkPortId;
conf.mbuf_size = RTE_MBUF_DEFAULT_BUF_SIZE;
// 获取以太网网卡 mac 地址
rte_eth_macaddr_get(gDpdkPortId, (struct rte_ether_addr*)conf.mac_addr);
// 获取以太网 mtu
rte_eth_dev_get_mtu(gDpdkPortId, &conf.mtu);
// 定义 kni 操作
struct rte_kni_ops ops;
memset(&ops, 0, sizeof(ops));
ops.port_id = gDpdkPortId;
ops.config_network_if = g_config_network_if;
// 创建 kni 网卡接口,通过 mmap 映射到内存
global_kni = rte_kni_alloc(mbuf_pool, &conf, &ops);
...
// 业务逻辑:接收发送数据
while (1) {
// 逻辑 1:从内核协议栈读取数据,转发到以太网网卡接口,发送数据
struct rte_mbuf *kni_burst[MBUF_SIZE];
// 读取 kni 返回的内核协议栈读取的数据
num_recvd = rte_kni_rx_burst(global_kni, kni_burst, MBUF_SIZE);
if (num_recvd > MBUF_SIZE) {
rte_exit(EXIT_FAILURE, "rte_kni_rx_burst Error\n");
}
// 向以太网网卡发送读取到的 kni 的数据
unsigned nb_tx = rte_eth_tx_burst(gDpdkPortId, 0, kni_burst, num_recvd);
// 未处理完的数据包的处理方式,可以再次转发,这里选择直接丢弃
if (nb_tx < num_recvd) {
// 将未转发的数据包释放掉
for (i = nb_tx; i < num_recvd; i++) {
rte_pktmbuf_free(kni_burst[i]);
kni_burst[i] = NULL;
}
}
...
// 逻辑2:从以太网网卡读取数据,判断数据类型
// 若是 udp 数据,则执行 echo 操作;否则,转发到内核协议栈处理
for (i = 0;i < num_recvd;i ++) {
...
// 其他类型的数据发送到 kni,交由内核协议栈处理(向内核写数据)
else {
rte_kni_tx_burst(global_kni, &mbufs[i], 1);
}
}
// 处理 kni 请求
rte_kni_handle_request(global_kni);
}
}
4.2、程序测试
首先,为保证 kni 可以运行,需要开启向内核写入数据
echo 1 > /sys/devices/virtual/net/lo/carrier
为避免干扰,解除静态 arp 绑定
netsh -c i i delete neighbors 10
启动程序,ifconfig -a 可以查看 kni 网卡信息,名字为 vEth0
vEth0 Link encap:Ethernet HWaddr 00:0c:29:18:ef:9d
BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:2 errors:0 dropped:2 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:120 (120.0 B) TX bytes:0 (0.0 B)
为 vEth0 配置 ip 地址
ifconfig vEth0 192.168.0.105 up
捕获发送到 vEth0 (内核协议栈)的数据
tshark -i vEth0 icmp
远端执行 ping 命令,捕获到 kni 的 icmp 数据包,说明其他协议成功交给内核处理,并返回。
192.168.0.106 → 192.168.0.105 ICMP 74 Echo (ping) request id=0x0001, seq=23/5888, ttl=64
192.168.0.105 → 192.168.0.106 ICMP 74 Echo (ping) reply id=0x0001, seq=23/5888, ttl=64 (request in 57)