本文重点
我们分析机器学习算法都是从损失函数的角度来说的,为了找到最佳的参数θ,可以最小化损失函数,那么本节课程我们将学习基于内容的推荐系统的损失函数是什么?
数据集
我们将每一个电影称为样本,每个电影有两个特征x1、x2,其中x1表示该电影为恐怖片的程度,x2表示该电影为武打类的程度,那么我们的数据集样本如下所示:
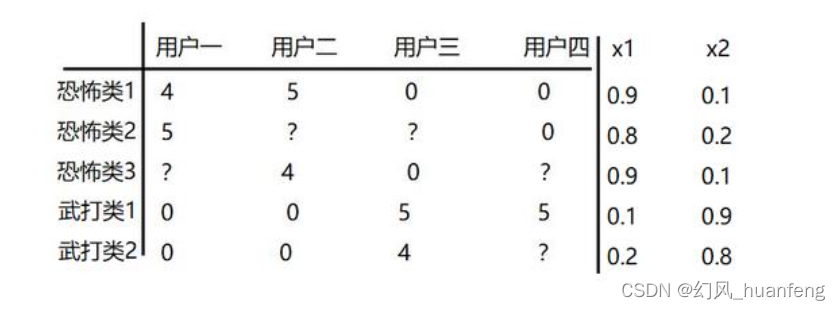
现在我们给每一个样本增加一个特征变量x0=1,这样恐怖类1这部电影的特征向量为:

预测
现在我们已经有了样本的特征,现在我们将每位用户对电影的评分当作样本的标签。具体来说就是:对于每位用户j,我们都学习出一个参数θ(j)∈R³,然后我们就可以根据参数θ和特征x(i)的内积来预测用户j对电影i的评分。

以前的线性回归的问题是建立一个回归模型,现在不是了,现在是为每一个用户建立一个回归模型,每一个用户j都有属于自己兴趣偏向的参数θ(j)。
假如学习到用户j参数θ







![[JavaEE]synchronized 与 死锁](https://img-blog.csdnimg.cn/b41fb650558246dc9cb065605700e4d2.png)