数据库管理 2023-01-08
- 第五十一期 新年新气象
- 1 新年快乐
- 2 旧账
- 3 软硬件对比
- 4 新气象
- 总结
第五十一期 新年新气象
1 新年快乐
2023年来了,我也没有第一时间写一篇写文章给大家祝福,第一呢是因为某些原因元旦假期也没咋休息,其次就是因为本周又做了一次割接,后面细讲。所以在2023年第一周的最后一天给大家说一声新年快乐。
其次呢,当天写好了这篇文章,存了草稿,送快递无法自拔,直接关机忘记发布了。。。
2 旧账
其实这个迁移本应去年12月份完成测试并迁移的,一个省级一线系统,11204双节点RAC无任何补丁,因为众所周知的原因延后迁移了。主要表象就是业务高发期的时候,数据库服务器的CPU占用率总会达到100%,造成数据库几乎处于卡死状态,业务无法正常运行。由于这个原来的数据库环境我并没有直接接手,也没有数据库级别监控,因此只能通过AWR、ASH、ADDM等对数据库进行排查并紧急处理一些问题:
-
内存分配不合理及IO等待较高

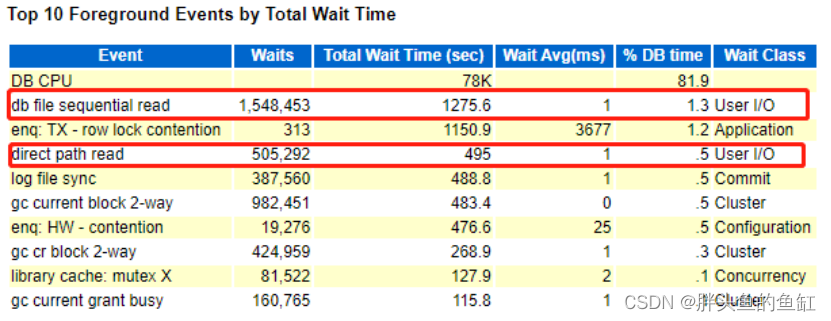
数据库服务器内存为512G,数据库使用仅占用13%左右,未充分利用服务器内存资源,会造成数据内存缓存数据量较小,需要频繁的存储与内存数据交互,增加数据库IO压力,进而引起一系列其他问题。将AMM内存设置调整到400GB,相关IO等待消除。 -
序列cache不合理
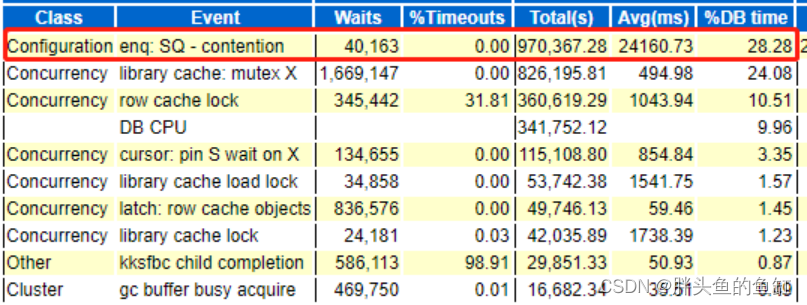
处理完第一个问题后,经过排查发现业务所使用的部分cache值仅为为20,在业务高发期需要频繁生产序列并加载到内存,不足以满足业务响应要求。将对应序列cache调整至3000以上,相关等待消除。 -
异常library cache: mutex X等待
其实上面排在第二的library cache: mutex X等待也不低,在处理完序列之后,这个等待就几乎变成了数据库的主要等待事件了:

由于时间仓促,暂未发现造成该问题的原因,与Oracle原厂沟通,考虑到数据库为应用任何补丁,可能为数据库BUG引起性能故障。
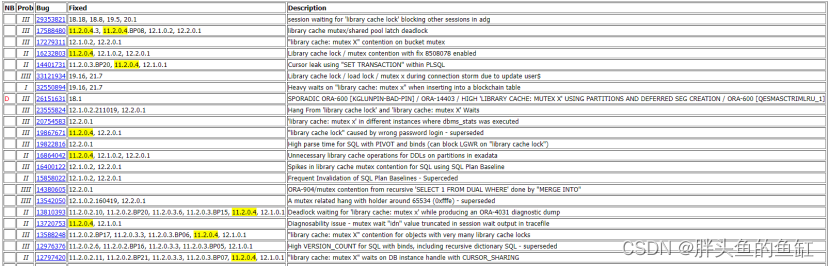
library cache: mutex X的相关MOS,这里也附上相关DOC信息:Troubleshooting ‘library cache: mutex X’ Waits. (Doc ID 1357946.1),还有一个翻译后中文的:诊断 ’library cache: mutex X’ 等待 (Doc ID 2331144.1)。有兴趣可以看看,主要还是有些版本问题。 -
部分表、SQL设计不合理
部分大表未进行分区操作,会造成不必要IO消耗,同时增大数据清理难度
部分表约束不合理,影响数据维护效率
部分SQL语句未限制返回列数量,会增加不必要的网络消耗
部分SQL语句使用全模糊查询、空值匹配,会造成无法利用索引的问题
等,反馈业务开发,根据业务逻辑进行紧急调整,无法紧急调整的排期处理,已解决部分相关问题。
经过相关紧急优化,数据库依然无法支撑业务。在省公司领导的要求下,紧急向新建环境进行迁移。迁移流程和第四十期的一体机迁移方式一样,只不过这次不是一体机,而是新建的X86集群。
3 软硬件对比
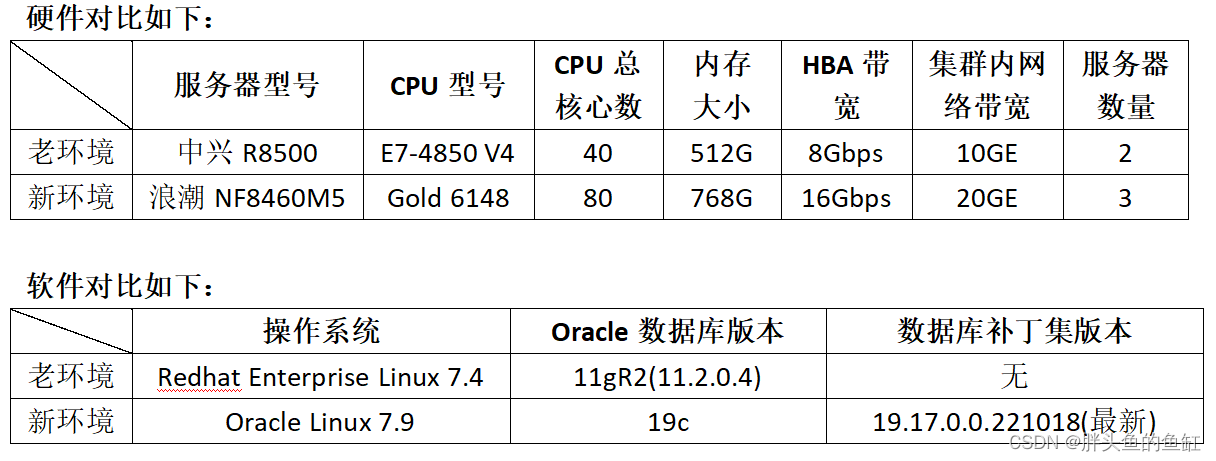
这里业务方其实有个疑惑,原来的硬件是否给的太差了,其实对比我之前的那套四节点X86环境,CPU是E5 V3的,核心数一样,承载的业务比整业务大一倍左右,一样能跑得很好,由于没有最终后台排查(有时间不够也有11g不支持的原因),所以个人认为BUG或者某些没有排查到的不合理设置引起性能问题的原因较大。
4 新气象
这个业务在迁移之前,一线反馈的含妈量是巨高的,然而迁移过后的反馈是完全不卡了,是处于惊呆的状态,那么迁移后是什么样的呢?
- CPU与内存
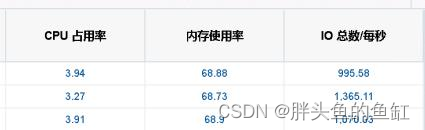
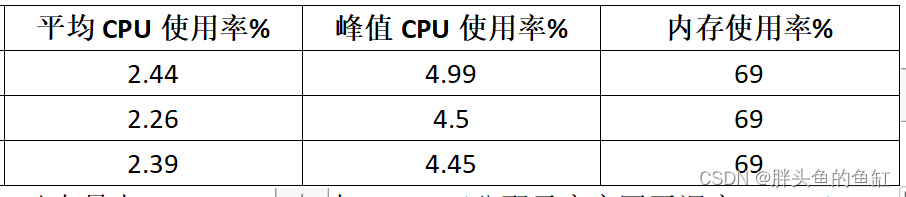
这里CPU几乎就没怎么用,内存也是ASMM直接占用。SGA分配给这个业务是350GB。
-
IO
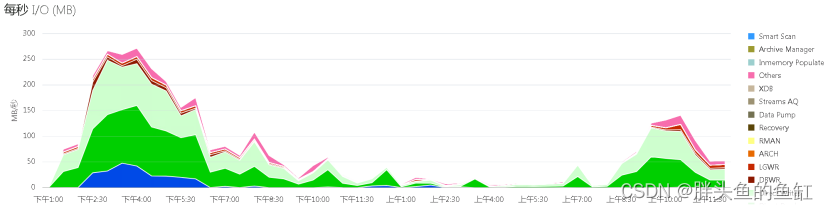
IOMBPS(MB/s)最大约为275,平均约为100
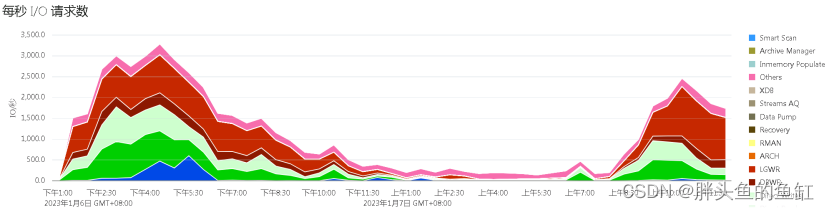
IOPS(每秒IO请求次数)最大约为3750,平均约为1500 -
TPS每秒事务处理量

TPS(每秒事务处理量)最大约为420
从基本性能来看,数据库的运行是十分顺畅的,由于CPU使用率一直未超过5%,让客户感到了震惊。
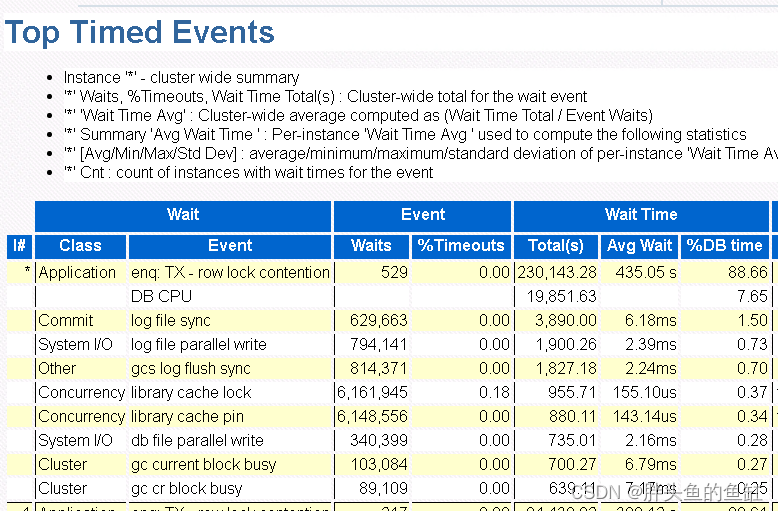
从AWR来看除了第一条因为数据调整引起的行锁,其余等待均未造成大量性能损耗。当然业务侧还是有很多需要优化的地方,现在新的数据库有EM统一全面的监控,也能更好的去发现、排查问题。
后续这套集群还会迁移上一些其他业务,之前为了保障这个重要业务迁移,资源给的比较多,从目前的实际监控来看并没有完全使用,因此可能会向下进行动态调整。
总结
本次迁移,总结起来还是很成功的,解决了实际问题,提升了我们客户在他们客户前的满意度,也提升了我们在客户面前的满意度。
老规矩,2023年的第一篇,知道写了些啥。