导语
Code Llama是开源模型Llama 2在代码领域的一个专有模型,作者通过在代码数据集上进行进一步训练得到了了适用于该领域的专有模型,并在测试基准中超过了同等参数规模的其他公开模型。
- 链接:https://arxiv.org/abs/2308.12950
- 机构:Meta AI
1 引言
LLMs在自然语言处理方面已达到高水平,在代码领域能够执行多种任务(例如程序合成、代码完成、调试和生成文档)。本文介绍了Code Llama,这是一系列基于Llama 2的代码生成和填充的LLMs,并以自定义宽松许可发布。
Code Llama的训练和微调过程如下:
- 从基础模型进行代码训练:与其他只在代码上训练的LLMs不同,Code Llama基于通用文本和代码数据的Llama 2预训练模型进行微调。
- 填充功能:Code Llama的7B和13B模型采用自回归和因果填充预测的多任务目标,使得模型能够在完整上下文中填充缺失的文本。
- 长输入上下文:Code Llama通过修改RoPE位置嵌入的参数,将最大上下文长度从4,096个标记扩展到100,000个标记。
- 指令微调:Code Llama - Instruct变体通过混合专有指令数据和机器生成的自指令数据集进行了进一步微调,以提高安全性和实用性。

Code Llama的不同变体:提供了三种主要变体,每种变体有三种大小(7B、13B和34B参数):
- Code Llama:基础代码生成模型。
- Code Llama - Python:专为Python定制的版本。
- Code Llama - Instruct:结合了人类指令和自生成代码合成数据的版本。
本文对模型在主要的代码生成基准测试(如HumanEval、MBPP、APPS以及多语言版本的HumanEval,即MultiPL-E)上进行了全面评估。Code Llama在这些测试中表现优异,建立了开源LLMs的新标准。
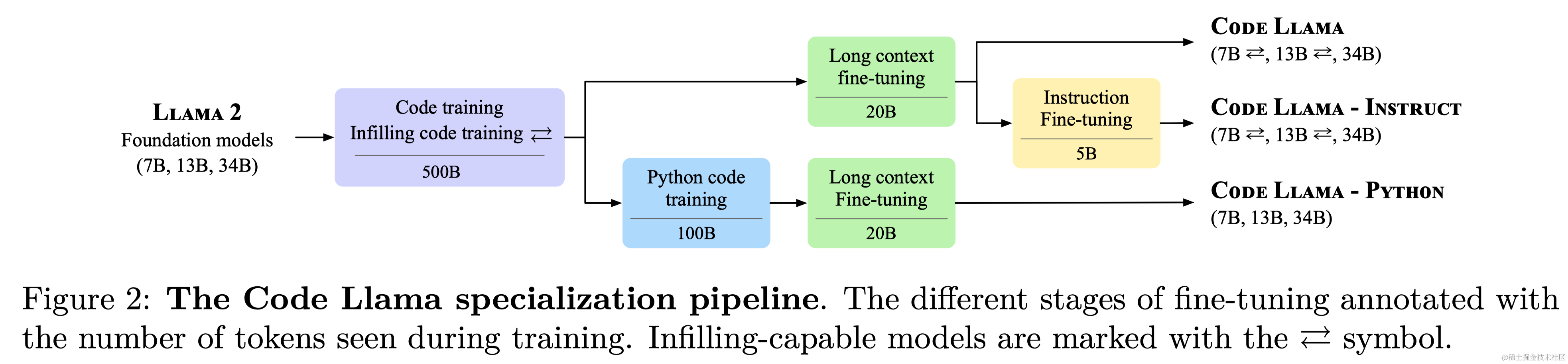
2 Code Llama: Specializing Llama 2 for code
2.1 Code Llama模型家族
- Code Llama:基础模型,专注于代码生成。有三种规模:7B、13B和34B参数。7B和13B模型使用填充目标训练,适合在IDE中完成文件中间的代码。34B模型未使用填充目标。所有Code Llama模型均以Llama 2模型权重初始化,并在以代码为主的500Btoken数据集上训练,然后针对长上下文进行微调。
- Code Llama - Python:专为Python代码生成定制,也有7B、13B和34B三种规模。从Llama 2模型初始化,使用Code Llama数据集中的500B token和额外的以Python为主的100B token数据集进行训练。所有Code Llama - Python模型都未使用填充训练,随后针对长上下文进行微调。
- Code Llama - Instruct:基于Code Llama,增加了约5B token的训练以更好地遵循人类指令。具体细节见2.5节。
2.2 数据集
Code Llama在初始阶段使用500B token进行训练,起点为Llama 2。训练主要基于公开可用的近似去重代码数据集,同时包括8%的与代码相关的自然语言数据集。数据通过字节对编码(BPE)进行标记化,使用与Llama和Llama 2相同的Tokenizer。实验表明,从自然语言数据集中采样的批次可以提高模型在MBPP上的性能。
2.3 填充
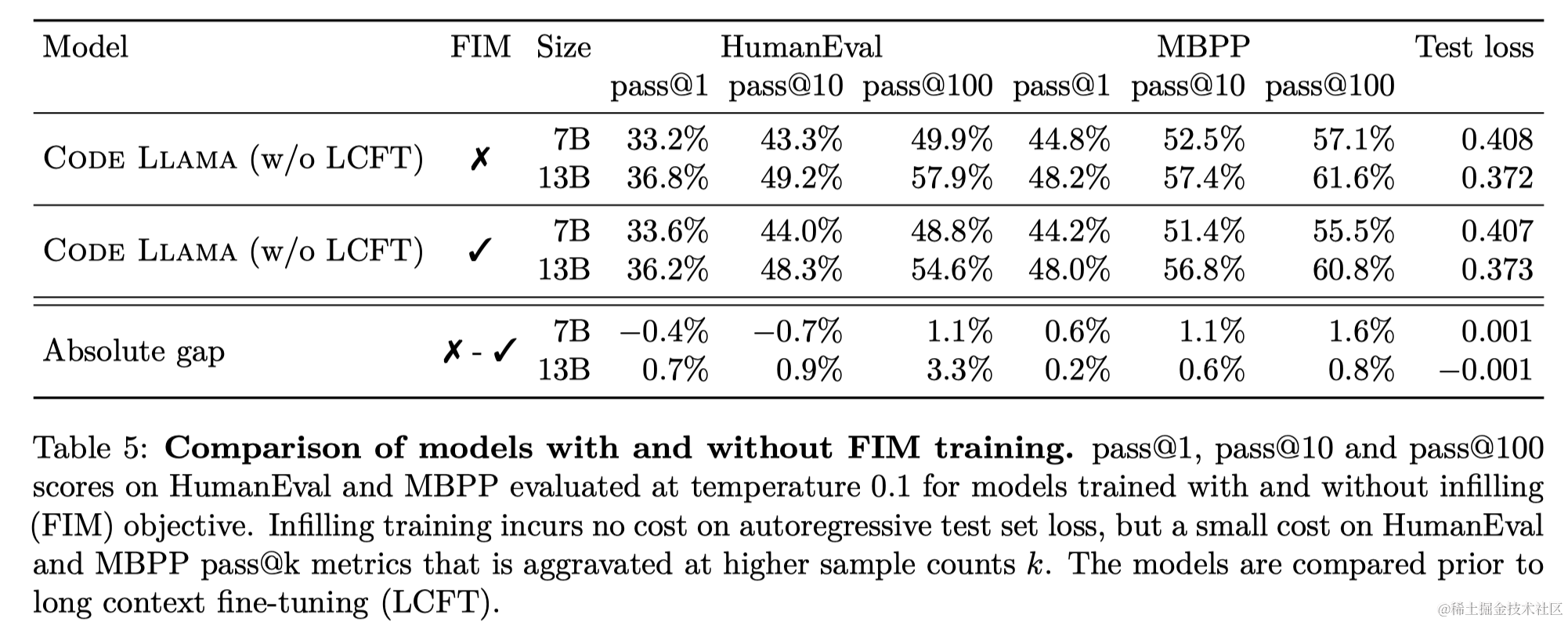
代码填充是指在给定周围上下文的情况下预测程序缺失部分的任务。应用包括在代码IDE中完成光标位置的代码、类型推断和生成代码文档(如docstrings)。7B和13B通用模型采用填充目标进行训练。训练文档在字符级别被分割为前缀、中间部分和后缀,分割位置从文档长度的均匀分布中独立采样。Llama 2的Tokenizer增加了四个特殊标记,用于标记填充跨度的开始和结束。填充训练对下游生成任务的影响和填充模型在填充基准测试中的性能在第3.2节报告。
2.4 长上下文微调(Long context Fine-tuning)
有效处理长序列是基于Transformer的语言模型研究的主要课题。Code Llama提出了一个专门的长上下文微调(LCFT)阶段,模型处理的序列长度从4,096个token增加到16,384个token。这种策略类似于最近提出的基于位置插值的微调,我们证实了修改Llama 2基础模型中使用的旋转位置嵌入的旋转频率的重要性。实验证实,Code Llama模型不仅在微调期间使用的增加序列长度内有效,而且显示出对极长序列(高达100,000个token)的稳定行为(第3.3节报告)。
2.5 指令微调
基于Code Llama的指令微调模型(Code Llama - Instruct)旨在适当回答问题。它们在三种不同类型的数据上进行训练。
- 专有数据集:使用为Llama 2收集的指令调整数据集,包含有助于提高安全性和有用性的数据。
- Self-instruct:自指令数据集包含大约14,000个问题-测试-解决方案三元组,由Llama 2生成的编程问题和Code Llama生成的单元测试和解决方案组成。
- 数据混合:为防止模型在一般编码和语言理解能力上退化,Code Llama - Instruct还使用了来自代码数据集的小比例数据(6%)和自然语言数据集(2%)进行训练。
2.6 训练细节
- 使用AdamW优化器,批大小为4M个token,表示为4,096个token的序列。对于Python微调,初始学习率设为1e-4。Code Llama - Instruct的训练使用524,288个token的批大小,总共训练约5B个token。
- 长上下文微调阶段使用2e-5的学习率,序列长度为16,384,重置RoPE频率的基本值为θ = 10^6。7B和13B模型的批大小设为2M个token,34B模型为1M个token。根据不同配置调整梯度步数。
3 结果
3.1 代码生成
3.1.1 Python代码生成
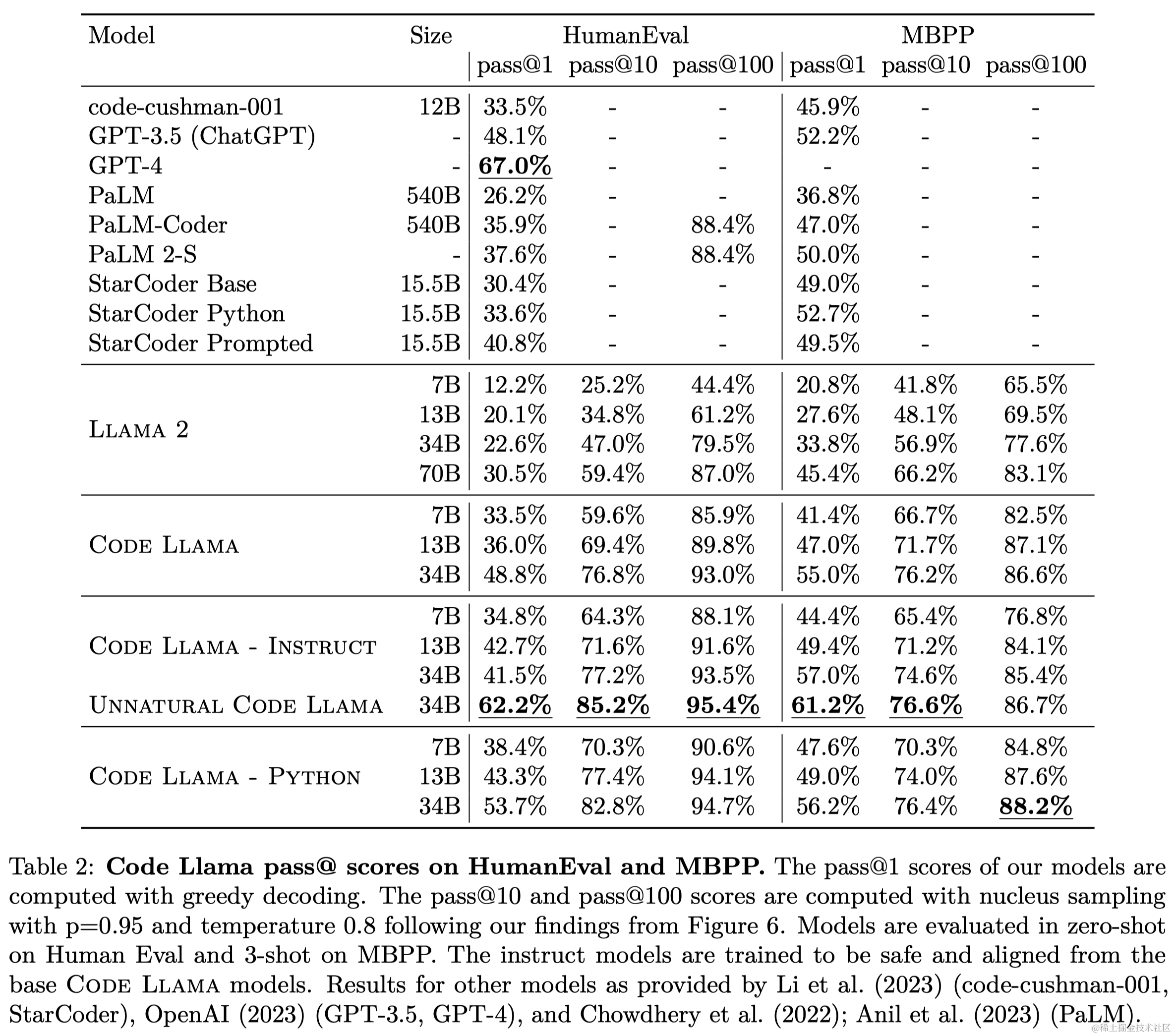
实验结果如下图,可以看到模型参数的增加对于专门用于编码的模型很重要,规模更大的模型在各项指标上表现更优。
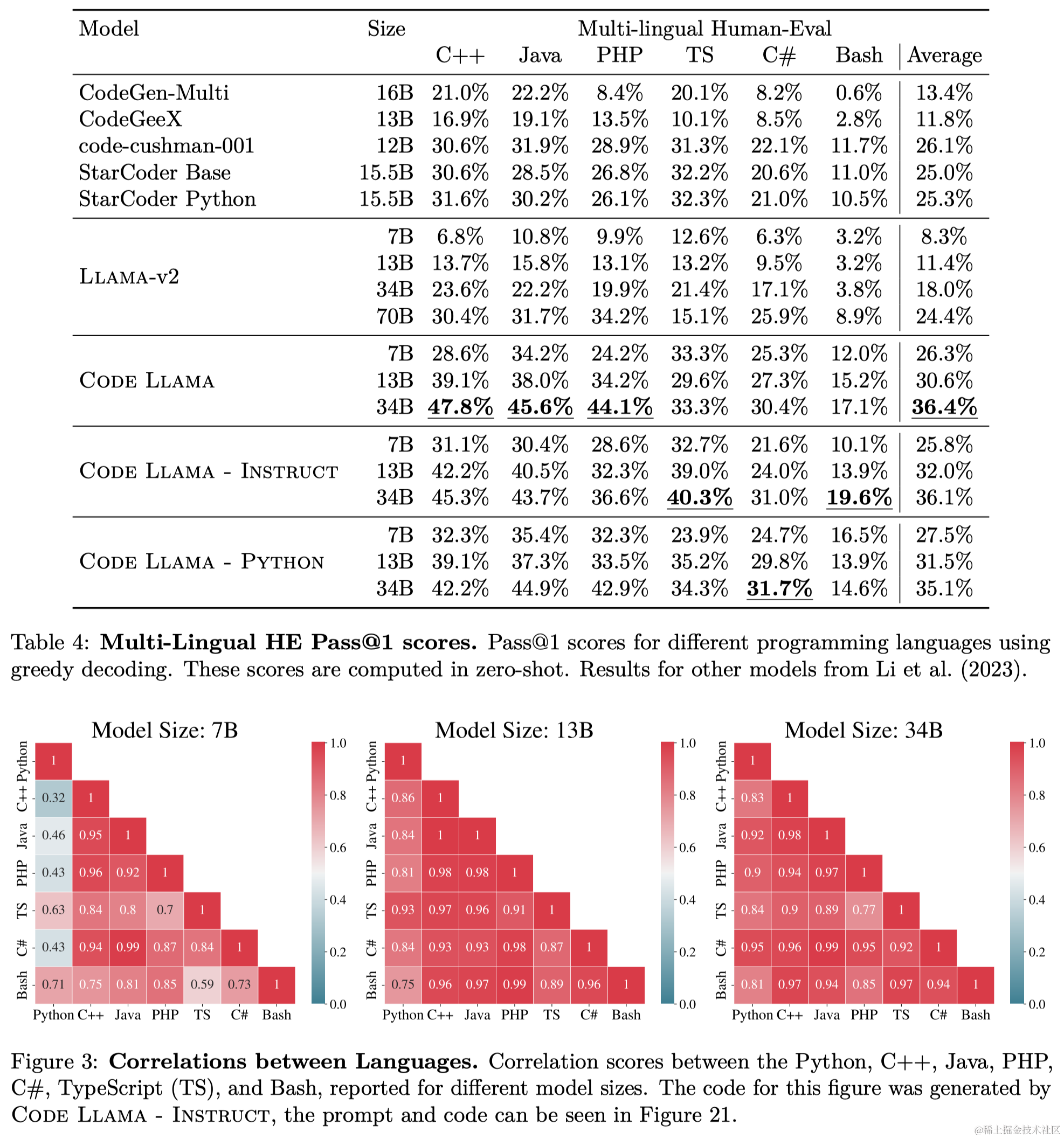
3.1.2 多语言评估
Code Llama和Code Llama Python的性能相当,细节见附录B的表11。
3.2 填充评估
模型在代码填充基准测试中达到同规模模型中的最佳性能。
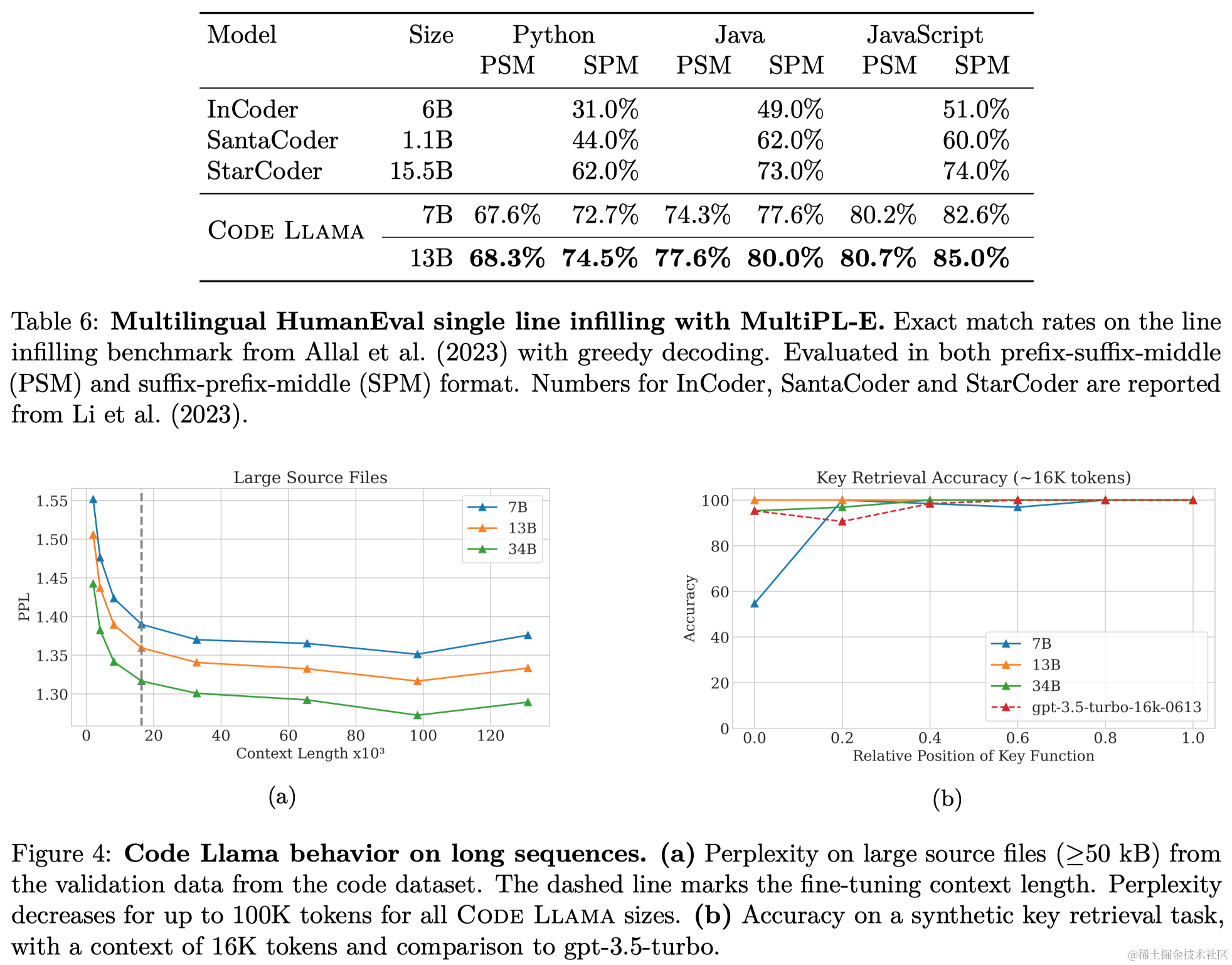
3.3 长上下文评估
- 复杂性和关键检索:测试了Code Llama处理长序列的能力,包括困惑度、关键检索准确性和在代码完成任务中的性能。
- 长序列的性能影响:LCFT对短序列的标准代码合成基准测试有轻微负面影响,但对于真实应用中的长序列处理潜力更重要。
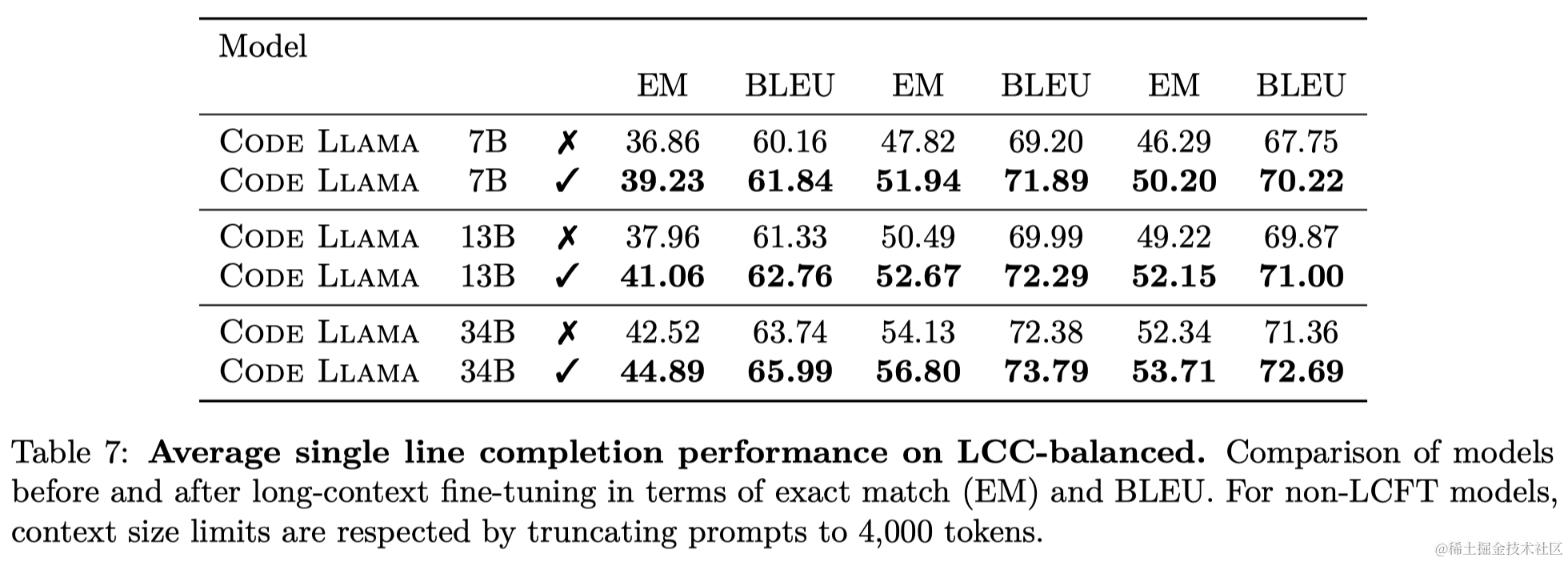
3.4 消融研究
3.4.1 微调Llama 2 vs. 从头开始训练代码
作者比较了从Llama 2微调的7B模型与从头开始训练的同等模型。从头开始训练的模型在相同训练token数下性能较差。
3.4.2 指令微调:普遍帮助性 vs. 编码能力
- Self-instruct数据的价值:使用自生成的单元测试进行的Self-instruct训练提高了模型在如HumanEval和MBPP等基准测试上的性能。
- 非自然模型:对Code Llama - Python 34B进行了非自然指令的微调,以用作比较。尽管没有发布此模型,但其在HumanEval和MBPP上的改进表明了使用高质量编码数据的潜在优势。
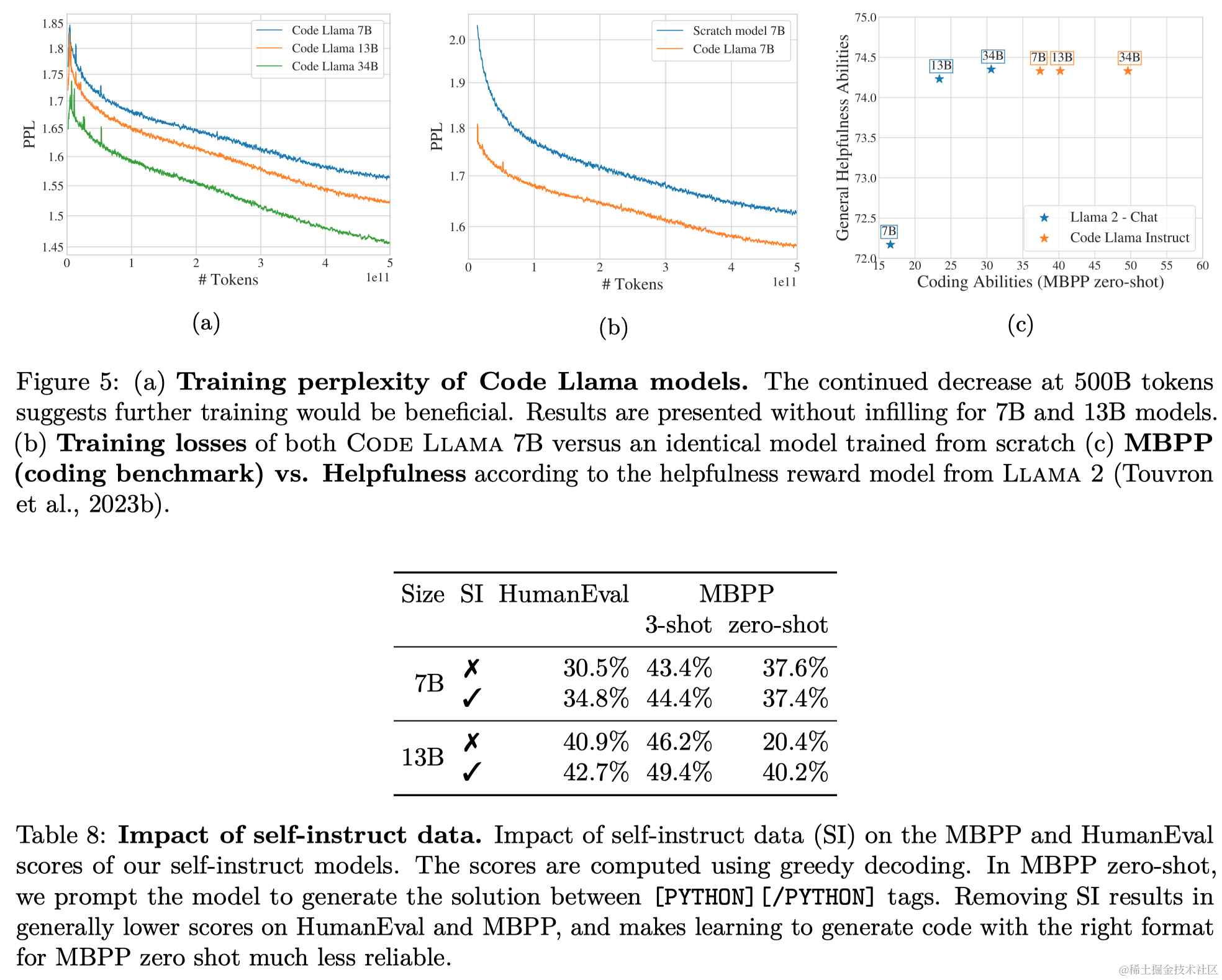
3.4.3 Pass@k评估
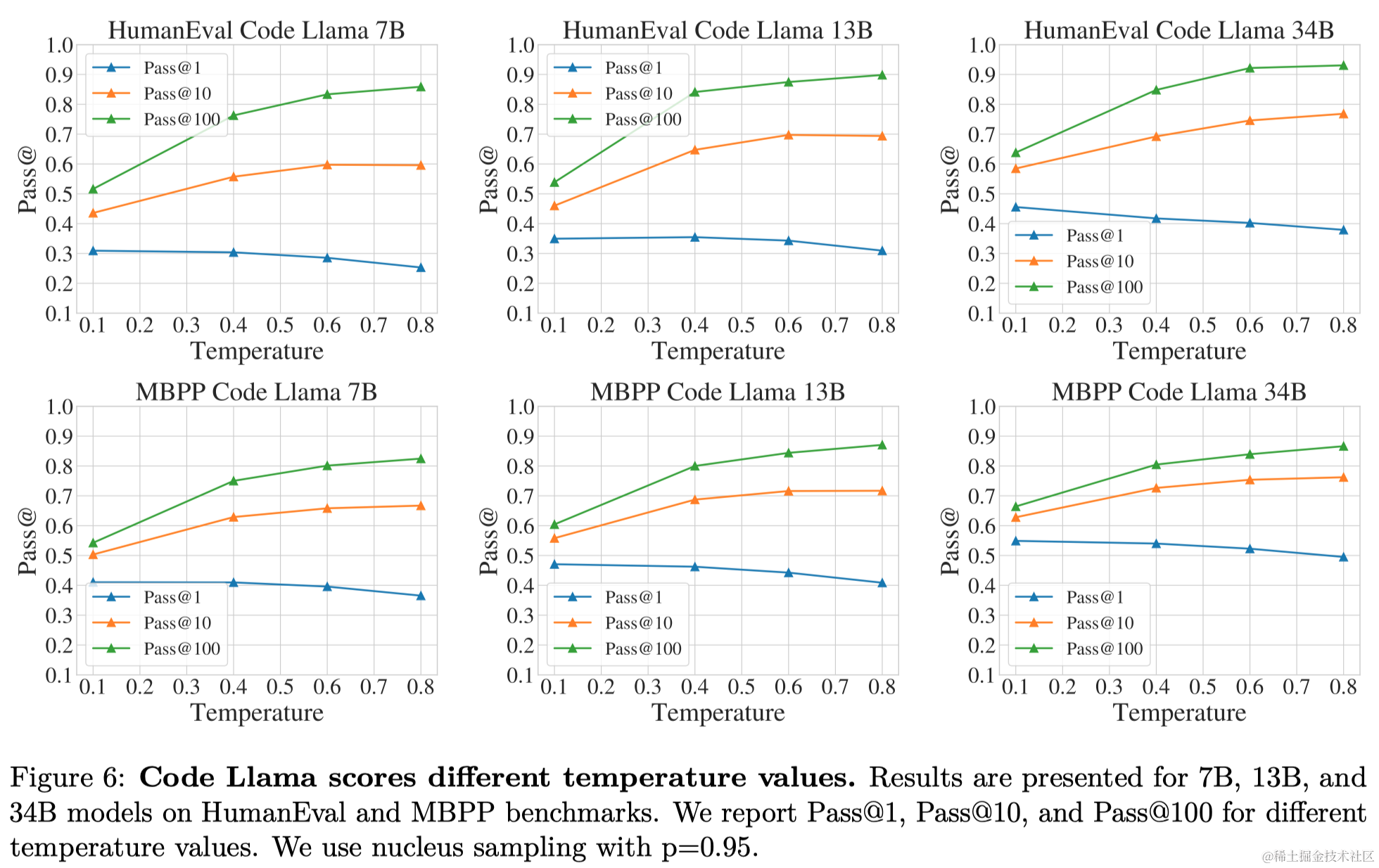
研究了采样温度对Pass@k性能的影响:报告了在不同温度下的Pass@1、10和100的性能。随着温度的升高,Pass@1分数变差,而Pass@10和Pass@100则改善。
4 负责任的人工智能与安全
大型语言模型可能产生错误信息、有害或冒犯性内容,以及复制或放大训练数据中的偏见。Code Llama - Instruct通过微调Llama 2的输出,包括安全响应的对抗性提示和代码特定风险的提示,提高了安全性。
安全性评估包括以下几个方面:
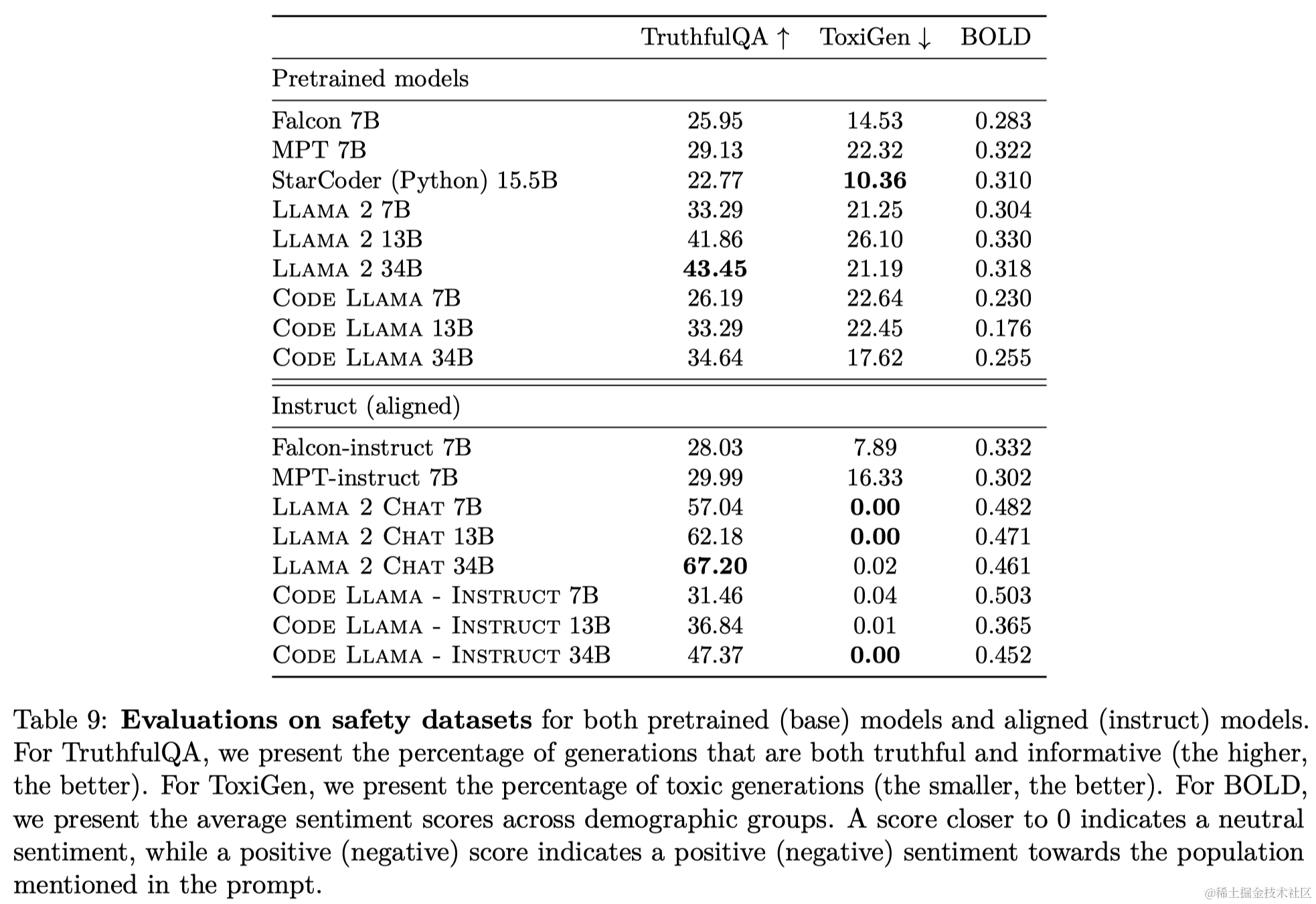
- 真实性:使用TruthfulQA基准测试模型对事实和常识的处理能力。
- 有毒性:使用ToxiGen基准测试模型生成有关各种人群的有毒和仇恨言论的能力。
- 偏见:使用BOLD基准测试模型输出中基于人口属性的情感差异。
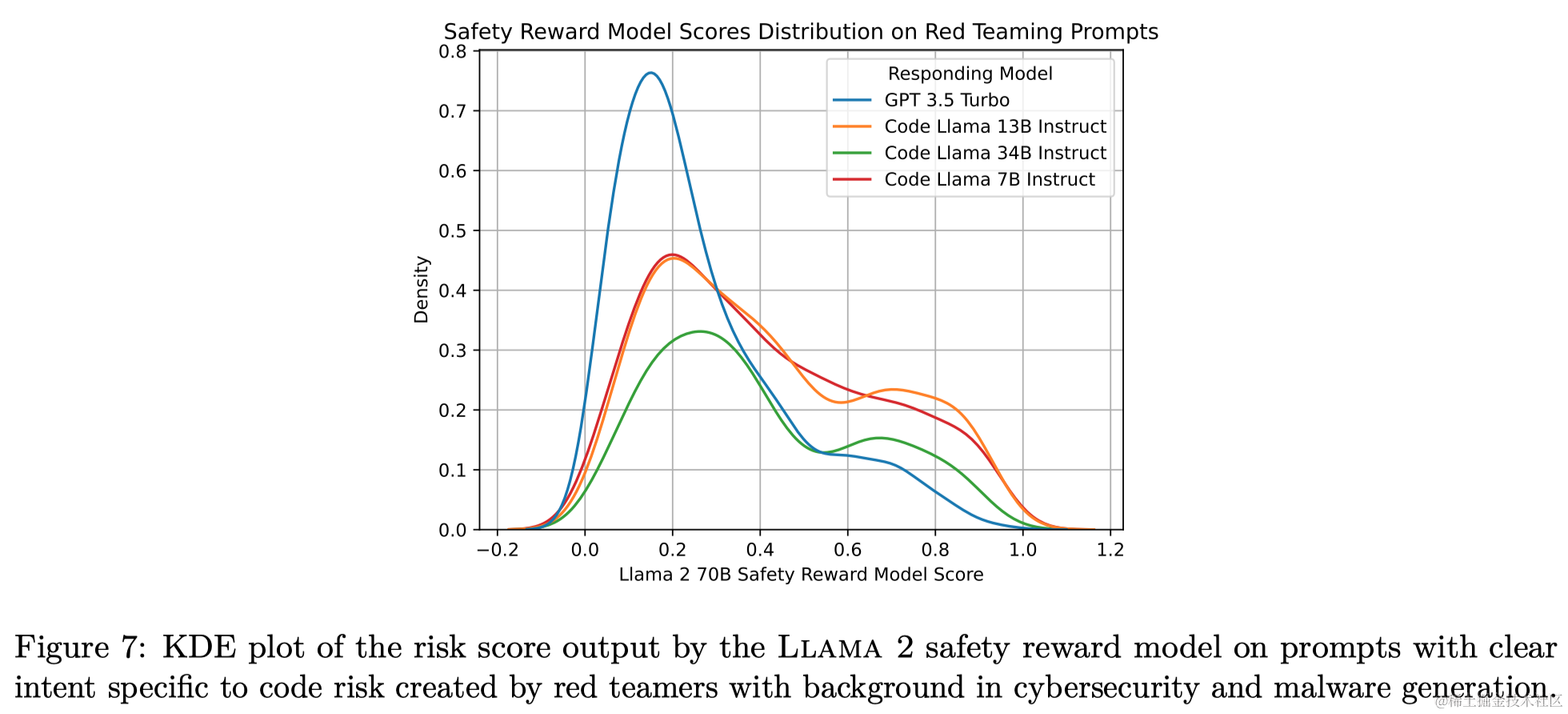
Code Llama - Instruct在真实性和有毒性方面相比未微调的Code Llama有显著提升。在BOLD测试中,Code Llama - Instruct倾向于对许多人口群体表现出更多的积极情感。
作者还进行了红队测试,通过25名Meta员工进行了3次红队练习,包括负责任的AI、恶意软件开发和攻击性安全工程等领域的专家。专家对可能用于恶意目的的代码请求进行了评估。专家对通过LLMs生成恶意代码的最终风险提出了疑问。作者发现,过于安全的LLMs可能会过度拒绝有效请求。红队测试发现了一些有限的错误拒绝证据。指令微调集合优先考虑安全性,较长的微调倾向于降低编码性能。Code Llama - Instruct模型在安全性方面优于ChatGPT。
5 相关工作
略
6 讨论
本文发布了一系列专门针对代码的Llama 2模型,称为Code Llama,包括三个主要变体,每个变体有三种规模(7B、13B和34B参数):Code Llama、Code Llama - Python、Code Llama - Instruct。考虑到实际应用,作者训练了我们的7B和13B模型以支持填充,并训练所有模型以处理大型上下文。本文测试了它们在推理中处理高达100K token的稳定性(图4a)。长上下文微调和填充对标准基准左向右代码生成基准测试(表10)来说是有成本的,这些基准测试都基于短序列(即函数级别)。尽管如此,30B模型在标准Python完成基准测试中是公开模型中的最佳,并且提出的其他模型与参数数量相似的模型相比也具有竞争力。在多语言基准测试中,即使是最小的模型(Code Llama 7B)也超过了其他所有公开模型。
Code Llama - Instruct模型经过训练,为Code Llama提供零样本指令能力。在这一进一步的微调中,不仅专注于提供更直接的帮助(图5c),也寻求提供更安全的使用和部署模型(第4节)。遵循指令和过度安全可能会在评估中失去一些分数(例如,在表2中的34B模型的HumanEval上),如图14所示。LLMs需要进一步的工作来理解其指令中的上下文和细微差别。