文章目录
- 前言
- 一、Group normalization
- 二、批量规范化(Batch Normalization)
- 三、层规范化(Layer Normalization)
前言
批量规范化和层规范化在神经网络中的每个批次或每个层上进行规范化,而GroupNorm将特征分成多个组,并在每个组内进行规范化。这种规范化技术使得每个组内的特征具有相同的均值和方差,从而减少了特征之间的相关性。通常,组的大小是一个超参数,可以手动设置或自动确定。
相对于批量规范化,GroupNorm的一个优势是它对批次大小的依赖性较小。这使得GroupNorm在训练小批量样本或具有不同批次大小的情况下更加稳定。另外,GroupNorm还可以应用于一维、二维和三维的输入,适用于不同类型的神经网络架构。
GroupNorm的一种变体是分组卷积(Group Convolution),它将输入通道分成多个组,并在每个组内进行卷积操作。这种结构可以减少计算量,并提高模型的效率。
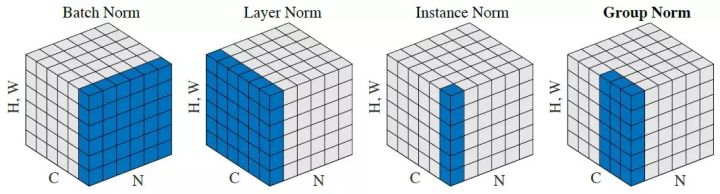
- BatchNorm:batch方向做归一化,算N* H*W的均值
- LayerNorm:channel方向做归一化,算C* H* W的均值
- InstanceNorm:一个channel内做归一化,算H*W的均值
- GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G) * H * W的均值
一、Group normalization
Group normalization(GroupNorm)是深度学习中用于规范化神经网络激活的一种技术。它是一种替代批量规范化(BatchNorm)和层规范化(LayerNorm)等其他规范化技术的方法。
import torch
import torch.nn as nn
class GroupNorm(nn.Module):
def __init__(self, num_groups, num_channels, eps=1e-5):
super(GroupNorm, self).__init__()
self.num_groups = num_groups
self.num_channels = num_channels
self.eps = eps
self.weight = nn.Parameter(torch.ones(1, num_channels, 1, 1))
self.bias = nn.Parameter(torch.zeros(1, num_channels, 1, 1))
def forward(self, x):
batch_size, num_channels, height, width = x.size()
# 将特征重塑成 (batch_size * num_groups, num_channels // num_groups, height, width)
x = x.view(batch_size, self.num_groups, -1, height, width)
# 计算每个组内的均值和方差
mean = x.mean(dim=(2, 3, 4), keepdim=True)
var = x.var(dim=(2, 3, 4), keepdim=True)
# 规范化
x = (x - mean) / torch.sqrt(var + self.eps)
# 重塑特征
x = x.view(batch_size, num_channels, height, width)
# 应用缩放和平移
x = x * self.weight + self.bias
return x
# 使用示例
group_norm = GroupNorm(num_groups=4, num_channels=64)
inputs = torch.randn(32, 64, 32, 32)
outputs = group_norm(inputs)
print(outputs.shape)
二、批量规范化(Batch Normalization)
BatchNorm的基本思想是对每个特征通道在一个小批次(即一个批次中的多个样本)的数据上进行规范化,使得其均值接近于0,方差接近于1。这种规范化可以有助于加速神经网络的训练,并提高模型的泛化能力。
具体而言,对于给定的一个特征通道,BatchNorm的计算过程如下:
- 对于一个小批次中的输入数据,计算该特征通道上的均值和方差。
- 使用计算得到的均值和方差对该特征通道上的数据进行规范化,使得其均值为0,方差为1。
- 对规范化后的数据进行缩放和平移操作,使用可学习的参数进行调整,以恢复模型对数据的表示能力。
通过在训练过程中对每个小批次的数据进行规范化,BatchNorm有助于解决梯度消失和梯度爆炸等问题,从而加速模型的收敛速度。此外,BatchNorm还具有一定的正则化效果,可以减少模型对输入数据的依赖性,增强模型的鲁棒性。
import torch
import torch.nn as nn
# 输入数据形状:(batch_size, num_features)
input_data = torch.randn(32, 64)
# 使用BatchNorm进行批量规范化
batch_norm = nn.BatchNorm1d(64)
output = batch_norm(input_data)
print(output.shape)
三、层规范化(Layer Normalization)
与批量规范化相比,层规范化更适用于对序列数据或小批次样本进行规范化,例如自然语言处理任务中的文本序列。它在每个样本的特征维度上进行规范化,使得每个样本在特征维度上具有相似的分布。
层规范化的计算过程如下:
对于每个样本,计算该样本在特征维度上的均值和方差。
- 使用计算得到的均值和方差对该样本的特征进行规范化,使得其均值为0,方差为1。
- 对规范化后的特征进行缩放和平移操作,使用可学习的参数进行调整,以恢复模型对数据的表示能力。
import torch
import torch.nn as nn
# 输入数据形状:(batch_size, num_features)
input_data = torch.randn(32, 64)
# 使用LayerNorm进行层规范化
layer_norm = nn.LayerNorm(64)
output = layer_norm(input_data)
print(output.shape)