金融业务产品授信准入、交易营销等环节存在广泛的风控诉求,随着业务种类增多,传统的专家规则、评分卡模型难以应付日趋复杂的风控场景。
在传统风控以专家规则系统为主流应用的语境下,规则模型的入参习惯被称为“变量”。基于专家规则的风险评估,存在规则触发阈值难量化的特点,规则命中精准度提升存在瓶颈。
随着机器学习及神经网络算法的技术落地,更多开始采用“特征”来代指供给算法模型的入参。具体来说,“特征”在其产出过程中,作为上游外数接口的出参,在应用端输入过程中,作为下游规则模型的入参。
建设背景
特征变量数据来源包括客户基本信息、财务状况、消费行为和社交网络图谱等,其在不同风控模型中输入反映借款人的信用状况和风险水平的度量,高效的特征抽取管理是一系列线上化风控动作的数据基础。
在银行保险等同业金融机构中,由于风险业务来源的在组织架构上的复杂性,不同条线之间不可避免地存在烟囱式的特征变量开发,策略建模人员的数据需求往往在某一产品中已开发部署但并未形成统一管理共享的平台机制,造成了业务间用数口径及策略生成一致性的偏差。
因此,需要对风险业务用数流程进一步产品化抽象,来规范特征变量的衍生、存储、调用及监测,统一风控特征变量平台也应运而生。
痛点分析
在风控任务开发场景中,模型任务从预先开发的变量存储表中取数。实际开发中往往存在特征开发部署门槛高、复杂特征抽取难度大、特征应用口径不一致、特征加工流程不统一等业务及开发痛点。
01 实时特征变量开发门槛高
风控业务相关策略建模人员技术栈以Python、SQL能力为主,对基于Java语义的Flink开发有一定学习成本,除了基于离线数据的模型训练部署,实时特征处理能力不足。
02 复杂特征变量抽取难度大
部分外部数据源接口的返回报文嵌套层级较多,出参位置混乱,接口取数难度较大,对抽取特征缺乏统一平台管理维护。
03 特征变量应用口径不一致
在构建风控模型时模型任务存在相同的特征变量需求,但不同团队或不同项目中存在针对相同的原始数据重复进行特征工程处理的情况,导致特征变量逻辑变更后相应SQL的一致性和准确性问题。
04 特征变量加工流程难统一
下游策略、模型侧的新增特征变量需求缺乏一致标准化的加工路径,导致对应变量表出入参命名杂乱,当新增字段通过原SQL无法读取上游表,产生更多复杂嵌套的Join操作,随着衍生特征及变量集的配置,任务规模及资源占用情况往往难以控制。
风控特征变量体系建设方案
风控特征变量体系建设聚焦于金融机构实时风险识别与防控,通过对多源异构数据的批流抽取、聚合与衍生加工,沉淀标准化、易扩展的统一特征变量平台,实现从数据接入、特征变量生成、为下游模型训练及决策执行供数的端到端闭环,提升风险事件响应速度与决策精准度。
01 技术能力
风控业务往往面临实时数据处理需求,在客户交易、信贷审批等场景中,流计算能够实时更新客户信用评级、额度管控等风险信息,为下游决策引擎提供实时化跨系统的风险识别能力。
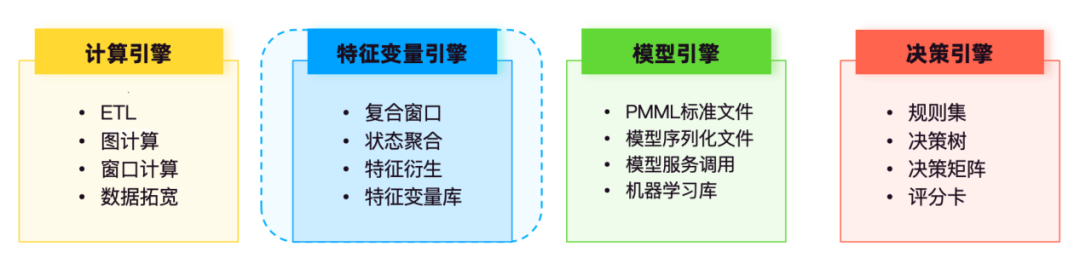
在实时风控技术系架构中,计算包括了批计算、流计算及图计算,以流计算能力为例,Flink提供了底层面向实时特征计算的能力,主要用于数据ETL、宽表加工、窗口计算、双流Join等场景,通过预计算、状态聚合计算等能力实现原始特征变量、标准特征变量、衍生特征变量的加工,为决策模型提供特征支持。
模型引擎主要负责存储和管理经训练的各类模型,如信用评分模型、欺诈检测模型、流失预警模型等。
决策引擎集中管理规则集、决策树、决策矩阵、评分卡等策略模型,规则集调用特征变量服务及模型引擎的模型服务参与决策流的逻辑运算。
特征变量引擎基于异构数据源,进行数据抽取、加工计算、标准化管理维护,实现风控人员自助查询,更加便捷、规范地进行业务取数和数据分析。
02 数据来源
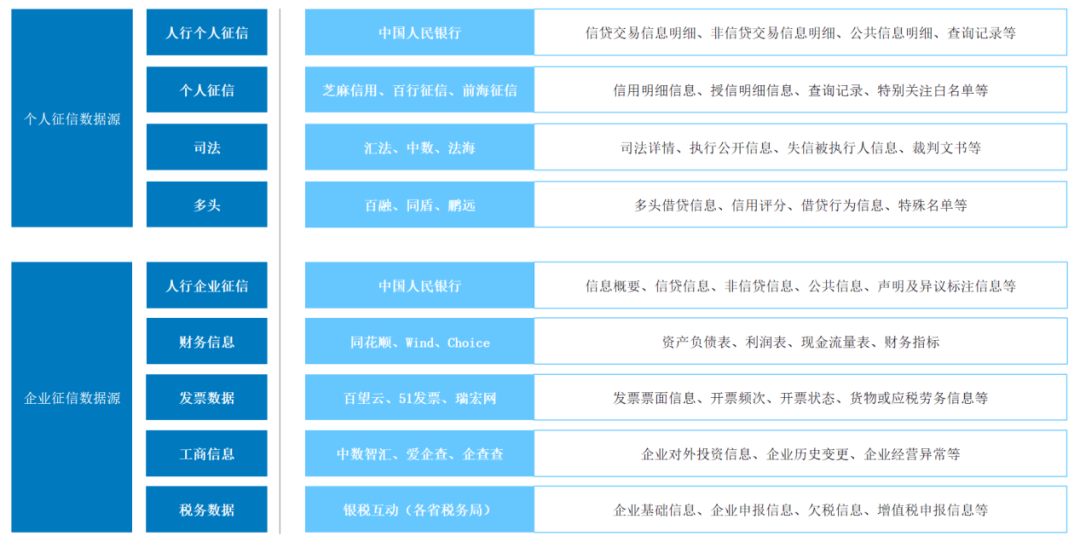
以信贷业务数据源为例,根据授信主体不同通常可分为To C个人信贷及To B对公信贷。在实际业务审查中,客户经理通常以现金流水平及负债水平两大指标进行客户授信可行性分析。
在个人信贷场景下,客户现金流水平可拆解为社保缴纳、银行及三方支付平台收入流水。负债水平则主要来源于人行征信,涵盖了个人名下各金融机构发放的全部贷款、占用风险敞口的金融产品及对外担保信息,征信数据来源除人行外包括其他第三方个人持牌征信机构,如百行征信、朴道征信及钱塘征信。
在对公信贷场景下,小微普惠类贷款的风险来源聚集于其实控人,现金流水平除实控人个人流水外同步采集对公账户流水,负债水平则额外接入其人行企业征信。中大型企业授信及行业专项贷款下,其主体风险行为事件难以依赖征信税务数据直接度量,区别于小微普惠类贷款,需结合企业实地库存与关联企业经营状况进一步线下尽调。
针对以上两类信贷业务,特征加工往往采集以下多维数据来源:
03 数据处理
面向不同风控场景的数据源,采用批、流、预计算等模式融合的特征变量加工方式,实现对业务需求的敏捷开发与存算成本管控。
批计算:针对大规模历史数据集,采用批处理进行特征变量加工。对数据中的缺失值、异常值等问题,采用插值、平滑等方法进行处理,保证数据质量。
流计算:针对实时数据流,采用流式处理模式进行特征变量加工。通过实时流处理技术,实现对数据实时分析,满足风控场景对实时性的要求。同时,采用事件驱动的架构,确保数据处理的高效与灵活性。
预计算:针对业务系统数据,视其变化频率预先计算并存储特征变量,可以有效降低流计算成本,提高决策系统从特征引擎取数的效率。
04 平台建设
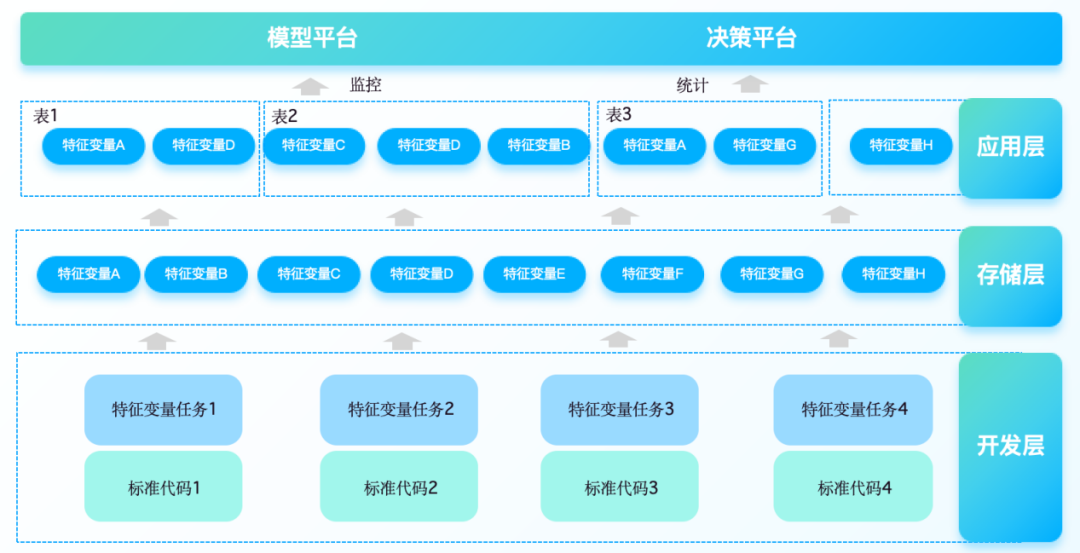
具体来说,特征变量平台需要整合征信系统、三方数据源、企业内部系统等多来源数据并进行流批能力的衍生加工,能够支持不同业务场景的风控模型入参需求。对于不同复杂度的特征变量支持可配置的、业务主导的低代码加工方式。因此,特征变量平台的建设通常包含以下几个方面:
1、特征变量抽取与生成 自动化数据清洗与预处理,将原始数据转化为可供建模使用的特征。提供画布+组件化的一站式WEB IDE模式提升开发效率,支持用户自定义或系统内置的特征计算逻辑。
2、特征变量存储与管理
基于分布式存储机制,存储大规模的历史及实时特征数据。实现特征版本控制,记录特征计算逻辑的变更历史,确保模型训练时可以回溯至特定版本的数据。
3、特征变量服务化
提供特征服务接口,为各种模型训练、预测以及决策引擎提供实时或批量特征查询服务。通过输出组件可以快速对接下游规则引擎、实时数仓、消息队列,满足复杂业务场景下低延迟、高并发访问的性能需求。
4、特征变量探索与分析
提供丰富的统计分析工具,帮助分析人员快速了解特征变量分布、关联关系等。可视化界面展示特征重要性、影响度等指标,辅助特征选择与迭代。
5、与内外部系统的集成
集成金融机构内部交易系统、CRM系统、ERP系统等多种数据源。支持与其他风控组件(如规则引擎、模型库等)以及外部征信等第三方数据服务商的对接。
05 建设收益
在某银行客户特征变量项目的落地实践中,平台服务于贷前授信场景的特征变量加工衍生管理需求,对接上游多样化数据来源,如外部的运营商、工商、司法数据;银行内部的客户设备信息、账户交易信息;贷前收集的资产估值、额度测算数据。通过实时特征变量计算能力,向下游申请评分卡等模型供数。
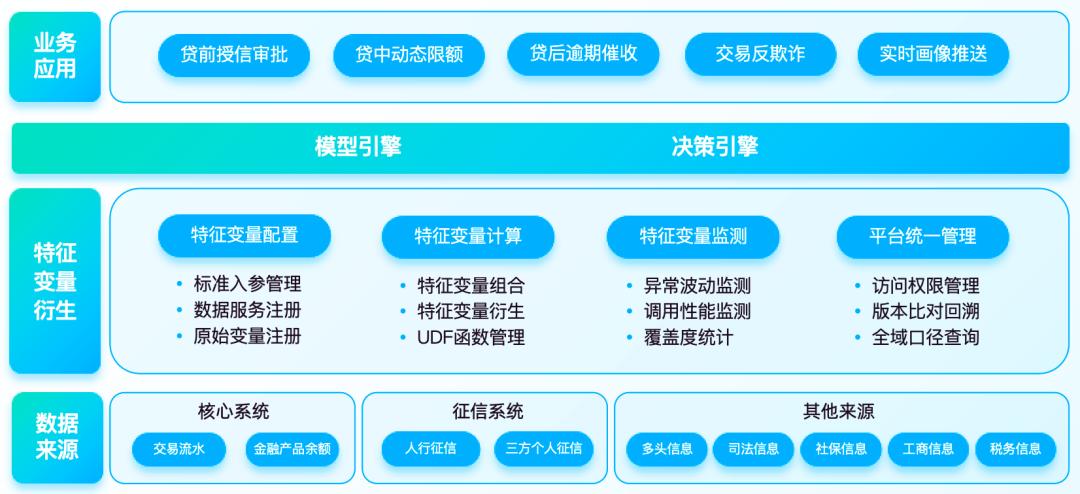
1、组件化抽取特征变量
平台从SQL命令中批量解析特征变量,面向模型任务的取数需求,用户可在平台自由加工组合所需特征变量写入相应主题hive表以供读取加工。
2、特征变量集同步更新
页面支持增、删、编辑特征变量集,平台表结构操作自动同步至物理模型表。当特征变量逻辑发生变化时,仅需编辑对应标准特征变量衍生代码或原始特征变量标准化操作,避免面向大段sql函数的复杂开发。
3、稳定性及异常监测
平台提供的监控看板功能支持了对特征变量的波动及变量集调用情况的监测,特征变量值监控确保上游数据异常时,下游任务及时停止,最大可能避免模型用数时特征变量差异过大造成的模型结果失真;统计各变量集调用情况,实时推送基线告警及强弱规则校验信息。
4、平台统一管控
平台提供成员管理、审批中心、调用分析、自动归档、任务重启等管控手段,支持任务优先级调整,统一调度任务运行以提高数据服务达成效果及集群资源利用率。
平台部署上线,覆盖支持了消费贷、小微信用贷等业务下30+授信场景。特征变量平台通过与下游规则模型引擎的结合,实现了实时决策能力在风控场景的落地,满足了贷前授信场景下提高用户在信用卡申请、贷款审批过程中的客户体验和放款效率,此外,也为贷后催收、交易反欺诈等场景供数,支持下游系统实时监控用户的异常交易行为,进行反洗钱身份识别,并进行实时告警推送。
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn








![[C语言]——scanf和printf介绍](https://img-blog.csdnimg.cn/direct/3b29da3b3ee7476ebed9b3ec01e641c8.png)