ES是一个强大的搜索引擎,它提供了非常丰富的数据检索Api来满足用户各种各样的需求。我们今天要介绍的是部分非常基础的全文搜索Api,这部分Api我们会在日常使用中经常用到。
在我们查询一些文本内容的时候,一般不会做精确匹配,一来性能开销大,而来意义也不大
其实在我们写入数据的时候,系统会使用分词器把文本数据进行分词,并且统计每个词语出现的次数信息,
如上图,当我们检索文本数据的时候,会使用同样的分词器对检索内容进行分词,然后与文本内容匹配,根据统计信息给每个词语打分,最好根据公式算出相关性评分(内容相似度),并且返回相关性最高的TopN个文档返回用户
ES支持全文索引的Api主要有以下几个:
- match:匹配查询可以处理全文本,精确字段(日前、数字等)
- match phrase(短语):短语匹配会将检索内容分词,这些词语必须全部出现在检索内容中,并且顺序必须一致,默认情况下这些词必须连续
- match phrase prefix:与match phrase类似,但最后一个词项会作为前缀,并且匹配这个词项开头的任何词语
- multi match:通过multi match可以在多个字段上执行相同的查询语句
## match(匹配查询) 匹配查询可以处理全文本、精确字段(日期、数字等)

返回结果:
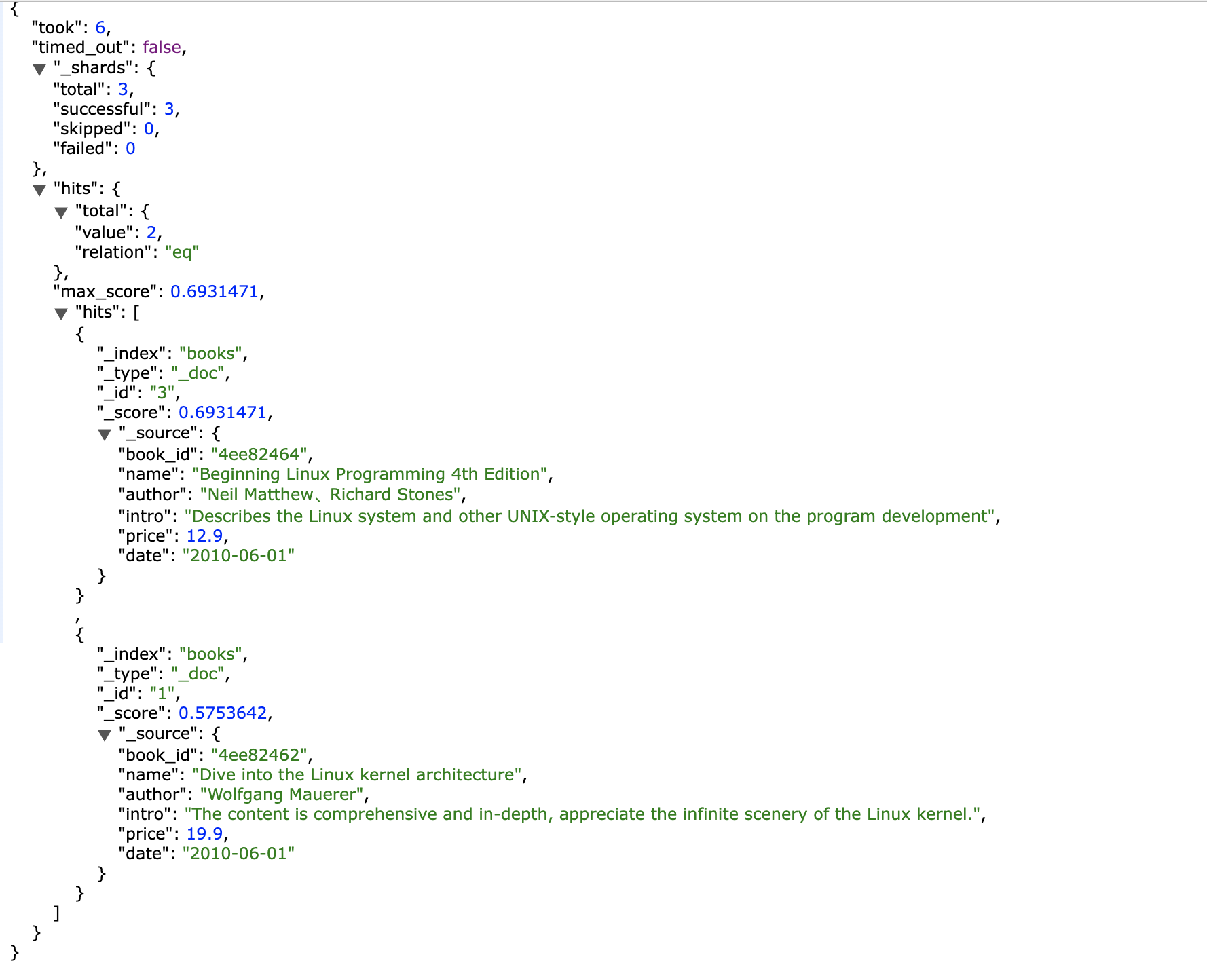
从结果可以看到 匹配到了id为3和为1的文档,这两个文档都含有“linux”或者“architecture”
在进行全文本字段检索的时候,match Api提供了operator和minimum_should_match参数:
- opeartor:参数可以为“or”或者“and”来控制检索词项间的关系,默认值为“or”。所以上面例子中,只要书名中含有“linux”或者“architecture”的文档都可以匹配上
- minimum_should_match:可以指定词项的最少匹配个数,其实可以指定为具体某个数字,但因为我们无法预估索引内容的词项数量,一般将其设置为一个百分比

返回结果:
match phrase(短语匹配)
简单来说,短语匹配会检索内容进行分词,这些分词必须全部出现在检索内容中,并且顺序必须一致,默认情况下这些词都必须连续
返回结果:
如上实例,查询书名中带有“linux kernel”短语的书本。在默认情况下,当我们搜索书名中带有“linux architecture”的时候,是无法命中文档的,因为没有书本的名字带有这个短语。这个时候可以使用stop参数来指定词项间的距离差值,即两个词项中可以含有多少个其他不相关的词语,stop默认是0
这里的stop如果为0,是没有数据的, 如果为1,返回数据为:
match phrase prefix(短语前缀匹配)
match phrase prefix与match phrase类似,但最后一个词项会作为前缀,并且匹配这个词项开头的任何词语。可以使用max_expansions参数来控制最后一个词项的匹配数量,词参数默认值值为50
返回结果:

我们可以通过设置max_expansions来限制最后一个词项的匹配个数为2。也就是说max_expansions=2的话,每个分片最多匹配2个文档,如果有3个分片,最多返回6个匹配的文档
一般来说,match_phrase_prefix api可以实现比较粗糙的自动建议功能,但要实现自动建议的功能,可以使用 Suggest Api
multi match
multi-match Api构建在match查询的基础上,可以允许在多个字段上执行相同的查询
如上示例,fields参数是一个列表,里面的元素是需要查询的字段名称。Fields中的值既可以支持以通配符方式匹配文档字段,又可以支持提升字段的权重。如 "nam" 就是使用了通配符匹配的方式,其可以匹配到书名(name)字段。而 “intro^2” 就是对书本简介字段(intro)的相关性评分乘以 2,其他字段不变。*
multi-match Api还提供了多种类型来设置其执行方式:
- best_fields:默认的类型
- most_fields: 会执行match查询并且将所有与查询匹配的文档作为结果返回
- phrase: 在 fields 中的每个字段上均执行 match_phrase 查询,并将最佳匹配字段的评分作为结果返回
- phrase_prefix:在fields中的字段上均执行 match_phrase_prefix查询,并将最佳匹配字段的评分作为结果返回
- cross_fields:它将所有字段当成一个大字段,并在每个字段中查询每个词,例如当需要查询英文人名的时候,可以将first_name和last_name两个字段组合作为full_name来查询
- bool_prefix:在每个字段上创建一个match_bool_prefix查询,并且合并每个字段的评分作为评分结果
上述的几种类型,无法就是在设置算分的方式和匹配文档的方式不一样,可以使用“type”字段来指定这些类型,以best_fiels为例,其示例如下:
![剑指offer》15--二进制中1的个数[C++]](https://img-blog.csdnimg.cn/direct/3059b3dbf2f743329a1dd2fe037ea77e.png)