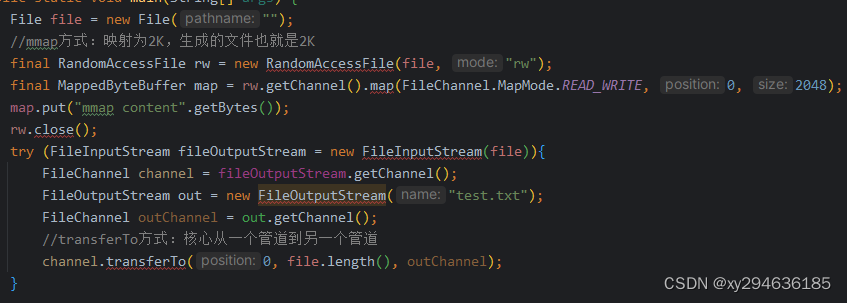
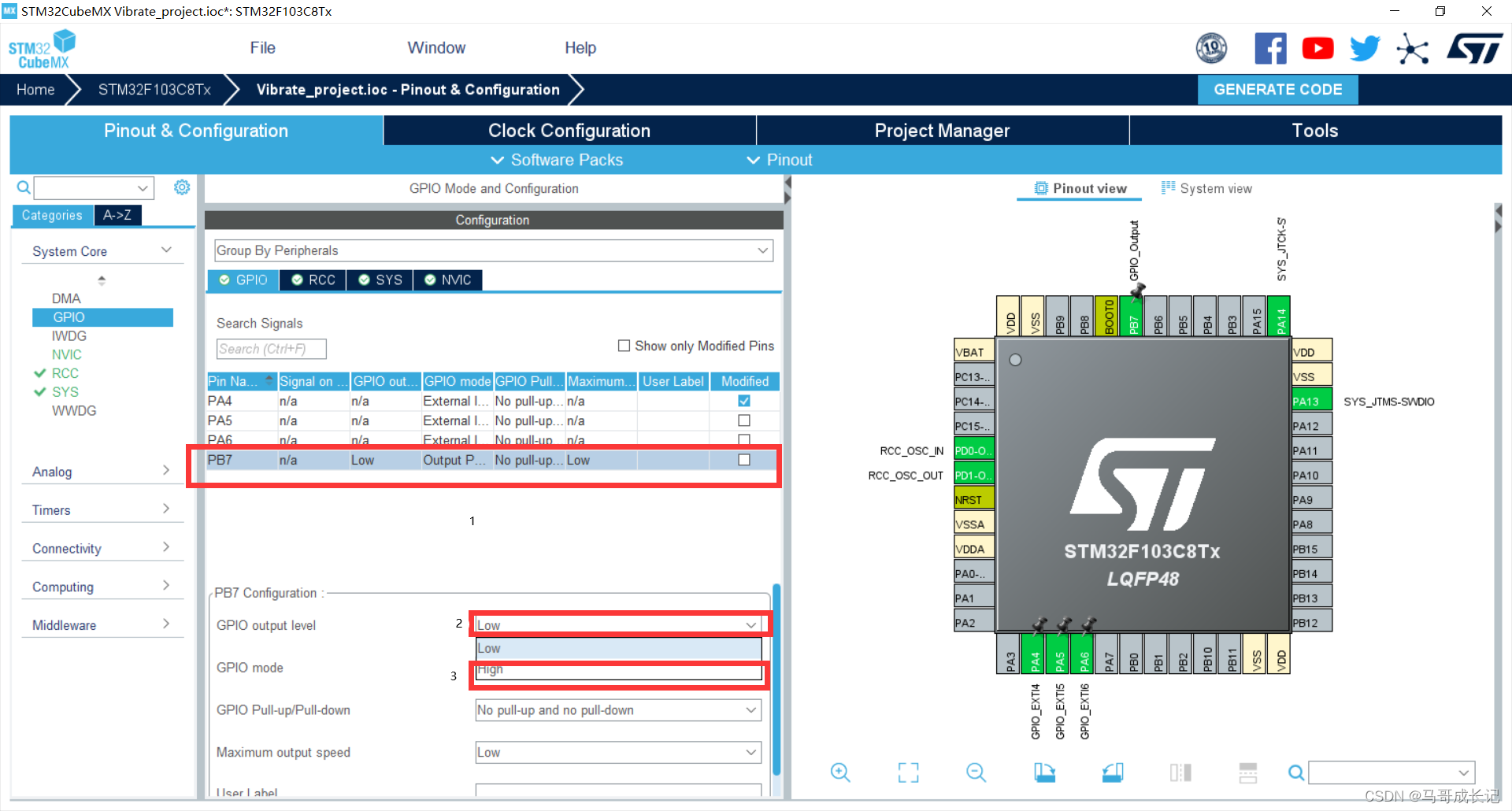
最近了解了下些常见的推理和加速方案:
1、量化方案:
- gptq、quantization、int8、int4、AWQ、Speculative Decoding、GGUF
2、Attention加速方案:
- atten的不同种类
- fused attention
3、内存层面:
- kv_cache策略、page_attention
- StreamingLLM(这个不能算加速,算技巧)
- batching
- 复用prompt策略
- Continuous batching
4、硬件层面:
- A100最好,越高越好,新的加速硬件
- flash_attention1 & flash_attention2 加速策略
- kernel 算子融合策略
- tensor 并行,分布式
5、模型层面:
- 参数量降低1B?、层数降低、模型结构创新
可能不少遗漏,欢迎各位大佬补充在评论区~
部分经验总结 & 问题:
1、compile 整个模型后的模型确实更快了,如果只compile attention部分加速不大,因为compile优化的空间并不大
2、投机采样测试过程中发现多卡推理 int4 模型出现报错,int8模型没有问题,这个目前没空看了
3、量化确实会带来速度的巨大提升,但是模型效果截图不太方便,效果确实降低了一些
4、AWQ量化后的千问7B模型,效果巨差,暂不确定问题在哪,目测了效果
不同cuda_kernel 的测试结果: default vs sdp-math vs sdp-flash vs sdp-efficient:

vllm & compile测试后的结果:

公众号"小晨的AI工作室"回复: "vllm_test" 获得原图,测试不易,希望点点关注哈~
![洛谷 P1083 [NOIP2012 提高组] 借教室(二分+差分)](https://img-blog.csdnimg.cn/direct/5dc475663519463d82a9c254d8f6917d.png)