文章目录
- 样本经验处理
- 降低图片像素和通道
- 构建连续状态捕捉动作
- 经验回放类
- 各部分的模型
- 编码器模型
- 反向模型
- 正向模型
- DQN模型
- ICM 的 反向传播
- 概念补充
- 强化学习组成元素
- 按照学习目标来分
- 按照策略更新方式区分强化学习
- on-line 与 off-line
- 经验回放
- 全部代码
样本经验处理
降低图片像素和通道
import matplotlib.pyplot as plt
from skimage.transform import resize
import numpy as np
# 降低每帧图片的尺寸和颜色通道,从而降低后面模型需要关注的内容
def downscale_obs(obs, new_size=(42, 42), to_gray=True):
if to_gray:
return resize(obs, new_size, anti_aliasing=True).max(axis=2)
else:
return resize(obs, new_size, anti_aliasing=True)
# (240, 256, 3) -> (42,42)
# plt.imshow(env.render(mode= "rgb_array"))
# plt.show()
plt.imshow(downscale_obs(env.render(mode="rgb_array")))
plt.show()
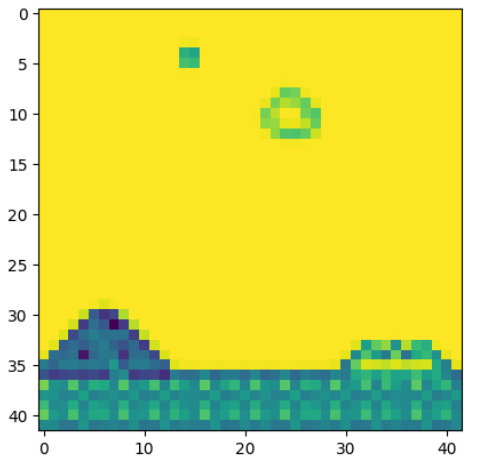
通过降低每一帧的图片像素和通道(转为灰度图),一反面可以降低经验回放器的内存问题,一方面可以自动过滤掉一些与游戏无关的游戏背景,比如飘动的云。从而在后面训练好奇心机制的时候,能够更加关注于与游戏通过有关的‘意外’变动。
构建连续状态捕捉动作
通过同时叠合多帧图像,用于获取运动信息。
def prepare_state(state):
# unsqueeze(dim=0) 为批量做准备
return torch.from_numpy(downscale_obs(state, to_gray=True)).float().unsqueeze(dim=0)
# (1,42,42)
# 构建初始训练state,对游戏初始化返回的state重复3次
def prepare_initial_state(state, N=3):
state_ = torch.from_numpy(downscale_obs(state, to_gray=True)).float()
tmp = state_.repeat((N, 1, 1))
# .unsqueeze(dim=0) 创建了样本batch 维度
return tmp.unsqueeze(dim=0)
# prepare_multi_state中的state1是一个训练的state, 他包含3个游戏返回的state
# state2 是一个游戏返回的state
def prepare_multi_state(state1, state2):
state1_ = state1.clone()
tmp = torch.from_numpy(downscale_obs(state2, to_gray=True)).float()
state1_[0][0] = state1[0][1]
state1_[0][1] = state1[0][2]
state1_[0][2] = tmp
return state1_
经验回放类
from random import shuffle
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
class ExperienceReplay:
def __init__(self, N=500, batch_size=100):
self.N = N
self.batch_size = batch_size
self.memory = []
self.counter = 0
def add_memory(self, state1, action, reward, state2):
self.counter += 1
if self.counter % 500 == 0:
self.shuffle_memory()
# memory未满,添加经验
if len(self.memory) < self.N:
self.memory.append((state1, action, reward, state2))
# memory已满,随机替换经验
else:
rand_index = np.random.randint(0, self.N - 1)
self.memory[rand_index] = (state1, action, reward, state2)
def shuffle_memory(self):
shuffle(self.memory)
# 生成训练batch
def get_batch(self):
if len(self.memory) < self.batch_size:
batch_size = len(self.memory)
else:
batch_size = self.batch_size
if len(self.memory) < 1:
print("Error: No data in memory")
return None
ind = np.random.choice(
np.arange(len(self.memory)), batch_size, replace=True)
batch = [self.memory[i] for i in ind]
# 分别返回state1张量、action张量、reward张量、state2张量
state1_batch = torch.stack([x[0].squeeze(dim=0) for x in batch], dim=0)
action_batch = torch.Tensor([x[1] for x in batch]).long()
# print(f'action_batch.shape {action_batch.shape}') # action_batch.shape torch.Size([150])
reward_batch = torch.Tensor([x[2] for x in batch])
state2_batch = torch.stack([x[3].squeeze(dim=0)
for x in batch], dim=0)
return state1_batch, action_batch, reward_batch, state2_batch
在该项目中,为Agent 也添加了经验回放模块,从而高效使用样本, 注意该经验回放,并没有实现优先回放。
shuffle_memory()实现了样本的随机化
get_batch()实现了从样本池中取出minibatch的样本,
add_memory()实现了新样本添加,和旧样本丢弃
各部分的模型
编码器模型
# 编码器模型
class Phi(nn.Module):
def __init__(self):
super(Phi, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
def forward(self, x):
x = F.normalize(x)
y = F.elu(self.conv1(x))
y = F.elu(self.conv2(y))
y = F.elu(self.conv3(y))
y = F.elu(self.conv4(y)) # size [1,32,3,3] batch, channels, 3*3
y = y.flatten(start_dim=1) # Size N, 288
return y
编码器模型Phi用来给ICM模块提高理解环境的能力,同时编码器模型还要过滤掉一些不重要的内容,比如马里奥游戏上方飘动的云,这些与奖励没有任何相关性的东西。这样说来,编码器模型起到类似注意力机制的作用,虽然代码逻辑不通,但是都是让模型将注意力放在重要的内容上。这里的编码器模型输出的张量维度为(N, 288)
反向模型
# 反向模型,输出的是动作概率
class Gnet(nn.Module): # 反向模型
def __init__(self):
super(Gnet, self).__init__()
self.linear1 = nn.Linear(576, 256)
self.linear2 = nn.Linear(256, 12)
def forward(self, state1, state2):
x = torch.cat((state1, state2), dim=1)
y = F.relu(self.linear1(x))
y = self.linear2(y)
y = F.softmax(y, dim=1)
return y
反向模型用于预测诱发状态从状态state1到状态state2变化的动作action。所以可以看到反向模型的输入是进过编码器编码的state1与state2。两个288相加为576。最后输出的是12个可能action的概率
反向模型的误差即训练反向模型和编码器模型的数据,同时也作为好奇心奖励的一部分。
为什么反向模型误差可以训练编码器模型Encoder
inverse prediction error ( a ^ t + 1 {\hat{\mathbf{a}}}_{\mathrm{t+1}} a^t+1 与 a t + 1 \mathrm{a}_{\mathrm{t+1}} at+1 的损失) 来训练Encoder。这样处理的好处是让 Encoder 输出的特征空间限于智能体能够控制、改变的空间里。可以注意到的是,反向模型的预测是动作 a ^ t + 1 {\hat{\mathbf{a}}}_{\mathrm{t+1}} a^t+1,从而计算与实际动作 a t + 1 \mathrm{a}_{\mathrm{t+1}} at+1 的误差。所以通过反向模型进行反向传播的梯度,能够帮助Encoder编码器模型只关注由动作引起的变化。如果使用正向模型的误差训练编码器的话,那么编码器不能很好的关注到什么是由动作引起的变化。
def ICM(state1, action, state2, forward_scale=1., inverse_scale=1e4):
state1_hat = encoder(state1) # encoder = Phi() 编码器模型
state2_hat = encoder(state2)
state2_hat_pred = forward_model(state1_hat.detach(), action.detach())
forward_pred_err = forward_scale * \
forward_loss(state2_hat_pred, state2_hat.detach()
).sum(dim=1).unsqueeze(dim=1)
pred_action = inverse_model(state1_hat, state2_hat)
inverse_pred_err = inverse_scale * \
inverse_loss(pred_action, action.detach().flatten()).unsqueeze(dim=1)
return forward_pred_err, inverse_pred_err
从ICM模块可以看出,前向模型对输入state1_hat与action进行了梯度截断,因为state1_hat是由Encoder计算出来的,action是由DQN模块计算出来的。所以要进行梯度截断。另外可以通过调节forward_scale 与 inverse_scale进行反向模型与正向模型的误差大小,从而优化梯度更新效率
正向模型
# 正向模型,输出的是t+1 的状态预测
class Fnet(nn.Module):
def __init__(self):
super(Fnet, self).__init__()
self.linear1 = nn.Linear(300, 256)
self.linear2 = nn.Linear(256, 288)
def forward(self, state, action):
action_ = torch.zeros(action.shape[0], 12)
indices = torch.stack(
(torch.arange(action.shape[0]), action.squeeze()), dim=0) # 这里的代码好像有问题
indices = indices.tolist()
action_[indices] = 1.
x = torch.cat((state, action_), dim=1)
y = F.relu(self.linear1(x))
y = self.linear2(y)
return y
正向模型用于给定state1与action,从而预测state2。因此正向模型的输入是state1的(N,288)和action的(N,12),在模型中做了一个torch.cat((state,action_),dim=1)从而将两个数据进行拼接。
正向模型的误差用于训练其自身,同时也作为好奇心奖励的一部分。主义正向模型的误差是不用于训练编码器模型的。
DQN模型
# DQN 返回q值
class Qnetwork(nn.Module):
def __init__(self):
super(Qnetwork, self).__init__()
self.conv1 = nn.Conv2d(
in_channels=3, out_channels=32, kernel_size=(3, 3), stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.linear1 = nn.Linear(288, 100)
self.linear2 = nn.Linear(100, 12)
def forward(self, x):
x = F.normalize(x)
y = F.elu(self.conv1(x))
y = F.elu(self.conv2(y))
y = F.elu(self.conv3(y))
y = F.elu(self.conv4(y))
y = y.flatten(start_dim=2)
y = y.view(y.shape[0], -1, 32)
y = y.flatten(start_dim=1)
y = F.elu(self.linear1(y))
y = self.linear2(y)
return y
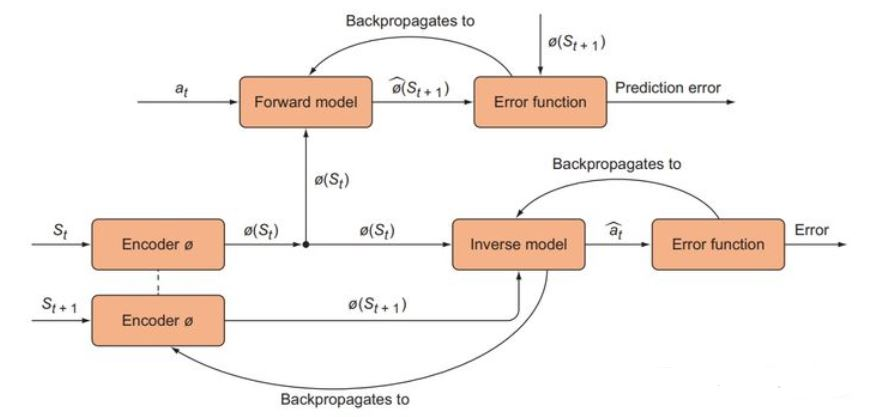
ICM 的 反向传播
- Forward Model 的 Prediction error ( s ^ t + 1 \hat{\mathbf{s}}_{\mathrm{t+1}} s^t+1 > 与 s t + 1 \mathbf{s}_{\mathrm{t}+1} st+1 的损失) 只用来训练 Forward model ,而不用于训练 Encoder
- Inverse Model 的 Inverse prediction error(> a ^ t + 1 {\hat{\mathbf{a}}}_{\mathrm{t+1}} a^t+1 与 a t + 1 \mathrm{a}_{\mathrm{t+1}} at+1 的损失) 既用来训练 Inverse model ,也用来训练 Encoder
- Forward Model 的 Prediction error 同时也是 intrinsic reward (好奇心奖励)来训练我们的 agent
概念补充
强化学习组成元素
强化学习主要由两个主体、四个部分组成。
-
两个主体
Agent:代理人,即采取行动的个体,如玩家。
Environment:环境,能对行动产生反馈,如游戏规则。 -
四个部分
<A, S, R, P> Action space, State space , Reward, Policy
A:动作空间,即Agent采取行动的所有动作空间。如对于贪吃蛇游戏,就是上下左右的离散操作空间;而对于驾驶类游戏,则是向左向右和液氮加速等的连续空间。
S:状态空间,对于Agent采取行动后的反馈状态。贪吃蛇的身体长度位置、卡丁车的速度位置等,都是State。
R:奖励,实数值,顾名思义,就是奖赏或惩罚。
P:策略,即我们训练的模型,一般基础模型为DQN。
强化学习,就是在环境E下,由Agent根据状态S采取动作A,为了获得最大奖励R而不断训练生成策略P的过程。
按照学习目标来分
- Policy-Based RL(基于概率)
通过感官分析所处的环境,直接输出下一步要采取的各种动作的概率,然后根据概率采取行动,所以每种动作都有可能被选中,只是可能性不同。如,Policy
Gradients等。
- Value-Based RL(基于价值)
输出所有动作的价值,根据最高价值来选择动作。如,Q
learning、Sarsa等。(对于不连续的动作,这两种方法都可行,但如果是连续的动作基于价值的方法是不能用的,我们只能用一个概率分布在连续动作中选择特定的动作)。
- Actor-Critic
结合这两种方法建立一种Actor-Critic的方法,基于概率会给出做出的动作,基于价值会对做出的动作的价值二者的综合。
按照策略更新方式区分强化学习
Monte-Carlo update(回合更新)
游戏开始到结束更新一次模型参数(行为准则)。如,基础版Policy Gradients、Monte-Carlo Learing等。Temporal-Difference update(单步更新)
游戏开始到结束中的每一步都会更新一次模型参数(行为准则)。如,Q Learning、Sarsa、升级版Policy Gradient等。
on-line 与 off-line
online RL(在线强化学习)
学习过程中,智能体需要和真实环境进行交互(边玩边学习)。并且在线强化学习可分为on-policy RL和off-policy RL。on-policy采用的是当前策略搜集的数据训练模型,每条数据仅使用一次。off-policy训练采用的数据不需要是当前策略搜集的。如,Sarsa、Sarsa lambda等。offline RL(离线强化学习)
学习过程中,不与真实环境进行交互,只从过往经验(dataset)中直接学习,而dataset是采用别的策略收集的数据,并且采集数据的策略并不是近似最优策略。如,Q> learning等。
经验回放
参考链接
-
经验回放是一种在强化学习中用来提升学习效率的技术,特别是在使用深度Q网络(DQN)时。传统的Q学习或Sarsa等算法通常采用在线更新策略,即在每个时间步结束后立即更新模型权重。然而,这种方法可能会导致样本效率低下和相关性问题的出现。
-
经验回放通过引入一个被称为
回放缓冲区(Replay Buffer)的数据结构来解决这些问题。这个缓冲区能够存储大量的经验转换(transitions),即由状态、动作、奖励和新状态组成的元组 (通常为(state1、action、reward、 state2)组成的元祖)。 -
前后两个 transition 之间存在很强的关联。实践证明这种相关性是 有害的。如果能够把 这些 transition 打散,更有利于训练 DQN。所以在更新模型时,不是直接使用最新收集的经验,而是从回放缓冲区中随机抽样
shuffle一批经验进行批量学习。这样做的好处是能够打破经验之间的相关性,并且允许多次利用相同的经验,从而提高了样本的效率。 -
经验回放的实施步骤大致如下:首先,将最新的经验转换添加到回放缓冲区中,直到缓冲区满为止。然后,在进行模型更新时,从回放缓冲区中随机抽取一定数量的样本,并计算相应的TD误差(Temporal Difference error)。接着,基于这些TD误差来计算梯度,并通过梯度下降法更新模型权重。
-
优先经验回放(Prioritized Experience Replay)是经验回放的一种改进形式,它引入了样本优先级的概念。也就是Agent对有些场景可能很熟悉,但是对某些场景很陌生,所以应该更关注陌生的场景,也就是说transition存在优先程度。在这种方法中,并非所有样本都有相同的机会被选中,而是根据TD误差的绝对值大小赋予不同样本不同的抽样概率。TD误差较大的样本会被赋予更高的优先级,因此更有可能被选中参与训练。这有助于模型更快地聚焦于那些难以学习的状态-动作组合,从而进一步提高学习效率。 -
为了平衡因优先级导致的抽样偏差,优先经验回放还会调整学习率。具体来说,如果一个样本被频繁抽取,其学习率会相应降低以避免过拟合;反之,如果样本很少被抽取,则适当提高其学习率以确保模型能够充分学习到这些样本中的信息。
-
从经验回放池抽出的样本,并不会影响
Agent梯度的计算,因为会重新利用抽出的transition的state1和state2进行qvalue计算,从而相减与transition的reward进行误差计算,从而进行梯度反向传播。
全部代码
import gym
from nes_py.wrappers import JoypadSpace
import gym_super_mario_bros
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT, COMPLEX_MOVEMENT
env = gym_super_mario_bros.make("SuperMarioBros-v0")
env = JoypadSpace(env, COMPLEX_MOVEMENT)
# done = True
# for step in range(2500):
# if done:
# state = env.reset()
# state, reward, done, info = env.step(env.action_space.sample())
# env.render()
# env.close()
import matplotlib.pyplot as plt
from skimage.transform import resize
import numpy as np
# 降低每帧图片的尺寸和颜色通道,从而降低后面模型需要关注的内容
def downscale_obs(obs, new_size=(42, 42), to_gray=True):
if to_gray:
return resize(obs, new_size, anti_aliasing=True).max(axis=2)
else:
return resize(obs, new_size, anti_aliasing=True)
# (240, 256, 3) -> (42,42)
# plt.imshow(env.render(mode= "rgb_array"))
# plt.show()
plt.imshow(downscale_obs(env.render(mode="rgb_array")))
plt.show()
# 准备原始状态
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
from collections import deque
if torch.cuda.is_available():
device = torch.device("cuda")
print("GPU is available and being used")
else:
device = torch.device("cpu")
print("GPU is not available, using CPU instead")
def prepare_state(state):
# unsqueeze(dim=0) 为批量做准备
return torch.from_numpy(downscale_obs(state, to_gray=True)).float().unsqueeze(dim=0)
# (1,42,42)
# 构建初始训练state,对游戏初始化返回的state重复3次
def prepare_initial_state(state, N=3):
state_ = torch.from_numpy(downscale_obs(state, to_gray=True)).float()
tmp = state_.repeat((N, 1, 1))
# .unsqueeze(dim=0) 创建了样本batch 维度
return tmp.unsqueeze(dim=0)
# prepare_multi_state中的state1是一个训练的state, 他包含3个游戏返回的state
# state2 是一个游戏返回的state
def prepare_multi_state(state1, state2):
state1_ = state1.clone()
tmp = torch.from_numpy(downscale_obs(state2, to_gray=True)).float()
state1_[0][0] = state1[0][1]
state1_[0][1] = state1[0][2]
state1_[0][2] = tmp
return state1_
# 策略函数
def policy(qvalues, eps=None):
if eps is not None:
if torch.rand(1) < eps:
return torch.randint(low=0, high=7, size=(1,))
else:
return torch.argmax(qvalues)
else:
# 构建多项式分布抽样返回动作
return torch.multinomial(F.softmax(F.normalize(qvalues), dim=-1), num_samples=1)
from random import shuffle
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
class ExperienceReplay:
def __init__(self, N=500, batch_size=100):
self.N = N
self.batch_size = batch_size
self.memory = []
self.counter = 0
def add_memory(self, state1, action, reward, state2):
self.counter += 1
if self.counter % 500 == 0:
self.shuffle_memory()
# memory未满,添加经验
if len(self.memory) < self.N:
self.memory.append((state1, action, reward, state2))
# memory已满,随机替换经验
else:
rand_index = np.random.randint(0, self.N - 1)
self.memory[rand_index] = (state1, action, reward, state2)
def shuffle_memory(self):
shuffle(self.memory)
# 生成训练batch
def get_batch(self):
if len(self.memory) < self.batch_size:
batch_size = len(self.memory)
else:
batch_size = self.batch_size
if len(self.memory) < 1:
print("Error: No data in memory")
return None
ind = np.random.choice(
np.arange(len(self.memory)), batch_size, replace=True)
batch = [self.memory[i] for i in ind]
state1_batch = torch.stack([x[0].squeeze(dim=0) for x in batch], dim=0)
action_batch = torch.Tensor([x[1] for x in batch]).long()
# print(f'action_batch.shape {action_batch.shape}') # action_batch.shape torch.Size([150])
reward_batch = torch.Tensor([x[2] for x in batch])
state2_batch = torch.stack([x[3].squeeze(dim=0)
for x in batch], dim=0)
return state1_batch, action_batch, reward_batch, state2_batch
# 编码器模型
class Phi(nn.Module):
def __init__(self):
super(Phi, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
def forward(self, x):
x = F.normalize(x)
y = F.elu(self.conv1(x))
y = F.elu(self.conv2(y))
y = F.elu(self.conv3(y))
y = F.elu(self.conv4(y)) # size [1,32,3,3] batch, channels, 3*3
y = y.flatten(start_dim=1) # Size N, 288
return y
# 反向模型,输出的是动作概率
class Gnet(nn.Module): # 反向模型
def __init__(self):
super(Gnet, self).__init__()
self.linear1 = nn.Linear(576, 256)
self.linear2 = nn.Linear(256, 12)
def forward(self, state1, state2):
x = torch.cat((state1, state2), dim=1)
y = F.relu(self.linear1(x))
y = self.linear2(y)
y = F.softmax(y, dim=1)
return y
# 正向模型,输出的是t+1 的状态预测
class Fnet(nn.Module):
def __init__(self):
super(Fnet, self).__init__()
self.linear1 = nn.Linear(300, 256)
self.linear2 = nn.Linear(256, 288)
def forward(self, state, action):
action_ = torch.zeros(action.shape[0], 12)
indices = torch.stack(
(torch.arange(action.shape[0]), action.squeeze()), dim=0) # 这里的代码好像有问题
indices = indices.tolist()
action_[indices] = 1.
x = torch.cat((state, action_), dim=1)
y = F.relu(self.linear1(x))
y = self.linear2(y)
return y
# DQN 返回q值
class Qnetwork(nn.Module):
def __init__(self):
super(Qnetwork, self).__init__()
self.conv1 = nn.Conv2d(
in_channels=3, out_channels=32, kernel_size=(3, 3), stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)
self.linear1 = nn.Linear(288, 100)
self.linear2 = nn.Linear(100, 12)
def forward(self, x):
x = F.normalize(x)
y = F.elu(self.conv1(x))
y = F.elu(self.conv2(y))
y = F.elu(self.conv3(y))
y = F.elu(self.conv4(y))
y = y.flatten(start_dim=2)
y = y.view(y.shape[0], -1, 32)
y = y.flatten(start_dim=1)
y = F.elu(self.linear1(y))
y = self.linear2(y)
return y
params = {
'batch_size': 150,
'beta': 0.2,
'lambda': 0.1,
'eta': 1.0,
'gamma': 0.2,
'max_episode_len': 100,
'min_progress': 15,
'action_repeats': 4,
'frames_per_state': 3
}
replay = ExperienceReplay(N=1000, batch_size=params['batch_size'])
Qmodel = Qnetwork()
encoder = Phi()
forward_model = Fnet()
inverse_model = Gnet()
forward_loss = nn.MSELoss(reduction='none')
inverse_loss = nn.CrossEntropyLoss(reduction='none')
qloss = nn.MSELoss()
all_model_params = list(Qmodel.parameters()) + list(encoder.parameters())
all_model_params += list(forward_model.parameters()) + \
list(inverse_model.parameters())
opt = optim.Adam(lr=0.001, params=all_model_params)
def loss_fn(q_loss, inverse_loss, forward_loss):
loss_ = (1 - params['beta']) * inverse_loss
loss_ += params['beta'] * forward_loss
loss_ = loss_.sum() / loss_.flatten().shape[0]
loss = loss_ + params['lambda'] * q_loss
return loss
def reset_env():
"""
reset the environment and return a new initial state
"""
env.reset()
state1 = prepare_initial_state(env.render(mode='rgb_array'))
return state1
def ICM(state1, action, state2, forward_scale=1., inverse_scale=1e4):
state1_hat = encoder(state1) # encoder = Phi() 编码器模型
state2_hat = encoder(state2) # # Size N, 288
state2_hat_pred = forward_model(state1_hat.detach(), action.detach())
forward_pred_err = forward_scale * \
forward_loss(state2_hat_pred, state2_hat.detach()
).sum(dim=1).unsqueeze(dim=1)
pred_action = inverse_model(state1_hat, state2_hat)
inverse_pred_err = inverse_scale * \
inverse_loss(pred_action, action.detach().flatten()).unsqueeze(dim=1)
return forward_pred_err, inverse_pred_err
def minibatch_train(use_extrinsic=True):
state1_batch, action_batch, reward_batch, state2_batch = replay.get_batch()
action_batch = action_batch.view(action_batch.shape[0], 1)
reward_batch = reward_batch.view(reward_batch.shape[0], 1)
forward_pred_err, inverse_pred_err = ICM(
state1_batch, action_batch, state2_batch)
i_reward = (1. / params['eta']) * forward_pred_err
reward = i_reward.detach()
if use_extrinsic:
reward += reward_batch
qvals = Qmodel(state2_batch)
reward += params['gamma'] * torch.max(qvals)
reward_pred = Qmodel(state1_batch)
reward_target = reward_pred.clone()
indices = torch.stack(
(torch.arange(action_batch.shape[0]), action_batch.squeeze()), dim=0)
indices = indices.tolist()
reward_target[indices] = reward.squeeze()
# qloss = nn.MSELoss(), 非动作的会相减为0
q_loss = 1e5 * qloss(F.normalize(reward_pred),
F.normalize(reward_target.detach()))
return forward_pred_err, inverse_pred_err, q_loss
# train
epochs = 50
env.reset()
eps = 0.15
losses = []
episode_length = 0
switch_to_eps_greedy = 1000
state_deque = deque(maxlen=params['frames_per_state']) # 3
e_reward = 0.
max_step = 1500
if_show = True
# print(dir(env.env.env))
# last_x_pos = env.env.env._x__position
last_x_pos = 0
position_distance = []
action_cum = []
use_extrinsic = False
for i in range(epochs):
episode_length += 1
action_num = 0
done = False
state1 = reset_env()
print(f"this is episode {i}")
while not done:
opt.zero_grad() # opt = optim.Adam(lr=0.001, params=all_model_params)
q_val_pred = Qmodel(state1)
if i > switch_to_eps_greedy:
action = int(policy(q_val_pred, eps))
else:
action = int(policy(q_val_pred))
for j in range(params['action_repeats']): # 将策略所说的任何动作重复6次以加快学习速度
state2, e_reward_, done, info = env.step(action)
# print(e_reward_)
if if_show:
env.render()
action_num += 1
if action_num == max_step:
done = True
# last_x_pos = info['x_pos']
e_reward = e_reward_
state_deque.append(prepare_state(state2))
if len(state_deque) == 3:
state2 = torch.stack(list(state_deque), dim=1)
replay.add_memory(state1, action, e_reward, state2) # (1,3,42,42), (1), (1), (1,3,42,42),
state1 = state2
if done:
position_distance.append(info['x_pos']) # 获取每局最后位置
action_cum.append(action_num)
break
# if episode_length > params['max_episode_len']: # 100
# if (info['x_pos'] - last_x_pos) < params['min_progress']:
# done = True
# else:
# last_x_pos = info['x_pos']
state1 = state2
if len(replay.memory) < params['batch_size']:
continue
forward_pred_err, inverse_pred_err, q_loss = minibatch_train(
use_extrinsic=False)
loss = loss_fn(q_loss, forward_pred_err, inverse_pred_err)
loss_list = (q_loss.mean(), forward_pred_err.flatten().mean(),
inverse_pred_err.flatten().mean())
losses.append(loss_list) # 用于后续可视化
loss.backward()
opt.step()
torch.save(Qmodel,'ICM_Qmodel.pt')
Qmodel = torch.load('ICM_Qmodel.pt')
# torch.save(Qmodel.state_dict(), 'ICM_Qmodel')
# 保存模型
# 训练结果可视化
# test trained agent
done = True
env = gym_super_mario_bros.make("SuperMarioBros-v0")
env = JoypadSpace(env, COMPLEX_MOVEMENT)
for step in range(5000):
if done:
# env.reset()
state1 = prepare_initial_state(env.render(mode='rgb_array'))
q_val_pred = Qmodel(state1)
action = int(policy(q_val_pred, eps))
# print(action)
state2, reward, done, info = env.step(action)
state2 = prepare_multi_state(state1, state2)
state1 = state2
env.render()
env.close()
https://blog.csdn.net/wzduang/article/details/112533271
https://zhuanlan.zhihu.com/p/613441084
https://www.cnblogs.com/Roboduster/p/16457727.html