目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
5.算法完整程序工程
1.算法运行效果图预览
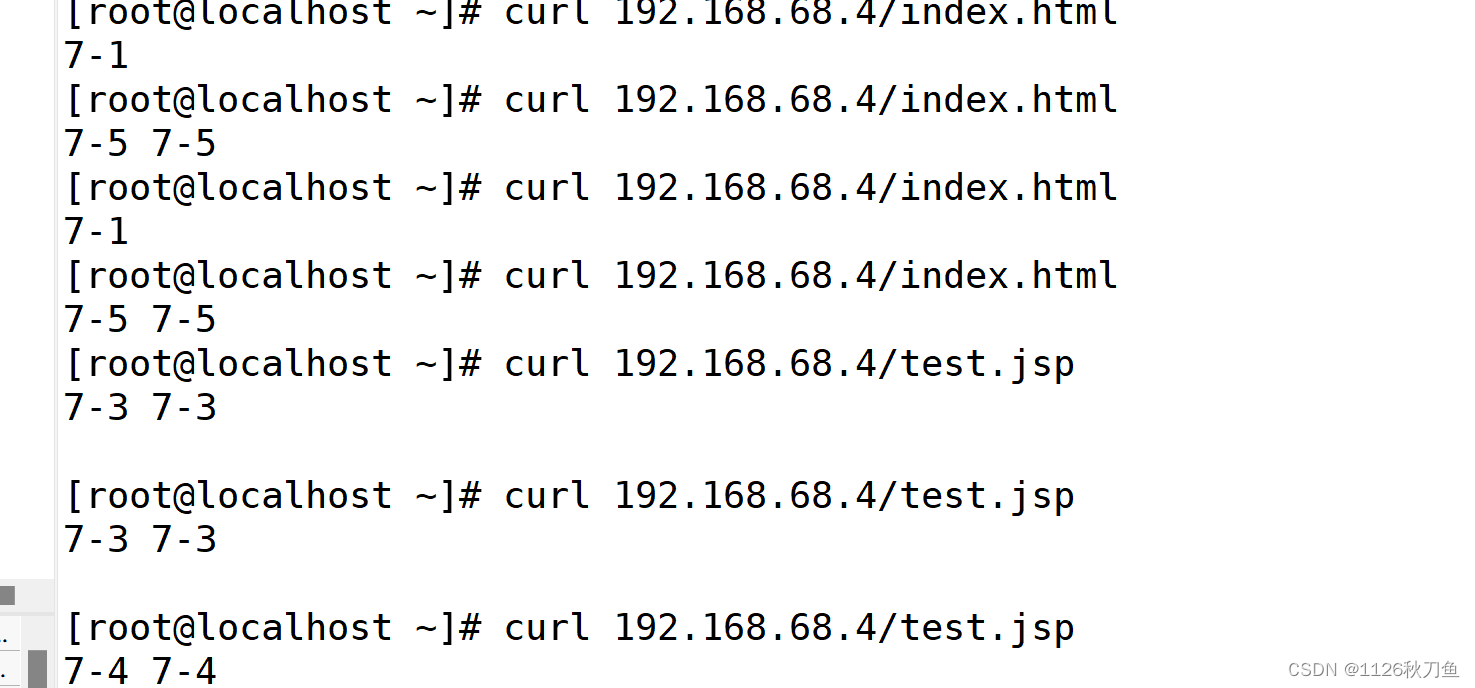
推荐商品的ID号:
ans =
9838
17582
21911
14902
14902
12352
24732
23071
23499
11790
1547
16550
16550
16550
1133
11330
27415
28391
6672
8193
8193
12168
241
14020
20631
17958
21336
25227
2257
2257
14182
5369
22313
11280
26699
25792
12168
17060
2963
27791
27791
27791
20297
14182
14182
12599
1547
1547
15584
4479
22583
26298
26006
3627
14020
9657
25086
23662
25372
29203
26871
15934
13883
12220
27785
27785
27785
25488
27989
27989
6672
27508
22583
9829
7386
4647
13554
11939
2635
25372
25372
6080
12162
25329
17550
7868
7868
28410
8637
25488
21838
11083
251
6319
6319
2410
23928
19421
13494
7490
23662
14159
11000
11000
12606
21657
4571
15639
12230
24528
17445
1133
11052
23482
23482
23482
23482
23482
23482
22583
241
26969
14902
6672
267222.算法运行软件版本
matlab2022a
3.部分核心程序
...............................................................
while gen < MAXGEN;
gen
P1 = 0.9;
P2 = 1-P1;
FitnV=ranking(Objv);
Selch=select('sus',Chrom,FitnV);
Selch=recombin('xovsp', Selch,P1);
Selch=mut( Selch,P2);
phen1=bs2rv(Selch,FieldD);
for a=1:1:NIND
if gen == 1
LR(a) = Supp0;
else
LR(a) = phen1(a,1);
end
%计算对应的目标值
errs = func_obj(data(Index(1:10000),:),Max_N,LR(a));
E = 1/errs;
JJ(a,1) = E;
end
Objvsel=(JJ+eps);
[Chrom,Objv]=reins(Chrom,Selch,1,1,Objv,Objvsel);
gen=gen+1;
%保存参数收敛过程和误差收敛过程以及函数值拟合结论
LR2(gen) = mean(LR);
end
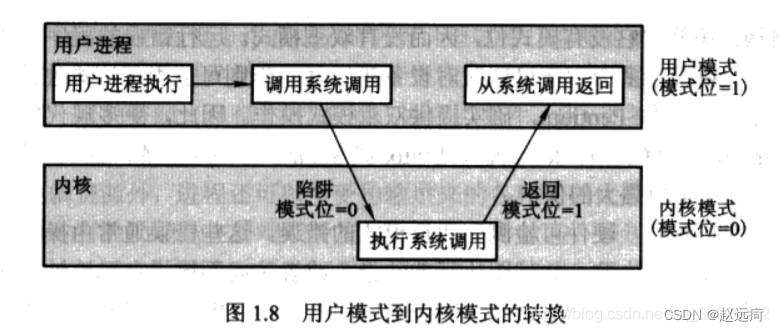
%画图
figure;
plot(LR2(3:end),'b-o','linewidth',2);
xlabel('Iteration Number');
ylabel('Support value');
grid on;
save GA.mat LR2
end
load GA.mat
figure;
plot(LR2(3:end),'b-o','linewidth',2);
xlabel('Iteration Number');
ylabel('Support value');
grid on;
%**************************************************************************
Supp = LR2(end); %支持度阈值
%根据关联规则进行推荐算法
%初始商品推荐列表
[P,Support] = func_ProductList(data,Supp);
if length(P) > Max_N
Len = length(P);
[tmps,I] = sort(Support);
Index = I(Len-Max_N+1:Len);
Recommend_list = P(Index);
Support_list = Support(Index);
else
Recommend_list = P;
Support_list = Support;
end
%获得最后的推介商品
R1 = [Prod_ID(Recommend_list),Support_list];
save r1.mat R1 P Support Prod_ID
disp('推荐商品的ID号:');
Prod_ID(Recommend_list)
05_028m
4.算法理论概述
用户兴趣模型,即对用户的兴趣和爱好的准确描述。而在建立用户兴趣模型的时候,首先需要确定用户兴趣模型的表示形式。因此,用户兴趣模型的表示是用户兴趣模型的一个重要环节。所谓用户兴趣的表示,即个性化信息推荐的一个重要环节,影响用户兴趣的因素有很多种,比如年龄,学历,职业等。另外一方面,用户兴趣会随着时间的变化而变化,这对用户兴趣的表示增加了难度。其中一个最为基础的用户兴趣表示方法是通过关键词来表示的。但是通过关键词方式的用户兴趣表示方法具有一定的局限性。这个局限性,主要是因为关键词无法完全表达出用户兴趣导致的。
用户兴趣模型的构建,其本质就是和用户兴趣相关的信息的获取,然后构建一个可以读取识别这些信息的数学模型的过程。用户兴趣模型的构建过程如下图所示。
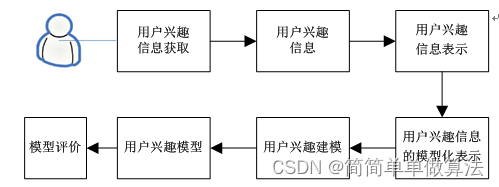
用户兴趣模型是个性化推荐技术的基础,通过建立一个优良的用户兴趣模型,可以实现更高性能的推荐系统。从而大大减少了用户寻找自己感兴趣信息的时间和精力。
协同过滤推荐(Collaborative Filtering Recommendation)技术,在推荐系统中是最为成功的技术之一。协同过滤,被称为社会过滤或者协作过滤。最早是由Goldberg等学者提出来的,之后发展快速且广泛。协同过滤方法,首先利用用户历史评价的记录,然后构建出用户评分矩阵,并且计算项目或用户之间相似度,最后是采用领域的方法向用户推荐。协同过滤,根据用户的历史喜好信息,计算用户之间的距离,然后对商品的评价进行加权评价值,利用目标用户的最近的邻居用户,预测目标用户对商品的喜好程度,系统根据对商品的喜好程度从而对目标用户进行个性化推荐。
支持度表示某一关联规则在数据中出现的普遍程度,即称为该关联规则在数据中的支持度,其中支持度的计算公式为:
![]()
此外,置信度说明某一关联规则成立的必然程度,即称为该关联规则在数据库的可信度,其中支持度的计算公式为:
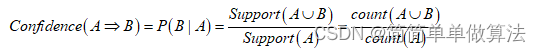
通过判断支持度和置信度是否超过阈值,来判断是否产生一个强规则,那么预先设置这个支持度阈值和置信度阈值是十分重要的,对最后的推荐准确度有着重要影响。 这里,通过遗传算法来优化支持度阈值和置信度阈值。
这里,设置优化目标函数为:
![]()
其中函数f表示的是当设置不同的支持度阈值和置信度阈值下,整个推荐算法获得的推荐正确率,然后通过GA算法流程图进行阈值的优化。
5.算法完整程序工程
OOOOO
OOO
O