目录
一、DolphinScheduler介绍
1.1 概述
1.2 特性
1.2.1 简单易用
1.2.2 丰富的使用场景
1.2.3 High Reliability
1.2.4 High Scalability
1.3 名词解释
1.3.1 名词解释
1.3.2 模块介绍
二、DolphinScheduler架构原理
2.1 系统架构图
2.2 架构说明
2.2.1 MasterServer
2.2.2 WorkerServer
2.2.3 AlertServer
2.2.4 ApiServer
2.2.5 UI
2.2.6 ZooKeeper
2.3 架构设计思想
2.3.1 去中心化vs中心化
2.3.2 容错设计
2.3.3 任务失败重试
2.3.4 任务优先级设计
三、负载均衡
3.1 Worker 负载均衡算法
3.1.1 加权随机(random)
3.1.2 平滑轮询(roundrobin)
3.1.3 线性负载(lowerweight)
一、DolphinScheduler介绍
1.1 概述
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务,工作流和全生命周期数据处理过程的解决方案。
Apache DolphinScheduler (简称DS)旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。DS以 DAG流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。

官网文章地址:
https://dolphinscheduler.apache.org/zh-cn/docs/3.2.1/about/introduction
集群部署流程见文章:
DolphinScheduler-3.2.0 集群搭建-CSDN博客
1.2 特性
1.2.1 简单易用
- 可视化 DAG: 用户友好的,通过拖拽定义工作流的,运行时控制工具
- 模块化操作: 模块化有助于轻松定制和维护。
1.2.2 丰富的使用场景
- 支持多种任务类型: 支持Shell、MR、Spark、SQL等10余种任务类型,支持跨语言,易于扩展
- 丰富的工作流操作: 工作流程可以定时、暂停、恢复和停止,便于维护和控制全局和本地参数。
1.2.3 High Reliability
- 高可靠性: 去中心化设计,确保稳定性。 原生 HA 任务队列支持,提供过载容错能力。 DolphinScheduler 能提供高度稳健的环境。
1.2.4 High Scalability
- 高扩展性: 支持多租户和在线资源管理。支持每天10万个数据任务的稳定运行。
1.3 名词解释
这里整理的是调度系统常用的名词
1.3.1 名词解释
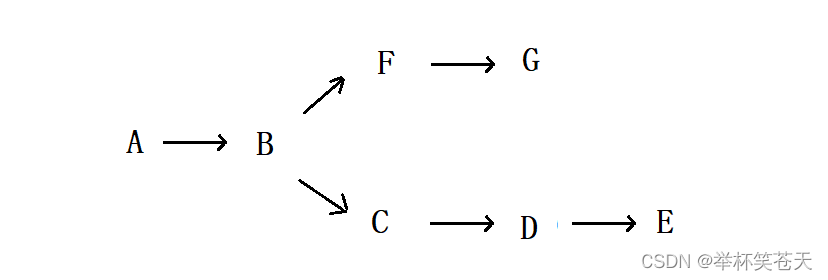
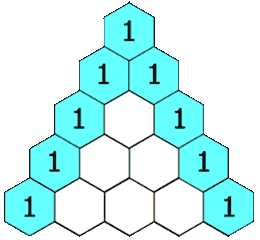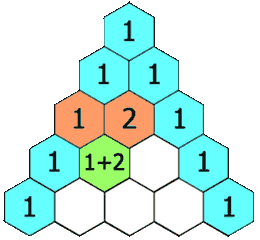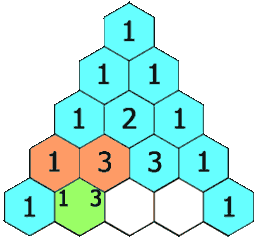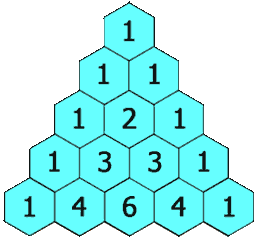
- DAG: 全称 Directed Acyclic Graph,简称 DAG。工作流中的 Task 任务以有向无环图的形式组装起来,从入度为零的节点进行拓扑遍历,直到无后继节点为止。举例如下图:

- 流程定义:通过拖拽任务节点并建立任务节点的关联所形成的可视化DAG
- 流程实例:流程实例是流程定义的实例化,可以通过手动启动或定时调度生成。每运行一次流程定义,产生一个流程实例
-
任务实例:任务实例是流程定义中任务节点的实例化,标识着某个具体的任务
-
任务类型:目前支持有 SHELL、SQL、SUB_PROCESS(子流程)等
-
调度方式:系统支持基于cron表达式的定时调度和手动调度。命令类型支持:启动工作流、从当前节点开始执行、恢复被容错的工作流、恢复暂停流程、从失败节点开始执行、补数、定时、重跑、暂停、停止、恢复等待线程。
-
定时调度:系统采用quartz分布式调度器,并同时支持cron表达式可视化的生成
-
依赖:系统不仅支持 DAG 简单的前驱和后继节点之间的依赖,同时还提供任务依赖节点,支持流程间的自定义任务依赖
-
优先级 :支持流程实例和任务实例的优先级,如果流程实例和任务实例的优先级不设置,则默认是先进先出
-
邮件告警:支持 SQL任务 查询结果邮件发送,流程实例运行结果邮件告警及容错告警通知
-
失败策略:对于并行运行的任务,如果有任务失败,提供两种失败策略处理方式,继续是指不管并行运行任务的状态,直到流程失败结束。结束是指一旦发现失败任务,则同时Kill掉正在运行的并行任务,流程失败结束
ps: 工作流--> 工作流实例, 一个工作流包含多个任务节点,任务节点 --> 任务实例
1.3.2 模块介绍
-
dolphinscheduler-master master模块,提供工作流管理和编排服务。
-
dolphinscheduler-worker worker模块,提供任务执行管理服务。
-
dolphinscheduler-alert 告警模块,提供 AlertServer 服务。
-
dolphinscheduler-api web应用模块,提供 ApiServer 服务。
-
dolphinscheduler-common 通用的常量枚举、工具类、数据结构或者基类
-
dolphinscheduler-dao 提供数据库访问等操作。
-
dolphinscheduler-extract extract模块,包含master/worker/alert的sdk
-
dolphinscheduler-service service模块,包含Quartz、Zookeeper、日志客户端访问服务,便于server模块和api模块调用
-
dolphinscheduler-ui 前端模块
二、DolphinScheduler架构原理
2.1 系统架构图

为更好的理解上述架构图, 相关概念介绍:
- API服务:用于与UI交互;
- Process(工作流):由任务以有向无环图形式构成,执行时解析一个工作流为多个任务,可设置工作流优先级,工作执行全局参数、超时告警;
- Task(任务):调度执行的最小单元,包含Shell、Spark、Flink、Sql、MR等多种类型。可设置任务执行优先级、任务执行参数、超时告警、超时失败;
- Command(待调度指令):工作流经手动调度或定时调度生成的数据,存储在数据库DB中;
- Instance(任务实例):任务执行后,会生成相应的实例,记录执行时任务的状态及执行内容,任务实例可查看下载日志;
- Master(调度服务):提供对工作流手动调度、定时调度、超时告警、任务容错、任务执行监控等功能;
- Worker(运行服务):解析工作流,识别任务类型,调用对应任务类型的逻辑,生成任务实例;
- Alert(告警通知服务):可通过Email、微信等多种方式,告知工作流、任务执行结果。
- 主节点(master)和工作节点(worker)是去中心化的,可以部署多个Master和多个Worker,它们可以分布在不同的位置并独立工作。
下面具体展示调度任务的创建、被调度执行的过程:
- 根据具体的业务需求,通过Web界面以DAG形式创建工作流,生成Process并落库;
- 手动调度或定时调度生成待调度指令Command,存储在数据库DB中;
- Master监听读取Command记录,解析后动态分配至Worker,选择对应的任务类型执行;
- Worker执行完成后,生成Process Instance(工作流实例)、Task Instance(任务实例)并落库;
- Alert告警模块监听Instance实例,通过Email等发送任务执行结果。
2.2 架构说明
2.2.1 MasterServer
MasterServer采用分布式无中心设计理念,其主要负责DAG任务切分、任务提交监控、并同时监听其它MasterServer和WorkerServer的健康状态。
MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 MasterServer基于netty提供监听服务。
2.2.2 WorkerServer
WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。
WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。 WorkerServer基于netty提供监听服务。
该服务内主要包含:
-
WorkerManagerThread主要负责任务队列的提交,不断从任务队列中领取任务,提交到线程池处理;
-
TaskExecuteThread主要负责任务执行的流程,根据不同的任务类型进行任务的实际处理;
-
RetryReportTaskStatusThread主要负责定时轮询向Master汇报任务的状态,直到Master回复状态的ack,避免任务状态丢失;
2.2.3 AlertServer
提供告警服务,通过告警插件的方式实现丰富的告警手段。
2.2.4 ApiServer
API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。
2.2.5 UI
系统的前端页面,提供系统的各种可视化操作界面。
2.2.6 ZooKeeper
系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。
2.3 架构设计思想
2.3.1 去中心化vs中心化
(1)中心化思想
中心化的设计理念比较简单,分布式集群中的节点按照角色分工,大体上分为两种角色:

- Master的角色主要负责任务分发并监督Slave的健康状态,可以动态的将任务均衡到Slave上,以致Slave节点不至于“忙死”或”闲死”的状态。
- Worker的角色主要负责任务的执行工作并维护和Master的心跳,以便Master可以分配任务给Slave。
该中心化思想设计存在的问题:
- 一旦Master出现了问题,则群龙无首,整个集群就会崩溃。为了解决这个问题,大多数Master/Slave架构模式都采用了主备Master的设计方案,可以是热备或者冷备,也可以是自动切换或手动切换,而且越来越多的新系统都开始具备自动选举切换Master的能力,以提升系统的可用性。
- 另外一个问题是如果Scheduler在Master上,虽然可以支持一个DAG中不同的任务运行在不同的机器上,但是会产生Master的过负载。如果Scheduler在Slave上,则一个DAG中所有的任务都只能在某一台机器上进行作业提交,则并行任务比较多的时候,Slave的压力可能会比较大
(2)去中心化
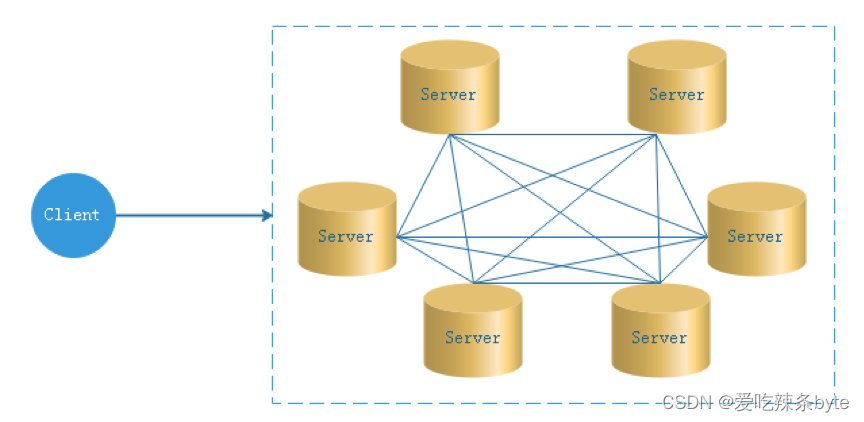
- 在去中心化设计里,通常没有Master/Slave的概念,所有的角色都是一样的,地位是平等的
- 去中心化设计的核心设计在于整个分布式系统中不存在一个区别于其他节点的”管理者”,因此不存在单点故障问题。但由于不存在” 管理者”节点所以每个节点都需要跟其他节点通信才得到必须要的机器信息,而分布式系统通信的不可靠性,则大大增加了上述功能的实现难度。
- DolphinScheduler的去中心化是Master/Worker注册心跳到Zookeeper中,Master基于slot(资源槽)处理各自的Command,通过selector分发任务给worker,实现Master集群和Worker集群无中心。
2.3.2 容错设计
容错分为服务宕机容错和任务重试,服务宕机容错又分为Master容错和Worker容错两种情况
服务宕机容错设计依赖于ZooKeeper的Watcher机制,实现原理如图:
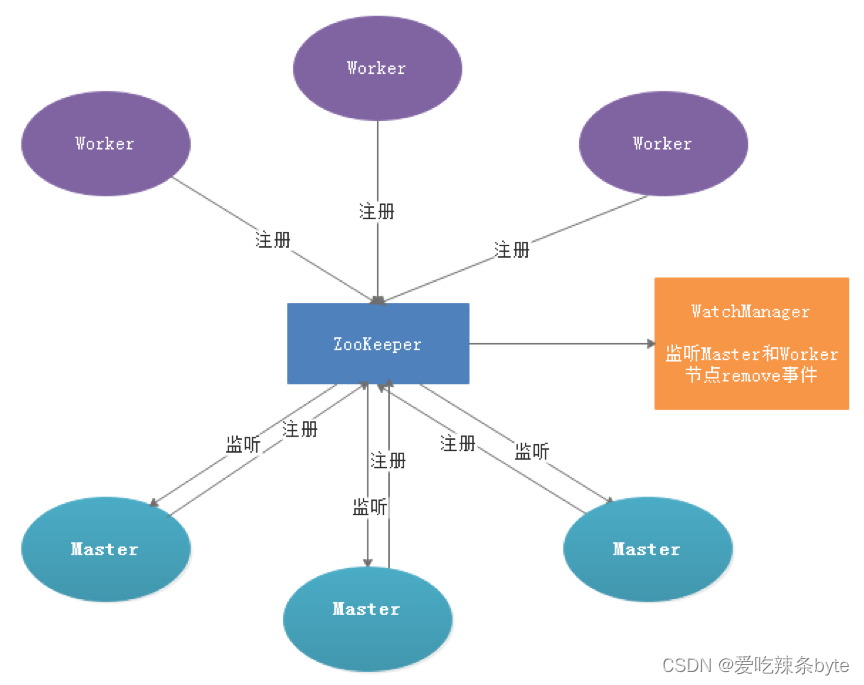
其中Master监控其他Master和Worker的目录,如果监听到remove事件,则会根据具体的业务逻辑进行流程实例容错或者任务实例容错。
2.3.3 任务失败重试
这里首先要区分任务失败重试、流程失败恢复、流程失败重跑的概念:
- 任务失败重试是任务级别的,是调度系统自动进行的,比如一个Shell任务设置重试次数为3次,那么在Shell任务运行失败后会自己再最多尝试运行3次
- 流程失败恢复是流程级别的,是手动进行的,恢复是从只能从失败的节点开始执行或从当前节点开始执行
- 流程失败重跑也是流程级别的,是手动进行的,重跑是从开始节点进行
2.3.4 任务优先级设计
根据任务实例的json解析优先级,然后把流程实例优先级_流程实例id_任务优先级_任务id信息保存在ZooKeeper任务队列中,当从任务队列获取的时候,通过字符串比较即可得出最需要优先执行的任务。
(1)流程定义的优先级:考虑到有些流程需要先于其他流程进行处理,这个可以在流程启动或者定时启动时配置,共有5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST。如下图

(2)任务的优先级:分为5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST。如下图

三、负载均衡
负载均衡即通过路由算法(通常是集群环境),合理的分摊服务器压力,达到服务器性能的最大优化。
3.1 Worker 负载均衡算法
DolphinScheduler-Master 分配任务至 worker,默认提供了三种算法:
3.1.1 加权随机(random)
3.1.2 平滑轮询(roundrobin)
3.1.3 线性负载(lowerweight)
默认配置为线性加权负载。该算法每隔一段时间会向注册中心上报自己的负载信息,主要根据两个信息来进行判断:
- load 平均值(默认是 CPU 核数 *2)
- 可用物理内存(默认是 0.3,单位是 G)
如果两者任何一个低于配置项,那么这台worker将不参与负载(即不分配流量)。可以在 worker.properties 修改下面的属性来自定义配置
- worker.max.cpu.load.avg=-1 (worker最大cpu load均值,只有高于系统cpu load均值时,worker服务才能被派发任务. 默认值为-1: cpu cores * 2)
- worker.reserved.memory=0.3 (worker预留内存,只有低于系统可用内存时,worker服务才能被派发任务,单位为百分比)
参考文章:
DolphinScheduler 介绍及系统架构_dolphinschedule的模块是怎么划分的-CSDN博客
深入了解海豚调度DolphinScheduler-CSDN博客