1 目标
搜狗-微信这个网址来爬取微信的文章:
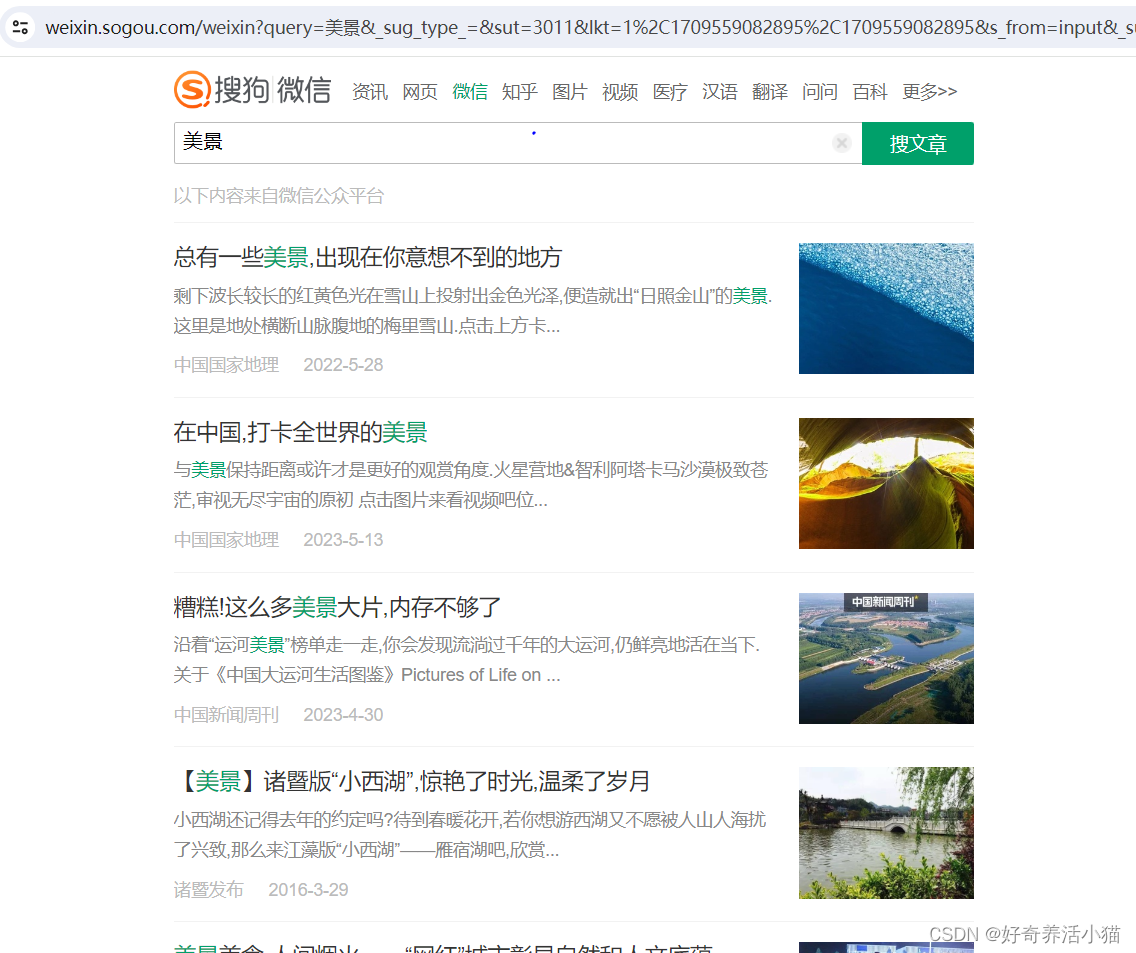
ps:登录后才能查看第10页之后的内容:
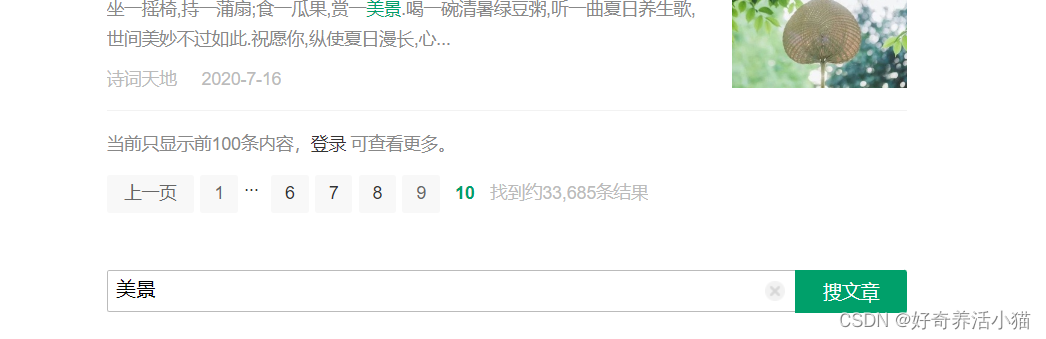
量翻页触发了网站的反爬虫措施,导致ip被封,需要进行解锁。
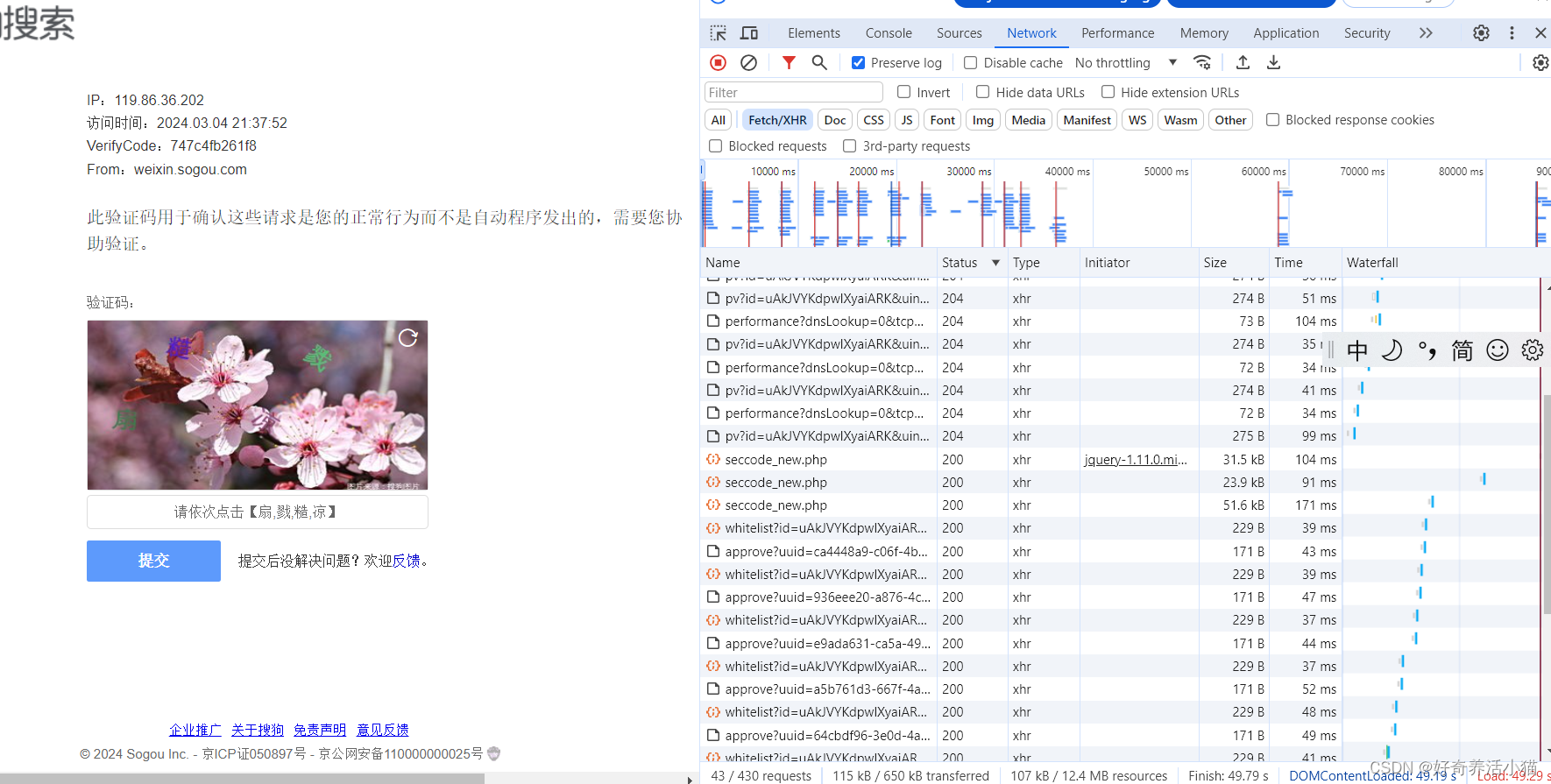
然而从doc中可以看到,请求失败的那页(状态码应该非200)被隐藏,只留下了状态码为200的这个验证页面。但是实际上,最后的那次请求返回状态码是302。
详情界面:
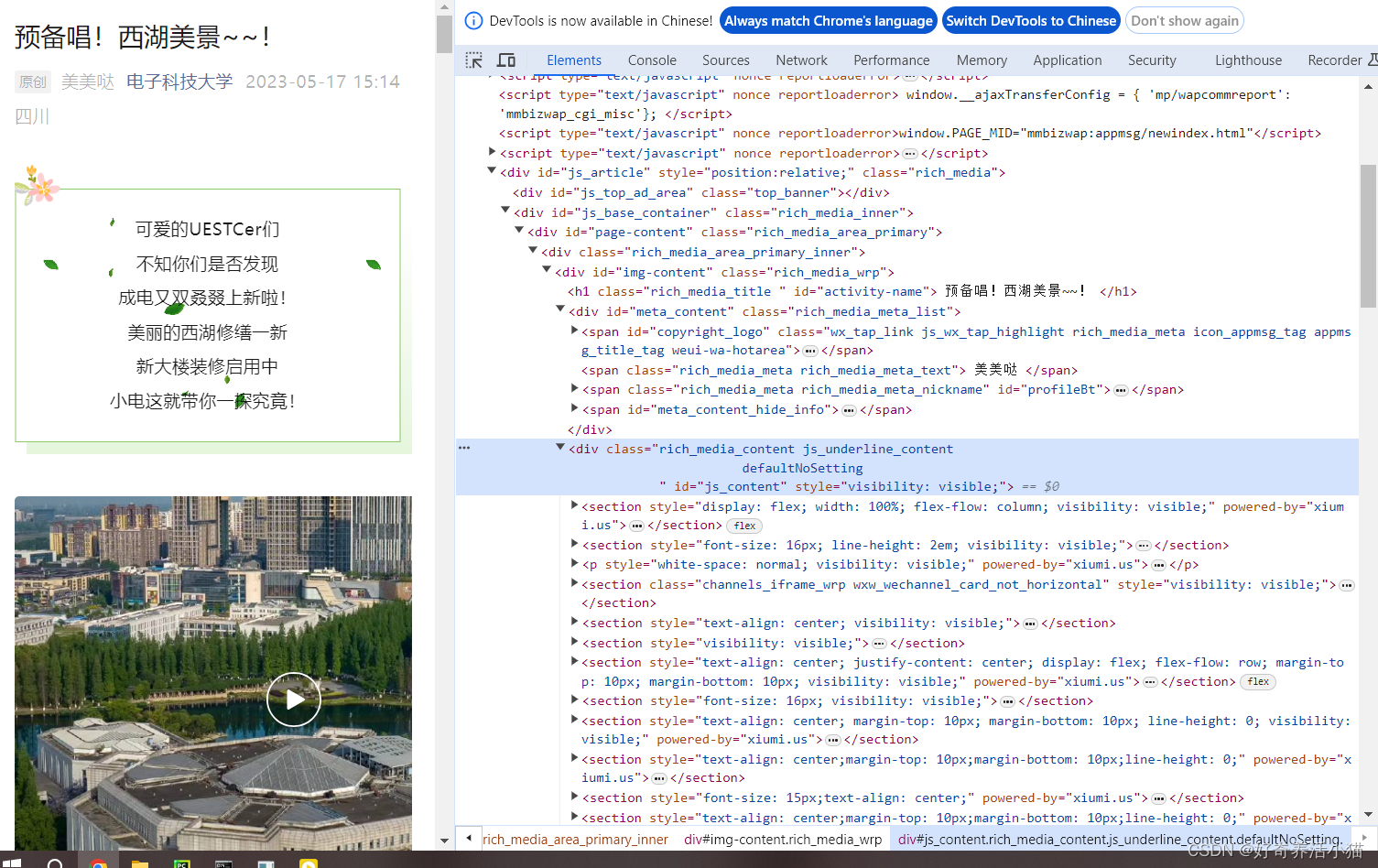
2 流程框架
- 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果。
- 代理设置:如果遇到302状态码,则证明IP被封,切换代理重试。
- 分析详情页内容:请求详情页,分析得到标题,正文等内容。
- 将数据保存到数据库:将结构化数据保存至MongDB。
3 实战
获取索引页
url:https://weixin.sogou.com/weixin?query=程序员&type=2&page=1
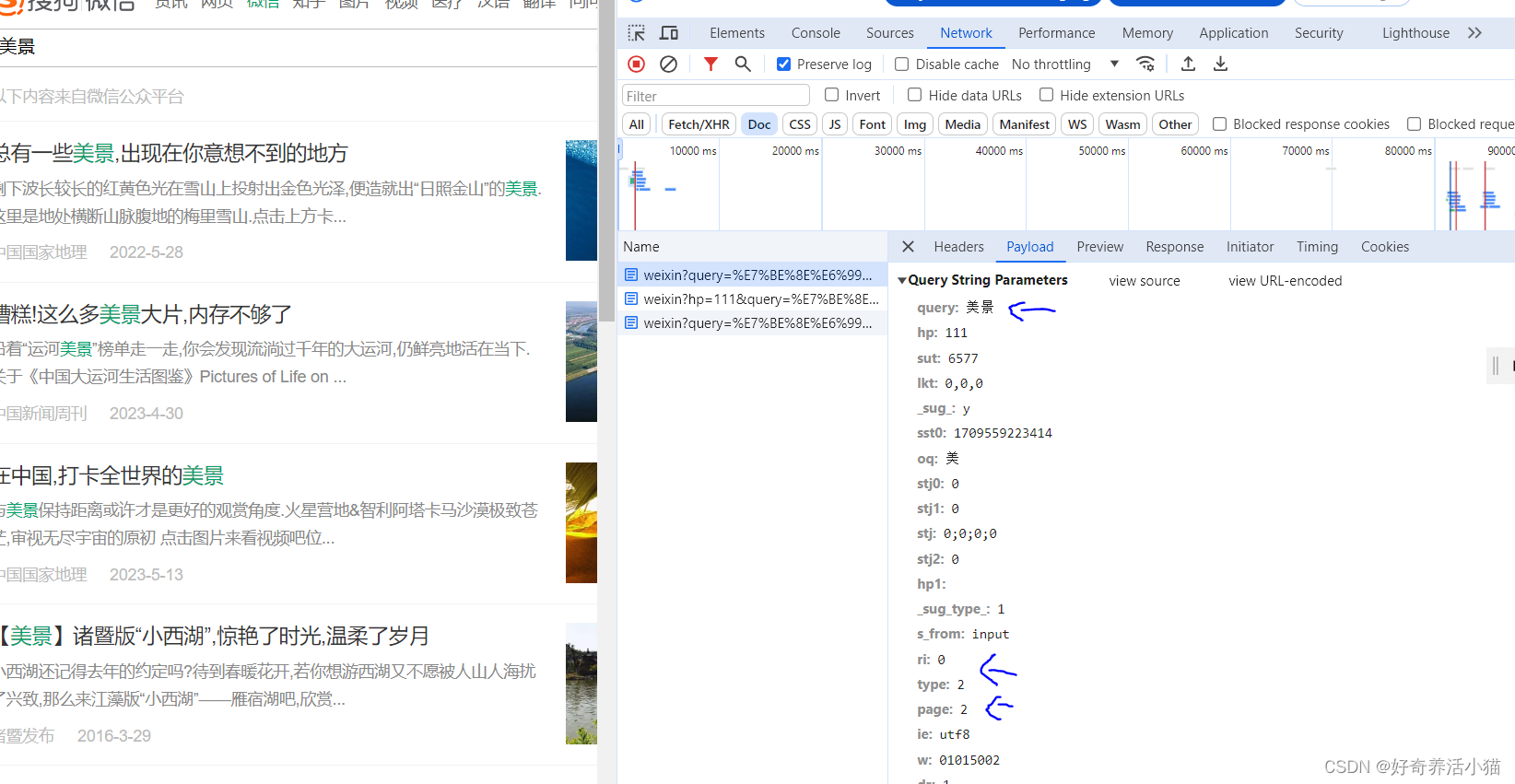
headers的部分,可以从网页审查中复制过来,并且构造为一个字典。
from urllib.parse import urlencode
import requests
base_url = 'https://weixin.sogou.com/weixin?'
headers={'Cookie': 'IPLOC=CN3205; SUID=E5C695243118960A000000005BD115E8; ld=Tlllllllll2b1SgolllllVsSVWklllllJJgpiyllll9lllllpylll5@@@@@@@@@@; SUV=1540429307839674; ABTEST=4|1541298543|v1; weixinIndexVisited=1; JSESSIONID=aaaKxagg6ZBOkf5LLDaBw; sct=2; ppinf=5|1541299811|1542509411|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZToyNzolRTclOEMlQUElRTUlODYlQjIlRTUlODclODl8Y3J0OjEwOjE1NDEyOTk4MTF8cmVmbmljazoyNzolRTclOEMlQUElRTUlODYlQjIlRTUlODclODl8dXNlcmlkOjQ0Om85dDJsdU9wakYzNVp1NklhNGhqYTdKUUxydTRAd2VpeGluLnNvaHUuY29tfA; pprdig=FzBX9Lki68sfImndi44lcV84vLEqbuPe8AXYRZYh5DtlawPVJEYr3bvv1oF8vmRfP0_rrTGYvtpqKwb39yNvJWqXl-Oh-29iaP0S893esgJdg2XNaxk7PNy5dcq1gMZOmf2kS_2YjNbV8WDULQnpjleCUcqcMMw3Av-FlSTgeh4; sgid=19-37785553-AVveXmPrwZ6BLoWTJ85UWicI; ppmdig=1541299811000000f0314597e0483df6fc4b14c41cacb024; PHPSESSID=0t7h64pmb3n0iphtp2j62i3a26; SUIR=A278AA1A3F3B46F2B8CFF48F3FD5AB76; SNUID=8ED5863612176BDC72510ED513A5E096',
'Host': 'weixin.sogou.com',
'Referer': 'https://weixin.sogou.com/weixin?query=%E7%A8%8B%E5%BA%8F%E5%91%98&type=2&page=39&ie=utf8',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
def get_html(url):
# 请求url
try:
response = requests.get(url,allow_redirects=False,headers =headers) #禁止302自动跳转处理
if response.status_code == 200:
return response.text
if response.status_code == 302:
pass
except ConnectionError:
return get_html(url) # 若失败,重试
# 获取索引页
def get_index(keyword,page):
data = { # 将get请求所需要的参数构造为字典
'query':keyword,
'type':2,
'page':page
}
url = base_url + urlencode(data) # 拼接url
html = get_html(url)
print(html)
if __name__ == '__main__':
get_index('美景',1)

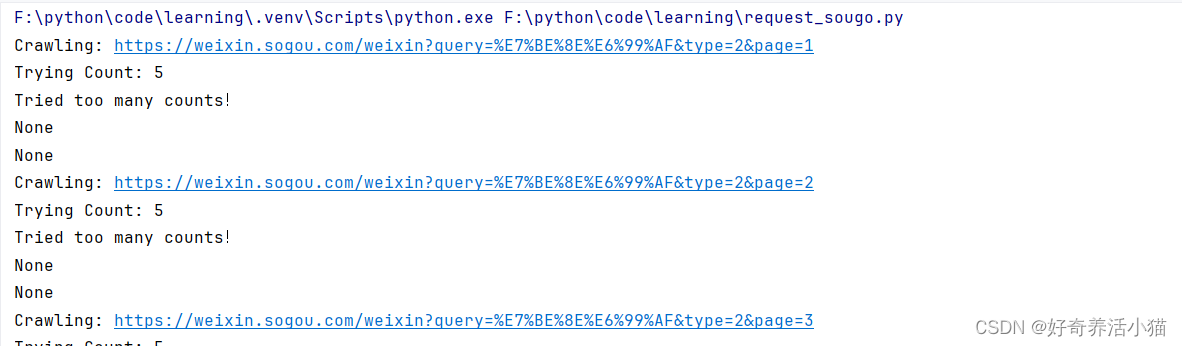
只请求了第一页,并不会触发反爬虫措施,改成循环会触发302,说明此时的ip已经被封:
def main():
for page in range(1,101):
html = get_index(keyword,page)
print(html)
if __name__ == '__main__':
main()

使用代理
出现ip被封的情况,需要更换代理进行请求。
from urllib.parse import urlencode
import requests
base_url = 'https://weixin.sogou.com/weixin?'
headers={'Cookie': 'IPLOC=CN3205; SUID=E5C695243118960A000000005BD115E8; ld=Tlllllllll2b1SgolllllVsSVWklllllJJgpiyllll9lllllpylll5@@@@@@@@@@; SUV=1540429307839674; ABTEST=4|1541298543|v1; weixinIndexVisited=1; JSESSIONID=aaaKxagg6ZBOkf5LLDaBw; sct=2; ppinf=5|1541299811|1542509411|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZToyNzolRTclOEMlQUElRTUlODYlQjIlRTUlODclODl8Y3J0OjEwOjE1NDEyOTk4MTF8cmVmbmljazoyNzolRTclOEMlQUElRTUlODYlQjIlRTUlODclODl8dXNlcmlkOjQ0Om85dDJsdU9wakYzNVp1NklhNGhqYTdKUUxydTRAd2VpeGluLnNvaHUuY29tfA; pprdig=FzBX9Lki68sfImndi44lcV84vLEqbuPe8AXYRZYh5DtlawPVJEYr3bvv1oF8vmRfP0_rrTGYvtpqKwb39yNvJWqXl-Oh-29iaP0S893esgJdg2XNaxk7PNy5dcq1gMZOmf2kS_2YjNbV8WDULQnpjleCUcqcMMw3Av-FlSTgeh4; sgid=19-37785553-AVveXmPrwZ6BLoWTJ85UWicI; ppmdig=1541299811000000f0314597e0483df6fc4b14c41cacb024; PHPSESSID=0t7h64pmb3n0iphtp2j62i3a26; SUIR=A278AA1A3F3B46F2B8CFF48F3FD5AB76; SNUID=8ED5863612176BDC72510ED513A5E096',
'Host': 'weixin.sogou.com',
'Referer': 'https://weixin.sogou.com/weixin?query=%E7%A8%8B%E5%BA%8F%E5%91%98&type=2&page=39&ie=utf8',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
keyword = "美景"
proxy_pool_url = 'http://127.0.0.1:5000/get' #这是从web接口获取代理的地址
proxy = None #将代理设为全局变量
max_count = 5 #最大请求次数
#获取代理
def get_proxy():
try:
response = requests.get(proxy_pool_url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#请求url
def get_html(url,count = 1):
#打印一些调试信息
print('Crawling:', url)
print('Trying Count:', count)
global proxy #引用全局变量
if count >= max_count:#如果请求次数达到了上限
print('Tried too many counts!')
return None
try :
if proxy:# 如果现在正在使用代理
proxies = {
'http:':'http://'+ proxy #设置协议类型
}
response = requests.get(url, allow_redirects = False, headers = headers ,proxies = proxies)#使用有代理参数的请求
else: #否则使用正常的请求
response = requests.get(url, allow_redirects = False,headers=headers)#禁止自动处理跳转
if response.status_code == 200:
return response.text
if response.status_code == 302:
# 需要代理
print("302!")
proxy = get_proxy()
if proxy:
print('Using Proxy', proxy)
return get_html(url)
else:
print('Get Proxy Failed')
return None
except ConnectionError as e:
print('Error Occurred',e.args)#打印错误信息
proxy = get_proxy() #若失败,更换代理
count += 1 #请求次数+1
return get_html(url,count) #重试
# 获取索引页
def get_index(keyword,page):
data = { # 将get请求所需要的参数构造为字典
'query':keyword,
'type':2,
'page':page
}
url = base_url + urlencode(data) # 拼接url
html = get_html(url,5)
print(html)
def main():
for page in range(1,101):
html = get_index(keyword,page)
print(html)
if __name__ == '__main__':
main()
分析详情页内容
解析索引页
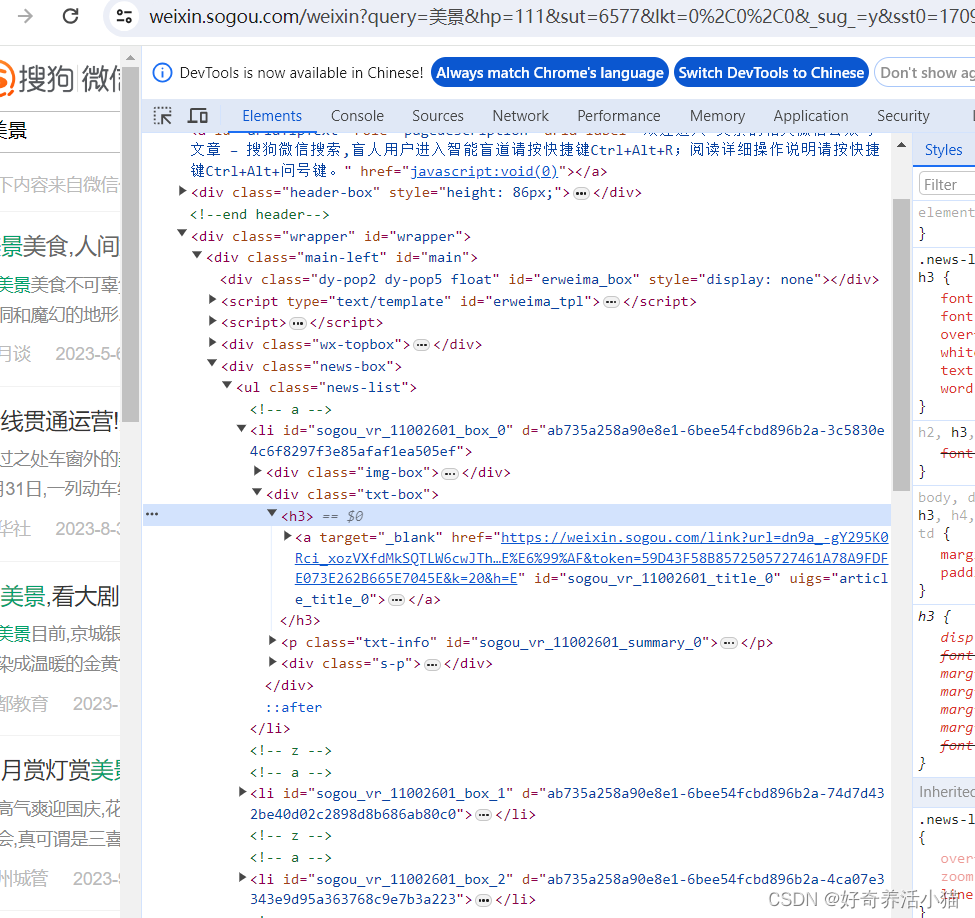
def parse_index(html):
doc = pq(html)
items = doc('.news-box .news-list li .txt-box h3 a').items()
for item in items:
yield item.attr('href')
请求详情页
# 请求详情页
def get_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
解析详情页
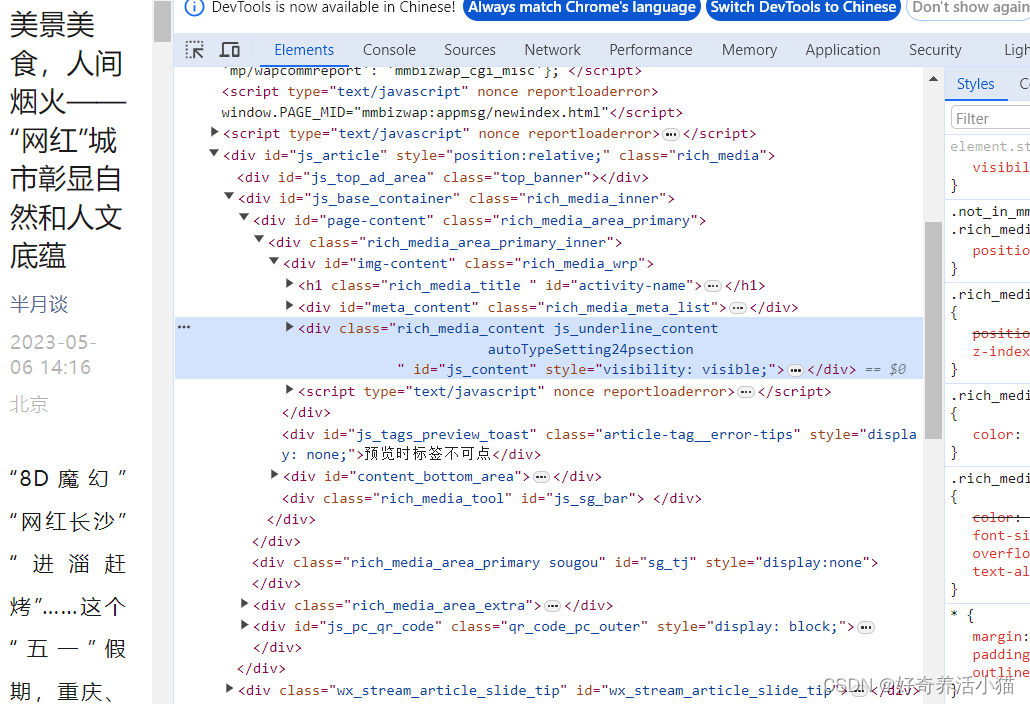
# 解析详情页
def parse_detail(html):
doc = pq(html)
title = doc('.rich_media_title').text()
content = doc('.rich_media_content').text()
date = doc('#post-date').text()
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title': title,
'content': content,
'date': date,
'nickname': nickname,
'wechat': wechat
}
保存至MongoDB
client = pymongo.MongoClient('localhost')
db = client["weixin"]
def save_to_mongo(data):
if db['articles'].update({'title': data['title']}, {'$set': data}, True): # 如果不存在则插入,否则进行更新
print('save to Mongo', data["title"])
else:
print('Save to Monge Failed', data['title'])
4 整体代码
from urllib.parse import urlencode
import requests
from pyquery import PyQuery as pq
base_url = 'https://weixin.sogou.com/weixin?'
headers={'Cookie': 'IPLOC=CN3205; SUID=E5C695243118960A000000005BD115E8; ld=Tlllllllll2b1SgolllllVsSVWklllllJJgpiyllll9lllllpylll5@@@@@@@@@@; SUV=1540429307839674; ABTEST=4|1541298543|v1; weixinIndexVisited=1; JSESSIONID=aaaKxagg6ZBOkf5LLDaBw; sct=2; ppinf=5|1541299811|1542509411|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZToyNzolRTclOEMlQUElRTUlODYlQjIlRTUlODclODl8Y3J0OjEwOjE1NDEyOTk4MTF8cmVmbmljazoyNzolRTclOEMlQUElRTUlODYlQjIlRTUlODclODl8dXNlcmlkOjQ0Om85dDJsdU9wakYzNVp1NklhNGhqYTdKUUxydTRAd2VpeGluLnNvaHUuY29tfA; pprdig=FzBX9Lki68sfImndi44lcV84vLEqbuPe8AXYRZYh5DtlawPVJEYr3bvv1oF8vmRfP0_rrTGYvtpqKwb39yNvJWqXl-Oh-29iaP0S893esgJdg2XNaxk7PNy5dcq1gMZOmf2kS_2YjNbV8WDULQnpjleCUcqcMMw3Av-FlSTgeh4; sgid=19-37785553-AVveXmPrwZ6BLoWTJ85UWicI; ppmdig=1541299811000000f0314597e0483df6fc4b14c41cacb024; PHPSESSID=0t7h64pmb3n0iphtp2j62i3a26; SUIR=A278AA1A3F3B46F2B8CFF48F3FD5AB76; SNUID=8ED5863612176BDC72510ED513A5E096',
'Host': 'weixin.sogou.com',
'Referer': 'https://weixin.sogou.com/weixin?query=%E7%A8%8B%E5%BA%8F%E5%91%98&type=2&page=39&ie=utf8',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
keyword = "美景"
proxy_pool_url = 'http://127.0.0.1:5000/get' #这是从web接口获取代理的地址
proxy = None #将代理设为全局变量
max_count = 5 #最大请求次数
client = pymongo.MongoClient('localhost')
db = client["weixin"]
def save_to_mongo(data):
if db['articles'].update({'title': data['title']}, {'$set': data}, True): # 如果不存在则插入,否则进行更新
print('save to Mongo', data["title"])
else:
print('Save to Monge Failed', data['title'])
# 解析详情页
def parse_detail(html):
doc = pq(html)
title = doc('.rich_media_title').text()
content = doc('.rich_media_content').text()
date = doc('#post-date').text()
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title': title,
'content': content,
'date': date,
'nickname': nickname,
'wechat': wechat
}
# 请求详情页
def get_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
# 解析索引页
def parse_index(html):
doc = pq(html)
items = doc('.news-box .news-list li .txt-box h3 a').items()
for item in items:
yield item.attr('href')
#获取代理
def get_proxy():
try:
response = requests.get(proxy_pool_url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#请求url
def get_html(url,count = 1):
#打印一些调试信息
print('Crawling:', url)
print('Trying Count:', count)
global proxy #引用全局变量
if count >= max_count:#如果请求次数达到了上限
print('Tried too many counts!')
return None
try :
if proxy:# 如果现在正在使用代理
proxies = {
'http:':'http://'+ proxy #设置协议类型
}
response = requests.get(url, allow_redirects = False, headers = headers ,proxies = proxies)#使用有代理参数的请求
else: #否则使用正常的请求
response = requests.get(url, allow_redirects = False,headers=headers)#禁止自动处理跳转
if response.status_code == 200:
return response.text
if response.status_code == 302:
# 需要代理
print("302!")
proxy = get_proxy()
if proxy:
print('Using Proxy', proxy)
return get_html(url)
else:
print('Get Proxy Failed')
return None
except ConnectionError as e:
print('Error Occurred',e.args)#打印错误信息
proxy = get_proxy() #若失败,更换代理
count += 1 #请求次数+1
return get_html(url,count) #重试
# 获取索引页
def get_index(keyword,page):
data = { # 将get请求所需要的参数构造为字典
'query':keyword,
'type':2,
'page':page
}
url = base_url + urlencode(data) # 拼接url
html = get_html(url,5)
print(html)
def main():
for page in range(1, 101):
html = get_index(keyword, page)
if html:
article_urls = parse_index(html)
for article_url in article_urls:
article_html = get_detail(article_url)
if article_html:
article_data = parse_detail(article_html)
print(article_data)
if article_data:
save_to_mongo(article_data)
if __name__ == '__main__':
main()